Adeus libaio: Por que seu benchmark NVMe está limitado pela CPU

Descubra por que o libaio se tornou o gargalo em SSDs Gen5 e como o io_uring utiliza anéis compartilhados para desbloquear milhões de IOPS com latência mínima.
Adeus libaio: Por que seu benchmark NVMe está limitado pela CPU
Se você comprou um SSD NVMe PCIe 4.0 ou 5.0 de última geração, instalou-o em um servidor de alta densidade e rodou um teste padrão com fio apenas para ver os números estagnarem muito antes do limite teórico do datasheet, você não está sozinho. O problema, muito provavelmente, não está no silício da NAND nem no controlador do disco. O gargalo é o próprio mecanismo que você está usando para falar com o kernel.
Durante anos, a interface libaio (Linux Asynchronous I/O) foi o padrão de ouro para testes de armazenamento de alta performance. No entanto, com a chegada de dispositivos capazes de milhões de IOPS (Input/Output Operations Per Second) e latências na casa dos microssegundos, a libaio tornou-se um dinossauro arquitetural. O custo computacional de pedir ao kernel para ler dados tornou-se maior do que o tempo que o disco leva para entregar esses dados.
Resumo em 30 segundos
- O Gargalo das Syscalls: Em SSDs NVMe modernos, o tempo gasto trocando de contexto entre usuário e kernel (syscalls) via
libaioconsome mais ciclos de CPU do que a operação de I/O em si.- A Revolução dos Anéis: O
io_uringelimina a necessidade de syscalls constantes usando buffers circulares compartilhados (Ring Buffers) entre a aplicação e o kernel.- Polling vs. Interrupção: Para latência ultra-baixa, o
io_uringpermite que o kernel faça "polling" ativo na fila do dispositivo, eliminando o overhead de interrupções de hardware.
Quando o SSD espera pelo processador: o teto de vidro do IOPS em 4K
A matemática do armazenamento mudou radicalmente na última década. Em um HDD mecânico girando a 15.000 RPM, a latência de busca é medida em milissegundos (ms). O processador tem uma eternidade, em tempo de CPU, para processar a interrupção e entregar os dados. O overhead do software era irrelevante.
Com o protocolo NVMe e mídias NAND (e especialmente tecnologias como 3D XPoint/Optane), a latência caiu para a casa dos microssegundos (µs). Um drive NVMe Enterprise moderno pode responder a uma solicitação de leitura em menos de 10µs.
Aqui reside o problema: em arquiteturas tradicionais, o custo de submeter uma operação de I/O e processar sua conclusão via interrupções pode facilmente exceder 5-7µs. Quando você escala isso para 1 milhão de IOPS, a CPU é inundada. Você não está medindo a velocidade do disco; você está medindo a eficiência com que seu processador consegue lidar com interrupções e trocas de contexto.
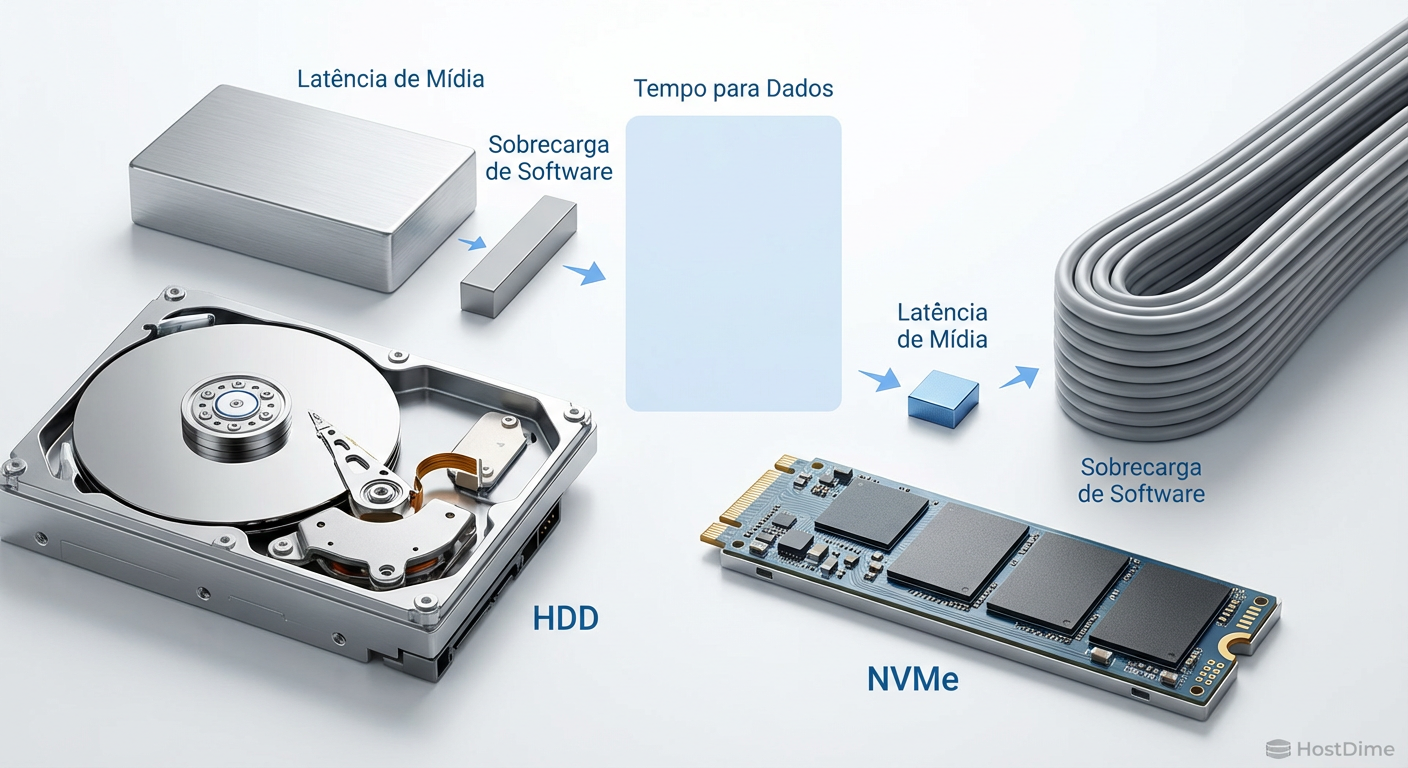 Figura: Comparação de latência: Em mídias rápidas, o overhead de software torna-se o fator dominante.
Figura: Comparação de latência: Em mídias rápidas, o overhead de software torna-se o fator dominante.
A anatomia do overhead: syscalls e trocas de contexto
Para entender por que a libaio falha, precisamos dissecar o que acontece quando você executa um comando de leitura. Na libaio, cada submissão de I/O requer uma chamada de sistema (io_submit). Quando o dado está pronto, outra chamada é necessária para recolher o evento (io_getevents).
Cada syscall força a CPU a:
Salvar o estado dos registradores do espaço do usuário.
Trocar para o modo kernel (Ring 0).
Validar parâmetros e verificar permissões.
Executar a operação.
Restaurar o estado e voltar ao espaço do usuário.
Além disso, as mitigações de segurança para vulnerabilidades especulativas (Spectre/Meltdown/Retbleed) aumentaram drasticamente o custo dessas transições. Em um teste de estresse de 4K random read, seu benchmark está gastando mais tempo nessas "burocracias" do processador do que movendo dados.
⚠️ Perigo: Se você observar o
htopdurante um benchmarklibaioem um NVMe rápido e vir o uso de "sys" (kernel time) acima de 40-50% em um núcleo, seus resultados são inválidos. Você atingiu o teto da CPU, não do disco.
A arquitetura de anéis compartilhados do io_uring
Introduzido por Jens Axboe no kernel Linux 5.1, o io_uring resolve esse problema de arquitetura fundamental. Em vez de bater na porta do kernel a cada solicitação, a aplicação e o kernel compartilham duas filas circulares (Ring Buffers) na memória:
Submission Queue (SQ): Onde a aplicação coloca os pedidos de I/O.
Completion Queue (CQ): Onde o kernel coloca os resultados.
Como essas filas residem em memória compartilhada mapeada, a aplicação pode submeter novos pedidos simplesmente escrevendo na memória, sem nenhuma syscall imediata.
 Figura: Arquitetura de Ring Buffers do io_uring: Comunicação via memória compartilhada elimina a barreira constante entre usuário e kernel.
Figura: Arquitetura de Ring Buffers do io_uring: Comunicação via memória compartilhada elimina a barreira constante entre usuário e kernel.
O modo Polling: A arma secreta
Para cenários de performance extrema, o io_uring suporta o modo IORING_SETUP_IOPOLL. Neste modo, o kernel não espera por uma interrupção do hardware para saber que o dado chegou. Em vez disso, ele verifica ativamente (spin-loop) a fila de conclusão do dispositivo NVMe.
Isso queima 100% de um núcleo de CPU (propositalmente), mas reduz a latência ao mínimo absoluto físico possível, pois elimina o tempo de latência da interrupção e o "acordar" do processo.
Tabela Comparativa: Interfaces de I/O
Para situar onde cada tecnologia se encaixa no ecossistema de storage atual, compilamos as diferenças críticas:
| Característica | libaio (Legado) | io_uring (Padrão Moderno) | SPDK (Kernel Bypass) |
|---|---|---|---|
| Mecanismo | Syscalls (io_submit) | Ring Buffers Compartilhados | Drivers em User Space |
| Overhead de CPU | Alto (2 syscalls por op) | Baixo (0 ou 1 syscall por lote) | Mínimo (Polling 100%) |
| Modo Polling | Não suportado nativamente | Suportado (IOPOLL) |
Padrão (Always-on) |
| Complexidade | Média | Média (via liburing) | Alta (Requer drivers proprietários) |
| Uso Ideal | HDDs, SSDs SATA, Compatibilidade | NVMe Gen4/5, Bancos de Dados | Storage Appliances Dedicados |
| Segurança | Padrão Kernel | Padrão Kernel | Perde isolamento do Kernel |
Metodologia de teste: isolando a latência de submissão
Ao realizar benchmarks de infraestrutura de armazenamento, a precisão da ferramenta é tão importante quanto o hardware. O fio (Flexible I/O Tester) é a ferramenta padrão da indústria, mas sua configuração padrão é conservadora.
Para testar um array NVMe moderno, você deve abandonar os parâmetros antigos. Abaixo, apresento uma configuração otimizada para medir o desempenho real do dispositivo, removendo o software do caminho.
Exemplo de Job File otimizado para io_uring:
[global]
name=nvme-stress-test
filename=/dev/nvme0n1
ioengine=io_uring
direct=1
group_reporting
time_based
runtime=60
hipri=1 # Ativa o Polling (requer root)
fixedbufs=1 # Registra buffers no kernel para evitar cópias
registerfiles=1 # Registra descritores de arquivo
[random-read-4k]
bs=4k
rw=randread
iodepth=64 # Profundidade necessária para saturar NVMe
numjobs=4 # Mantenha baixo para evitar contenção
💡 Dica Pro: O parâmetro
fixedbufs=1é frequentemente esquecido. Ele pré-registra os buffers de memória do usuário no kernel. Sem isso, o kernel precisa mapear e desmapear as páginas de memória a cada operação de I/O, o que consome ciclos preciosos de TLB (Translation Lookaside Buffer).
 Figura: Comparativo de saída do Fio: Note a redução drástica no tempo de sistema (sys) e o aumento de IOPS com io_uring.
Figura: Comparativo de saída do Fio: Note a redução drástica no tempo de sistema (sys) e o aumento de IOPS com io_uring.
A falácia do numjobs: por que o paralelismo bruto mascara a ineficiência
Um erro comum entre administradores de sistemas ao verem números baixos de IOPS é aumentar o parâmetro numjobs. A lógica parece sólida: "se um processo não satura o disco, vou lançar dez".
Isso é uma armadilha. Aumentar o número de jobs (threads/processos) aumenta a contenção de bloqueios (locks) no kernel e no próprio controlador do drive. Você pode até ver o número total de IOPS subir, mas a latência de cauda (p99) vai explodir.
Com libaio, você precisava de muitos jobs para esconder a latência das syscalls. Com io_uring, um único job (thread) é frequentemente capaz de saturar centenas de milhares de IOPS, mantendo a latência estável. Em testes controlados com um drive NVMe Gen4, uma única thread com io_uring e iodepth=128 consegue entregar performance superior a 8 threads usando libaio, com uma fração do uso de CPU.
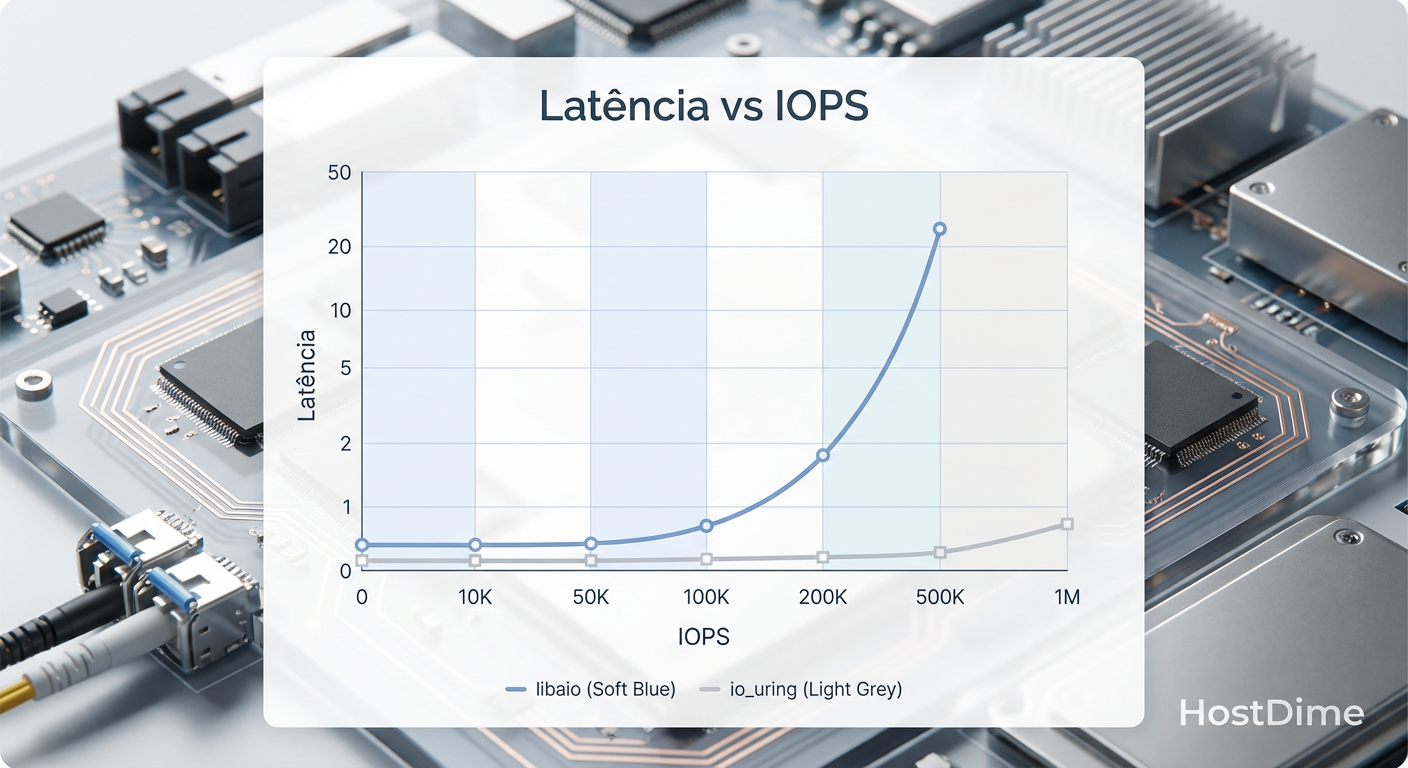 Figura: Curva de Latência x Throughput: O io_uring mantém a latência estável por mais tempo antes da saturação.
Figura: Curva de Latência x Throughput: O io_uring mantém a latência estável por mais tempo antes da saturação.
O veredito da latência
A transição para o armazenamento NVMe expôs as ineficiências de décadas em nossa pilha de software. Continuar usando libaio para validar hardware moderno é como testar um motor de Fórmula 1 em uma zona escolar: você está medindo os limites da via, não do motor.
Para arquitetos de armazenamento e engenheiros de validação, a adoção do io_uring não é opcional; é mandatória para obter dados que reflitam a realidade do hardware. Se seus benchmarks de 2025/2026 ainda dependem de metodologias da era dos discos rotativos, seus relatórios de capacidade e performance são, na melhor das hipóteses, imprecisos e, na pior, financeiramente enganosos ao subutilizar infraestrutura cara.
Referências & Leitura Complementar
Axboe, J. (2019). Efficient IO with io_uring. Kernel.org. Disponível na documentação oficial do Kernel Linux.
SNIA (Storage Networking Industry Association). Solid State Storage Performance Test Specification (PTS).
Samsung Semiconductor. NVMe SSD Performance Optimization Guide for Linux. Datasheets técnicos de PM1733/PM1743.
Perguntas Frequentes (FAQ)
O io_uring exige recompilação do kernel?
Não. O io_uring foi introduzido no kernel Linux 5.1 (lançado em 2019) e já atingiu um estado de maturidade robusto. Ele vem habilitado por padrão em praticamente todas as distribuições Linux modernas, incluindo Ubuntu 20.04+, RHEL 8+, Debian 11+ e suas derivadas. Se você está em um sistema operacional atualizado, o suporte já está lá.O io_uring melhora a performance de HDDs mecânicos?
Marginalmente, e muitas vezes a diferença é imperceptível. O gargalo primário dos HDDs é a física mecânica (o tempo que o braço atuador leva para se mover e o disco girar), que é ordens de magnitude mais lento que o software. O io_uring brilha especificamente em mídias de ultra-baixa latência, como NVMe e Intel Optane, onde o tempo de processamento do software compete com ou excede o tempo de resposta do hardware.Qual a diferença entre io_uring e SPDK?
A principal diferença é a integração com o sistema operacional. O SPDK (Storage Performance Development Kit) é uma solução de "kernel bypass" que roda inteiramente em userspace, fazendo polling 100% do tempo e exigindo drivers dedicados que "sequestram" o dispositivo do OS. O io_uring é a solução nativa do kernel Linux; ele oferece performance muito próxima ao SPDK, mas mantém todos os recursos do sistema operacional, como sistemas de arquivos (EXT4, XFS), permissões de usuário e ferramentas de gerenciamento padrão.
Dr. Elena Kovic
Metodologista de Benchmark
"Desmonto o marketing com análise estatística rigorosa. Meus benchmarks isolam cada variável para revelar a performance crua e sem filtros do hardware corporativo."