Além do iostat: dissecando a latência de I/O com eBPF e observabilidade moderna

Abandone as médias enganosas do iostat. Aprenda a usar eBPF, biolatency e histogramas para visualizar a latência real de disco (P99) em ambientes Linux e Storage.
Você já esteve naquela sala de guerra às 3 da manhã. O banco de dados está engasgando, a aplicação está dando timeout, e o sysadmin aponta para o monitor e diz: "Mas o disco está tranquilo, o iostat mostra apenas 40% de utilização e latência média de 2ms".
Se você confia cegamente na média, você está voando às cegas.
No mundo do armazenamento moderno, onde dispositivos NVMe Gen5 alcançam milhões de IOPS e latências na casa dos microssegundos, as ferramentas legadas de monitoramento não contam mais a história completa. Elas mentem por omissão. Para entender o que realmente acontece quando seu servidor grava um bloco no disco, precisamos descer ao nível do kernel, abandonar as médias e abraçar a observabilidade de alta resolução.
Resumo em 30 segundos
- Médias escondem crimes: Uma latência média de 2ms pode esconder picos de 500ms que destroem a experiência do usuário (latência de cauda).
- O limite do iostat: Ferramentas baseadas em amostragem de
/proc/diskstatsnão conseguem capturar a volatilidade de SSDs NVMe modernos.- A revolução eBPF: Ferramentas como
biolatencyebiosnooppermitem rastrear cada operação de I/O individualmente com custo computacional irrisório.
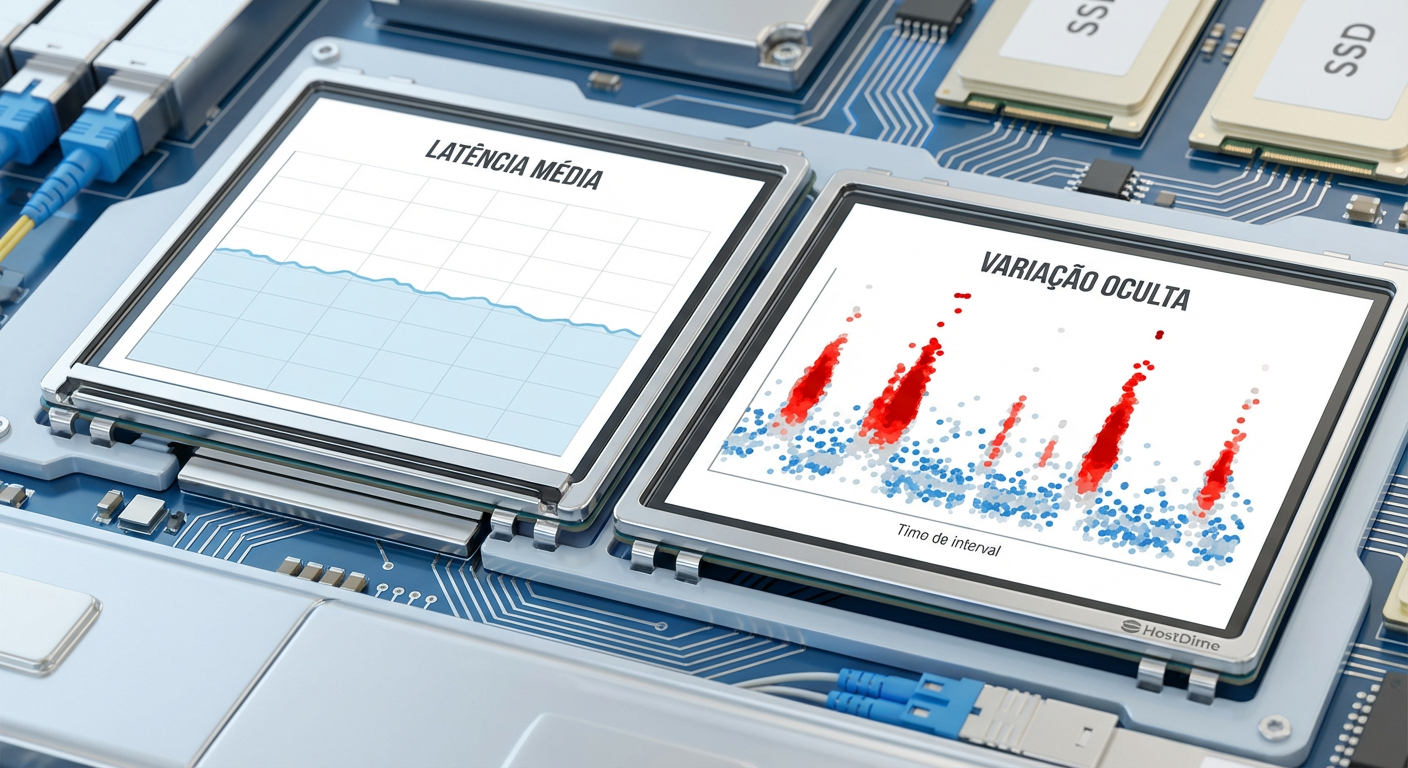 Figura: Visualização de dados comparando a "ilusão da média" versus a realidade dos picos de latência em um dashboard de observabilidade.
Figura: Visualização de dados comparando a "ilusão da média" versus a realidade dos picos de latência em um dashboard de observabilidade.
O mito da média e a invisibilidade do P99
A média é uma métrica de conforto. Ela nos diz que "na maior parte do tempo", as coisas estão bem. Mas sistemas de storage não falham na média; eles falham nos extremos.
Imagine um array de discos em um servidor de arquivos TrueNAS ou um cluster Ceph. Se você processa 10.000 requisições de leitura e 9.900 delas levam 100 microssegundos (cache), mas 100 delas levam 5 segundos (rotação de disco ou garbage collection de SSD), sua média ainda parecerá excelente. No entanto, para as 100 threads da aplicação que ficaram presas esperando esses 5 segundos, o sistema caiu.
É aqui que entra o conceito de Percentil 99 (P99). O P99 nos diz: "99% das requisições foram mais rápidas que X". Se o seu P99 é 500ms, significa que 1% dos seus usuários (ou transações) estão sofrendo severamente. Em escala, 1% pode ser milhares de erros por minuto.
💡 Dica Pro: Em storage, ignore a média. Configure seus alertas baseados no P95, P99 e, para sistemas críticos, P99.9. É na "cauda" da distribuição que os problemas de performance se escondem.
A anatomia de um I/O: rastreando a struct bio
Para entender por que o disco está lento, precisamos entender o caminho que o dado percorre. No Linux, quando uma aplicação pede um dado, não é mágica.
VFS (Virtual File System): A chamada de sistema entra.
Page Cache: O kernel verifica se o dado já está na RAM.
Block Layer: Se não estiver em cache, o pedido é transformado em uma estrutura chamada
struct bio.Driver NVMe/SCSI: A
struct bioé enviada para a fila do dispositivo.Hardware: O SSD ou HDD executa a operação física.
O problema das ferramentas tradicionais é que elas olham para esse fluxo de muito longe. O iostat, por exemplo, lê contadores incrementais. Ele não sabe qual bio demorou. Ele apenas sabe que, no último segundo, X bytes foram movidos e o tempo total de espera aumentou Y.
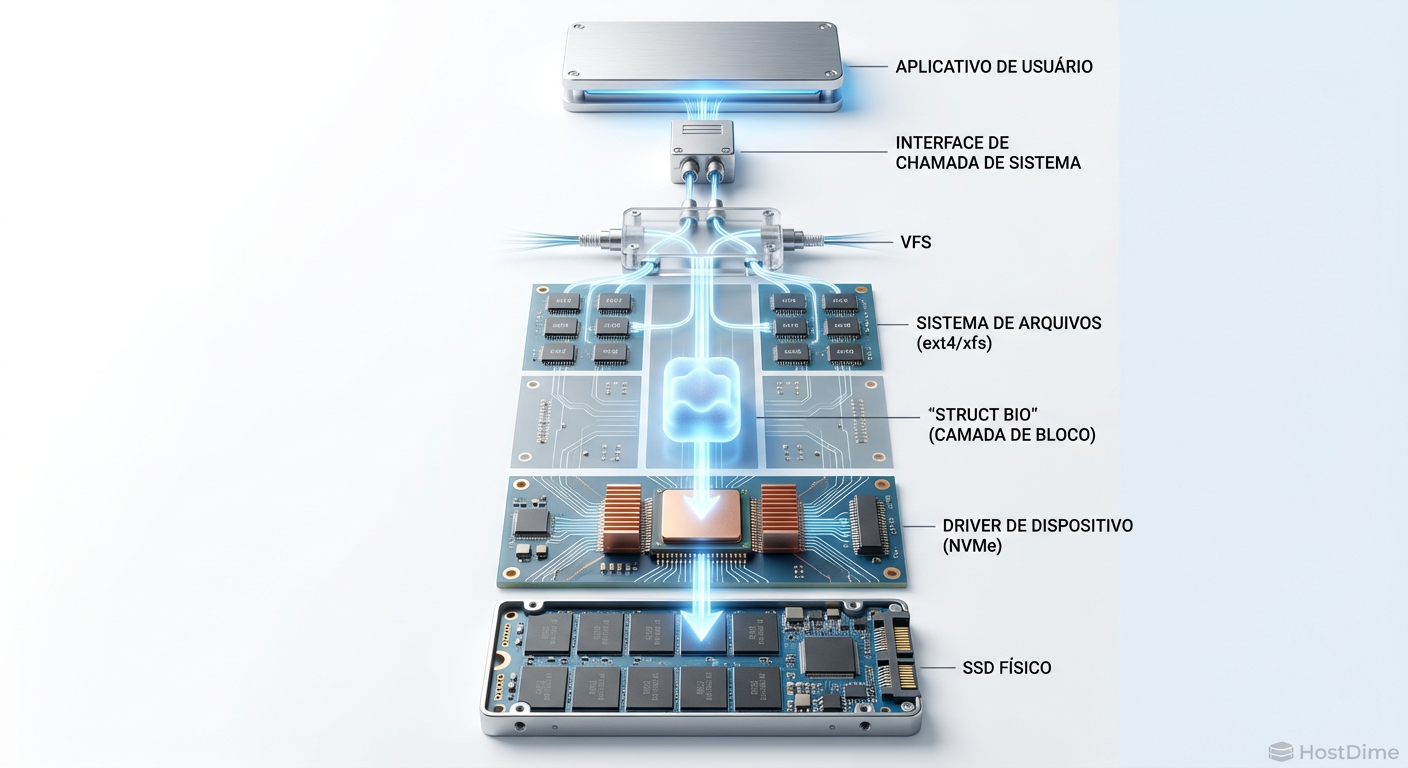 Figura: Diagrama da pilha de armazenamento do Linux destacando o fluxo da struct bio desde a aplicação até o dispositivo físico.
Figura: Diagrama da pilha de armazenamento do Linux destacando o fluxo da struct bio desde a aplicação até o dispositivo físico.
As limitações do iostat em um mundo NVMe
O iostat foi criado em uma época onde discos rígidos faziam 100 IOPS. Hoje, um único SSD NVMe Enterprise pode fazer 1.000.000 de IOPS.
Quando você roda iostat -x 1, você está pedindo uma atualização a cada segundo. Em um segundo, um SSD moderno pode ter processado centenas de milhares de operações. O iostat pega todos esses eventos, joga num liquidificador e te entrega um número: await (tempo médio de espera).
Se o seu SSD tem um "soluço" de 50ms devido a uma operação interna de wear leveling ou garbage collection, e isso acontece entre as amostras do iostat, esse pico é diluído na média de milhares de outras operações rápidas. Você vê await: 0.5ms. A aplicação sentiu 50ms. A desconexão é total.
Além disso, o iostat não te dá contexto. Ele diz que o disco está lento, mas não diz quem está causando a lentidão ou qual tipo de operação (leitura sequencial, escrita aleatória, sync) é a culpada.
Observabilidade granular com eBPF
Aqui entra o eBPF (Extended Berkeley Packet Filter). Pense no eBPF como uma máquina virtual segura e de alta performance que roda dentro do kernel do Linux. Ele nos permite rodar pequenos programas que "observam" funções do kernel sem precisar recompilar o kernel ou carregar módulos perigosos.
Para storage, isso é o Santo Graal. Podemos anexar sondas (kprobes) diretamente nas funções que processam a struct bio (como blk_account_io_start e blk_account_io_done).
Isso nos dá duas superpoderosas ferramentas do pacote BCC (BPF Compiler Collection):
1. Biolatency: O mapa de calor da performance
Em vez de médias, o biolatency mede o tempo de cada I/O individual e os agrupa em um histograma.
# biolatency -D /dev/nvme0n1
Tracing block device I/O... Hit Ctrl-C to end.
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 152 |******** |
8 -> 15 : 4215 |****************************************|
16 -> 31 : 1204 |*********** |
32 -> 63 : 54 | |
64 -> 127 : 2 | |
128 -> 255 : 0 | |
256 -> 511 : 0 | |
512 -> 1023 : 1 | |
Veja o exemplo acima (hipotético). A maioria das operações está entre 8 e 31 microssegundos (excelente para NVMe). Mas veja lá embaixo: temos 1 operação na faixa de 512-1023 microssegundos. O iostat jamais mostraria isso. O biolatency mostra a forma da latência.
2. Biosnoop: O "tcpdump" para discos
Se o biolatency te dá o panorama, o biosnoop te dá o culpado. Ele imprime uma linha para cada I/O completado, com detalhes de latência e processo.
TIME(s) COMM PID DISK T SECTOR BYTES LAT(ms)
0.000000 kworker/u32:1 142 nvme0n1 W 423424 4096 0.04
0.004123 postgres 8921 nvme0n1 R 992122 16384 5.21
No exemplo acima, vemos claramente que o processo postgres sofreu uma latência de 5.21ms para ler 16KB. Isso é acionável. Isso é dado real.
 Figura: Captura de tela de terminal exibindo um histograma de latência gerado por ferramenta CLI, mostrando uma distribuição bimodal.
Figura: Captura de tela de terminal exibindo um histograma de latência gerado por ferramenta CLI, mostrando uma distribuição bimodal.
Interpretando distribuições bimodais e latência de cauda
Quando você começa a usar histogramas, você frequentemente verá distribuições bimodais (dois picos). Em storage, isso conta histórias fascinantes:
Cache vs. Disco: O primeiro pico (microssegundos) são leituras resolvidas no cache do controlador ou DRAM do SSD. O segundo pico (milissegundos) são leituras que tiveram que buscar dados na NAND flash ou girar o prato do HDD.
Tiering Híbrido: Em sistemas como ZFS com L2ARC ou pools híbridos, um pico representa o SSD e o outro o HDD.
Contenção de Bloqueio: Às vezes, o segundo pico não é o disco, mas o tempo que a
struct bioficou parada na fila do kernel esperando um lock.
⚠️ Perigo: Se você vir uma distribuição com uma "cauda longa" (long tail) se estendendo para a direita, isso indica variância extrema. Em bancos de dados, essa cauda é o que causa timeouts intermitentes que fazem os desenvolvedores questionarem a sanidade da infraestrutura.
Comparativo: Ferramentas Tradicionais vs. Observabilidade Moderna
| Característica | iostat / sar | eBPF (biolatency/biosnoop) |
|---|---|---|
| Fonte de Dados | /proc/diskstats (Contadores) |
Eventos do Kernel (kprobes/tracepoints) |
| Granularidade | Média por intervalo (ex: 1 seg) | Cada evento de I/O individual |
| Overhead | Muito Baixo | Baixo (JIT compilado no kernel) |
| Visibilidade | Dispositivo inteiro | Processo, PID, Latência exata |
| Melhor uso | Tendências de longo prazo, capacidade | Debugging de performance, análise de picos |
Veredito Técnico
Não estamos mais em 2010. Gerenciar storage de alta performance com iostat é como tentar consertar um relógio suíço usando luvas de boxe.
Se você opera bancos de dados, clusters Kubernetes com PVs (Persistent Volumes) ou storage definido por software (Ceph/MinIO), a adoção de ferramentas baseadas em eBPF não é opcional, é mandatória. Comece instalando o pacote bcc-tools (ou bpfcc-tools no Debian/Ubuntu) em seu ambiente de staging hoje.
Na próxima vez que alguém disser "o disco está rápido na média", puxe o histograma do biolatency. Mostre a eles onde os dragões da latência realmente vivem. A observabilidade não é sobre ter mais dashboards; é sobre ver o que antes era invisível.
Por que o iostat não mostra picos de latência curtos?
O iostat exibe médias agregadas (geralmente em segundos). Um pico de 500ms diluído em uma média de 1 segundo pode parecer apenas um leve aumento no 'await', escondendo o impacto real na aplicação.O uso de eBPF causa overhead no servidor de storage?
O overhead é extremamente baixo. O código eBPF roda no kernel em bytecode otimizado (JIT) e só envia metadados para o userspace, diferentemente de ferramentas antigas que precisavam copiar grandes volumes de dados.Qual a diferença entre biolatency e biosnoop?
O 'biolatency' gera histogramas agregados para análise de distribuição (ótimo para ver tendências). O 'biosnoop' imprime cada evento de I/O individualmente em tempo real (ótimo para correlacionar um pico específico com um processo).Referências & Leitura Complementar
Gregg, Brendan. BPF Performance Tools. Addison-Wesley Professional, 2019. (A bíblia da observabilidade moderna).
Kernel.org. Block Layer IO Accounting. Documentação oficial sobre como o kernel contabiliza I/O.
NVM Express. NVM Express Base Specification 2.0. Detalhes sobre filas de comando e latência em dispositivos NVMe.
IO Visor Project. BCC - Tools for BPF-based Linux IO analysis. Repositório oficial no GitHub.

Lucas Ferreira
Engenheiro de Observabilidade
"Transformo o caos de logs, métricas e traces em clareza operacional. Minha missão é eliminar pontos cegos e garantir que nada permaneça invisível na infraestrutura."