A morte das médias: rastreando latência de I/O com eBPF

Descubra por que o iostat esconde a verdade sobre seu storage. Aprenda a usar eBPF, biolatency e biosnoop para visualizar a latência de cauda no Linux.
Se você gerencia armazenamento — seja um array All-Flash NVMe em um datacenter ou um pool ZFS no seu homelab — existe uma verdade desconfortável que você precisa aceitar: a média é uma mentira.
Você já passou por isso. O banco de dados está lento, a aplicação está reclamando de timeouts, mas quando você roda o iostat, ele mostra uma latência média de 0.5ms e utilização de disco abaixo de 20%. O painel de monitoramento está verde. O disco diz que está tudo bem. Mas o usuário diz que o sistema está quebrado.
Quem está mentindo? Ninguém. O problema é que você está usando uma métrica do século passado para diagnosticar problemas de hoje. A média esconde os crimes do sistema. Ela pega aquele único I/O que demorou 500ms (e travou a transação crítica) e o dilui em milhares de operações de 0.1ms, resultando em um número "aceitável".
Para ver o invisível, precisamos parar de amostrar e começar a rastrear. É aqui que entra o eBPF.
Resumo em 30 segundos
- Médias escondem a realidade: Em sistemas de armazenamento, a latência não segue uma curva normal. Picos de latência (outliers) são invisíveis em médias, mas são eles que matam a performance da aplicação.
- eBPF é o microscópio: Diferente de ferramentas antigas que apenas leem contadores, o eBPF permite executar código seguro dentro do kernel para medir cada operação de I/O individualmente.
- Histogramas são essenciais: Substitua gráficos de linha por mapas de calor (heatmaps) e histogramas. Eles revelam se a lentidão é constante ou esporádica, algo impossível de ver com
iostat.
O mistério das aplicações lentas em discos ociosos
A intuição clássica de sysadmin diz: "Se o disco não está 100% ocupado, a lentidão não é o disco". Isso estava correto na era dos HDDs mecânicos, onde a física da agulha limitava tudo. Em um mundo de SSDs NVMe e Optane, a fila (queue) pode estar vazia 99% do tempo, mas se o Garbage Collection do SSD decidir rodar exatamente durante um commit de log crítico, você terá uma latência de cauda (tail latency) brutal.
O problema das ferramentas padrão (como sar, iostat, vmstat) é a resolução. Elas geralmente coletam dados a cada 1 ou 10 segundos. Um SSD moderno pode processar 500.000 IOPS. Uma amostra de 1 segundo é uma eternidade. É como tentar entender o enredo de um filme assistindo a um único frame a cada 10 minutos.
 Figura: A ilusão da média: o gráfico da esquerda mostra o que o iostat vê; o da direita mostra o que a aplicação sente.
Figura: A ilusão da média: o gráfico da esquerda mostra o que o iostat vê; o da direita mostra o que a aplicação sente.
A distribuição multimodal
Em storage, a latência quase nunca é uma curva de sino (distribuição normal). Ela é multimodal:
Cache Hits: Respostas ultra-rápidas (microssegundos) vindas da RAM ou cache do controlador.
Flash Reads: Latência padrão da NAND (ex: 80-100us).
Outliers: Retentativas, bloqueios de software, throttling térmico ou garbage collection (milissegundos ou segundos).
Quando você tira a média desses três modos, você cria um número que não representa nenhum deles. O número médio é um fantasma matemático que não existe na realidade física do seu servidor.
A jornada de uma syscall: onde o tempo é gasto?
Para rastrear a latência, precisamos entender o caminho. Quando uma aplicação faz um write(), não é mágica.
VFS (Virtual File System): A chamada entra no kernel. Aqui temos locks de sistema de arquivos (inode mutex).
Block Layer: O I/O é enfileirado, talvez fundido (merged) com outros pedidos adjacentes. O agendador de I/O (BFQ, Kyber, None) atua aqui.
Driver (NVMe/SCSI): O pedido é formatado para o protocolo do hardware e colocado na fila de submissão do dispositivo.
Dispositivo: O SSD executa a operação física.
Ferramentas tradicionais medem o tempo "médio" que o pedido ficou na fila. O eBPF nos permite medir o tempo exato que cada I/O gastou em cada uma dessas etapas.
💡 Dica Pro: Se a latência é alta no VFS mas baixa no Block Layer, o problema é software (ex: fragmentação do sistema de arquivos ou contenção de locks), não o disco físico. Trocar o SSD por um mais rápido não resolverá nada.
Instrumentação dinâmica com eBPF
O eBPF (Extended Berkeley Packet Filter) é a maior revolução em observabilidade Linux da última década. Pense nele como uma máquina virtual leve e segura dentro do kernel. Ele permite que você escreva pequenos programas que são executados em eventos específicos (como uma função do kernel sendo chamada) sem precisar recompilar o kernel ou carregar módulos perigosos que podem causar kernel panic.
Antigamente, para rastrear cada I/O, usávamos blktrace. O problema do blktrace é que ele despeja eventos para o espaço do usuário (user-space) para serem processados. Em um disco NVMe rápido, isso gera gigabytes de logs em segundos e consome tanta CPU que a própria ferramenta causa lentidão. Isso é o "Efeito do Observador" destruindo sua análise.
O eBPF resolve isso processando os dados dentro do kernel. Ele cria o histograma na memória do kernel e envia para o usuário apenas o resumo final (o mapa de bits), consumindo recursos insignificantes.
 Figura: Arquitetura de observabilidade eBPF: processamento no kernel para overhead mínimo.
Figura: Arquitetura de observabilidade eBPF: processamento no kernel para overhead mínimo.
Ferramentas do BCC (BPF Compiler Collection)
Não precisamos escrever código C ou Assembly eBPF do zero. O projeto BCC (liderado por engenheiros como Brendan Gregg) nos dá ferramentas prontas. As duas principais para storage são:
1. biolatency
Esta ferramenta mede o tempo desde a emissão do I/O para o dispositivo até a sua conclusão. Em vez de imprimir cada evento, ela armazena as latências em "buckets" (baldes) de potência de 2.
Exemplo de saída (simplificado):
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 12 | |
16 -> 31 : 452 |** |
32 -> 63 : 12895 |****************************************|
64 -> 127 : 3241 |********** |
128 -> 255 : 52 | |
256 -> 511 : 2 | |
512 -> 1023 : 0 | |
1024 -> 2047 : 1 | |
Veja o outlier na linha 1024 -> 2047. Houve um I/O que demorou entre 1 e 2ms. O iostat teria ignorado isso. Se esse I/O fosse o commit do log de transação do seu banco SQL, você teria um usuário reclamando.
2. biosnoop
Enquanto o biolatency agrega, o biosnoop imprime cada operação de I/O individualmente em tempo real, com detalhes de qual processo (PID/COMM) a solicitou.
⚠️ Perigo: Use o
biosnoopcom cautela em produção. Em sistemas com centenas de milhares de IOPS, imprimir uma linha de texto por I/O pode saturar o terminal e a CPU. Prefira semprebiolatencypara diagnóstico inicial.
Tabela Comparativa: O velho vs. O novo
| Característica | iostat (Legado) | biolatency (eBPF) | biosnoop (eBPF) |
|---|---|---|---|
| Métrica Principal | Média (Avg Wait) | Histograma / Distribuição | Evento Individual |
| Visibilidade de Outliers | Nula (escondidos na média) | Alta (mostra cauda longa) | Total (detalhe por evento) |
| Overhead | Muito Baixo | Muito Baixo | Médio/Alto (depende do IOPS) |
| Contexto | Apenas Dispositivo | Dispositivo + Latência | Processo + Latência + Tipo |
| Uso Ideal | Monitoramento de Capacidade | Diagnóstico de Performance | Auditoria Forense |
Transformando logs em mapas de calor
Ler texto no terminal é útil, mas humanos são visuais. A melhor forma de visualizar dados de latência de storage é através de Mapas de Calor (Heatmaps).
Em um heatmap de latência:
Eixo X: Tempo (passar das horas).
Eixo Y: Latência (microssegundos/milissegundos).
Cor: Intensidade (quantidade de I/Os naquela latência).
Imagine que você vê uma faixa horizontal sólida na parte inferior (latência baixa) — isso é o funcionamento normal. De repente, você vê "nuvens" ou "fumaça" subindo no gráfico a cada 5 minutos. Isso indica que, periodicamente, alguns I/Os estão ficando lentos.
Isso permite correlações imediatas. "Ah, essa fumaça de latência acontece exatamente quando o cron job de backup do ZFS inicia". Com médias, você veria apenas uma pequena elevação na linha, fácil de ignorar. Com heatmaps, o padrão grita na sua cara.
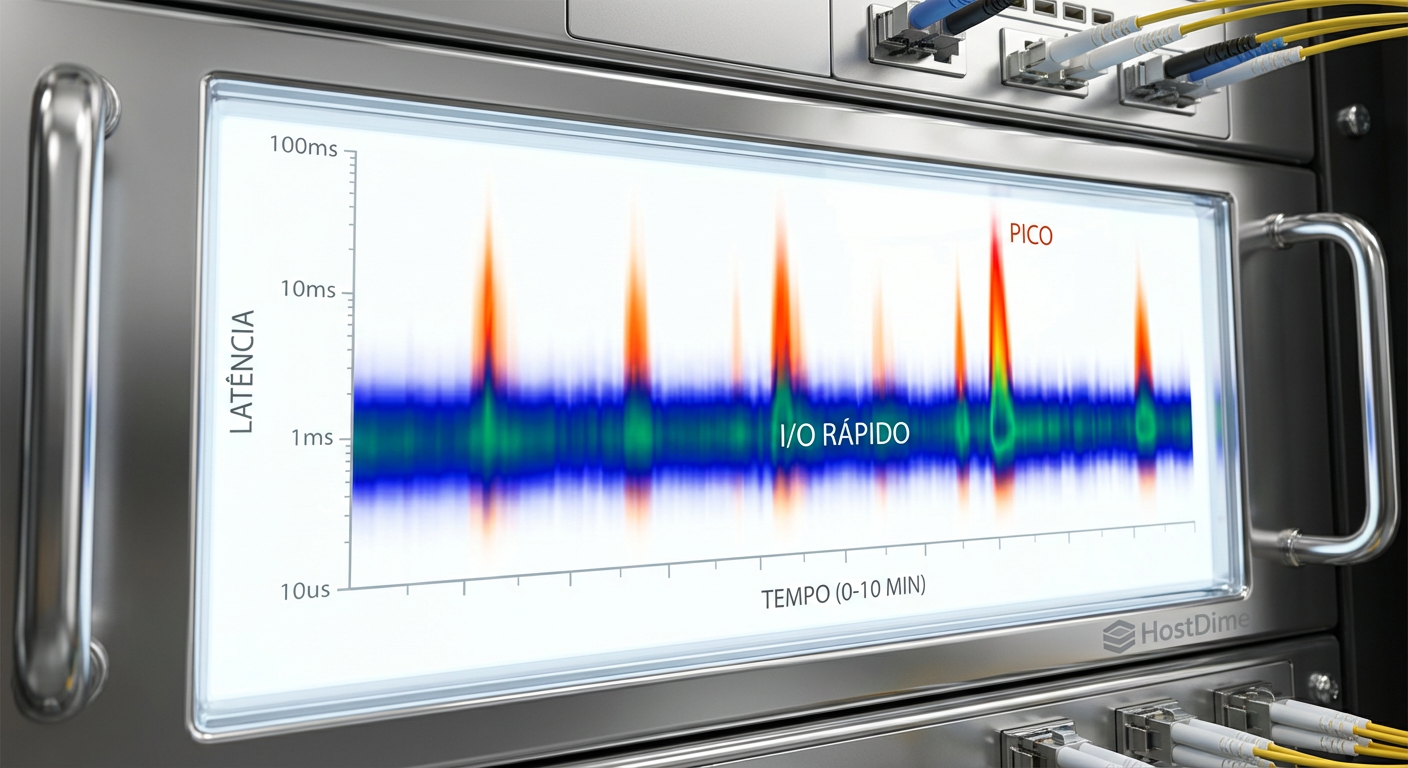 Figura: Mapa de calor revelando latência intermitente que seria invisível em gráficos de linha.
Figura: Mapa de calor revelando latência intermitente que seria invisível em gráficos de linha.
Estudo de caso: O SSD mentiroso
Recentemente, investiguei um servidor de banco de dados onde as consultas ficavam lentas aleatoriamente. O iostat mostrava latência média de 0.2ms. O fabricante do SSD NVMe jurava que o disco estava saudável.
Rodamos o biolatency -m (em milissegundos). O histograma mostrou:
99% dos I/Os: < 1ms.
0.5% dos I/Os: 250ms - 500ms.
Isso é meio segundo! Para um computador, meio segundo é uma era geológica. Investigando mais a fundo com biosnoop, vimos que esses I/Os lentos eram sempre escritas (W). Cruzando com logs do controlador, descobrimos que o SSD estava entrando em um ciclo agressivo de thermal throttling (redução de clock por temperatura) por frações de segundo, invisível nos sensores de temperatura que reportam médias a cada minuto.
Sem eBPF, estaríamos trocando cabos e culpando a rede até hoje.
O futuro é observável
A era de monitorar "se o disco está cheio" acabou. O armazenamento moderno é complexo, com camadas de abstração, virtualização e hardware inteligente. As médias foram úteis quando a variação de performance era pequena. Hoje, a diferença entre um cache hit e um acesso à flash congestionada é de 1000x.
Se você quer ser um engenheiro sério sobre performance de dados, você precisa abandonar as médias. Instale o pacote bpfcc-tools (ou bcc-tools) na sua distro Linux. Comece a rodar biolatency quando sentir que algo está estranho.
Pare de perguntar "qual é a latência média?". Comece a perguntar "onde está a latência de cauda?". É lá que seus problemas — e suas soluções — estão escondidos.
Referências & Leitura Complementar
Brendan Gregg's Blog: Referência mundial em performance e eBPF.
IO Visor Project: A casa do projeto BCC e ferramentas eBPF.
NVMe Specification (NVM Express): Para entender as filas e comandos de latência em nível de hardware.
Linux Kernel Source (block/blk-mq.c): Para os corajosos que querem ver como o Multi-Queue Block Layer funciona.
Perguntas Frequentes (FAQ)
Qual a diferença entre iostat e biolatency?
O iostat fornece médias baseadas em amostragem, o que esconde picos de latência (outliers) críticos para a performance percebida. O biolatency usa eBPF para rastrear cada operação de I/O individualmente no kernel, gerando um histograma preciso da distribuição de latência, permitindo ver o que a média esconde.O uso de eBPF causa overhead no servidor de produção?
Ferramentas modernas baseadas em eBPF (como biolatency) agregam dados dentro do kernel usando 'maps', gerando overhead insignificante e sendo seguras para produção. Já ferramentas que enviam cada evento para o user-space (como biosnoop) podem causar impacto em discos de altíssima performance (milhões de IOPS) e devem ser usadas com cautela.Como identificar se a latência é do disco ou do sistema de arquivos?
Compare os resultados do 'biolatency' (que mede no nível de bloco/driver) com ferramentas como 'ext4slower' ou 'xfsslower' (que medem no nível VFS). Se a latência alta aparece no VFS mas não no bloco, o problema é provavelmente lock de software, fragmentação ou contenção no sistema de arquivos, e não o hardware físico.
Lucas Ferreira
Engenheiro de Observabilidade
"Transformo o caos de logs, métricas e traces em clareza operacional. Minha missão é eliminar pontos cegos e garantir que nada permaneça invisível na infraestrutura."