Acelerando metadados no ZFS: por que o Special VDEV muda o jogo em pools híbridos

Chega de latência no 'ls -la'. Descubra como isolar metadados em NVMe usando ZFS Special VDEVs para eliminar o gargalo físico dos HDDs e reduzir a latência de cauda.
Você já olhou para um cursor piscando em um terminal SSH enquanto espera um simples ls -la retornar em um diretório com meio milhão de arquivos? Se sim, você sentiu na pele a diferença entre throughput e latência. Em sistemas distribuídos, costumamos dizer que "os noves não importam se o usuário está infeliz". No mundo do armazenamento, a frase equivalente é: "Seus 2 GB/s de throughput sequencial são irrelevantes se seus metadados estão presos atrás de um braço mecânico físico buscando aleatoriamente em um prato de metal".
A observabilidade nos ensina a desconfiar das médias. A média diz que seu pool de armazenamento está saudável. O histograma de latência, porém, grita que suas operações de metadados estão sofrendo timeouts silenciosos. É hora de pararmos de tratar discos rígidos rotacionais (HDDs) como dispositivos de uso geral em 2026. Para dados frios e sequenciais, eles são imbatíveis em custo por terabyte. Para metadados, eles são um gargalo físico que nenhuma quantidade de cache RAM (ARC) consegue mascarar completamente quando a escala aumenta.
Aqui entra o Special VDEV (Allocation Classes) do ZFS. Não é cache. É tiering estrutural. E se você gerencia pools híbridos sem ele, você está deixando performance na mesa e aceitando uma latência de cauda (P99) inaceitável.
Resumo em 30 segundos
- Física Implacável: HDDs são excelentes para streaming de dados, mas terríveis para o I/O aleatório exigido por metadados (Dnodes, diretórios).
- Cache vs. Persistência: Diferente do L2ARC (que precisa ser "aquecido" e consome RAM), o Special VDEV é um armazenamento primário e persistente. Os metadados vivem lá permanentemente.
- Observabilidade: Mover metadados para flash (SSD/NVMe) elimina a "cauda longa" de latência, transformando operações de varredura de arquivos de minutos em segundos.
Quando o ls -la se torna um gargalo de observabilidade
A maioria dos engenheiros projeta storage pensando na capacidade total ou na velocidade de transferência de grandes arquivos de vídeo ou backups. O problema é que o sistema de arquivos não vive apenas de payload. Ele vive de estrutura.
Cada arquivo no ZFS possui um dnode (equivalente ao inode no mundo ext4/xfs). Este dnode contém informações vitais: permissões, timestamps, checksums e, crucialmente, os ponteiros para onde os dados reais residem no disco. Quando você executa uma varredura de integridade, um backup incremental ou simplesmente lista um diretório massivo, você não está lendo dados; você está lendo metadados.
Se o seu pool é composto por 60 discos de 18 TB em RAIDZ2, seus dados estão seguros. Mas se esses metadados estiverem espalhados aleatoriamente nesses pratos giratórios, cada leitura de dnode exige um movimento mecânico da cabeça de leitura/gravação.
Isso cria um cenário onde a CPU do servidor está ociosa, a rede está livre, mas o load average sobe disparado em estado de "iowait". A observabilidade do sistema mostra que o disco está 100% ocupado, mas transferindo apenas alguns kilobytes por segundo. Isso é a morte por I/O aleatório.
 Fig 1. O 'Imposto de Busca': A diferença física entre varrer metadados em pratos giratórios versus acesso direto em flash.
Fig 1. O 'Imposto de Busca': A diferença física entre varrer metadados em pratos giratórios versus acesso direto em flash.
A física cruel dos HDDs lidando com IOPS aleatórios de metadados
Vamos olhar para os dados brutos. Um HDD moderno de classe Enterprise (7200 RPM) entrega, em um dia bom, cerca de 120 a 150 IOPS (Input/Output Operations Per Second) em leituras aleatórias. A latência média de busca (seek time) gira em torno de 4ms a 8ms.
Agora, imagine um diretório com 100.000 arquivos. Para ler os metadados de todos eles (assumindo que não estão em cache), você precisa de milhares de IOPS. Seus discos mecânicos atingem o teto físico instantaneamente.
⚠️ Perigo: Em configurações RAIDZ (Z1/Z2/Z3), o desempenho de IOPS aleatórios é limitado ao de um único disco por VDEV, independentemente de quantos discos existam no grupo. Um VDEV de 10 discos RAIDZ2 tem aproximadamente os mesmos IOPS aleatórios de um único disco.
Isso acontece porque o ZFS precisa acessar todos os discos para reconstruir o bloco de dados (ou verificar a paridade), e o grupo inteiro precisa esperar pelo disco mais lento completar sua busca mecânica. É um problema de latência de cauda exacerbado pela física.
Se você mistura metadados e dados no mesmo meio físico lento, cada operação de metadados rouba um IOPS que poderia estar sendo usado para entregar o payload (o arquivo real). Você está criando contenção artificial.
A armadilha do L2ARC e por que cache não é tiering
Muitos administradores tentam resolver isso jogando um SSD barato no servidor e configurando-o como L2ARC (Level 2 Adaptive Replacement Cache). Eu vejo isso constantemente em logs de diagnóstico e é uma abordagem falha para este problema específico.
O L2ARC é volátil. Se você reinicia o servidor, o cache esvazia (embora o "Persistent L2ARC" tenha mitigado isso, a reconstrução dos ponteiros ainda custa tempo). Mais importante: o L2ARC consome RAM do sistema para indexar o que está no SSD. Para cada bloco no L2ARC, você perde um pedaço do seu precioso ARC (cache de RAM principal).
Em cenários de working set massivo — imagine um servidor de arquivos com 500 TB de dados e bilhões de arquivos — o L2ARC frequentemente falha em manter os metadados "quentes" o suficiente. O algoritmo de substituição acaba despejando metadados vitais para dar lugar a dados lidos recentemente.
O Special VDEV não é cache. Ele é uma Class of Allocation (Classe de Alocação). Quando você configura um Special VDEV, você está dizendo ao ZFS: "A partir de agora, todo bloco de metadados deve ser escrito fisicamente neste dispositivo NVMe, e nunca nos HDDs".
Isso é tiering real. Os metadados nunca tocam a ferrugem dos discos rotacionais. Eles vivem no flash. Isso garante que a latência de leitura de qualquer metadado seja sempre a latência do flash (microssegundos), não a do HDD (milissegundos).
 Fig 2. Anatomia de um Pool Híbrido com Allocation Classes: Separação física de dados sequenciais e metadados aleatórios.
Fig 2. Anatomia de um Pool Híbrido com Allocation Classes: Separação física de dados sequenciais e metadados aleatórios.
Implementando classes de alocação dedicadas em NVMe
A implementação dessa tecnologia exige planejamento. Diferente do cache (L2ARC/SLOG), que pode ser removido a qualquer momento sem perda de dados, o Special VDEV contém dados únicos. Se o seu Special VDEV falhar e não tiver redundância, você perde o pool inteiro.
Regras de ouro para a arquitetura
Redundância é Obrigatória: Nunca adicione um único SSD como Special VDEV. Use sempre um espelhamento (Mirror). Se o seu pool principal é um array massivo de 3-way mirrors, seu Special VDEV deve ser um 3-way mirror de NVMe. A confiabilidade dos metadados deve igualar ou superar a dos dados.
Dimensionamento: Uma regra prática baseada em dados de campo sugere que os metadados ocupam entre 0,1% e 0,3% do tamanho total do pool para cargas de trabalho padrão (arquivos grandes). Para cargas com muitos arquivos pequenos, isso pode subir para 1% a 3%.
Tecnologia do Drive: Use SSDs com alta durabilidade (DWPD). Metadados sofrem muitas escritas pequenas e constantes. Discos NVMe Enterprise (como as séries Intel Optane ou Micron 7450/9400) são ideais devido à baixa latência.
O comando mágico
Para adicionar um par de NVMes espelhados como Special VDEV a um pool existente chamado tank:
zpool add tank special mirror /dev/disk/by-id/nvme-A /dev/disk/by-id/nvme-B
A partir desse momento, novos metadados serão escritos no flash. Os metadados antigos permanecerão nos HDDs até que sejam reescritos ou que você force uma movimentação (via zfs send/recv ou reescrita dos dados).
💡 Dica Pro: O parâmetro
ashifté crítico aqui. Garanta que seus SSDs estejam formatados com o alinhamento correto (geralmenteashift=12para 4k, ouashift=13para 8k em alguns SSDs modernos) para evitar amplificação de escrita.
Acelerando pequenos blocos: special_small_blocks
Aqui é onde a mágica acontece para bancos de dados e sistemas de arquivos com muitos arquivos de texto, logs ou thumbnails. O ZFS permite que você defina um limiar de tamanho. Qualquer arquivo menor que esse tamanho será tratado como "metadado" para fins de armazenamento e irá direto para o NVMe.
zfs set special_small_blocks=64K tank/dataset
Neste exemplo, qualquer arquivo de 64K ou menos será armazenado fisicamente no SSD. Isso retira todo o I/O "sujo" e pequeno dos HDDs. O resultado? Seus HDDs ficam livres para fazer o que fazem de melhor: ler e escrever grandes sequências contínuas de dados. O throughput sequencial dos seus HDDs aumenta porque eles param de perder tempo buscando arquivos minúsculos.
Validando a latência de cauda com zpool iostat e histogramas
Como engenheiros de observabilidade, não confiamos em sentimentos. Validamos com métricas. Antes e depois da migração, você deve monitorar a latência.
O comando padrão zpool iostat -v mostra largura de banda, mas para ver a verdade, precisamos olhar para a latência de operação e as filas.
Use:
zpool iostat -r 1
Isso mostrará a latência de requisição individual. No entanto, para visualizar a "cauda" (outliers), precisamos de histogramas. No OpenZFS moderno, podemos usar ferramentas como zpool latency (se disponível na sua distribuição) ou scripts baseados em eBPF para traçar a distribuição.
Em um pool apenas com HDD, você verá um histograma "gordo" e espalhado, com muitas operações na faixa de 10ms a 100ms (e picos assustadores de 500ms+ sob carga).
Após implementar o Special VDEV, o histograma de operações de metadados colapsa para a esquerda. A grande maioria das operações cai para a faixa de 50us - 200us (microssegundos). O P99 (o 1% das operações mais lentas) deixa de ser medido em "segundos de frustração" e passa a ser imperceptível.
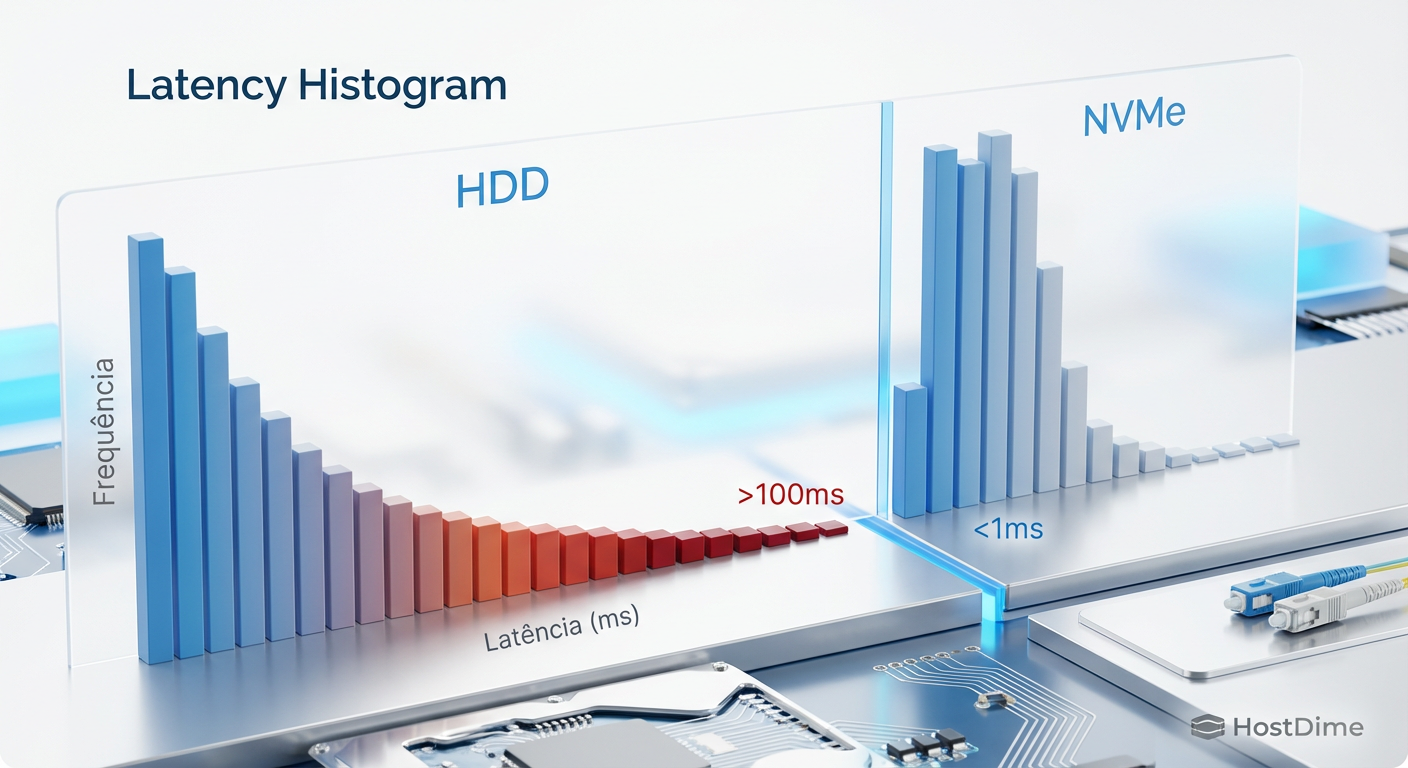 Fig 3. Histograma de Latência: A eliminação da 'cauda longa' (p99) após a migração de metadados para flash.
Fig 3. Histograma de Latência: A eliminação da 'cauda longa' (p99) após a migração de metadados para flash.
Isso não é apenas "mais rápido". É determinístico. A variabilidade da latência diminui drasticamente, o que é o santo graal para aplicações sensíveis a tempo de resposta, como bancos de dados ou servidores de virtualização (VMs).
Monitoramento contínuo: O que observar
Uma vez implementado, você precisa monitorar o preenchimento do Special VDEV. Se ele encher, os metadados transbordarão de volta para os HDDs, reintroduzindo a latência que você lutou para eliminar.
Configure alertas no seu Prometheus/Grafana para a capacidade da classe alloc.
Métrica chave: Percentual de uso do Special VDEV.
Alerta: Aviso crítico em 85% de uso.
Se você estiver usando special_small_blocks, o consumo será muito mais rápido. Ajuste esse parâmetro dinamicamente. Se o espaço estiver acabando, reduza o tamanho do bloco (ex: de 64K para 32K) para enviar apenas os arquivos realmente pequenos para o flash.
O futuro é híbrido, mas inteligente
Estamos em uma era de transição. O armazenamento all-flash ainda é proibitivamente caro para petabytes de arquivamento, e o armazenamento all-spinning-rust é inaceitavelmente lento para as expectativas modernas de UX.
O Special VDEV é a ponte racional. Ele reconhece que nem todos os bytes são criados iguais. Um byte de metadado é ordens de magnitude mais "quente" e crítico para a performance do sistema do que um byte de um arquivo de vídeo arquivado.
Não deixe seus metadados sofrerem na "física cruel" da rotação mecânica. Trate-os como a infraestrutura crítica que são. Seus usuários podem não saber o que é um dnode, mas eles saberão que o sistema parou de travar. E você, olhando para os gráficos de latência achatados no zero, terá a satisfação de ver o invisível funcionando perfeitamente.
Referências & Leitura Complementar
OpenZFS Documentation: "Allocation Classes" - Detalhes técnicos sobre a implementação de classes de alocação e estrutura de blocos.
Matt Ahrens (Delphix): Palestras sobre ZFS Allocation Classes na OpenZFS Developer Summit (2018/2019).
NVMe Specifications: Datasheets de latência de leitura aleatória (QD1) para drives Enterprise (ex: Micron 7450 / Intel Optane P5800X).
FreeBSD Man Pages:
zpool-features(7)- Seção sobreallocation_classes.
Perguntas Frequentes (FAQ)
P: Posso remover um Special VDEV depois de adicioná-lo? R: Depende da versão do ZFS e da configuração. Na maioria das implementações atuais (OpenZFS 2.0+), não é possível remover um Special VDEV de um pool RAIDZ. Você pode removê-lo de um pool composto apenas por espelhos (Mirrors), desde que haja espaço nos discos restantes para realocar os dados. Planeje como se fosse um casamento: para sempre.
P: Qual o tamanho ideal para o Special VDEV?
R: A regra de ouro é 0.3% da capacidade do pool para metadados puros. Se você planeja usar a função small_blocks para armazenar arquivos pequenos também, precisará calcular a distribuição dos seus dados. Ferramentas de análise de arquivos podem ajudar a estimar quantos GBs você tem em arquivos menores que X KB.
P: O que acontece se o Special VDEV falhar? R: Se todo o VDEV falhar (ambos os discos de um espelho, por exemplo), você perde o pool inteiro. Os metadados são a "mapa" dos seus dados. Sem o mapa, os dados nos HDDs são lixo ilegível. Por isso, a redundância (Mirror ou RAIDZ para o Special VDEV) é não-negociável.
P: Preciso de SSDs PLP (Power Loss Protection)? R: Altamente recomendado. O ZFS é robusto contra perda de energia (copy-on-write), mas SSDs de consumo sem capacitores de proteção podem corromper dados em voo ou "mentir" sobre a confirmação de escrita para ganhar velocidade. Para metadados críticos, use hardware Enterprise.

Lucas Ferreira
Engenheiro de Observabilidade
"Transformo o caos de logs, métricas e traces em clareza operacional. Minha missão é eliminar pontos cegos e garantir que nada permaneça invisível na infraestrutura."