Adeus, números de marketing: a ciência do pré-condicionamento de SSDs

Descubra por que benchmarks de SSD falham sem a metodologia SNIA PTS. Aprenda a eliminar o viés do estado FOB e medir a performance real em Steady State usando Fio.
Se você baseia a arquitetura do seu storage nos números de IOPS estampados na caixa do SSD, seu projeto já nasceu falho. Os departamentos de marketing da indústria de armazenamento aperfeiçoaram a arte de vender o "pico de performance" (burst) como se fosse a capacidade sustentada do dispositivo. Para o engenheiro de dados sério ou o administrador de sistemas que preza pela estabilidade, esses números são, na melhor das hipóteses, ruído estatístico e, na pior, uma armadilha perigosa.
A realidade de um SSD em um ambiente de produção — seja um servidor de banco de dados transacional ou um cluster de virtualização — é governada pelo "Steady State" (Estado Estacionário), não pelo frescor do "Fresh Out of Box" (FOB). Entender e aplicar o pré-condicionamento não é apenas um preciosismo acadêmico; é a única maneira de garantir que a latência que você mede hoje será a mesma daqui a seis meses, quando o drive estiver 90% cheio e lutando contra a fragmentação interna.
Resumo em 30 segundos
- A mentira do FOB: SSDs novos operam com todas as páginas limpas e cache SLC vazio, entregando uma performance artificialmente alta que desaparece com o uso real.
- O que é Steady State: É o ponto de equilíbrio onde a taxa de escrita do usuário iguala a capacidade do drive de realizar Garbage Collection em tempo real.
- Metodologia SNIA: Para descobrir a verdade, devemos seguir o protocolo da SNIA: limpar (Purge), preencher (WIPC) e estressar (WDPC) até a convergência estatística.
A ilusão do estado FOB e o abismo de performance
Quando você retira um SSD da embalagem, ele está no estado FOB (Fresh Out of Box). Neste cenário idílico, todas as células de memória NAND estão apagadas e prontas para receber dados. O controlador não precisa realizar nenhuma operação de "limpeza" antes de escrever; ele apenas grava. Além disso, a maioria dos drives modernos (NVMe e SATA) utiliza uma porção da NAND como cache pSLC (pseudo-SLC), onde escreve 1 bit por célula para velocidade máxima, antes de consolidar os dados em TLC ou QLC (3 ou 4 bits por célula) em segundo plano.
 Figura: Comparação visual entre a organização imaculada de um SSD novo (FOB) e o caos de fragmentação no Estado Estacionário.
Figura: Comparação visual entre a organização imaculada de um SSD novo (FOB) e o caos de fragmentação no Estado Estacionário.
O problema surge quando o drive enche. Diferente de um disco magnético (HDD), que pode sobrescrever dados diretamente, a memória NAND exige um ciclo de Apagar-antes-de-Escrever. Você escreve em páginas (geralmente 4KB ou 16KB), mas só pode apagar em blocos (que contém centenas de páginas).
💡 Dica Pro: Se você está testando um SSD para um ZFS SLOG ou cache de escrita, ignore completamente os primeiros 15 minutos de qualquer benchmark. A performance real só aparece quando o buffer pSLC satura e o controlador é forçado a escrever diretamente na NAND lenta.
A mecânica do Garbage Collection e a Amplificação de Escrita
Para manter a performance, o controlador do SSD executa um processo chamado Garbage Collection (GC). Ele varre blocos que contêm uma mistura de dados válidos e inválidos (arquivos deletados pelo OS, mas ainda residentes na NAND), copia os dados válidos para um novo bloco limpo e apaga o bloco antigo.
Esse processo gera a Amplificação de Escrita (WAF - Write Amplification Factor). Se você pede para o disco escrever 4KB, mas o controlador precisa mover 12KB de dados antigos para liberar espaço, seu WAF é 4. Isso consome largura de banda interna do controlador e ciclos da NAND, matando a performance de I/O visível para o host.
No estado estacionário, o GC não roda apenas em momentos ociosos (idle); ele roda concorrentemente às suas escritas. É aqui que a latência de cauda (p99) explode. Um drive enterprise de qualidade (como um Intel/Solidigm D7 ou um Samsung PM9a3) possui controladores robustos e overprovisioning (espaço reservado) generoso para mitigar isso. Drives de consumo (mesmo os "Pro") geralmente colapsam sob essa pressão.
Por que o preenchimento sequencial falha
Uma prática comum, porém errônea, em reviews amadores é "encher o disco com arquivos grandes" antes de testar. Isso é insuficiente para simular um cenário de pior caso.
A escrita sequencial é "fácil" para a FTL (Flash Translation Layer). A tabela de mapeamento que traduz endereços lógicos (LBA) para físicos (PBA) permanece organizada. O verdadeiro teste de estresse para a FTL é a escrita aleatória (Random Write) em todo o espaço endereçável do disco. Isso fragmenta a tabela de mapeamento, forçando o controlador a buscar metadados na DRAM (ou pior, na própria NAND, se a DRAM for insuficiente), adicionando latência.
Tabela: Preenchimento Simples vs. Pré-condicionamento Real
| Variável | Preenchimento Sequencial (Errado) | Pré-condicionamento SNIA (Correto) |
|---|---|---|
| Padrão de I/O | Blocos grandes, contíguos. | Aleatório (4K/8K) ou misto. |
| Estresse na FTL | Baixo. Mapeamento linear. | Crítico. Fragmentação máxima da tabela. |
| Estado do GC | Passivo ou pouco ativo. | Ativo e concorrente (Worst Case). |
| Resultado | Performance otimista. | Performance real sustentada. |
Implementando o protocolo SNIA PTS
A Storage Networking Industry Association (SNIA) definiu o padrão ouro para testes de performance em estado sólido: o PTS (Performance Test Specification). Para obter dados confiáveis, devemos seguir três fases distintas antes de sequer pensar em rodar o benchmark final.
 Figura: Fluxograma das fases do protocolo SNIA PTS: Purge, Carga de Trabalho Independente, Carga Dependente e Janela de Medição.
Figura: Fluxograma das fases do protocolo SNIA PTS: Purge, Carga de Trabalho Independente, Carga Dependente e Janela de Medição.
1. Purge (Saneamento)
O drive deve ser retornado ao estado FOB ou o mais próximo possível disso. Não basta formatar. É necessário enviar um comando NVMe Format ou Secure Erase.
- Comando Linux:
nvme format /dev/nvme0n1 --ses=1(User Data Erase).
2. WIPC (Workload Independent Pre-conditioning)
O objetivo aqui é invalidar o estado "vazio" das células. Devemos escrever em todo o espaço de usuário (LBA space) duas vezes (2x capacity) com um padrão sequencial ou aleatório, garantindo que não haja compressão pelo controlador.
- Por que 2x? Para garantir que qualquer área de overprovisioning acessível também tenha sido ciclada e que o controlador não possa usar truques de "zero-deduplication".
3. WDPC (Workload Dependent Pre-conditioning)
Esta é a fase crítica. Você deve rodar exatamente a mesma carga de trabalho que pretende medir (ex: 4K Random Write, 70/30 Read/Write) continuamente. Não há um tempo fixo. O teste roda em loops até que a performance atinja a convergência estatística.
Convergência estatística: verificando o Steady State
Como sabemos que o drive atingiu o Steady State? A SNIA define matematicamente:
Uma janela de medição (ex: 5 rodadas de 1 minuto).
A variação entre os resultados não pode exceder 10% da média.
A inclinação (slope) da curva de performance deve ser próxima de zero.
Visualmente, você verá o gráfico de IOPS começar alto (cache SLC), cair abruptamente (transição para TLC/QLC direto) e depois cair lentamente até estabilizar em uma linha reta "nervosa". Essa linha reta é a verdade sobre seu disco.
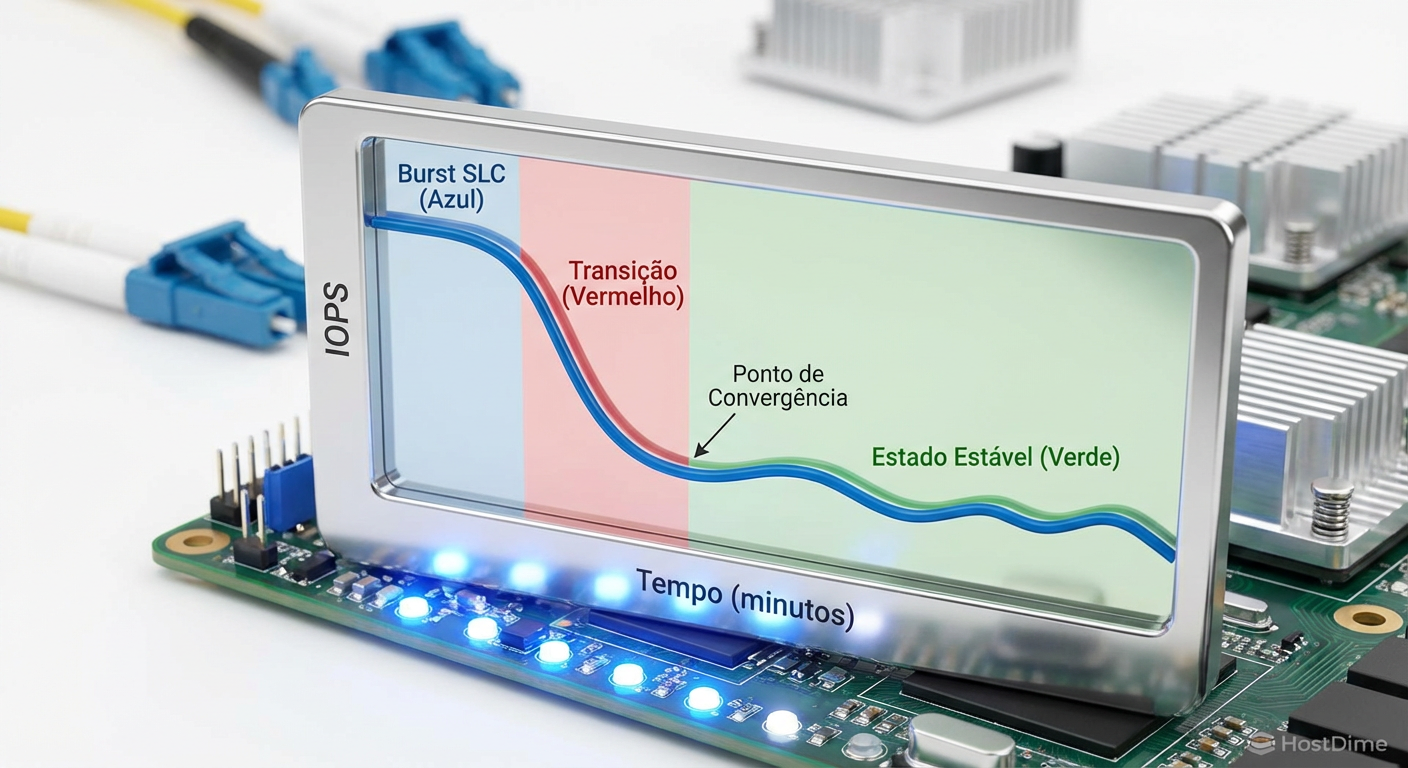 Figura: Gráfico de performance temporal demonstrando a queda do burst inicial até a estabilização no Estado Estacionário.
Figura: Gráfico de performance temporal demonstrando a queda do burst inicial até a estabilização no Estado Estacionário.
Mãos à obra: Scripting com Fio
Para aplicar isso no seu laboratório, o fio é a ferramenta padrão. Esqueça CrystalDiskMark ou AS SSD; eles são brinquedos de interface gráfica que não permitem esse controle granular.
Aqui está um exemplo de como estruturar a fase WDPC para um teste de escrita aleatória 4K:
# ATENÇÃO: Isso vai destruir todos os dados no disco.
fio --name=precondition_4k_random \
--filename=/dev/nvme0n1 \
--ioengine=libaio \
--direct=1 \
--rw=randwrite \
--bs=4k \
--iodepth=32 \
--numjobs=4 \
--time_based \
--runtime=3600 \
--group_reporting \
--eta-newline=1
⚠️ Perigo: O parâmetro
--runtime=3600(1 hora) é apenas um exemplo. Em drives enterprise de alta capacidade (ex: 7.68TB ou 15.36TB), o pré-condicionamento para atingir o steady state pode levar mais de 12 ou 24 horas de escrita contínua. Monitore a saída. Se a performance ainda estiver caindo ao final da hora, repita.
Para verificar a convergência, você deve capturar os logs de IOPS do fio (usando --write_iops_log) e plotar os dados. Se a linha de tendência dos últimos 20% do tempo for plana, você chegou lá. Só agora você pode rodar o benchmark de medição real e anotar os resultados.
O veredito técnico
A diferença entre um datasheet e a realidade operacional é o pré-condicionamento. Se você está projetando infraestrutura para cargas críticas, ignorar o comportamento de estado estacionário é negligência técnica. Discos que parecem idênticos em testes rápidos de 1 minuto podem apresentar uma diferença de 10x em performance sustentada após 24 horas de carga.
Para o entusiasta ou profissional de TI, a recomendação é clara: pare de buscar o número mais alto para postar em fóruns. Busque a linha mais plana. A consistência é a única métrica de velocidade que importa quando o sistema está sob pressão real.
Referências & Leitura Complementar
SNIA Solid State Storage (SSS) Performance Test Specification (PTS): O documento oficial que define os protocolos de teste.
JEDEC JESD218/219: Padrões para cargas de trabalho de resistência (Endurance Workloads) em SSDs.
Manpage do Fio: Documentação técnica dos parâmetros de I/O.
Perguntas Frequentes (FAQ)
O pré-condicionamento danifica o meu SSD?
Sim, ele consome ciclos de escrita (P/E cycles) de forma agressiva. O objetivo é simular o desgaste e a fragmentação de meses ou anos de uso em poucas horas para revelar a performance real do dispositivo. Não faça isso em discos onde a integridade dos dados existentes ou a garantia limitada (TBW) são preocupações críticas. É um procedimento destrutivo para fins de validação.Posso usar o CrystalDiskMark para medir o Steady State?
Não. Ferramentas de "clique único" como o CrystalDiskMark testam apenas áreas pequenas e temporárias (burst) do disco, criando arquivos de teste que cabem inteiramente no cache SLC ou na DRAM. Elas não exercitam a tabela de mapeamento da FTL em sua totalidade nem forçam o Garbage Collection a atuar concorrentemente com a escrita, mascarando a performance real.Qual a diferença entre WIPC e WDPC?
WIPC (Workload Independent Pre-conditioning) é a fase de preparação geral, onde enchemos o disco inteiro com dados válidos para eliminar o espaço livre e anular otimizações de fábrica. Já o WDPC (Workload Dependent Pre-conditioning) é a fase de estresse específico: executamos a carga de trabalho exata que queremos medir (ex: leitura/escrita aleatória 4k) repetidamente até que a performance pare de cair e se estabilize.
Dr. Elena Kovic
Metodologista de Benchmark
"Desmonto o marketing com análise estatística rigorosa. Meus benchmarks isolam cada variável para revelar a performance crua e sem filtros do hardware corporativo."