A ilusão dos IOPS: Por que benchmarks sintéticos falham no armazenamento para IA

Descubra por que testes com FIO e CrystalDiskMark mascaram gargalos reais em clusters de treinamento de IA e como utilizar o MLPerf Storage para validar a saturação de GPUs H100.
Você acabou de investir milhões em um cluster de NVIDIA H100s. O armazenamento é um array all-flash NVMe de última geração que promete 10 milhões de IOPS na folha de especificações. No entanto, ao iniciar o treinamento do modelo, o nvidia-smi mostra suas GPUs oscilando em 40% de utilização. O armazenamento não está saturado, a rede está livre, mas o treinamento se arrasta.
Bem-vindo ao "abismo da ingestão de dados".
A indústria de armazenamento passou décadas otimizando controladores para bancos de dados transacionais e virtualização, onde o IOPS (Input/Output Operations Per Second) aleatório de 4K é rei. O problema é que cargas de trabalho de Inteligência Artificial e Aprendizado de Máquina (AI/ML) não se comportam como um banco de dados Oracle. Elas operam em um paradigma fundamentalmente diferente, onde a latência de metadados e o throughput de ingestão de tensores tornam os benchmarks sintéticos tradicionais, como o CrystalDiskMark ou configurações padrão do FIO, não apenas irrelevantes, mas perigosamente enganosos.
Resumo em 30 segundos
- IOPS é uma métrica de banco de dados: O treinamento de IA depende de throughput sequencial massivo (LLMs) ou operações intensivas de metadados (Visão Computacional), raramente de leituras aleatórias simples.
- O gargalo mudou: Em benchmarks sintéticos, testamos o disco. Na IA real, o gargalo frequentemente é a CPU tentando decodificar dados rápido o suficiente para alimentar a GPU (Data Loading Bottleneck).
- Use ferramentas de rastro: Abandone testes genéricos. Ferramentas como MLPerf Storage e DLIO simulam o comportamento real de dataloaders como PyTorch e TensorFlow.
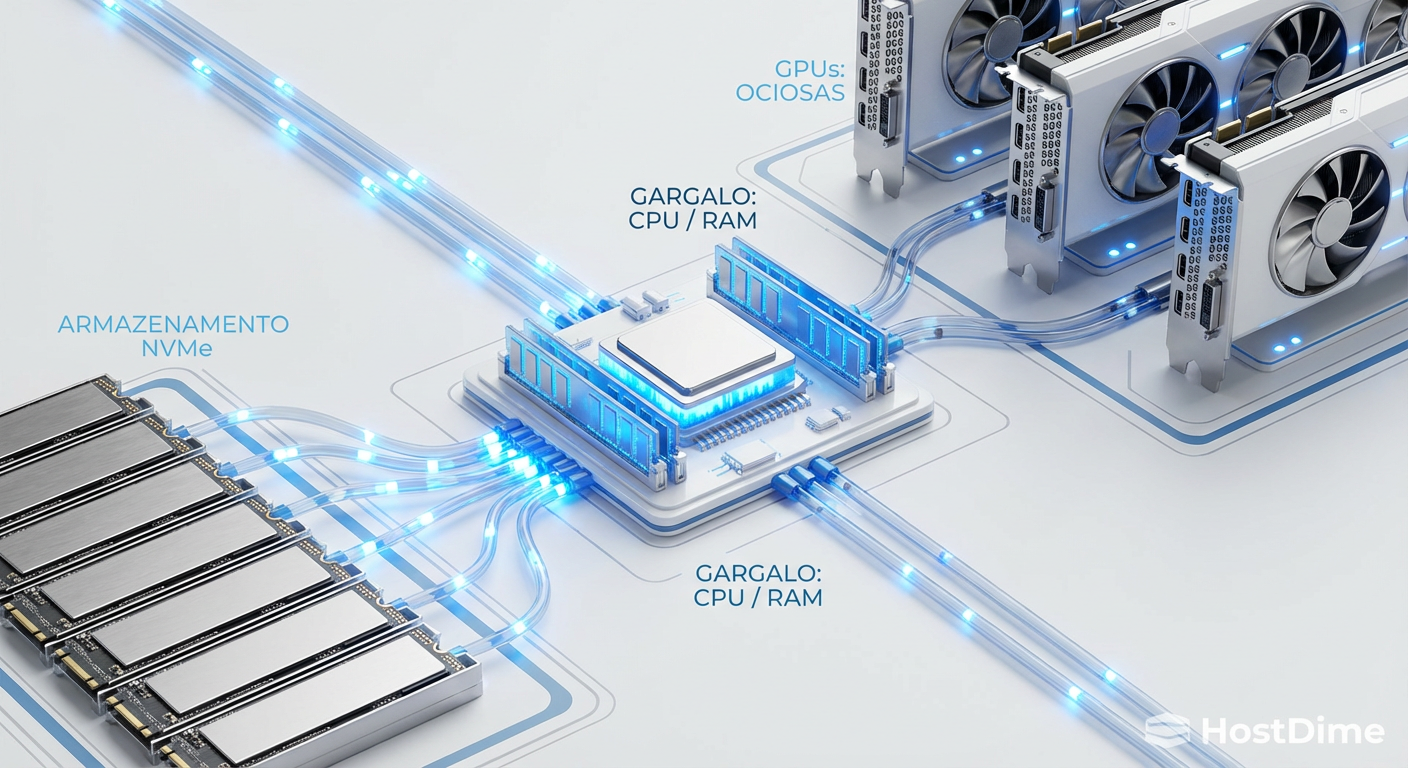 Figura: O "Data Loading Bottleneck": Onde IOPS brutos morrem antes de chegar à GPU.
Figura: O "Data Loading Bottleneck": Onde IOPS brutos morrem antes de chegar à GPU.
O paradoxo das GPUs ociosas
A métrica mais cara no seu datacenter não é o custo por TB do SSD, mas o custo de oportunidade de uma GPU ociosa. Se você tem um cluster de 8 GPUs e elas estão esperando por dados 20% do tempo, você efetivamente jogou fora o valor de quase duas dessas placas.
O erro fundamental de metodologias baseadas apenas em IOPS é ignorar o pipeline de software. Em um teste sintético com FIO (Flexible I/O Tester), o caminho é curto: o kernel solicita o bloco, o SSD entrega, o teste confirma. Fim.
Em um dataloader de IA real (como o DataLoader do PyTorch), o processo é brutalmente mais complexo:
O sistema de arquivos localiza o arquivo (metadados).
O arquivo é lido para a RAM do sistema (Page Cache).
A CPU descomprime e decodifica o arquivo (ex: JPEG para tensor bruto).
Transformações e aumentos de dados são aplicados (crop, resize, normalize).
O tensor é copiado via barramento PCIe para a VRAM da GPU.
Se o seu armazenamento tem uma latência de cauda (p99) alta, o passo 1 engasga. Se o throughput não for linear, o passo 2 falha. O resultado é o que chamamos de GPU Starvation. O armazenamento pode estar entregando apenas 2 GB/s de um potencial de 50 GB/s, não porque o disco é lento, mas porque a latência de cada operação individual de abertura de arquivo está paralisando a thread de carregamento da CPU.
💡 Dica Pro: Monitore a métrica de Wait I/O na CPU, não apenas a atividade do disco. Se o Wait I/O estiver alto e a utilização do disco baixa, você tem um problema de latência de metadados ou de serialização no software, não de largura de banda bruta.
A desconexão entre padrões de acesso e a realidade
Para entender por que os benchmarks falham, precisamos dissecar os dois tipos principais de cargas de trabalho de IA atuais: LLMs (Large Language Models) e Visão Computacional.
LLMs e o mito do aleatório
O treinamento de LLMs (como GPT ou Llama) envolve datasets massivos, muitas vezes arquivos binários gigantescos contendo tokens pré-processados. O padrão de acesso aqui é predominantemente sequencial. O sistema lê grandes blocos (1MB a 16MB) continuamente.
Testar um array de storage para LLM usando blocos de 4K é um erro metodológico primário. Um SSD NVMe pode entregar 800.000 IOPS em 4K, mas engasgar ao tentar manter um fluxo estável de 10 GB/s em leituras sequenciais de longa duração devido ao superaquecimento ou saturação do cache SLC.
Visão computacional e o inferno dos metadados
Aqui o cenário inverte. Datasets como ImageNet ou COCO consistem em milhões de arquivos minúsculos (imagens de 50KB a 500KB). O desafio aqui não é a taxa de transferência (MB/s), mas a taxa de operações de metadados.
Cada leitura de imagem exige um open(), read(), close(). Se o seu sistema de arquivos (seja local como XFS/Ext4 ou distribuído como Ceph/Lustre/WEKA) não conseguir lidar com a tempestade de lookups de metadados, o throughput efetivo cai para perto de zero. Benchmarks sintéticos que criam um arquivo gigante e fazem leituras aleatórias dentro dele (o padrão do CrystalDiskMark) mascaram completamente essa latência de sistema de arquivos. Eles testam a NAND, não a pilha de software de armazenamento.
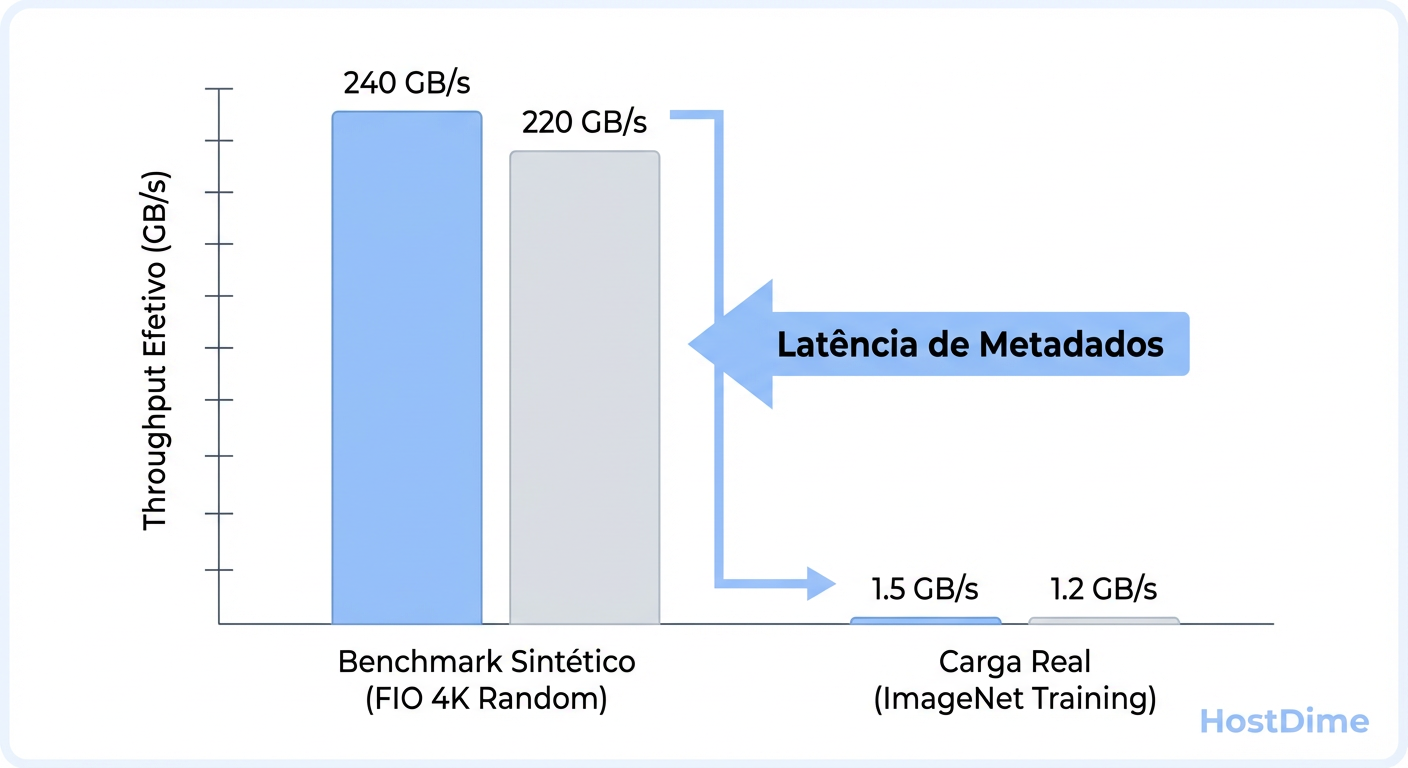 Figura: A ilusão dos números: Como a sobrecarga de metadados destrói a performance teórica em datasets de visão computacional.
Figura: A ilusão dos números: Como a sobrecarga de metadados destrói a performance teórica em datasets de visão computacional.
Implementação de cargas baseadas em rastreamento
A única maneira científica de validar armazenamento para IA é usar benchmarks que mimetizam o comportamento da aplicação, não do disco. É aqui que entram o MLPerf Storage e o DLIO.
MLPerf Storage
Padronizado pela MLCommons, este benchmark não gera tráfego aleatório. Ele utiliza "rastros" (traces) de cargas de trabalho reais (como BERT e Unet3D). Ele simula o tempo de computação do acelerador (GPU) e exige que o armazenamento entregue dados rápido o suficiente para manter essa "GPU virtual" ocupada. Se o armazenamento falha, a utilização do acelerador cai. A métrica de sucesso não é MB/s, é Accelerator Utilization (AU).
DLIO (Data Loader I/O)
Desenvolvido por pesquisadores do Argonne National Laboratory, o DLIO é uma ferramenta de benchmark que se conecta diretamente aos dataloaders modernos. Ele permite que arquitetos de sistemas simulem o comportamento de I/O de modelos específicos sem precisar rodar o treinamento real (que exigiria GPUs caras).
Ao usar essas ferramentas, você descobre verdades desconfortáveis. Por exemplo, um array SATA SSD bem configurado com um sistema de arquivos otimizado para metadados pode superar um array NVMe mal configurado em tarefas de visão computacional, simplesmente porque a latência de handshake do protocolo é menor ou o paralelismo do software é melhor.
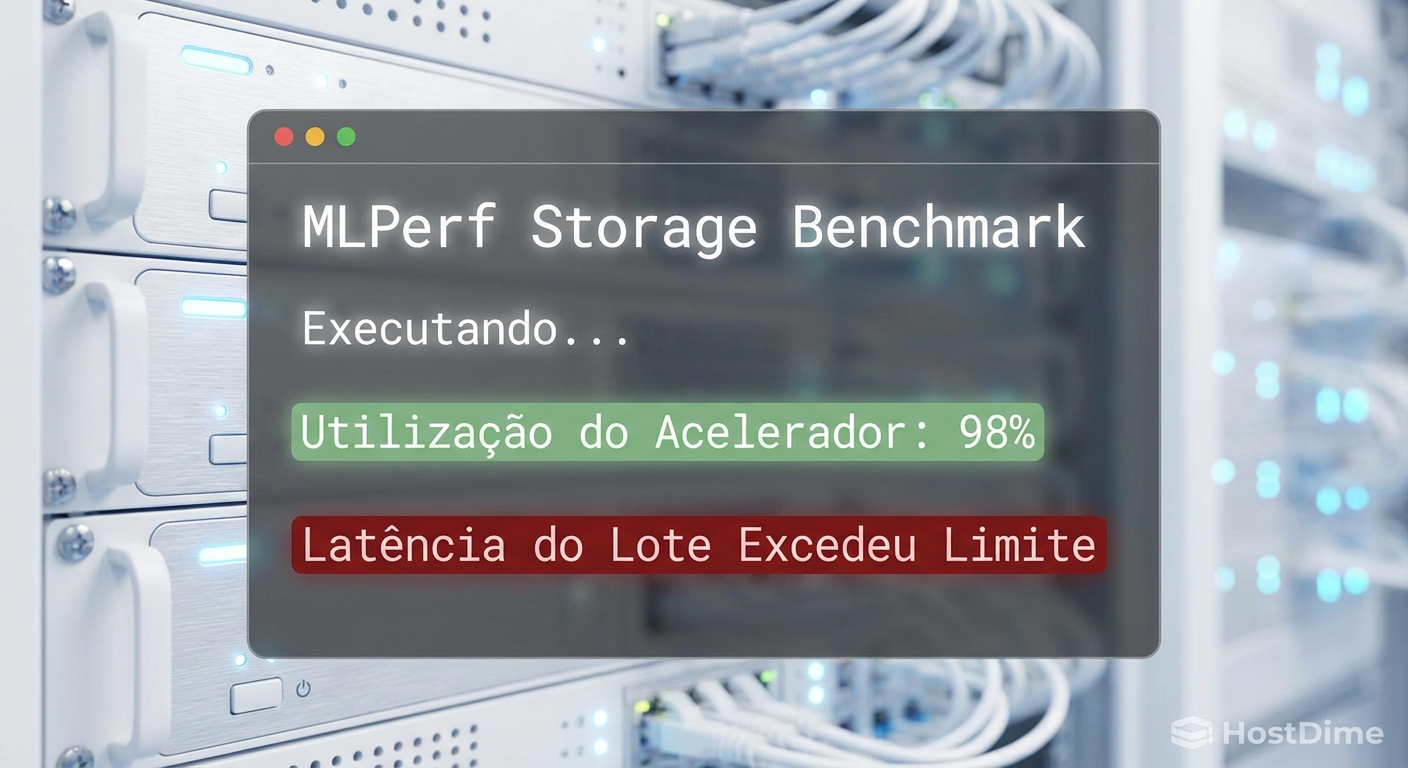 Figura: Validando a realidade: O MLPerf Storage foca na utilização do acelerador, a única métrica que paga as contas.
Figura: Validando a realidade: O MLPerf Storage foca na utilização do acelerador, a única métrica que paga as contas.
Tabela Comparativa: O Velho vs. O Novo
Para consolidar a mudança de paradigma, observe as diferenças críticas entre as abordagens:
| Característica | Benchmark Sintético (FIO / Iometer) | Benchmark de IA (MLPerf Storage / DLIO) |
|---|---|---|
| Foco Principal | Estressar o dispositivo de bloco (SSD/HDD). | Estressar o pipeline completo de ingestão. |
| Padrão de Acesso | Matemático (100% Random ou Sequencial). | Estocástico (Baseado em traces reais de PyTorch/TF). |
| Métrica de Sucesso | IOPS e Latência Média. | Utilização do Acelerador (AU) e Tempo de Época. |
| Simulação de "Think Time" | Nenhuma (I/O constante). | Simula o tempo de computação da GPU entre batches. |
| Relevância para IA | Baixa (apenas para sanity check de hardware). | Crítica (prevê performance real de treinamento). |
Métricas que importam: AU e Tempo de Época
Esqueça os megabytes por segundo. As duas métricas que você deve exigir do seu fornecedor de storage ou medir em sua PoC (Prova de Conceito) são:
Accelerator Utilization (AU): A porcentagem de tempo que a GPU passa executando kernels de computação versus esperando por dados. Um armazenamento ideal mantém a AU acima de 90-95%. Se sua AU é 60%, seu storage é o gargalo, não importa se ele diz fazer 1 milhão de IOPS.
Variação do Tempo de Época (Epoch Time Jitter): O tempo médio para completar uma época de treinamento é importante, mas a consistência é vital. Se uma época leva 1 hora e a seguinte leva 1h30m devido a "vizinhos barulhentos" no storage ou garbage collection do SSD, seu planejamento de treinamento colapsa.
⚠️ Perigo: Cuidado com soluções de armazenamento baseadas em rede (NAS) que não suportam RDMA (Remote Direct Memory Access). Sem RDMA (como RoCE v2 ou InfiniBand), a CPU do servidor de armazenamento e a CPU do cliente gastam ciclos preciosos copiando dados de buffers de rede, aumentando drasticamente a latência de entrega do batch.
 Figura: Tempo é dinheiro: Como a latência de entrega de dados impacta diretamente o tempo total de treinamento.
Figura: Tempo é dinheiro: Como a latência de entrega de dados impacta diretamente o tempo total de treinamento.
O futuro é a validação orientada a aplicação
A era de comprar armazenamento baseando-se em números de "herói" na capa do datasheet acabou para o setor de IA. A complexidade dos pipelines de dados modernos, com descompressão na CPU, staging em memória e transferência via PCIe, exige uma abordagem holística.
Se você é um arquiteto de infraestrutura, sua obrigação é parar de perguntar "quantos IOPS isso faz?" e começar a perguntar "qual é a curva de latência de cauda para um dataset de 5 milhões de arquivos pequenos?". Utilize ferramentas como DLIO para modelar sua carga específica antes de assinar o cheque. O armazenamento mais rápido não é aquele com o maior número no papel, mas aquele que nunca deixa sua GPU esperando.
Referências & Leitura Complementar
MLCommons: MLPerf Storage Benchmark Methodology. Disponível na documentação oficial da MLCommons.
Argonne National Laboratory: DLIO: A Data-Centric I/O Benchmark. Paper técnico sobre caracterização de I/O em Deep Learning.
NVIDIA: GPUDirect Storage (GDS) Design Guide. Documentação técnica sobre bypass de CPU para armazenamento.
SNIA: Real World Storage Workload Specification. Padrões da indústria para captura e replay de cargas de trabalho.
Perguntas Frequentes (FAQ)
Por que meu array NVMe mostra 1 milhão de IOPS no FIO mas minha GPU fica em 40% de uso?
Porque o treinamento de IA raramente usa leituras aleatórias de 4K puras, que é o cenário onde esses números de 1 milhão são gerados. O gargalo real geralmente está na CPU (que precisa descomprimir e decodificar dados antes de enviar à GPU) ou na latência de metadados do sistema de arquivos ao lidar com milhões de arquivos pequenos. Benchmarks de "hero numbers" ignoram completamente a pilha de software e o pipeline de ingestão.O que é Accelerator Utilization (AU) e por que é mais importante que MB/s?
AU mede a porcentagem de tempo real que a GPU passa computando versus esperando ociosamente por dados. É a métrica financeira definitiva. Um storage que entrega 50 GB/s de pico mas tem alta latência oscilante pode fazer a AU cair para 60%, desperdiçando 40% do seu investimento em GPUs. É preferível um storage de 20 GB/s consistentes que mantenha a AU em 95%.Qual o tamanho de bloco ideal para testar storage para LLMs?
Para Large Language Models (LLMs), o padrão de acesso é massivamente sequencial. Esqueça o 4K. Você deve configurar seus testes com tamanhos de bloco entre 1MB e 4MB (ou até maiores, dependendo do *chunk size* do seu dataset). O foco deve ser em *throughput* sustentado e, crucialmente, na latência de cauda (p99) durante operações de gravação de *checkpoints*.O NVIDIA GPUDirect Storage (GDS) elimina a necessidade de benchmarks de CPU?
Parcialmente, mas não totalmente. O GDS remove o "bounce buffer" da CPU, permitindo que o storage envie dados direto para a memória da GPU via DMA. Isso alivia a CPU, mas exige que o hardware de storage suporte protocolos específicos (como NVMe-oF sobre RDMA). A validação ainda é necessária para garantir que o barramento PCIe da GPU não esteja saturado e que o storage consiga manter o ritmo das solicitações diretas da GPU.
Dr. Elena Kovic
Metodologista de Benchmark
"Desmonto o marketing com análise estatística rigorosa. Meus benchmarks isolam cada variável para revelar a performance crua e sem filtros do hardware corporativo."