A Matemática do Caos: Por Que o Upgrade de Storage é uma Equação de Sobrevivência (EOL/EOS)

Não espere o 'cliff' de performance. Aplique a Lei da Escalabilidade Universal (USL) e modelos preditivos para mitigar riscos de EOL/EOS antes da falha catastrófica.
A intuição humana é tragicamente linear. Quando observamos o consumo de armazenamento crescer 10% ao ano, nossa tendência natural é projetar uma linha reta no gráfico e assumir que teremos recursos suficientes até que a capacidade bruta se esgote. No entanto, sistemas computacionais complexos, especialmente arrays de armazenamento corporativo, não operam no domínio da linearidade. Eles habitam o domínio da não-linearidade, onde pequenas variações na carga de trabalho resultam em degradações desproporcionais de performance.
O planejamento de capacidade não é uma arte divinatória; é uma disciplina fundamentada na física dos sistemas de filas e na modelagem matemática. A decisão de adiar um upgrade de storage baseada na premissa de que "ainda há espaço em disco" ignora a variável mais volátil dessa equação: o tempo de serviço. Quando cruzamos as fronteiras do End of Life (EOL) e End of Support (EOS), não estamos apenas lidando com hardware velho; estamos navegando em um sistema onde os coeficientes de falha e latência começam a se comportar de maneira assintótica. A matemática do caos assume o controle.
A Falácia da Linearidade: Onde o Legacy Realmente Falha
A crença de que a performance de um storage se degrada suavemente à medida que a capacidade é preenchida é um erro de cálculo fundamental. Na realidade, a degradação de performance segue uma curva exponencial inversa relacionada à ocupação e à contenda (contention) nos controladores.
Em 2024 e 2025, observamos uma mudança no perfil de I/O que exacerba essa falha de modelagem. Cargas de trabalho modernas, impulsionadas por inferência de IA e analytics em tempo real, geram padrões de acesso aleatório de alta concorrência que saturam as filas de processamento muito antes de a capacidade física do disco ser atingida. Um array de armazenamento legado, projetado para padrões de I/O mais determinísticos da década passada, não falha por falta de terabytes; ele falha por exaustão de coerência.
Quando um sistema legado atinge cerca de 70% a 80% de sua capacidade de processamento (não de armazenamento), a Lei de Little ($L = \lambda W$) dita que o comprimento da fila ($L$) crescerá exponencialmente com pequenos aumentos na taxa de chegada ($\lambda$). O administrador que olha apenas para o dashboard de capacidade livre está cego para a tempestade de latência que se forma nos buffers do controlador. O upgrade não é necessário porque o disco está cheio; é necessário porque a latência está prestes a violar os SLAs de forma irreversível.
EOL e EOS: Variáveis Críticas na Função de Confiabilidade
End of Life (EOL) e End of Support (EOS) são frequentemente tratados como marcos administrativos ou burocráticos. Sob a ótica da engenharia de confiabilidade, no entanto, eles representam pontos de inflexão na curva de probabilidade de falha do sistema.
A confiabilidade de um sistema de armazenamento pode ser modelada, de forma simplificada, pela função $R(t) = e^{-\lambda t}$, onde $\lambda$ é a taxa de falhas. Durante a vida útil suportada, o fabricante suprime artificialmente o $\lambda$ através de atualizações de microcódigo, patches de segurança e substituição preventiva de componentes. No momento em que um sistema entra em EOS, o suporte do fabricante cessa e a taxa de falhas deixa de ser uma constante gerenciada para se tornar uma variável progressiva.
 Figura: Fig. 2: A assimetria econômica do EOS. O custo operacional (OPEX) de manter sistemas legados pós-garantia supera rapidamente o CAPEX de modernização quando ajustado ao risco.
Figura: Fig. 2: A assimetria econômica do EOS. O custo operacional (OPEX) de manter sistemas legados pós-garantia supera rapidamente o CAPEX de modernização quando ajustado ao risco.
A decisão de manter hardware em EOS sob contratos de manutenção de terceiros (TPM) introduz um risco de segurança não quantificado nos modelos tradicionais de TCO (Total Cost of Ownership). Em 2025, a vulnerabilidade de firmwares não patcheados em controladores de armazenamento tornou-se um vetor primário para ataques de ransomware que visam a criptografia na camada de bloco. O custo operacional (OPEX) de mitigar esses riscos, somado ao prêmio de risco de uma indisponibilidade prolongada por falta de peças sobressalentes, inverte a lógica econômica. Manter o legado torna-se matematicamente mais custoso do que a aquisição de nova tecnologia, uma vez que ajustamos a equação pelo risco de perda de dados e tempo de inatividade.
A Lei da Escalabilidade Universal (USL) Aplicada ao Storage Antigo
Para compreender verdadeiramente por que o upgrade é imperativo, devemos aplicar a Lei da Escalabilidade Universal (USL), formulada para descrever como a capacidade do sistema responde ao aumento de carga. A equação da USL é definida como:
$$C(N) = \frac{N}{1 + \alpha(N-1) + \beta N(N-1)}$$
Onde $N$ é a carga (ou usuários concorrentes), $\alpha$ representa o custo de serialização (contenda por recursos compartilhados) e $\beta$ representa o custo de coerência (a latência necessária para que os dados sejam consistentes entre os nós ou controladores).
Em sistemas de storage legados, especialmente aqueles baseados em arquiteturas de disco rotacional ou SSDs SAS antigos, os valores de $\alpha$ e $\beta$ são significativamente altos. O parâmetro $\beta$ é particularmente destrutivo. Ele descreve o "crosstalk" ou a sobrecarga de comunicação entre os processos para manter a integridade dos dados.
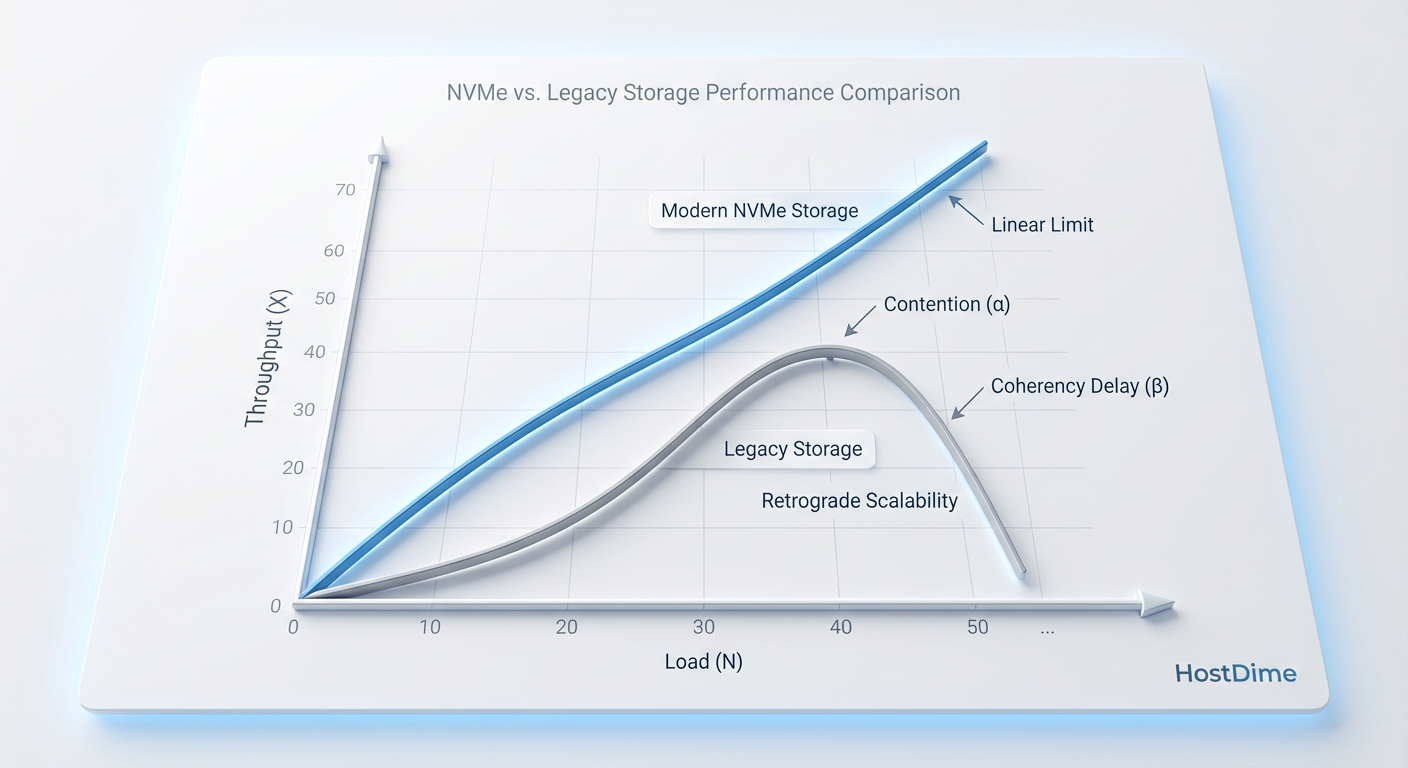 Figura: Fig. 1: A Lei da Escalabilidade Universal (USL) demonstrando o 'Retrograde Scaling'. Em hardware legado, o custo de coerência (β) causa degradação de performance sob carga, não apenas saturação.
Figura: Fig. 1: A Lei da Escalabilidade Universal (USL) demonstrando o 'Retrograde Scaling'. Em hardware legado, o custo de coerência (β) causa degradação de performance sob carga, não apenas saturação.
O gráfico da USL nos mostra um fenômeno conhecido como Retrograde Scaling. Diferente da saturação simples, onde a performance se estabiliza, em sistemas com alto $\beta$, adicionar mais carga (ou tentar extrair mais IOPS) faz com que o throughput total do sistema diminua. O sistema gasta mais ciclos de CPU gerenciando filas e bloqueios (locks) do que processando I/O útil.
Sistemas modernos baseados em NVMe e arquiteturas paralelas massivas são projetados matematicamente para minimizar $\alpha$ e $\beta$, empurrando o ponto de inflexão para muito além das demandas atuais. Insistir em hardware antigo é lutar contra uma equação quadrática onde o termo negativo $\beta N^2$ domina o denominador, garantindo o colapso da performance sob carga de pico.
O Custo da Latência: Modelando o Impacto Financeiro da Inércia
A latência é o imposto invisível sobre a eficiência operacional. Em termos de modelagem de capacidade, a latência não deve ser vista apenas como "tempo de espera", mas como "tempo de ocupação de recurso". Uma transação que leva 10ms para ser concluída ocupa memória, threads de processamento e conexões de rede por dez vezes mais tempo do que uma que leva 1ms.
Isso cria um efeito cascata. Se o subsistema de armazenamento é o gargalo, ele força a camada de aplicação a manter estados abertos por mais tempo, o que por sua vez infla o consumo de memória nos servidores de aplicação e aumenta o custo de licenciamento de software que é cobrado por núcleo (vCore), já que os núcleos ficam ocupados esperando por I/O (I/O Wait).
Estudos de mercado de 2024 indicam que a latência de armazenamento é diretamente correlacionada com a taxa de abandono em aplicações de e-commerce e com a ineficiência em pipelines de treinamento de IA. Ao modelar o ROI de um upgrade de storage, o planejador de capacidade deve incluir o ganho de eficiência em toda a stack. Reduzir a latência de I/O em uma ordem de magnitude (de ms para $\mu$s) frequentemente libera capacidade de computação suficiente para adiar a compra de novos servidores, alterando completamente a análise de custo-benefício. O custo da inércia — não fazer nada — é o custo acumulado de todos os recursos computacionais desperdiçados em estados de espera.
Estratégia de Migração: A Física da Gravidade dos Dados
O planejamento de um upgrade de storage enfrenta um obstáculo físico imutável: a gravidade dos dados. Dados possuem "massa", e a velocidade com que podemos movê-los é limitada pela largura de banda e pela latência. Quanto maior o conjunto de dados, maior a sua gravidade e mais difícil é movê-lo sem causar interrupções.
O erro mais comum em projetos de substituição de EOL é subestimar o tempo de migração. Se um array legado possui 500 TB de dados e opera a uma taxa de transferência efetiva de 500 MB/s (considerando que ele ainda precisa atender à produção), a migração levaria teoricamente cerca de 12 dias ininterruptos. No entanto, sistemas próximos da saturação ou em estado de degradação não conseguem sustentar essa taxa.
 Figura: Fig. 3: O Horizonte de Eventos da Migração. O planejamento deve considerar a latência de aquisição e a física da transferência de dados, garantindo que o 'Cutover' ocorra antes da zona de perigo do EOS.
Figura: Fig. 3: O Horizonte de Eventos da Migração. O planejamento deve considerar a latência de aquisição e a física da transferência de dados, garantindo que o 'Cutover' ocorra antes da zona de perigo do EOS.
Existe um "Horizonte de Eventos" na migração. Se você esperar até que o sistema legado esteja a 95% de capacidade ou sofrendo de Retrograde Scaling para iniciar a migração, o overhead adicional do processo de cópia de dados será o golpe de misericórdia que derrubará a produção. A leitura intensiva necessária para a migração compete com as gravações da produção, elevando o $\beta$ (custo de coerência) a níveis críticos.
O planejamento deve calcular o Cutover Point ideal, que deve ocorrer meses antes do EOS oficial. A janela de migração deve ser modelada considerando a degradação de performance do hardware antigo durante o processo de extração de dados. A física dita que você precisa de "gordura" de performance para sair do buraco; se você esperar até estar no fundo dele, a energia necessária para escapar será infinita.
O Princípio da Capacidade Preditiva
A gestão de capacidade no contexto de EOL/EOS não é sobre comprar discos; é sobre gerenciar riscos matemáticos. A decisão de upgrade deve ser guiada por modelos preditivos que considerem a não-linearidade da escalabilidade (USL), a probabilidade crescente de falha catastrófica e o custo econômico da latência sistêmica.
Não espere pelo "cliff" ou pelo abismo de recursos. Os dados mostram que quando os sintomas de degradação se tornam perceptíveis ao usuário final, o sistema já ultrapassou o ponto de recuperação econômica. A atualização tecnológica é, portanto, uma equação de sobrevivência. Os parâmetros $\alpha$ e $\beta$ não negociam, e a gravidade dos dados não perdoa atrasos. Execute a regressão, determine seus coeficientes e inicie a migração enquanto a física ainda está a seu favor.

Roberto Sato
Planejador de Capacidade
"Traduzo métricas de consumo em modelos de crescimento sustentável. Minha missão é antecipar gargalos e garantir que sua infraestrutura escale matematicamente antes de atingir o limite crítico."