AI-Ready Storage Decoded: Separating High-Bandwidth Facts from Marketing Fiction

We cut through the 'AI-Ready' buzzwords to analyze the real bottleneck: feeding GPUs. Deep dive into GPUDirect, NVMe-oF, and the physics of data gravity.
Se você abriu a caixa de entrada do seu e-mail corporativo nos últimos seis meses, provavelmente foi bombardeado por press releases de fabricantes de armazenamento. A mensagem é sempre a mesma: o SSD que eles lançaram há dois anos, ou o array de flash que estava acumulando poeira no armazém, agora é magicamente "AI-Ready", "Built for LLMs" ou "Neural Network Optimized".
Vamos ser brutalmente honestos: a física do NAND Flash não mudou porque o CEO da NVIDIA vestiu uma jaqueta de couro nova. O que mudou foi o departamento de marketing.
Como alguém que já viu a indústria rebatizar "overclocking" como "turbo boost" e "bugs" como "features não documentadas", estou aqui para traduzir o dialeto de vendas para a realidade da engenharia. Se você está construindo infraestrutura para alimentar H100s ou Blackwells, você não precisa de um adesivo "AI"; você precisa de baixa latência de cauda e caminhos de dados que não engasguem sua CPU. Vamos dissecar o que realmente importa.
O Fenômeno do "AI-Washing": Por que todo SSD agora é uma "Solução de IA"
O termo técnico para isso é AI-Washing. É a mesma estratégia que vimos com o termo "Gaming" em 2015 e "Blockchain" em 2018. Se tem um controlador Phison e um dissipador de calor extravagante, agora é "AI".
Mas aqui está a realidade técnica: Cargas de trabalho de IA não são monolíticas. Treinamento de modelos (Training) e Inferência (Inference) são bestas completamente diferentes.
Treinamento: É um pesadelo de I/O. Você está lendo datasets massivos (terabytes a petabytes) aleatoriamente e, crucialmente, gravando checkpoints gigantescos periodicamente para não perder o progresso se uma GPU falhar.
Inferência: É sensível à latência, mas muito menos exigente em largura de banda de escrita.
Quando um fornecedor vende um drive QLC (Quad-Level Cell) barato como "AI-Ready" sem especificar a resistência de escrita para checkpointing, eles estão vendendo uma bomba-relógio. O marketing diz "Alta Capacidade para Data Lakes"; o engenheiro lê "Baixo DWPD (Drive Writes Per Day) e latência de escrita inconsistente".
O Verdadeiro Gargalo: Por que suas H100s estão esperando pelo I/O
Você gastou o PIB de uma pequena nação em um cluster de NVIDIA H100s. Parabéns. Agora, abra o monitor de utilização. Se suas GPUs estão operando a 60-70% de utilização, você não tem um problema de computação; você tem um problema de fome de dados (Data Starvation).
O problema não é necessariamente a velocidade bruta do SSD (sequencial). O problema é como os dados chegam do SSD para a VRAM da GPU. No modelo tradicional, os dados fazem uma viagem turística desnecessária:
SSD lê os dados.
Dados vão para a RAM do sistema (CPU).
CPU processa interrupções e copia os dados.
Dados viajam pelo barramento PCIe para a GPU.
Esse "salto" na CPU (CPU Bounce) é o assassino de performance. Em cargas de trabalho modernas, a CPU se torna o gargalo, não conseguindo despachar interrupções rápido o suficiente para saturar a largura de banda da GPU.
Ignorando a CPU: O Papel Crítico do GPUDirect e RDMA
Aqui é onde separamos o hardware de consumo do hardware de infraestrutura real. Se a folha de especificações do seu armazenamento não menciona explicitamente suporte total e certificado para NVIDIA GPUDirect Storage (GDS) ou tecnologias similares de acesso direto à memória, feche a aba do navegador.
O conceito é o DMA (Direct Memory Access) aplicado ao ecossistema moderno.
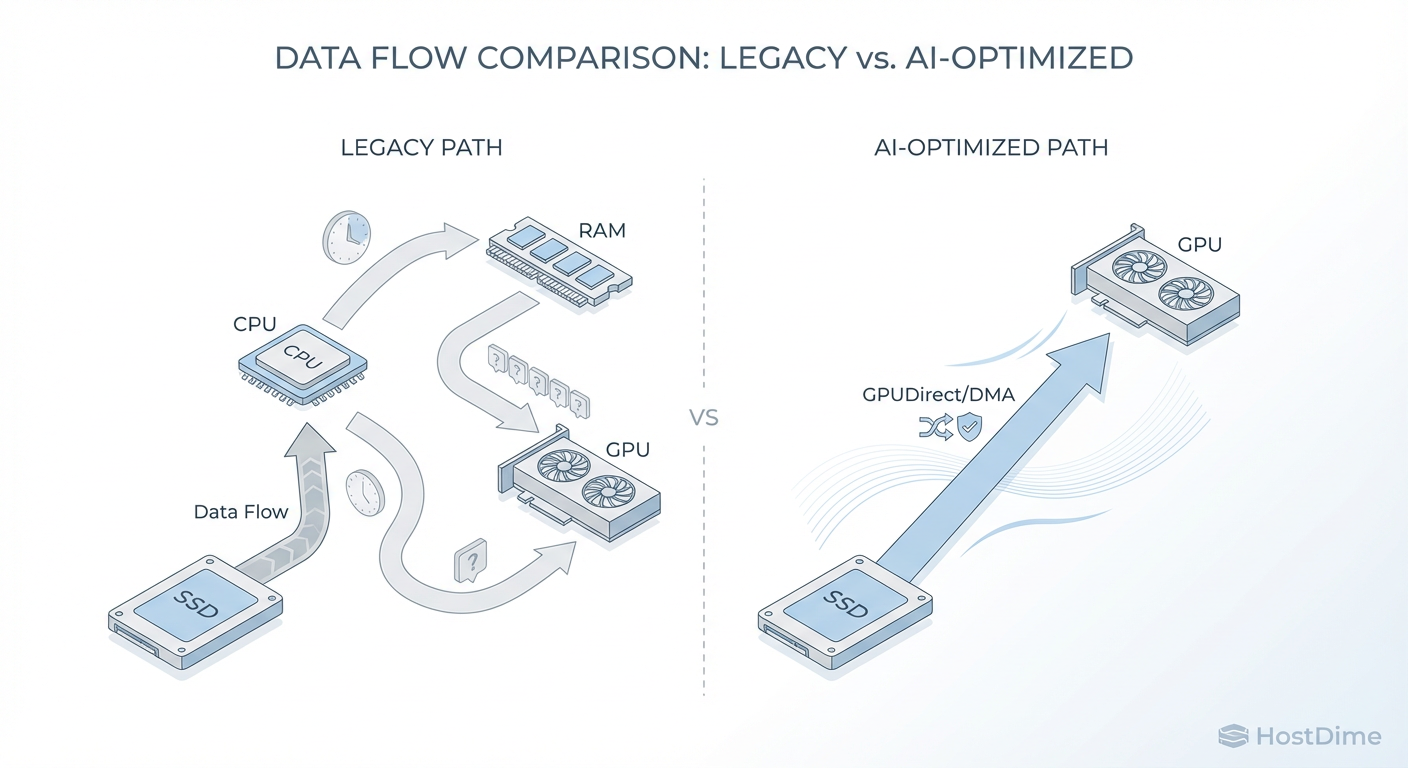 Figura: Fig. 1: The 'Bypass' Architecture. Marketing calls it magic; engineers call it Direct Memory Access (DMA). Eliminating the CPU bounce is the only way to saturate modern GPU interconnects.
Figura: Fig. 1: The 'Bypass' Architecture. Marketing calls it magic; engineers call it Direct Memory Access (DMA). Eliminating the CPU bounce is the only way to saturate modern GPU interconnects.
Como ilustrado acima, a arquitetura de "Bypass" permite que o armazenamento envie dados diretamente para a memória da GPU via PCIe, ignorando completamente o buffer da CPU e a memória do sistema principal.
Isso não é apenas "mais rápido". É uma mudança fundamental de arquitetura.
Sem GDS: A latência aumenta linearmente com a carga da CPU.
Com GDS: A latência permanece plana e a largura de banda escala com as lanes PCIe disponíveis.
Além disso, em clusters distribuídos, o RDMA (Remote Direct Memory Access) é obrigatório. Estamos falando de RoCE v2 (RDMA over Converged Ethernet) ou InfiniBand. Se o seu armazenamento "AI-Ready" depende de TCP/IP padrão com todo o overhead da pilha do kernel do OS, ele não é "AI-Ready", é apenas um NAS glorificado.
A Dança dos Protocolos: NVMe over Fabrics (NVMe-oF) vs. SAN Tradicional
Se alguém tentar lhe vender Fibre Channel para um cluster de treinamento de LLM em 2025, chame a segurança. O protocolo SCSI foi projetado para discos giratórios, não para a paralelismo massivo do NVMe.
Para IA, a única conversa aceitável é NVMe over Fabrics (NVMe-oF). Isso estende o protocolo NVMe através da rede, mantendo a semântica de filas paralelas que faz o NVMe ser rápido.
Aqui está a tabela da verdade que os vendedores de SAN legado odeiam:
| Característica | NVMe-oF (RoCE/TCP) | SAN Tradicional (iSCSI/FC) | Veredito para IA |
|---|---|---|---|
| Paralelismo | Até 64K filas (Queues) | 1 fila (Serializado) | NVMe-oF é mandatório para GPUs paralelas. |
| Latência Adicional | < 10 microsegundos | 100+ microsegundos | NVMe-oF vence. Latência mata inferência. |
| Overhead de CPU | Mínimo (Offload em NICs) | Alto (Processamento SCSI) | NVMe-oF libera a CPU para pré-processamento. |
| Throughput | Limitado pela Rede (400/800Gb) | Limitado pelo Protocolo | NVMe-oF satura links modernos. |
Nota do Engenheiro: Cuidado com implementações de "NVMe over TCP" que não utilizam SmartNICs ou DPUs para offload. Fazer encapsulamento NVMe/TCP na CPU principal vai destruir seus núcleos de processamento tão rápido quanto o iSCSI.
As Letras Miúdas: Endurance (DWPD), Checkpointing e Throttling Térmico
Vamos falar sobre o que está escondido no rodapé do PDF, em fonte tamanho 6.
1. O Problema do Checkpointing
Modelos de IA falham. Frequentemente. Para mitigar isso, o sistema despeja o estado da memória da GPU para o disco regularmente. Isso gera picos massivos de escrita sequencial.
O Risco: Drives "Read-Optimized" (frequentemente QLC com cache SLC pequeno) engasgam quando o cache enche. A velocidade cai de 7GB/s para 400MB/s (velocidade nativa do NAND). Seu treinamento para, suas GPUs ficam ociosas, você perde dinheiro.
A Solução: Procure por drives com Sustained Write Performance garantida, não apenas "Burst Performance".
2. Endurance (DWPD)
Muitos SSDs "AI" são classificados para 0.3 ou 0.5 DWPD. Para inferência? Ótimo. Para treinamento pesado com checkpointing constante? Eles vão virar peso de papel em 18 meses. Exija no mínimo 1 a 3 DWPD para camadas de cache de treinamento.
3. Throttling Térmico
Servidores de IA são fornos. Com densidades de potência chegando a 100kW por rack, seu SSD M.2 ou E1.S vai esquentar. Controladores modernos entram em thermal throttling a 70°C-80°C. Se o design térmico do chassi não for perfeito, seu SSD de 14GB/s vai operar a velocidades de USB 2.0 para se proteger. Verifique as curvas térmicas.
À Prova de Futuro: Onde o CXL 3.0 e o Processamento Near-Data se Encaixam
Se você está planejando infraestrutura para 2026 em diante, pare de olhar apenas para o PCIe Gen5. O CXL (Compute Express Link) é a verdadeira revolução.
O CXL permite o desacoplamento da memória. Com o CXL 3.0, podemos ter pools de memória compartilhada que tanto a CPU quanto a GPU podem acessar com coerência de cache, sem passar pelo gargalo de I/O tradicional.
Além disso, fique de olho no Computational Storage (CSD). A ideia é simples: em vez de mover 100TB de dados para a CPU para filtrar 100GB úteis, você envia a query para o SSD, e o SSD processa os dados localmente (usando FPGAs ou núcleos ARM integrados) e retorna apenas o resultado. Para pré-processamento de dados de IA (ETL), isso elimina terabytes de tráfego inútil no barramento.
Veredito: O Checklist para Infraestrutura de IA Real
Não compre o adesivo. Compre a arquitetura. Se você está assinando o cheque para o armazenamento do seu cluster de IA, use esta lista de verificação para filtrar o lixo de marketing:
Suporte a GPUDirect/RDMA: É nativo? Exige drivers proprietários obscuros?
Protocolo: É NVMe-oF ponta a ponta? Se houver conversão de protocolo no meio, é um gargalo.
Performance Sustentada: Qual é a velocidade de escrita após o cache SLC encher? (Peça o gráfico de "Steady State").
Fator de Forma e Térmica: É E1.S / E3 (EDSFF) projetado para fluxo de ar de servidor, ou é um M.2 de consumidor adaptado?
Caminho de Dados: A arquitetura suporta bypass de CPU real?
Se o vendedor gaguejar em qualquer um desses pontos, guarde seu dinheiro. O "AI-Ready" deles provavelmente só está pronto para o PowerPoint, não para o PyTorch.
Referências Técnicas
NVM Express Organization. (2024). NVM Express Base Specification 2.1 & NVMe over Fabrics. Disponível em: nvmexpress.org
NVIDIA. (2023). GPUDirect Storage: A Direct Path Between Storage and GPU Memory. Technical Whitepaper.
Compute Express Link Consortium. (2023). CXL 3.0 Specification: Enabling Fabric-Attached Memory.
SNIA (Storage Networking Industry Association). (2024). Computational Storage Architecture and Programming Model 1.0.

Carlos Ornelas
Mecânico de Datacenter
"Vivo nos corredores frios instalando racks e organizando cabeamento estruturado. Para mim, a nuvem é feita de metal, silício e ventoinhas que precisam girar sem parar."