A matemática do estado estacionário: como o protocolo SNIA PTS invalida benchmarks viciados em SSDs NVMe

Descubra por que benchmarks de marketing falham em data centers. Entenda como o preconditioning do SNIA PTS revela a verdadeira performance de SSDs NVMe.
A indústria de armazenamento corporativo sofre de uma epidemia de otimismo matemático. Quando você abre o datasheet de um novo SSD NVMe, os números de IOPS (operações de entrada e saída por segundo) e largura de banda parecem desafiar as leis da física. O problema é que essas métricas são invariavelmente capturadas no estado FOB (Fresh Out of Box). É o equivalente a medir a velocidade máxima de um carro esportivo em queda livre no vácuo.
Para arquitetos de infraestrutura, administradores de banco de dados e engenheiros de storage, o desempenho nos primeiros cinco minutos de uso é irrelevante. O que sustenta um cluster de virtualização ou um banco de dados transacional de alta densidade é o comportamento do disco após horas, dias e meses de punição contínua. É aqui que a ilusão do marketing desmorona e a matemática do estado estacionário (steady state) assume o controle.
Resumo em 30 segundos
- O desempenho de pico de um SSD NVMe reflete apenas o estado FOB, mascarando a degradação real sob cargas de trabalho contínuas.
- O esgotamento do cache SLC e a ativação do Garbage Collection forçam o controlador a dividir recursos, derrubando os IOPS drasticamente.
- O protocolo SNIA PTS exige um preconditioning rigoroso, garantindo que as medições ocorram apenas quando a variação de desempenho for matematicamente estável.
O colapso silencioso de IOPS após os primeiros minutos de gravação
Quando um SSD NVMe sai da caixa ou sofre um apagamento seguro (Secure Erase), todos os seus blocos NAND estão vazios e prontos para receber dados. O controlador não precisa se preocupar com a realocação de páginas antigas ou com a limpeza de blocos sujos. O caminho de gravação é direto e desimpedido.
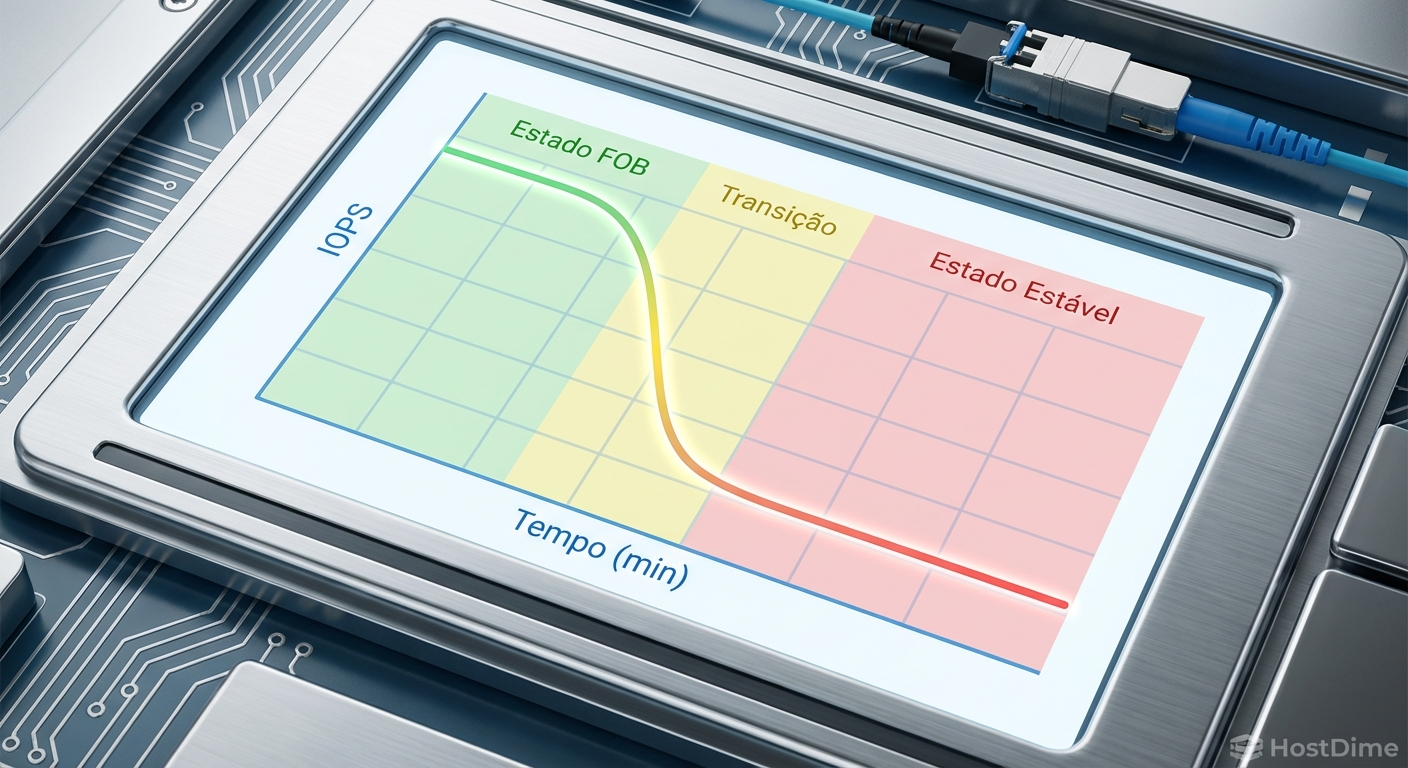 Figura: Gráfico ilustrando a queda drástica de IOPS do estado FOB para o estado estacionário.
Figura: Gráfico ilustrando a queda drástica de IOPS do estado FOB para o estado estacionário.
No entanto, à medida que a capacidade do disco é preenchida, a física da memória flash NAND cobra seu preço. Diferente de um disco rígido magnético (HDD) que pode simplesmente sobrescrever dados antigos, um SSD precisa apagar um bloco inteiro antes de poder gravar novos dados em uma página específica. Esse processo assimétrico cria um gargalo fundamental na arquitetura de armazenamento de estado sólido.
O colapso ocorre de forma abrupta. Em testes de gravação aleatória 4K, é comum ver um drive NVMe despencar de 500.000 IOPS para meros 80.000 IOPS em questão de minutos. A latência de cauda (tail latency), que mede os piores tempos de resposta no percentil 99.9%, dispara de microsegundos para dezenas de milissegundos. Para um hypervisor aguardando a confirmação de gravação de uma máquina virtual, esse atraso é catastrófico.
A exaustão do cache SLC e o impacto do garbage collection
Para mascarar a lentidão inerente das memórias TLC (Triple-Level Cell) e QLC (Quad-Level Cell), os fabricantes utilizam uma técnica chamada cache pseudo-SLC. Uma porção da memória flash é programada para armazenar apenas um bit por célula, operando em velocidades altíssimas. Enquanto esse buffer tiver espaço, o disco parece imbatível.
O problema em ambientes de data center é que cargas de trabalho contínuas esgotam esse cache rapidamente. Quando o buffer enche, o controlador NVMe entra em pânico arquitetônico. Ele precisa gravar os novos dados diretamente na lenta memória TLC/QLC e, simultaneamente, esvaziar o cache SLC movendo os dados antigos para o armazenamento definitivo.
💡 Dica Pro: Em ambientes de banco de dados intensivos em gravação, desative o cache de gravação do sistema operacional e confie em SSDs de classe enterprise (como os formatos U.2 ou E1.S) que possuem proteção contra perda de energia (PLP) e não dependem de truques de cache SLC para manter a consistência.
Neste exato momento, o Garbage Collection (GC) entra em ação. O controlador precisa ler blocos parcialmente válidos, reescrever os dados úteis em novos blocos e apagar os blocos antigos. Isso gera a temida amplificação de gravação (write amplification). O processador do SSD, que antes apenas recebia dados do barramento PCIe, agora gasta a maior parte de seus ciclos de clock movendo dados internamente. O desempenho despenca porque o disco está lutando contra si mesmo.
 Figura: Diagrama do controlador NVMe lidando com o esgotamento do cache SLC e o Garbage Collection simultâneo.
Figura: Diagrama do controlador NVMe lidando com o esgotamento do cache SLC e o Garbage Collection simultâneo.
Por que testes sintéticos curtos mascaram a degradação real
Ferramentas populares de benchmark de desktop são veneno para a engenharia de storage corporativo. Softwares que gravam um arquivo de teste de 1GB ou 5GB operam inteiramente dentro da zona de conforto do cache SLC e da RAM do sistema. Eles medem a velocidade da interface PCIe e do buffer, não a capacidade real da mídia de armazenamento.
Além disso, muitos revisores cometem o erro primário de executar um Secure Erase entre cada rodada de testes. Isso reseta o disco para o estado FOB, garantindo que o Garbage Collection nunca seja acionado durante a medição. É uma metodologia viciada que produz gráficos bonitos, mas que falha miseravelmente em prever como o disco se comportará em um servidor de produção rodando ZFS ou vSAN.
Para entender a gravidade dessa diferença, precisamos categorizar os estados operacionais do disco.
| Métrica | Estado FOB (Fresh Out of Box) | Transição (Degradação) | Estado Estacionário (Steady State) |
|---|---|---|---|
| IOPS de Gravação | Máximo (Pico de Marketing) | Queda acentuada e errática | Baixo, porém consistente |
| Latência (99.9%) | < 100 microsegundos | Picos imprevisíveis (> 50ms) | Estável, reflete a mídia real |
| Carga do Controlador | Baixa (Apenas I/O direto) | Extrema (I/O + GC + Wear Leveling) | Alta, mas equilibrada |
| Validade do Teste | Nula para Enterprise | Útil apenas para dimensionar cache | Única métrica válida para Datacenter |
A matemática do preconditioning e os critérios do protocolo SNIA PTS
Para eliminar o ruído do marketing, a SNIA (Storage Networking Industry Association) desenvolveu a especificação PTS (Solid State Storage Performance Test Specification). O coração deste protocolo não é a medição em si, mas a tortura prévia aplicada ao disco, conhecida como Preconditioning.
O preconditioning não é um simples aquecimento. É um ataque matemático projetado para forçar o disco ao seu pior cenário possível. A especificação exige que o disco seja preenchido com dados aleatórios até o dobro de sua capacidade total (2x a capacidade do usuário). Se você tem um SSD de 3.2TB, o script de teste gravará 6.4TB de dados aleatórios ininterruptamente antes de iniciar qualquer cronômetro de benchmark.
Esse processo garante que todos os blocos lógicos estejam mapeados para blocos físicos, que o cache SLC esteja completamente saturado e que o algoritmo de Garbage Collection esteja operando em sua capacidade máxima. Apenas quando o disco está se afogando em suas próprias rotinas de manutenção interna é que a verdadeira medição começa.
Validando a janela de medição para garantir a estabilidade
Atingir o estado estacionário não é um palpite visual em um gráfico. O protocolo SNIA PTS exige uma validação matemática rigorosa chamada de Janela de Medição (Measurement Window).
Durante o teste contínuo, o software coleta pontos de dados (IOPS ou largura de banda) em intervalos regulares, geralmente a cada minuto. Para que o disco seja oficialmente declarado em estado estacionário, ele deve satisfazer duas condições matemáticas simultâneas em uma janela de tempo específica (frequentemente as últimas 5 rodadas de teste):
Excursão Máxima: A diferença entre o maior e o menor valor medido dentro da janela não pode exceder 20% da média da própria janela.
Declive da Curva: A inclinação da linha de tendência linear calculada através dos pontos de dados na janela deve estar próxima de zero (variação máxima de 10%).
⚠️ Perigo: Se um fabricante fornece números de estado estacionário sem publicar o log de convergência da janela de medição, desconfie. Discos com firmware mal otimizado podem oscilar violentamente (efeito serrote) e nunca atingir a conformidade matemática exigida pela SNIA.
Se a linha de tendência ainda estiver caindo, o disco continua na fase de transição. O teste deve continuar rodando, às vezes por 12 ou 24 horas, até que a matemática prove que o desempenho parou de degradar e encontrou seu piso absoluto.
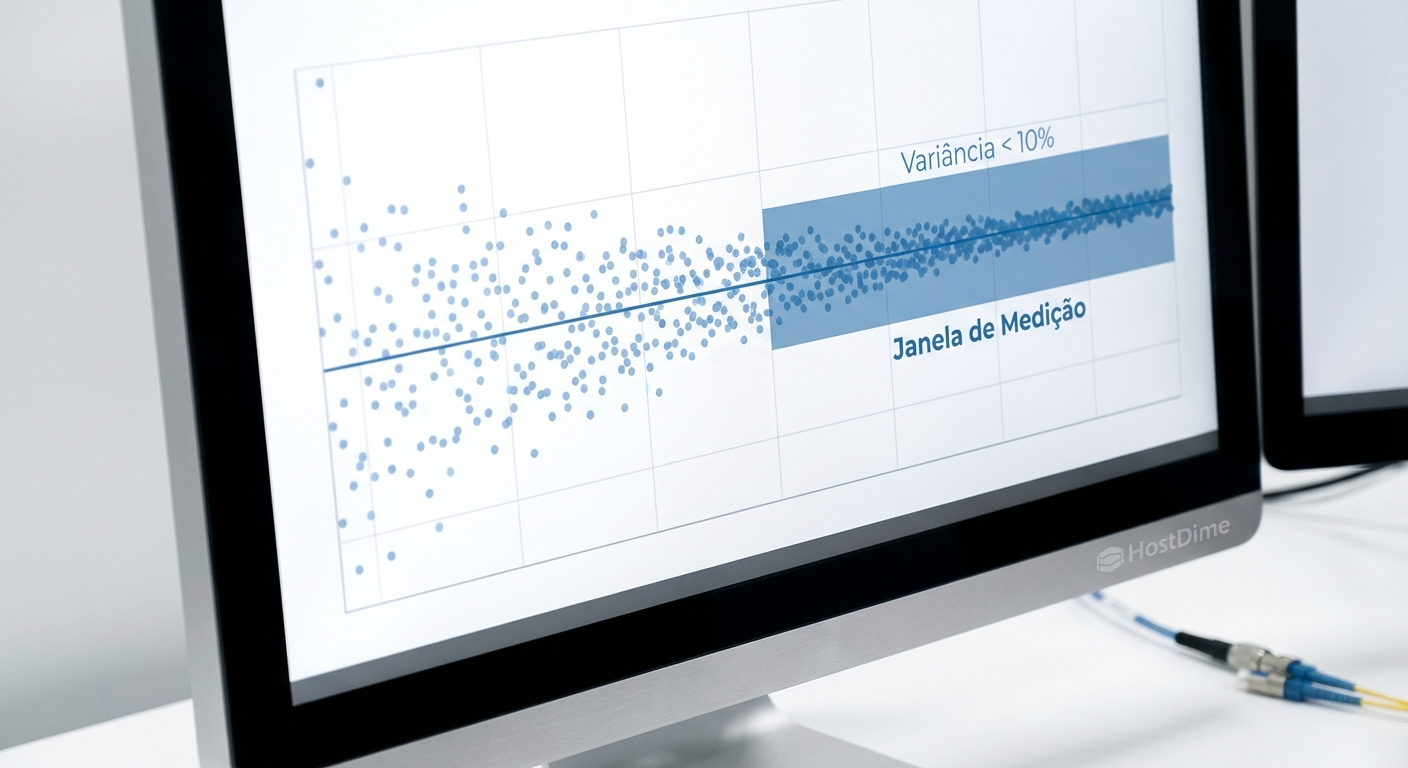 Figura: Gráfico de convergência matemática mostrando os pontos de dados entrando na janela de medição exigida pela SNIA.
Figura: Gráfico de convergência matemática mostrando os pontos de dados entrando na janela de medição exigida pela SNIA.
O veredito da infraestrutura: pare de comprar ilusões
Projetar uma infraestrutura de armazenamento baseada em números FOB é a receita garantida para incidentes de latência em produção. Quando um cluster de banco de dados atinge seu pico de utilização na Black Friday ou no fechamento contábil, os SSDs não estarão vazios e descansados. Eles estarão fragmentados, cheios e lutando contra o Garbage Collection.
A adoção de metodologias rigorosas como o SNIA PTS não é apenas um preciosismo de laboratório. É a única forma de garantir que o hardware entregue a previsibilidade exigida por SLAs corporativos. Ao avaliar novos fornecedores de NVMe, exija os relatórios de estado estacionário. Ignore os picos de marketing e concentre-se no piso de desempenho. Na engenharia de storage, o verdadeiro valor de um disco não é o quão rápido ele consegue correr nos primeiros metros, mas a velocidade que ele consegue sustentar quando o sistema inteiro está sob pressão máxima.
Referências & Leitura Complementar
SNIA Solid State Storage (SSS) Performance Test Specification (PTS) v2.0.1: Documentação oficial detalhando os requisitos matemáticos para preconditioning e validação de estado estacionário.
JEDEC JESD218: Padrão para requisitos e métodos de teste de resistência de unidades de estado sólido (SSD), focando nas diferenças entre cargas de trabalho de cliente e enterprise.
NVM Express Base Specification 2.0: Documentação técnica da arquitetura NVMe, detalhando o comportamento do controlador e comandos de gerenciamento de namespace.
O que é o estado estacionário (steady state) em um SSD NVMe?
É a fase de operação onde o SSD atinge um nível de desempenho consistente e previsível. Isso ocorre apenas após o preenchimento total do disco e a ativação contínua dos processos internos de garbage collection e wear leveling sob carga pesada, refletindo o verdadeiro piso de performance do hardware.Por que ferramentas comuns de benchmark não servem para testar SSDs de servidores?
Ferramentas tradicionais de desktop executam testes curtos que medem apenas o desempenho do cache SLC vazio (estado FOB - Fresh Out of Box). Elas ignoram completamente a degradação severa de IOPS e o aumento exponencial de latência que ocorrem sob cargas de trabalho contínuas em ambientes enterprise.O que significa preconditioning no contexto do protocolo SNIA PTS?
Preconditioning é a etapa preparatória obrigatória onde o SSD é submetido a gravações sequenciais e aleatórias extremas. O objetivo é gravar o dobro de sua capacidade total (2x a capacidade do usuário) em um curto período, forçando o controlador a lidar com blocos sujos e esgotamento de cache antes de qualquer medição oficial de benchmark.
Dr. Elena Kovic
Metodologista de Benchmark
"Desmonto o marketing com análise estatística rigorosa. Meus benchmarks isolam cada variável para revelar a performance crua e sem filtros do hardware corporativo."