A penalidade da reidratação: como appliances de deduplicação destroem o RTO na recuperação de VMs

Descubra por que seu appliance de deduplicação está estrangulando a performance da recuperação instantânea de VMs e como arquitetar um storage focado no restore real.
O backup é a maior mentira que os profissionais de TI contam a si mesmos para conseguir dormir à noite. A dura realidade, que costumo repetir até a exaustão, é que o backup não existe. A única coisa que importa, a única métrica que vai salvar o seu emprego quando o ransomware criptografar seu datacenter, é o restore.
E é exatamente no momento do restore que uma das tecnologias mais aclamadas da indústria de storage se revela um pesadelo silencioso. Os appliances de deduplicação, vendidos com a promessa de reduzir custos e economizar petabytes de espaço, escondem um segredo obscuro chamado penalidade de reidratação. Quando você precisa recuperar uma máquina virtual (VM) crítica em minutos, essa arquitetura pode transformar seu Recovery Time Objective (RTO) em uma piada de mau gosto.
Resumo em 30 segundos
- Appliances de deduplicação são otimizados para gravações sequenciais, mas a recuperação instantânea de VMs exige leituras aleatórias de altíssima performance.
- O processo de remontar blocos de dados espalhados (reidratação) esgota a CPU do storage e gera latências insustentáveis para o hypervisor.
- A solução definitiva exige uma arquitetura de duas camadas, utilizando uma "landing zone" sem deduplicação para os backups recentes e garantindo o RTO.
O desespero do boot infinito durante a recuperação instantânea
A cena é clássica em simulações de desastre. O servidor principal cai, o administrador abre a console do software de proteção de dados e aciona o recurso de Instant VM Recovery (IVMR). A promessa do IVMR é mágica: ligar a VM diretamente a partir do repositório de backup, sem precisar copiar os terabytes de dados de volta para o storage de produção (SAN ou NAS).
O hypervisor, seja VMware ESXi ou Microsoft Hyper-V, monta o datastore via NFS ou iSCSI e tenta dar o boot no sistema operacional convidado. É aí que o desespero começa. A tela do console da VM fica preta. O logotipo do Windows gira infinitamente. Os serviços de banco de dados apresentam falha por timeout de disco.
Isso acontece porque o hypervisor espera o comportamento de um storage de produção, que entrega blocos de dados com latência inferior a um milissegundo. No entanto, do outro lado do cabo de rede, o appliance de deduplicação está lutando pela própria vida para entender o que o hypervisor está pedindo.
⚠️ Perigo: Acreditar que a taxa de ingestão (gravação) do seu appliance reflete a velocidade de restauração (leitura) é o caminho mais rápido para o fracasso durante um desastre real.
A matemática cruel da reidratação de blocos no storage de destino
Para entender o gargalo, precisamos olhar para a engenharia por trás da economia de espaço. Quando um backup entra em um appliance com deduplicação inline, o controlador de storage quebra o fluxo de dados em blocos (chunks). Ele calcula um hash criptográfico para cada bloco e verifica em uma tabela de índices se aquele dado já existe nos discos.
Se o bloco for novo, ele é gravado. Se já existir, o storage grava apenas um ponteiro minúsculo referenciando o bloco original. Isso é brilhante para economizar discos rígidos (HDDs). O problema é o caminho inverso.
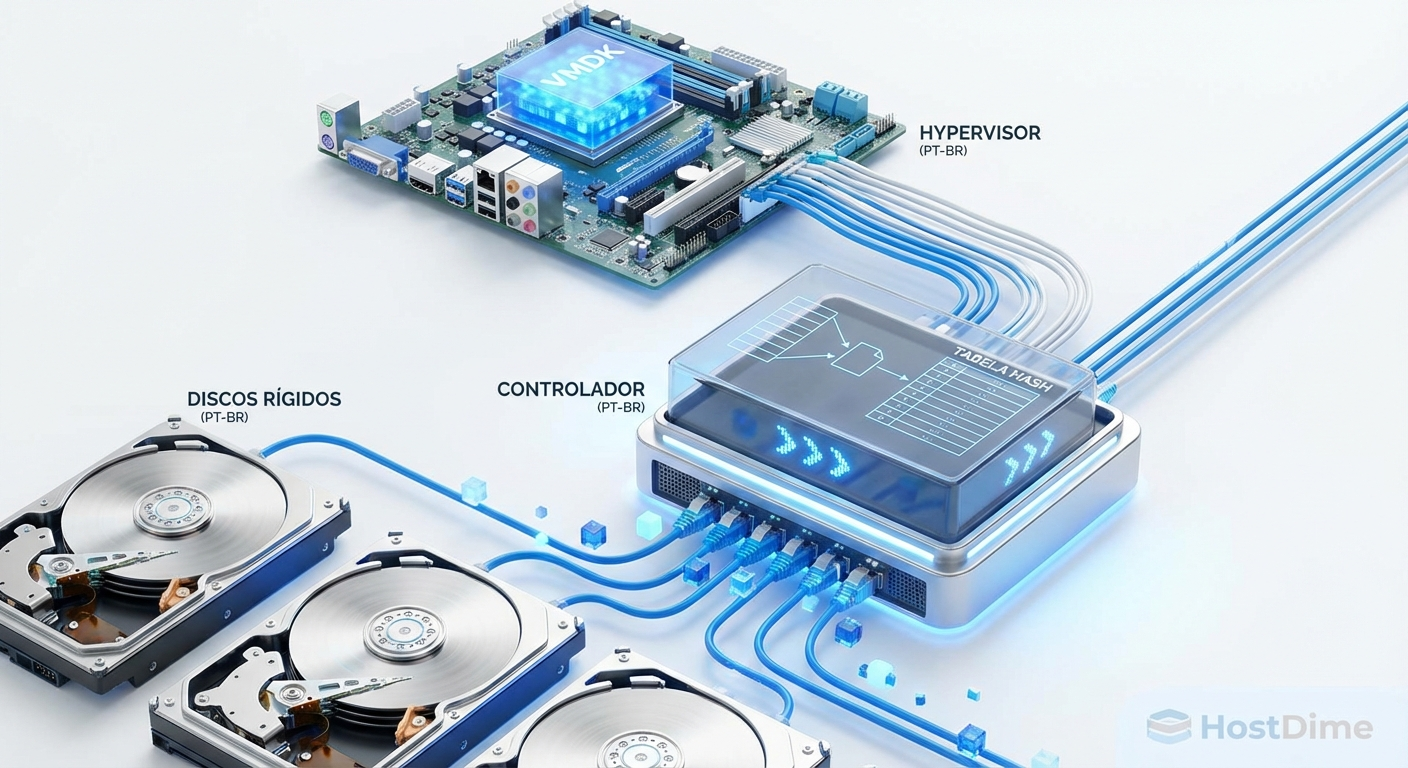 Figura: Diagrama ilustrando o processo de reidratação de dados, onde o controlador de storage busca blocos espalhados em discos físicos para remontar um arquivo de VM.
Figura: Diagrama ilustrando o processo de reidratação de dados, onde o controlador de storage busca blocos espalhados em discos físicos para remontar um arquivo de VM.
Quando o hypervisor pede para ler um arquivo de sistema operacional durante o boot, ele faz requisições de I/O aleatório (Random I/O). O appliance de backup precisa consultar a tabela de hash, encontrar os ponteiros, buscar os blocos físicos espalhados por dezenas de discos lentos, descompactar esses blocos e remontar o dado original na memória RAM.
Esse processo é a reidratação. A matemática é cruel: uma única requisição de leitura do hypervisor pode gerar dezenas de operações de busca (seeks) nos discos físicos do appliance. A latência dispara de 1 milissegundo para 50, 100 ou até 500 milissegundos. O sistema operacional da VM simplesmente desiste de esperar.
Por que adicionar cache SSD no appliance não resolve o gargalo da CPU
A resposta padrão de muitos fabricantes de hardware quando você reclama da lentidão no restore é sugerir um upgrade. Eles recomendam adicionar uma gaveta de discos de estado sólido (SSDs) ou drives NVMe (Non-Volatile Memory Express) para atuar como camada de cache de leitura no appliance.
Embora o flash resolva o problema da latência mecânica dos discos magnéticos, ele expõe o verdadeiro calcanhar de Aquiles da deduplicação: o processamento. A reidratação não é apenas um problema de I/O, é um problema computacional massivo.
Remontar milhares de blocos por segundo exige ciclos intensos de CPU e uma largura de banda de memória colossal. Mesmo que os SSDs entreguem os blocos deduplicados instantaneamente para a controladora, a CPU do storage se torna o gargalo ao tentar recalcular hashes e reconstruir a estrutura do arquivo em tempo real. Você apenas moveu o congestionamento de lugar.
| Característica | Appliance de Deduplicação (Archive) | Storage com Landing Zone (Restore) |
|---|---|---|
| Foco Principal | Retenção de longo prazo e custo por TB | RTO agressivo e performance de leitura |
| Padrão de I/O Ideal | Gravação sequencial contínua | Leitura e gravação aleatórias |
| Formato dos Dados | Deduplicado, compactado e fragmentado | Nativo, hidratado e pronto para uso |
| Performance de IVMR | Baixa (Alta latência de reidratação) | Alta (Latência de storage primário) |
| Custo de Armazenamento | Baixo (Alta taxa de redução de dados) | Médio/Alto (Sem redução agressiva) |
Arquitetura de landing zone e a separação entre retenção e recuperação
Se a deduplicação destrói o RTO, devemos abandonar os appliances? Absolutamente não. A regra 3-2-1 (três cópias dos dados, em duas mídias diferentes, com uma cópia fora do site) ainda é a lei suprema da sobrevivência. O erro está em tentar usar o mesmo hardware para retenção de longo prazo e para recuperação instantânea.
A solução definitiva adotada por arquitetos de infraestrutura paranoicos é a implementação de uma "Landing Zone" (Zona de Pouso). Trata-se de uma camada de storage intermediária, construída com discos rápidos (HDDs em RAID 10 ou SSDs de capacidade), configurada sem deduplicação ou compactação agressiva.
 Figura: Arquitetura de duas camadas mostrando a separação entre a Landing Zone para restores rápidos e o appliance de deduplicação para retenção de longo prazo.
Figura: Arquitetura de duas camadas mostrando a separação entre a Landing Zone para restores rápidos e o appliance de deduplicação para retenção de longo prazo.
Nesta arquitetura, os backups dos últimos 3 a 7 dias (que representam 95% das requisições de restore no mundo real) pousam primeiro nesta zona rápida. Como os dados já estão "hidratados" e em seu formato nativo, o hypervisor pode executar o Instant VM Recovery com performance quase idêntica à do storage de produção.
Após esse período de retenção curta, o software de backup move os dados mais antigos para o appliance de deduplicação. O appliance volta a fazer o que faz de melhor: esmagar dados frios para arquivamento de longo prazo, cumprindo requisitos de compliance sem atrapalhar a janela de recuperação crítica.
Testando o RTO real com scripts de validação automatizada de boot
Ter uma Landing Zone configurada é um excelente primeiro passo, mas a paranoia profissional exige provas. Você não tem um RTO garantido até que tenha testado a recuperação sob estresse. Confiar em um ícone verde de "Backup com Sucesso" é uma negligência inaceitável.
A única forma de garantir que a penalidade de reidratação não vai assombrar sua infraestrutura é implementar testes de recuperação automatizados. Ferramentas modernas de proteção de dados permitem criar ambientes isolados (sandboxes) diretamente no hypervisor, sem afetar a rede de produção.
💡 Dica Pro: Configure scripts que não apenas liguem a VM, mas que aguardem o boot do sistema operacional, verifiquem o heartbeat do VMware Tools ou Hyper-V Integration Services e executem consultas reais no banco de dados para validar a integridade da aplicação.
 Figura: Tela de monitoramento exibindo um fluxo automatizado de testes de recuperação de desastres, validando o boot e a aplicação de uma VM.
Figura: Tela de monitoramento exibindo um fluxo automatizado de testes de recuperação de desastres, validando o boot e a aplicação de uma VM.
Se o seu storage de backup estiver sofrendo com gargalos de leitura, esses scripts automatizados irão falhar por timeout. O sistema operacional vai demorar tanto para carregar os serviços que o script de validação abortará o processo. Essa falha controlada durante a madrugada é o alerta que você precisa para reestruturar seus discos antes que um desastre real aconteça.
O alerta definitivo para a sua estratégia de resiliência
O mercado de armazenamento de dados é movido por planilhas de custo por terabyte. Fabricantes adoram exibir taxas de redução de dados de 20:1 ou 50:1 em seus datasheets. No entanto, quando a sua infraestrutura principal vira fumaça, o conselho de administração da sua empresa não vai perguntar quanto espaço em disco você economizou. Eles vão perguntar em quantos minutos a operação voltará a faturar.
Projetar um repositório de backup focando apenas na ingestão e na deduplicação é construir um cofre fortificado onde a porta de saída é do tamanho de uma fechadura. Os dados estão seguros lá dentro, mas tirá-los de lá a tempo de salvar o negócio é fisicamente impossível.
Separe suas cargas de trabalho. Invista em discos rápidos e sem deduplicação para a sua janela operacional de recuperação imediata. Deixe a matemática complexa dos hashes e ponteiros para os dados históricos que ninguém tem pressa de acessar. Lembre-se sempre: o backup é apenas uma teoria reconfortante. O restore é a única realidade que importa.
Referências e leitura complementar
SNIA (Storage Networking Industry Association): Dictionary of Storage Networking Terminology (Definições oficiais sobre Data Deduplication e Rehydration).
NIST Special Publication 800-34 Rev. 1: Contingency Planning Guide for Federal Information Systems (Diretrizes sobre RTO e RPO).
VMware vSphere Documentation: Instant VM Recovery Storage Requirements and Best Practices (Requisitos de I/O para datastores NFS/iSCSI em recuperação).
O que é a penalidade de reidratação em storages de backup?
É o tempo e o poder de processamento exigidos para remontar os blocos de dados originais a partir de um pool deduplicado. Esse processo gera alta latência nas controladoras de storage, especialmente em operações de leitura aleatória que são estritamente necessárias para iniciar o sistema operacional de uma máquina virtual.Por que a recuperação instantânea (IVMR) falha ou fica lenta em appliances de deduplicação?
O recurso de Instant VM Recovery exige que o hypervisor faça leituras aleatórias intensas e de baixa latência diretamente do repositório de backup. Appliances de deduplicação são projetados para gravações sequenciais rápidas, mas sofrem um colapso de performance para buscar, descompactar e remontar ponteiros espalhados pelos discos em tempo real.Como resolver o problema de RTO sem abrir mão da economia de espaço da deduplicação?
A melhor prática de arquitetura é adotar um modelo de duas camadas. Utiliza-se uma "landing zone" com discos rápidos (como SSDs ou HDDs em RAID 10 sem deduplicação inline) para armazenar os backups dos últimos dias, garantindo restores instantâneos. O appliance de deduplicação é mantido, mas atua apenas como uma camada secundária de arquivamento a longo prazo.
Silvio Zimmerman
Operador de Backup & DR
"Vivo sob o lema de que backup não existe, apenas restore bem-sucedido. Minha religião é a regra 3-2-1 e meu hobby é desconfiar da integridade dos seus dados."