A tirania da média: por que o percentil 99 define a performance real do storage

Benchmarks de IOPS e latência média escondem a verdade sobre seu storage. Entenda a latência de cauda (p99), o impacto do Garbage Collection em SSDs e como medir o que realmente importa com FIO.
Você olha para o painel do Grafana ou Zabbix. A latência média de disco está em confortáveis 2ms. O throughput está longe de saturar o link SAS ou NVMe. No entanto, o telefone não para de tocar: o banco de dados está travando, a aplicação web está dando timeout e os usuários relatam lentidão intermitente.
Bem-vindo ao paradoxo da média aritmética em armazenamento de dados.
Na engenharia de storage, a média é uma mentira conveniente. Ela é uma métrica de marketing projetada para esconder a sujeira sob o tapete. Quando analisamos o comportamento de discos rígidos, e especialmente de SSDs modernos com algoritmos complexos de Garbage Collection, a performance não é uma linha reta; é um campo minado de interrupções microscópicas.
Se você projeta infraestrutura baseada em médias, você está projetando para a falha. O que define a experiência do usuário e a estabilidade de um cluster não é a velocidade que o disco entrega na maioria das vezes, mas sim o quão lento ele é quando decide parar de responder.
Resumo em 30 segundos
- A Média Esconde o Perigo: Uma latência média de 1ms pode coexistir com picos de 500ms que derrubam conexões de banco de dados, invisíveis em métricas padrão.
- O Efeito Dominó: Em arquiteturas distribuídas, um único disco lento (o "straggler") dita a velocidade de toda a transação, tornando o percentil 99 (p99) a única métrica segura.
- Metodologia Correta: Ferramentas como
iostatsuavizam os dados. Para diagnósticos reais, é necessário usar histogramas de latência e analisar p99, p99.9 e p99.99.
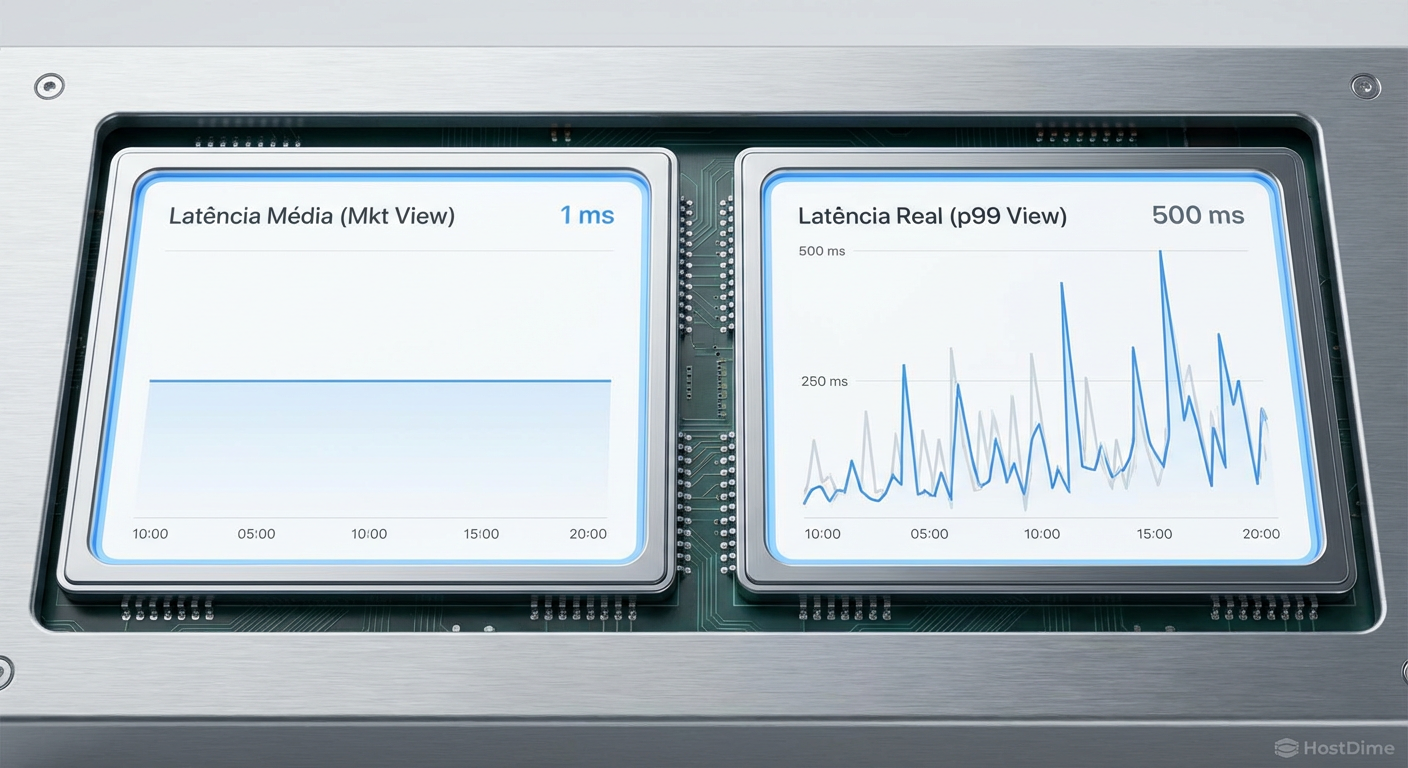 Figura: Comparativo visual: A ilusão da média estável versus a realidade caótica dos picos de latência capturados pelo p99.
Figura: Comparativo visual: A ilusão da média estável versus a realidade caótica dos picos de latência capturados pelo p99.
O engano estatístico: Por que a média é inútil para I/O
A distribuição de latência em sistemas de armazenamento não segue uma Curva de Gauss (distribuição normal). Ela tende a seguir uma distribuição de cauda longa (Long-Tail Distribution).
Imagine que você mede a latência de 100 operações de I/O (Input/Output).
99 operações levam 0.5ms.
1 operação leva 1000ms (1 segundo) devido a um bloqueio no controlador do SSD.
A média aritmética seria aproximadamente 10.5ms. Olhando para esse número, você pensaria: "10ms é aceitável para um HDD, talvez um pouco alto para SSD, mas o sistema deve estar rodando".
A realidade é brutalmente diferente: para 99% das requisições, o sistema voou. Mas para aquela 1 requisição crítica (que poderia ser o commit de uma transação financeira), o sistema congelou por um segundo inteiro. Se essa operação segurava um lock no banco de dados, todas as outras 99 operações rápidas ficaram presas na fila esperando o lock ser liberado.
A média diluiu o desastre. O percentil 99 (p99) teria mostrado 0.5ms, e o percentil 100 (Max Latency) mostraria 1000ms. O p99.9 expõe a verdade que a média esconde.
A matemática do caos: Amplificação de latência
O problema se agrava exponencialmente em arquiteturas modernas. Hoje, raramente lemos dados de um único disco. Em ambientes virtualizados (VMware vSAN, Proxmox Ceph) ou bancos de dados distribuídos (Cassandra, MongoDB, Elasticsearch), uma única consulta do usuário pode disparar leituras em dezenas de discos simultaneamente.
Este é o fenômeno da "Amplificação de Latência de Cauda".
Se uma transação web precisa consultar 100 fragmentos de dados (shards) em paralelo para montar uma resposta, a transação só termina quando o mais lento dos 100 discos responder.
💡 Dica Pro: A probabilidade de uma transação ser lenta não é a probabilidade de um disco ser lento. É a probabilidade de qualquer um dos discos envolvidos ser lento.
Matematicamente, se 1% das suas operações de disco são lentas (p99 ruim), e sua aplicação precisa acessar 100 discos para responder ao usuário:
Probabilidade de Lentidão = 1 - (0.99)^100 ≈ 63%
Com um p99 ruim, 63% das suas transações de usuário serão lentas, mesmo que 99% dos seus discos estejam rápidos individualmente. É por isso que em Hyperscalers (Google, AWS), o SLA de disco é medido em p99.99 ou p99.999.
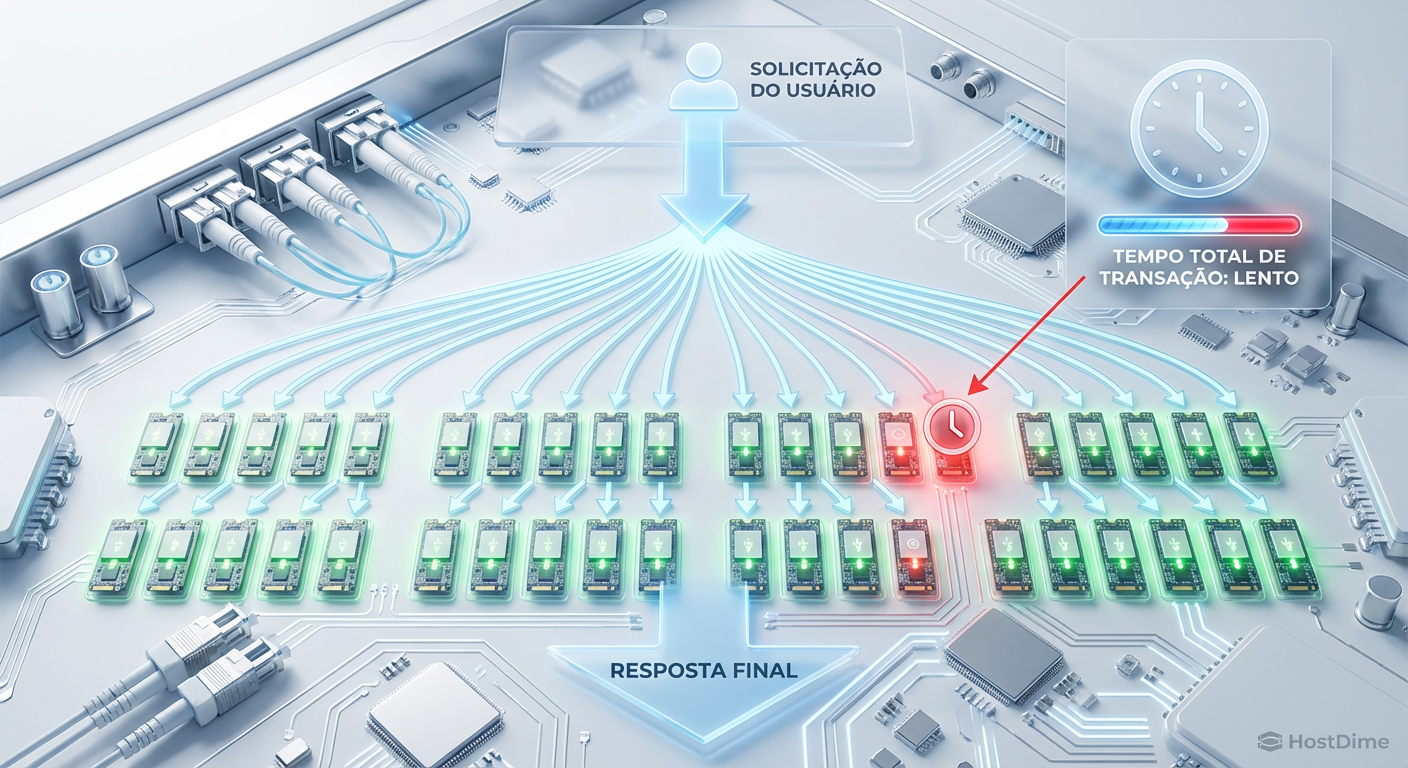 Figura: O efeito de amplificação: Como um único SSD em estado de stall (vermelho) contamina a performance de toda a transação distribuída.
Figura: O efeito de amplificação: Como um único SSD em estado de stall (vermelho) contamina a performance de toda a transação distribuída.
Anatomia de um Stall: Por que o SSD para de responder?
Diferente dos discos mecânicos (HDDs), onde a latência é física (rotação do prato + movimento da agulha), a latência do SSD é computacional e gerenciada por firmware. Os picos de latência (stalls) geralmente ocorrem por três motivos principais:
Garbage Collection (GC) Agressivo: O SSD não pode sobrescrever dados. Ele precisa apagar um bloco inteiro antes de escrever novamente. Se o disco estiver cheio ou sob escrita pesada, o controlador pausa as novas gravações para realizar essa limpeza interna. Durante esse tempo (que pode durar centenas de milissegundos), o I/O é bloqueado.
Saturação do Cache SLC: A maioria dos SSDs modernos (TLC e QLC) usa uma pequena porção de memória rápida (SLC) como buffer. Quando esse buffer enche, a velocidade de gravação cai da ordem de GB/s para MB/s, e a latência dispara.
DRAM-less Design: SSDs baratos sem cache DRAM precisam buscar a tabela de mapeamento de dados na própria NAND (que é lenta) ou usar a RAM do host (HMB). Isso introduz variabilidade.
Tabela Comparativa: Consistência de Latência
| Característica | SSD Consumer (Genérico) | SSD Enterprise (Data Center) | Impacto no p99 |
|---|---|---|---|
| Over-provisioning | Baixo (~7%) | Alto (28% ou mais) | Mais espaço livre reduz a frequência de GC, estabilizando o p99. |
| Cache de Escrita | Dinâmico (SLC Cache) | Estático / Não depende de SLC | SSDs Enterprise mantêm performance constante mesmo cheios. |
| Proteção de Energia | Inexistente | Capacitores (PLP) | Permite que o SSD confirme a gravação (ack) antes de gravar na NAND, reduzindo latência. |
| Foco do Firmware | Throughput Máximo (MB/s) | Latência Determinística (QoS) | Consumer foca em números de caixa; Enterprise foca em consistência. |
 Figura: Hardware importa: A presença de capacitores e cache DRAM em SSDs Enterprise é fundamental para garantir latência determinística.
Figura: Hardware importa: A presença de capacitores e cache DRAM em SSDs Enterprise é fundamental para garantir latência determinística.
Diagnóstico: O erro de confiar no iostat
A ferramenta iostat (parte do pacote sysstat) é onipresente em sistemas Linux, mas é perigosa para diagnósticos finos. Por padrão, o iostat exibe a média das métricas desde o último intervalo de amostragem.
Se você roda iostat -x 1, você vê a média de latência (r_await / w_await) dentro daquele segundo. Se o disco travou por 100ms e depois respondeu 900 requisições em 0.1ms, o iostat vai reportar uma média excelente, mascarando o travamento de 100ms que causou um jitter no seu streaming de vídeo ou VoIP.
A solução: Histogramas com FIO e eBPF
Para capturar a realidade, precisamos de ferramentas que registrem cada I/O individualmente ou usem buckets de histograma. O FIO (Flexible I/O Tester) é o padrão ouro para benchmark, mas deve ser configurado corretamente.
Não basta rodar um teste de velocidade. Você precisa configurar o FIO para reportar percentis de latência (clat_percentiles).
⚠️ Perigo: Evite benchmarks de curta duração (ex: 1 minuto). O SSD precisa atingir o "Steady State" (estado estacionário) para que o Garbage Collection entre em ação e mostre a verdadeira face da performance. Testes de 5 minutos são inúteis para validação de infraestrutura crítica; prefira testes de pré-condicionamento seguidos de janelas de medição longas (30m+).
Exemplo de saída crítica no FIO que a maioria ignora:
clat percentiles (usec):
| 1.00th=[ 396], 5.00th=[ 450], 10.00th=[ 490], 20.00th=[ 540],
| 30.00th=[ 580], 40.00th=[ 620], 50.00th=[ 668], 60.00th=[ 724],
| 70.00th=[ 796], 80.00th=[ 908], 90.00th=[ 1136], 95.00th=[ 1528],
| 99.00th=[ 3248], 99.50th=[ 5408], 99.90th=[12608], 99.95th=[18048],
| 99.99th=[32128]
Note a diferença brutal:
50.00th (Mediana): 668 microsegundos (0.6ms). Excelente.
99.99th: 32128 microsegundos (32ms). Desastroso.
Se sua aplicação exige resposta em tempo real, esses 32ms são onde o problema reside. O usuário final não sente a mediana; ele sente o travamento do p99.99.
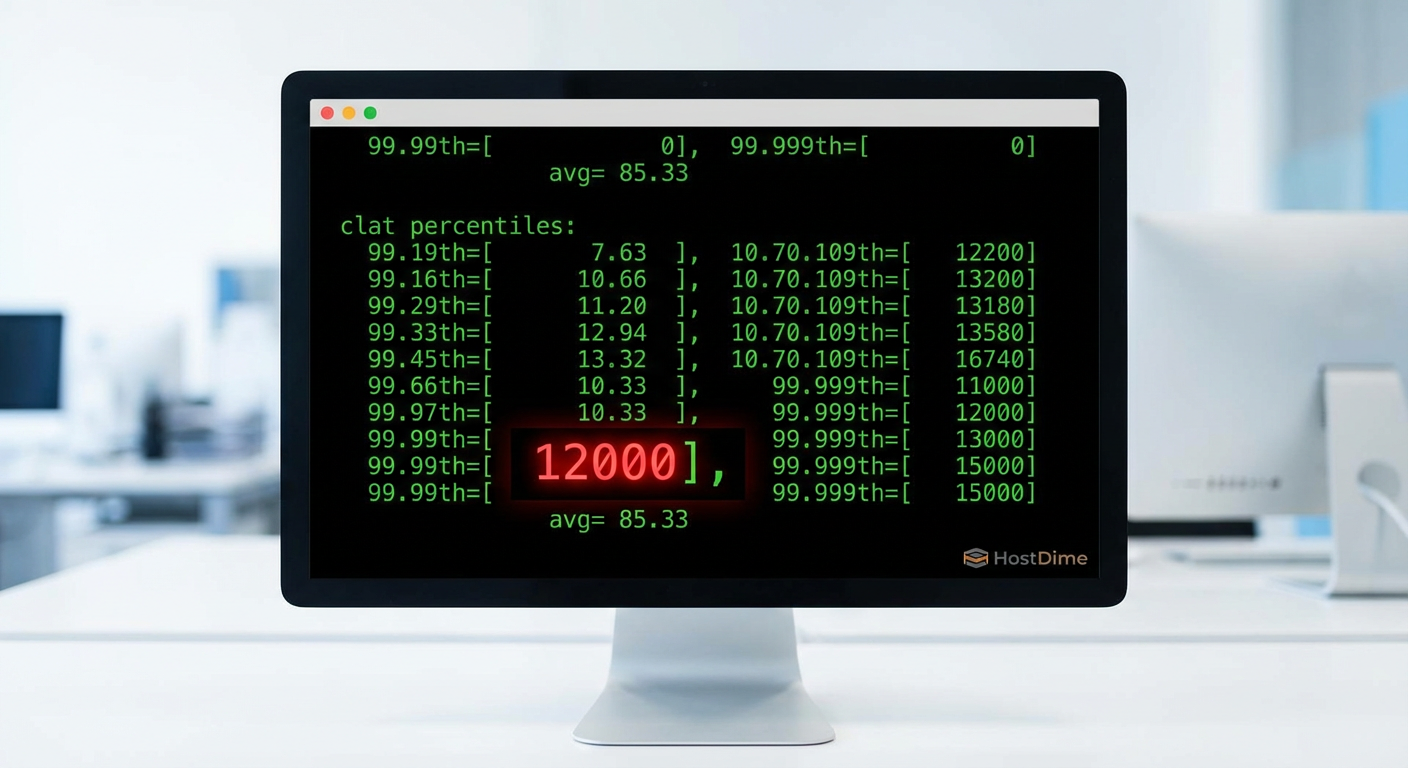 Figura: O relatório de verdade: A seção de percentis do FIO revela o que a média esconde.
Figura: O relatório de verdade: A seção de percentis do FIO revela o que a média esconde.
O Veredito: Exija Determinismo
A indústria de armazenamento de consumo treinou os usuários a olhar para números grandes: "Leitura Sequencial de 7.000 MB/s". Para um servidor de banco de dados, virtualização ou até mesmo um Home Lab rodando ZFS, esse número é irrelevante.
O que você deve buscar é determinismo.
Ao avaliar SSDs para qualquer carga de trabalho que não seja puramente armazenamento de arquivos frios (backup), ignore a taxa de transferência máxima. Procure reviews e datasheets que mostrem a "Qualidade de Serviço" (QoS) ou latência em QD1 (Queue Depth 1) e QD32 nos percentis 99.
Para infraestrutura crítica, um SSD que entrega 2.000 MB/s constantes com p99 de 2ms é infinitamente superior a um que entrega 7.000 MB/s com p99 de 500ms. A consistência é a única métrica de performance que realmente importa quando a escala aumenta. Pare de otimizar para o melhor caso e comece a mitigar o pior caso.
Referências & Leitura Complementar
SNIA (Storage Networking Industry Association): Solid State Storage Performance Test Specification (SSS PTS) – Metodologia padrão para atingir o Steady State.
JEDEC JESD218: Padrão para requisitos de SSDs e métodos de teste de resistência.
Google SRE Book: Capítulo sobre "Service Level Indicators" (SLIs) e a importância de medir a cauda da distribuição.
NVMe Specification 2.0: Detalhes sobre NVM Sets e Endurance Groups para isolamento de I/O e melhoria de QoS.
Perguntas Frequentes (FAQ)
O que é latência p99 e por que ela é mais importante que a média?
A latência p99 indica que 99% das suas requisições são mais rápidas que aquele valor. Ela é vital porque a média aritmética esconde picos de lentidão (outliers) que travam aplicações sensíveis, enquanto o p99 expõe a experiência real dos usuários mais afetados. Em sistemas distribuídos, um p99 ruim pode degradar 100% das transações complexas.Como o Garbage Collection do SSD afeta a latência de cauda?
O Garbage Collection é um processo de limpeza interna do SSD que pode bloquear temporariamente novas gravações para liberar blocos na memória NAND. Durante esse bloqueio, a latência dispara (stall), criando picos que não aparecem na média, mas são capturados no p99 ou p99.9. SSDs Enterprise possuem controladores mais robustos para mitigar esse efeito.Qual comando do FIO devo usar para medir latência de cauda?
Você deve usar a flag `clat_percentiles=1` (habilitada por padrão em versões recentes) e analisar a seção de percentis (99.00th, 99.90th, 99.99th) no relatório final. É crucial ignorar a linha 'avg' (média) e focar nos valores mais altos da distribuição para entender o comportamento do disco sob estresse.
Dr. Elena Kovic
Metodologista de Benchmark
"Desmonto o marketing com análise estatística rigorosa. Meus benchmarks isolam cada variável para revelar a performance crua e sem filtros do hardware corporativo."