A matemática da eficiência: Erasure coding vs. réplica no planejamento de clusters

Descubra como reduzir o TCO de armazenamento em até 50% substituindo réplica tripla por Erasure Coding. Uma análise matemática para planejadores de capacidade.
A lei de Moore pode ter impulsionado o processamento por décadas, mas no universo do armazenamento de dados, a física e a economia colidem de forma muito mais brutal. Quando projetamos clusters de armazenamento para a era do Big Data e da IA generativa, deparamo-nos com uma realidade matemática desconfortável: a estratégia de proteção de dados padrão está drenando o orçamento de infraestrutura.
O modelo de "Réplica 3x" (três cópias idênticas dos dados), que serviu bem durante a era dos discos rígidos baratos e redes de 1GbE, tornou-se um passivo tóxico em ambientes de NVMe e Flash de alta densidade. Não é apenas uma questão de comprar mais discos; é sobre o desperdício de slots de servidor, energia, refrigeração e portas de switch.
Para o planejador de capacidade, a transição para Erasure Coding (EC) não é apenas uma opção de configuração no software de storage definido por software (SDS); é a única álgebra viável para escalar além do petabyte sem implodir o CAPEX.
Resumo em 30 segundos
- O custo da segurança: A replicação tripla (3x) exige que você compre 3PB de hardware para cada 1PB de dados úteis, um overhead de 200% insustentável em escalas modernas.
- A matemática do EC: O Erasure Coding (como o esquema 4+2) reduz esse overhead para 50%, mantendo ou elevando a durabilidade dos dados através de algoritmos de paridade.
- O trade-off inevitável: Enquanto o EC salva o orçamento, ele cobra um imposto em ciclos de CPU e latência de escrita, exigindo um design de cluster híbrido inteligente.
O impacto inflacionário da réplica no orçamento
No planejamento de capacidade tradicional, a segurança dos dados sempre foi sinônimo de redundância bruta. Se você tem um bloco de dados, você o copia para dois outros nós. Se um nó falha, você tem duas cópias de segurança. Simples, robusto e rápido para leituras.
No entanto, a simplicidade tem um preço oculto que se revela exponencialmente. Imagine um cluster projetado para armazenar 5 PB de dados úteis. No modelo de Réplica 3x, a necessidade bruta de armazenamento é de 15 PB. Se estivermos falando de HDDs mecânicos de 20TB, o custo é alto. Se estivermos falando de SSDs NVMe Enterprise para alimentar cargas de IA, o custo é proibitivo.
⚠️ Perigo: O "cliff" de recursos acontece quando o custo marginal de adicionar capacidade supera o valor do dado armazenado. Com a Réplica 3x, você atinge esse precipício financeiro muito antes do que com qualquer outra estratégia.
Além do custo do disco, há o custo do chassi. Armazenar 200% de "lixo" (cópias redundantes) significa que 2/3 do seu espaço em rack, consumo de ar condicionado e portas de rede estão servindo apenas como uma apólice de seguro passiva, sem entregar valor ativo para a aplicação.
 Figura: Comparativo visual do footprint físico: A ineficiência espacial da Réplica 3x contra a densidade otimizada do Erasure Coding.
Figura: Comparativo visual do footprint físico: A ineficiência espacial da Réplica 3x contra a densidade otimizada do Erasure Coding.
A álgebra da eficiência: modelando esquemas N+M
O Erasure Coding funciona dividindo o dado original em fragmentos de dados ($k$) e calculando fragmentos de paridade ($m$). A fórmula básica para a capacidade bruta necessária é $(k + m) / k$.
Vamos analisar o esquema mais comum, o Reed-Solomon 4+2:
Dividimos o objeto em 4 pedaços de dados.
Calculamos 2 pedaços de paridade.
Total de fragmentos: 6.
Tolerância a falhas: Podemos perder quaisquer 2 discos ou nós e ainda recuperar os dados.
A matemática da economia: Para armazenar 1 TB de dados úteis:
Réplica 3x: Requer 3 TB brutos. (Overhead de 200%).
EC 4+2: Requer 1,5 TB brutos. (Overhead de 50%).
Ao mudar de Réplica 3x para EC 4+2, você dobra sua capacidade útil sem comprar um único disco adicional. Se formos mais agressivos, com um esquema 8+2 (comum em arquivamento frio ou cold storage), o overhead cai para 25%. Isso significa que 1,25 PB de disco físico entrega 1 PB de espaço útil.
Essa eficiência permite que o planejador de capacidade modele curvas de crescimento de dados muito mais suaves, adiando compras de hardware em meses ou até anos.
Latência e CPU: o preço da paridade
Não existe almoço grátis na termodinâmica do data center. A eficiência de espaço do Erasure Coding é paga com ciclos de processamento (CPU).
Diferente da replicação, que é apenas uma cópia de bits (I/O de rede e disco), o EC exige que a CPU execute cálculos polinomiais complexos para gerar a paridade a cada escrita. Isso introduz latência.
Penalidade de Escrita: Em operações de escrita aleatória (random write), o EC sofre. Se você precisa modificar um pequeno bloco de um arquivo, o sistema precisa ler os dados antigos, ler a paridade antiga, recalcular a nova paridade e escrever tudo de volta. Isso é conhecido como Read-Modify-Write.
Custo de Reconstrução: Embora a reconstrução seja distribuída (falaremos disso adiante), ela exige computação intensa para regenerar os dados perdidos a partir da álgebra dos fragmentos restantes.
Por isso, o EC não é a bala de prata para todas as cargas de trabalho. Bancos de dados transacionais de alta performance (como PostgreSQL ou Oracle com muitas transações por segundo) geralmente sofrem em volumes com EC.
Tabela comparativa: Réplica vs. Erasure Coding
| Critério | Réplica 3x (Padrão) | Erasure Coding (4+2) | Erasure Coding (8+2) |
|---|---|---|---|
| Eficiência de Espaço | 33% (Péssimo) | 67% (Bom) | 80% (Excelente) |
| Overhead de Armazenamento | 200% | 50% | 25% |
| Tolerância a Falhas | 2 Nós/Discos | 2 Nós/Discos | 2 Nós/Discos |
| Uso de CPU na Escrita | Baixo | Médio/Alto | Alto |
| Latência de Escrita | Baixa (Ideal para DBs) | Média | Alta (Ideal para Archive) |
| Cenário Ideal | Boot, DBs, Logs | File Server, Virtualização | Backup, Object Storage, Mídia |
Estratégias de transição para clusters híbridos
Para o arquiteto de storage, a solução não é binária. A resposta correta é quase sempre uma arquitetura híbrida ou tierizada.
Sistemas modernos de armazenamento definido por software (como Ceph, VMware vSAN ou Nutanix Files) permitem definir políticas de armazenamento por volume, bucket ou até mesmo por objeto.
💡 Dica Pro: Implemente uma política de "Tiering Automático". Configure o cluster para receber todas as novas escritas (Hot Data) em um pool de Réplica 3x (preferencialmente NVMe). Após 30 ou 60 dias sem acesso, mova esses dados automaticamente para um pool de Erasure Coding (HDD ou QLC SSD).
Isso oferece o melhor dos dois mundos: a performance de baixa latência da replicação para os dados que estão sendo trabalhados agora, e a eficiência de custo do EC para os 90% dos dados que apenas ocupam espaço.
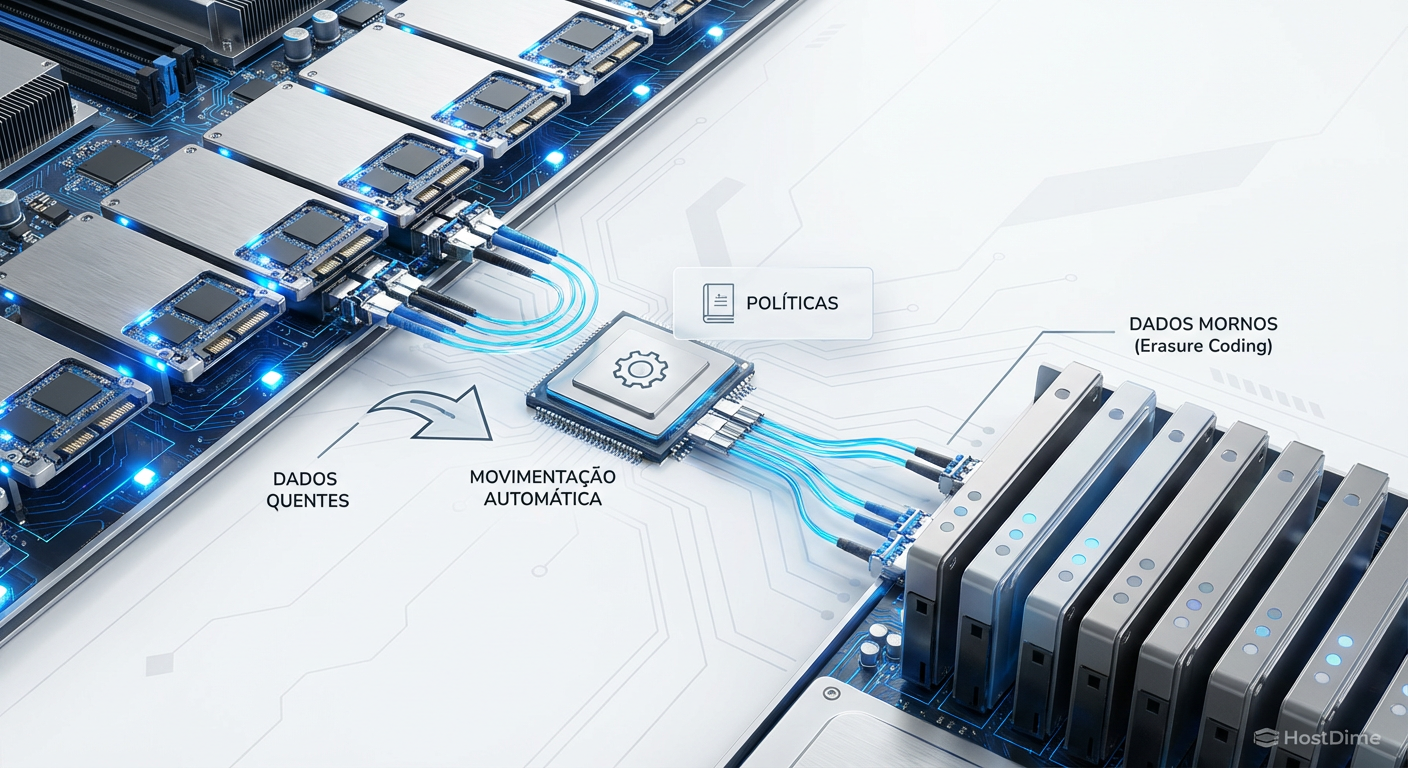 Figura: Diagrama de fluxo de dados em cluster híbrido: Movimentação automática de dados quentes (Réplica) para dados mornos (Erasure Coding) baseada em políticas.
Figura: Diagrama de fluxo de dados em cluster híbrido: Movimentação automática de dados quentes (Réplica) para dados mornos (Erasure Coding) baseada em políticas.
A segurança matemática em discos de alta capacidade
Há um mito persistente de que o RAID 5 ou 6 (os avós do Erasure Coding) são inseguros para discos grandes devido ao tempo de reconstrução. Com discos de 22TB ou 24TB chegando ao mercado, reconstruir um RAID tradicional pode levar dias, deixando o array vulnerável a uma segunda falha fatal.
O Erasure Coding moderno, distribuído em clusters, resolve isso através da reconstrução declusterizada.
Quando um disco de 20TB falha em um cluster com EC, o sistema não lê apenas um disco de paridade para reconstruir. Ele lê fragmentos de todos os outros discos do cluster simultaneamente. Se você tem um cluster de 50 nós, todos os 50 nós participam da reconstrução.
O resultado matemático é que a velocidade de recuperação aumenta linearmente com o tamanho do cluster. Em um ambiente de grande escala, recuperar 20TB pode levar horas em vez de dias, tornando o EC estatisticamente mais seguro que o RAID 6 tradicional, mesmo usando discos gigantes.
 Figura: Visualização de tráfego de rede na reconstrução: O gargalo do RAID tradicional versus o paralelismo massivo da reconstrução em Erasure Coding.
Figura: Visualização de tráfego de rede na reconstrução: O gargalo do RAID tradicional versus o paralelismo massivo da reconstrução em Erasure Coding.
Otimização de CAPEX como motor de sustentabilidade
A adoção do Erasure Coding é, em última análise, uma decisão financeira disfarçada de decisão técnica. Ao reduzir a necessidade de hardware físico em 50% ou mais, o planejador de capacidade libera orçamento para inovação.
Em vez de gastar o budget anual apenas para manter as luzes acesas e armazenar cópias triplas de logs antigos, a economia gerada pelo EC permite investir em camadas de computação, GPUs para inferência ou melhoria da rede de backbone.
Para o futuro próximo, com a explosão de dados não estruturados gerados por IA, a replicação 3x será relegada a nichos específicos de altíssima performance. A matemática é implacável: ou adotamos a eficiência dos algoritmos, ou seremos soterrados pelo custo da redundância física.
Perguntas Frequentes (FAQ)
O Erasure Coding é mais lento que a replicação tradicional?
Geralmente, sim, especialmente em operações de escrita. O Erasure Coding exige que a CPU calcule a paridade antes de gravar os dados, o que adiciona latência. No entanto, em operações de leitura sequencial (streaming), o desempenho pode ser comparável. Não é recomendado para cargas de trabalho de IOPS intenso e randômico, como bancos de dados transacionais, onde a latência é crítica.Qual é a economia real de espaço ao migrar de Réplica 3x para Erasure Coding?
A economia é drástica e imediata. Enquanto a Réplica 3x consome 300% da capacidade bruta (200% de overhead) para armazenar 1TB útil, um esquema de Erasure Coding 4+2 consome apenas 1,5TB (50% de overhead). Isso representa uma redução de 50% na necessidade de hardware físico (discos, servidores, energia) para armazenar a mesma quantidade de dados úteis.O Erasure Coding é seguro para discos de grande capacidade (20TB+)?
Sim, e frequentemente é matematicamente mais seguro que RAID 5 ou 6 tradicionais. Em sistemas distribuídos, o Erasure Coding permite reconstruir dados perdidos lendo fragmentos de dezenas ou centenas de outros nós simultaneamente (reconstrução declusterizada), em vez de estressar um único disco de paridade. Isso reduz drasticamente o tempo de janela de vulnerabilidade durante falhas de disco.
Roberto Sato
Planejador de Capacidade
"Traduzo métricas de consumo em modelos de crescimento sustentável. Minha missão é antecipar gargalos e garantir que sua infraestrutura escale matematicamente antes de atingir o limite crítico."