Além do workload sintético: auditando a performance real com replay de traces de bloco

Descubra por que benchmarks sintéticos falham em prever o mundo real e aprenda a usar blktrace e FIO para capturar e reproduzir cargas de trabalho exatas em seus discos.
A folha de especificações do seu novo array All-Flash promete 1 milhão de IOPS. O fabricante garante latência sub-milissegundo. No entanto, na primeira semana de produção, o banco de dados engasga, os usuários reclamam de lentidão e o dashboard de monitoramento mostra picos inexplicáveis de latência. O que aconteceu? A resposta reside na desconexão fundamental entre como o hardware é vendido e como o software realmente o utiliza.
Benchmarks sintéticos são ferramentas de isolamento de variáveis, não simuladores de realidade. Quando executamos um teste padrão, estamos medindo o teto teórico do dispositivo sob condições ideais de laboratório. O tráfego real de um servidor de arquivos, de um hypervisor ou de um banco de dados transacional é sujo, caótico e, acima de tudo, dependente do tempo. Para validar infraestrutura crítica, precisamos abandonar os geradores de números aleatórios e adotar a auditoria forense de I/O: a captura e o replay de traces de bloco.
Resumo em 30 segundos
- A Ilusão Sintética: Ferramentas como CrystalDiskMark testam limites teóricos com padrões constantes, ignorando a natureza "bursty" (em rajadas) e mista das aplicações reais.
- A Verdade no Kernel: O
blktracecaptura cada operação de I/O na camada de bloco, criando uma "impressão digital" exata do comportamento da sua aplicação.- Validação por Replay: Reexecutar esses traces em hardware de teste é a única maneira científica de garantir que o armazenamento suportará a carga de produção sem surpresas de latência.
 Figura: Comparação visual entre a previsibilidade de um benchmark sintético e o caos de um workload real.
Figura: Comparação visual entre a previsibilidade de um benchmark sintético e o caos de um workload real.
A falácia da profundidade de fila (Queue Depth)
O pecado original da maioria dos benchmarks de marketing é a manipulação da Profundidade de Fila (Queue Depth ou QD). Para atingir aquele número impressionante de "1 Milhão de IOPS" estampado na caixa do SSD NVMe, os fabricantes saturam o controlador com centenas de requisições simultâneas (QD128 ou QD256).
Isso é ótimo para demonstrar a largura de banda máxima do barramento PCIe, mas é irrelevante para a latência percebida pela aplicação. A maioria das aplicações sensíveis à latência, como o PostgreSQL ou o Redis, opera predominantemente em QD1 a QD4. Elas são síncronas: o banco de dados envia uma gravação para o log de transações (WAL) e espera a confirmação do disco antes de prosseguir.
Se o seu benchmark foca em throughput massivo com alta paralelização, você está testando o cenário de backup, não o de operação transacional. O replay de traces elimina essa adivinhação, pois ele respeita o tempo original de submissão de cada I/O.
Anatomia de um trace de bloco
Para entender o que acontece no disco, precisamos descer ao porão do sistema operacional. No Linux, a camada de bloco (block layer) é o porteiro que recebe as requisições do sistema de arquivos e as organiza para o driver do dispositivo.
Ferramentas como o blktrace se acoplam a essa camada. Elas não apenas contam "quantos" I/Os ocorreram, mas registram:
O Setor Lógico: Onde exatamente no disco o dado foi requisitado.
O Tamanho: Quantos bytes foram movidos.
O Tipo: Leitura, escrita, descarte (trim), flush.
O Timestamp: O momento exato (em nanossegundos) da submissão e da conclusão.
Essa riqueza de dados nos permite ver padrões de localidade espacial (o quão "aleatório" é o acesso) e temporal (rajadas versus silêncio) que geradores sintéticos falham em emular.
 Figura: Diagrama da pilha de armazenamento do Linux destacando a posição estratégica da camada de bloco para interceptação de dados.
Figura: Diagrama da pilha de armazenamento do Linux destacando a posição estratégica da camada de bloco para interceptação de dados.
Tabela: Sintético vs. Replay de Trace
| Característica | Benchmark Sintético (fio/CDM) | Replay de Trace (blktrace) |
|---|---|---|
| Padrão de Acesso | Algorítmico (100% Seq ou 100% Rand) | Orgânico (Misto, com localidade real) |
| Tempo | Constante / Tenta saturar | Respeita os intervalos originais (Think time) |
| Objetivo | Encontrar o limite do hardware | Validar o comportamento da aplicação |
| Complexidade | Baixa (Plug & Play) | Alta (Requer captura e processamento) |
| Risco | Baixo | Alto (Se executado incorretamente em produção) |
Metodologia de captura e replay
A implementação dessa auditoria exige rigor. Não estamos apenas "rodando um teste", estamos conduzindo um experimento científico controlado. O processo se divide em três fases: Captura, Processamento e Replay.
1. Captura (O ambiente de produção)
O objetivo é gravar o comportamento da aplicação em seu pico de carga. Utilizamos o blktrace.
💡 Dica Pro: O
blktracegera um volume massivo de dados. Grave apenas por períodos curtos (ex: 15 a 30 minutos) durante o horário de pico, e garanta que o destino dos logs não seja o mesmo disco que está sendo auditado para evitar o "efeito observador".
Exemplo de comando de captura:
# Captura I/O no dispositivo nvme0n1, salvando no diretório /tmp/traces
sudo blktrace -d /dev/nvme0n1 -D /tmp/traces -w 900
2. Processamento
Os arquivos brutos gerados pelo blktrace são binários fragmentados por CPU. Precisamos unificá-los e convertê-los em um formato que o motor de replay (geralmente o fio) consiga entender. O utilitário blkparse faz a leitura humana, mas para replay, usamos ferramentas de conversão como iolog ou o próprio parser do fio.
3. Replay (O ambiente de laboratório/staging)
Aqui reside o perigo e a glória. No ambiente de teste (que deve ter hardware idêntico ou o hardware alvo da migração), usamos o fio para reencenar o tráfego.
⚠️ Perigo: O replay de traces de escrita é destrutivo. Ele vai escrever nos mesmos setores lógicos que foram escritos na produção. Se você rodar isso no seu disco de boot ou em um banco de dados ativo, você perderá dados. Execute APENAS em discos de teste vazios ou clonados para este fim.
Configuração típica do fio para replay:
[replay-job]
ioengine=libaio
direct=1
read_iolog=trace_producao.bin
replay_no_stall=0
replay_redirect=/dev/nvme1n1
O parâmetro replay_no_stall=0 é crucial. Ele instrui o fio a respeitar os tempos de espera originais entre os I/Os. Se definido como 1, ele tentará executar tudo o mais rápido possível, transformando o teste em um benchmark sintético glorificado e perdendo o propósito da auditoria temporal.
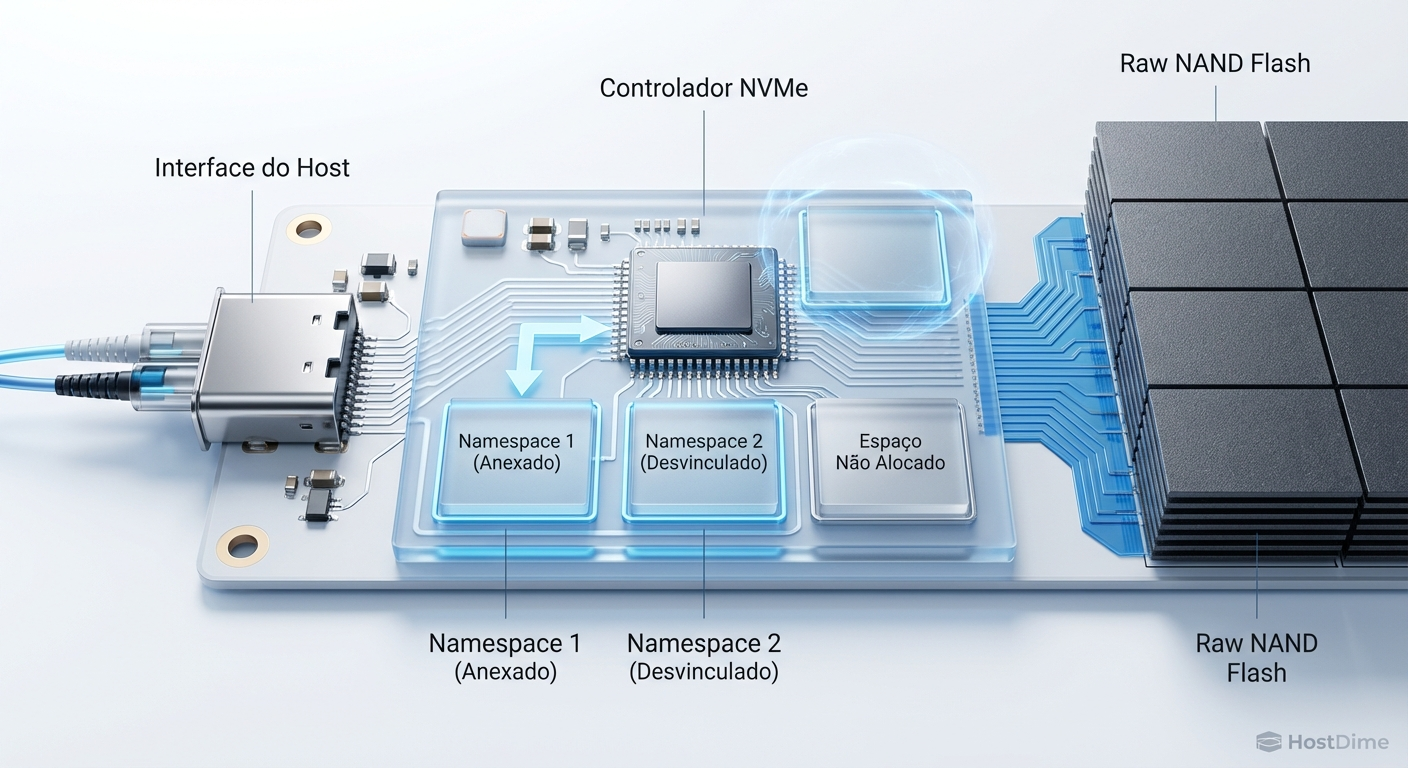 Figura: Alerta visual sobre a natureza destrutiva do replay de traces de escrita.
Figura: Alerta visual sobre a natureza destrutiva do replay de traces de escrita.
A tirania da latência de cauda (Tail Latency)
Ao analisar os resultados do replay, ignore a latência média. A média é uma métrica que esconde os crimes do armazenamento. Em um sistema moderno, a média pode ser excelente (ex: 200 microssegundos), mas se 1% das requisições levar 500 milissegundos, sua aplicação parecerá travada para o usuário final.
O replay de traces expõe impiedosamente a "latência de cauda" (Percentil 99 ou P99).
Imagine um cenário onde o Garbage Collection (GC) do SSD entra em ação. Em um teste sintético de escrita sequencial, o controlador do SSD consegue prever e otimizar o GC. Em um trace real, com escritas aleatórias esporádicas seguidas de uma rajada intensa, o controlador pode engasgar, elevando a latência momentaneamente.
Esses picos são invisíveis em folhas de dados, mas são a causa raiz de timeouts em aplicações web e quedas de conexões em clusters de alta disponibilidade.
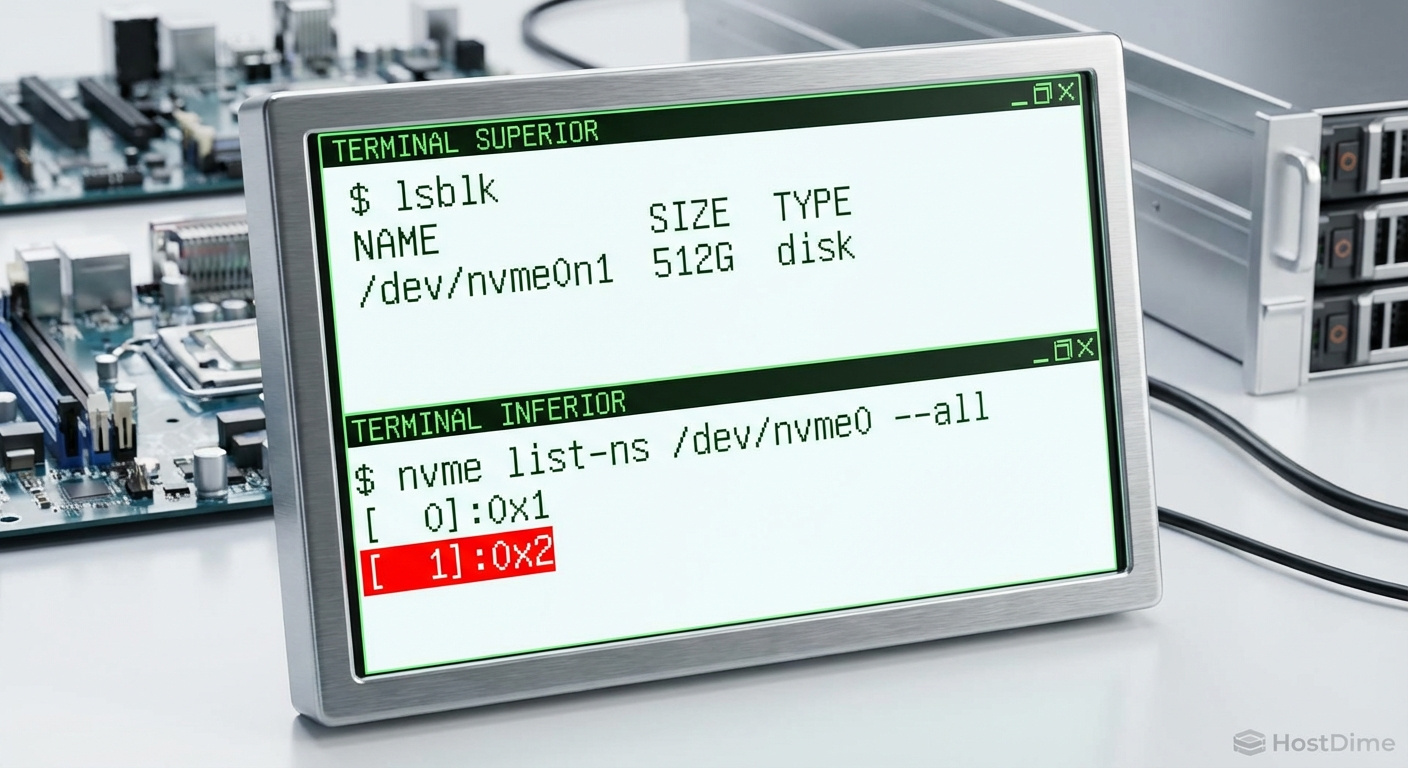 Figura: Gráfico de distribuição de latência destacando a cauda longa (P99) que afeta a performance percebida.
Figura: Gráfico de distribuição de latência destacando a cauda longa (P99) que afeta a performance percebida.
Otimização baseada em evidências
Uma vez que você possui o trace, o poder está em suas mãos. Você pode testar diferentes configurações de RAID, diferentes sistemas de arquivos (XFS vs EXT4 vs ZFS) ou diferentes schedulers de I/O (kyber, bfq, none) usando exatamente a mesma carga de trabalho.
Isso permite responder perguntas complexas com certeza binária:
"Se migrarmos de SATA SSD para NVMe QLC, o aumento de latência na escrita afetará nosso banco de dados?"
"O cache de escrita do controlador RAID está fazendo diferença real com este padrão de acesso?"
Não há "eu acho" ou "o vendedor disse". Há apenas o tempo de execução do trace e os histogramas de latência resultantes.
 Figura: Cenário de laboratório validando diferentes configurações de armazenamento contra o mesmo trace.
Figura: Cenário de laboratório validando diferentes configurações de armazenamento contra o mesmo trace.
O imperativo da validação
A infraestrutura de armazenamento moderna é complexa demais para ser resumida em um único número de IOPS. Caches SLC, tiering, deduplicação e compressão em linha reagem de forma imprevisível a dados reais.
Adotar o replay de traces de bloco como padrão de validação para novas aquisições ou mudanças arquiteturais não é apenas preciosismo técnico; é uma apólice de seguro. Ele separa os engenheiros que esperam que tudo funcione daqueles que sabem que vai funcionar. Antes de assinar a ordem de compra do próximo petabyte, capture o trace, faça o replay e deixe os dados decidirem.
Referências & Leitura Complementar
Jens Axboe (Autor do fio/blktrace): fio - Flexible I/O Tester User Guide.
Man Pages:
man 8 blktrace,man 1 blkparse.SNIA (Storage Networking Industry Association): Solid State Storage Performance Test Specification (PTS) - Para metodologias de pré-condicionamento.
Kernel.org Documentation: Block Layer Statistics.
Perguntas Frequentes (FAQ)
Por que benchmarks como CrystalDiskMark não refletem a performance real de um banco de dados?
Ferramentas sintéticas simples geram padrões de acesso constantes e previsíveis (ex: 100% leitura sequencial), enquanto bancos de dados reais produzem I/O misto, com rajadas (bursts) e dependências de tempo que estressam o controlador do disco de forma diferente.O que é o blktrace e como ele ajuda na análise de storage?
O blktrace é uma ferramenta de baixo nível do Linux que captura eventos de I/O diretamente na camada de bloco do kernel, permitindo registrar exatamente quais setores foram acessados e quando, criando um 'mapa' fiel da carga de trabalho.É seguro rodar um replay de trace em um ambiente de produção?
Não. O replay de traces de escrita sobrescreve dados nos endereços de bloco gravados. Esse procedimento deve ser realizado estritamente em ambientes de staging ou laboratório com discos dedicados para validação.
Dr. Elena Kovic
Metodologista de Benchmark
"Desmonto o marketing com análise estatística rigorosa. Meus benchmarks isolam cada variável para revelar a performance crua e sem filtros do hardware corporativo."