A Ascensão da Memória de Contexto: O Elo Perdido entre RAM e SSD

A arquitetura de servidores está mudando. Descubra como o CXL 3.1 e os módulos CMM-D estão criando uma nova camada de 'Memória de Contexto' para salvar a IA do gargalo de armazenamento.
A arquitetura de computação que nos trouxe até aqui está sufocando. Durante décadas, vivemos sob a ditadura benevolente de Von Neumann, onde a CPU é o rei e a memória é apenas um súdito distante. Mas na era dos Grandes Modelos de Linguagem (LLMs) e da Inteligência Artificial generativa, essa monarquia colapsou. Estamos testemunhando o nascimento de uma nova camada geológica na infraestrutura de TI: a Memória de Contexto.
Não se trata apenas de "mais RAM" ou "SSDs mais rápidos". Estamos falando de uma classe inteiramente nova de hardware que preenche o abismo de desempenho e custo entre a DRAM volátil e o armazenamento persistente. Se você gerencia datacenters ou projeta infraestrutura para IA, a sua próxima grande compra não será apenas discos NVMe, mas módulos de memória expandida via CXL.
Resumo em 30 segundos
- O Abismo da Latência: Existe uma lacuna crítica entre a RAM (nanossegundos) e o SSD (microssegundos) que gargala aplicações de IA modernas.
- A Solução CXL: O protocolo Compute Express Link permite conectar memória externa com latência próxima à da RAM, criando uma camada de "Far Memory".
- Economia de Escala: Essa tecnologia permite ter Terabytes de memória "quase-RAM" por uma fração do custo da DDR5, viabilizando janelas de contexto massivas para IA.
O colapso da arquitetura atual
A metáfora clássica da computação sempre foi: o disco rígido é o arquivo no porão, a RAM é a mesa de trabalho e a CPU é o trabalhador. O problema é que o "trabalhador" (IA) agora precisa de uma mesa do tamanho de um estádio de futebol para espalhar todos os documentos (parâmetros e contexto) de uma só vez.
A DDR5 atual é rápida, mas é cara e fisicamente limitada pelos slots da placa-mãe. O SSD NVMe é barato e vasto, mas é lento demais para a lógica de pensamento instantâneo da IA.
Quando um modelo como o GPT-4 ou Claude precisa acessar informações que não cabem na VRAM da GPU ou na RAM do sistema, ele sofre uma penalidade brutal de latência ao buscar no SSD. É aqui que a infraestrutura tradicional falha. Precisamos de um meio-termo.
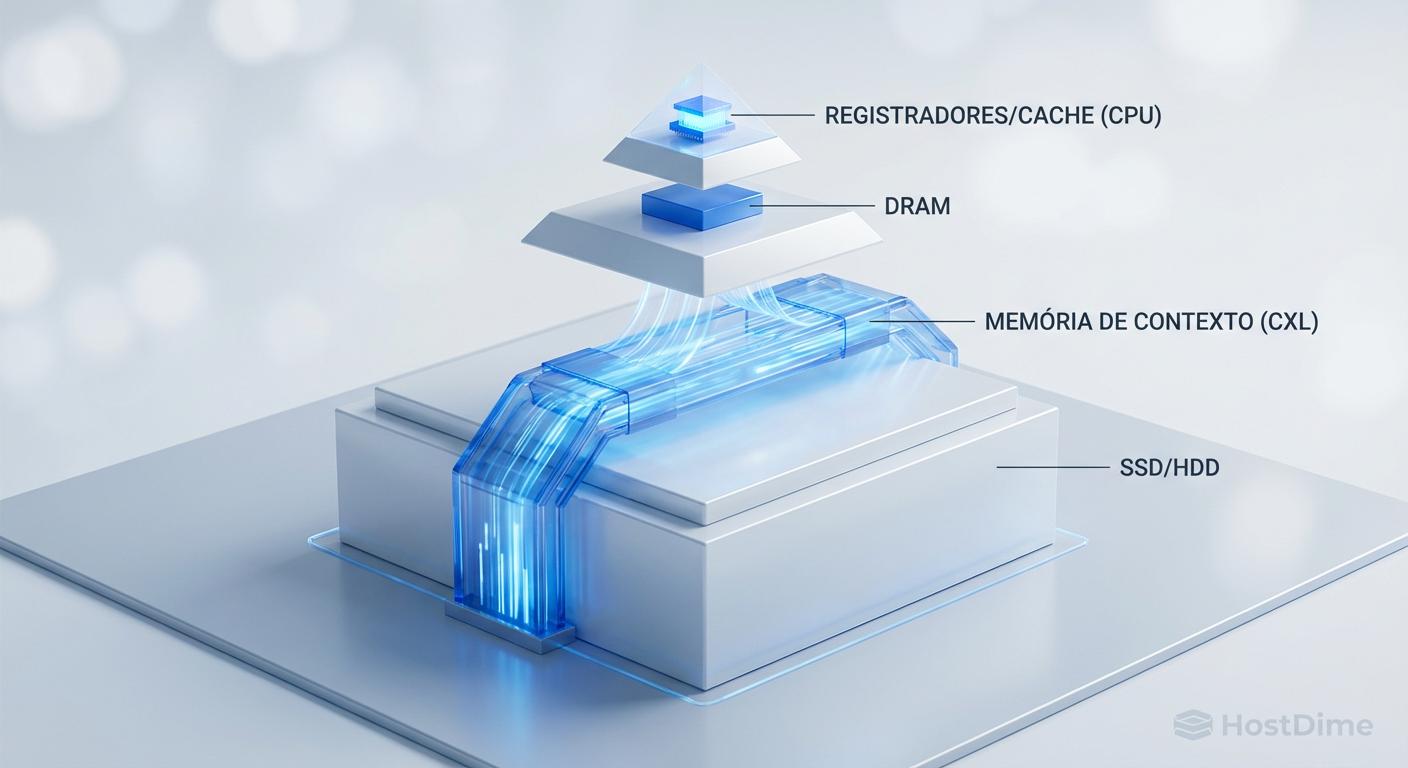 Figura: Diagrama da nova hierarquia de memória ilustrando a inserção da camada de Memória de Contexto via CXL entre a DRAM e o SSD.
Figura: Diagrama da nova hierarquia de memória ilustrando a inserção da camada de Memória de Contexto via CXL entre a DRAM e o SSD.
CXL: O protocolo que mudou as regras
A resposta da indústria para esse dilema é o CXL (Compute Express Link). Diferente do PCIe tradicional, que trata dispositivos como periféricos de I/O (entrada/saída), o CXL permite que dispositivos conectados falem a "língua da memória" (semântica de load/store).
Isso significa que a CPU pode acessar dados em um cartão CXL conectado via slot PCIe como se fosse um pente de memória RAM adicional. Não há drivers de sistema de arquivos, não há interrupções de software complexas. É acesso direto.
💡 Dica Pro: Pense no CXL não como um cabo, mas como uma extensão do barramento da memória. Com o CXL 3.1, podemos finalmente desacoplar a memória da CPU, permitindo pools de memória compartilhada entre vários servidores.
Far Memory vs. Near Memory
Neste novo paradigma, dividimos a memória em duas categorias:
Near Memory (DDR5 Direta): Conectada diretamente à CPU. Latência ultra-baixa (<100ns). Caríssima.
Far Memory (CXL): Conectada via barramento CXL. Latência ligeiramente maior (~170-250ns), mas com capacidade massiva e custo reduzido.
Para aplicações de RAG (Retrieval-Augmented Generation), onde a IA precisa consultar uma base de conhecimento vasta antes de responder, a "Far Memory" é o Santo Graal. A latência de 200ns é imperceptível para a inferência do modelo, mas a capacidade de manter 4TB ou 8TB de dados "quentes" prontos para uso muda o jogo econômico.
O hardware da nova hierarquia
Não estamos falando de teoria. O hardware já está entre nós, adotando formatos que confundem a linha entre disco e memória.
Empresas como Samsung e SK Hynix estão liderando com produtos como o CMM-D (CXL Memory Module - DRAM). Visualmente, eles se parecem com SSDs Enterprise no formato E3.S (parte da família EDSFF), mas por dentro, são repletos de chips DRAM e um controlador CXL inteligente.
Isso permite que um servidor 2U, que antes estava limitado a alguns terabytes de RAM nos slots DIMM, agora possa expandir sua capacidade de memória em centenas de terabytes usando as baias frontais que antes eram exclusivas para armazenamento.
Tabela Comparativa: A Nova Ordem
Para entender onde a Memória de Contexto se encaixa, veja a comparação direta:
| Característica | RAM DDR5 (Near Memory) | Memória CXL (Far Memory) | SSD NVMe Enterprise |
|---|---|---|---|
| Latência Típica | 70 - 100 ns | 170 - 250 ns | 80.000 - 100.000 ns (80-100µs) |
| Protocolo | Barramento de Memória | CXL (sobre PCIe físico) | NVMe (sobre PCIe físico) |
| Acesso | Byte-addressable (Load/Store) | Byte-addressable (Load/Store) | Block-addressable (I/O) |
| Custo por GB | Alto ($$$$) | Médio ($$) | Baixo ($) |
| Capacidade Máx. | Limitada por slots DIMM | Alta (Expansível via PCIe) | Muito Alta (Petabytes) |
| Uso Ideal | OS, Kernels de IA, Hot Data | Bancos em Memória, Cache de RAG | Armazenamento Persistente |
⚠️ Perigo: Não confunda Memória CXL com Swap em SSD. O Swap é uma gambiarra do sistema operacional que usa disco lento para simular RAM. O CXL é hardware dedicado que oferece performance real de memória, sem a penalidade catastrófica do Swap.
A economia do RAG e a "Latência de Cauda"
O custo de treinar modelos é alto, mas o custo de inferência (colocar o modelo para trabalhar) é onde as empresas sangram dinheiro. Em sistemas de busca vetorial e RAG, manter todo o índice na RAM DDR5 é financeiramente inviável para grandes datasets.
Ao mover esses índices para a Memória de Contexto CXL, sacrificamos uma fração ínfima de performance (imperceptível para o usuário final) em troca de uma redução de custos de 30% a 50%.
Além disso, o CXL resolve o problema da "latência de cauda" (tail latency). Em SSDs, ocasionalmente uma leitura demora muito mais que o normal, causando engasgos. Na memória CXL, a latência é determinística e estável. Isso é vital para SLAs rigorosos em ambientes financeiros e de saúde.
 Figura: Visualização interna de um servidor moderno mostrando módulos de memória CXL no formato E3.S conectados diretamente à via de dados da CPU, ilustrando a expansão de capacidade.
Figura: Visualização interna de um servidor moderno mostrando módulos de memória CXL no formato E3.S conectados diretamente à via de dados da CPU, ilustrando a expansão de capacidade.
O fim do servidor monolítico
Olhando 5 a 10 anos à frente, a distinção entre "Servidor de Banco de Dados" e "Servidor de Aplicação" ficará turva. Caminhamos para o Memory-Centric Computing (Computação Centrada na Memória).
Neste futuro próximo, a memória não pertencerá a um servidor específico. Teremos "caixas de memória" (Memory Appliances) no rack, conectadas via CXL a múltiplos servidores de computação. Se o Servidor A precisar de 1TB de RAM para uma tarefa pesada às 9h da manhã, ele aloca do pool. Às 10h, ele devolve essa memória para o pool, e o Servidor B a utiliza.
Isso elimina o superdimensionamento (over-provisioning) de memória, que hoje é um dos maiores desperdícios de capital em datacenters. A memória torna-se um recurso fluido, líquido, acessível por qualquer processador no cluster.
O horizonte inevitável
A ascensão da Memória de Contexto não é uma "tendência" passageira; é uma correção necessária da física computacional. A Lei de Moore para processadores pode estar desacelerando, mas a demanda por dados em tempo real está explodindo exponencialmente.
Para o profissional de storage e infraestrutura, a mensagem é clara: a fronteira entre o que é "disco" e o que é "memória" foi apagada. Prepare-se para arquitetar sistemas onde a persistência é secundária e a capacidade de contexto é o novo ouro. O futuro não pertence a quem processa mais rápido, mas a quem consegue manter mais contexto "vivo" e acessível instantaneamente.
O que é Memória de Contexto?
É uma nova camada de infraestrutura situada entre a DRAM rápida (caríssima) e o SSD NVMe (lento), viabilizada pelo protocolo CXL para armazenar grandes janelas de contexto de IA e bancos de dados em memória com custo reduzido.Qual a diferença entre CXL e NVMe?
Enquanto o NVMe é um protocolo de armazenamento baseado em blocos (exige drivers e sistema de arquivos), o CXL usa semântica de memória (acesso direto a bytes), permitindo que a CPU acesse dados externos com latência próxima à da RAM.O CXL vai substituir a RAM DDR5?
Não. Ele atua como uma memória de expansão (Tier 2), oferecendo capacidade massiva com uma leve penalidade de latência, ideal para dados que não cabem na DDR5 principal, mas precisam ser acessados mais rápido que em um SSD.
Julian Vance
Futurista de Tecnologia
"Exploro as fronteiras da infraestrutura, do armazenamento em DNA à computação quântica. Ajudo líderes a decodificar o horizonte tecnológico e construir o datacenter de 2035 hoje."