Além dos IOPS: A Verdade Sobre Storage para Bancos Vetoriais e RAG

Esqueça os benchmarks de marketing. Descubra por que seu SSD NVMe de '7000 MB/s' pode ser o gargalo da sua pipeline de IA e como testar a performance real para Vector Search.
A indústria de IA generativa tem uma obsessão doentia por GPUs. Enquanto arquitetos de sistemas brigam por alocações de H100s ou clusters de Blackwell, um componente crítico na infraestrutura de RAG (Retrieval-Augmented Generation) está sendo negligenciado, resultando em latências de inferência inaceitáveis. Estou falando do subsistema de armazenamento.
Se você está construindo aplicações que utilizam bancos de dados vetoriais (Vector DBs) como Milvus, Qdrant, Weaviate ou extensões pgvector, e seu índice não cabe inteiramente na RAM, seu SSD não é apenas um repositório de dados. Ele é parte ativa da memória computacional. A maioria dos benchmarks de armazenamento que vejo por aí — focados em transferências sequenciais de grandes arquivos ou IOPS de marketing em Queue Depth (QD) 32 — são estatisticamente irrelevantes para essa carga de trabalho.
Neste artigo, vamos dissecar o comportamento de I/O de algoritmos de busca de vizinhos mais próximos (ANN) quando operam em modo out-of-core (fora da memória RAM) e por que aquele SSD Gen5 de consumo que promete 14 GB/s pode ser pior que um drive enterprise de três anos atrás.
Resumo em 30 segundos
- Largura de banda é irrelevante: Buscas vetoriais operam em baixíssima profundidade de fila (QD1-QD4), onde a latência absoluta da mídia NAND dita a performance, não a velocidade do barramento PCIe.
- O problema do p99: Em RAG, uma única leitura lenta no disco (latência de cauda) pode travar toda a resposta da LLM, pois a busca vetorial é um pré-requisito bloqueante.
- Aleatoriedade hostil: Algoritmos como DiskANN geram padrões de leitura randômica não-previsíveis que derrotam os mecanismos de read-ahead e cache da maioria dos controladores de SSD de consumo.
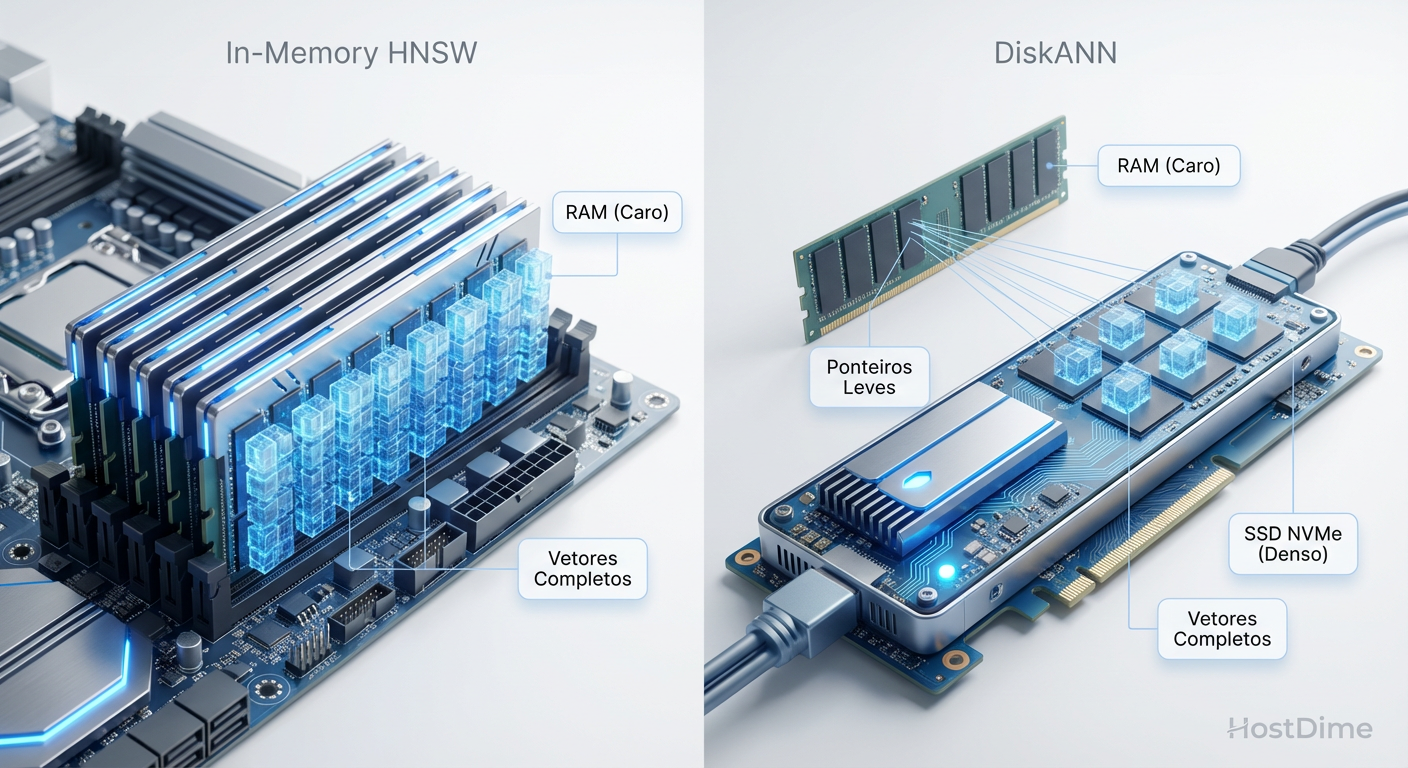 Fig. 1: O trade-off fundamental: HNSW puro (RAM) vs. DiskANN (Storage Híbrido).
Fig. 1: O trade-off fundamental: HNSW puro (RAM) vs. DiskANN (Storage Híbrido).
O gargalo invisível na latência de geração
Para entender o problema do armazenamento, precisamos olhar para o pipeline de uma aplicação RAG típica. O processo não começa na GPU. Começa na busca.
O usuário envia um prompt.
O sistema converte o prompt em um vetor (embedding).
O banco vetorial varre bilhões de vetores para encontrar os "vizinhos mais próximos" (contexto relevante).
O contexto é recuperado e enviado à LLM.
A LLM gera a resposta (Time to First Token - TTFT).
Se o passo 3 demora 500ms porque seu storage está engasgando com leituras aleatórias, não importa se sua GPU consegue gerar tokens em 10ms. A experiência do usuário já foi degradada.
O cenário ideal é manter todo o índice vetorial na RAM. O algoritmo HNSW (Hierarchical Navigable Small World) é o padrão ouro para isso. No entanto, vetores são pesados. Um índice de 1 bilhão de vetores com 1536 dimensões (padrão OpenAI) pode facilmente ultrapassar terabytes de memória. A custos de DRAM atuais, isso é inviável para a maioria das implementações on-premise ou home labs avançados.
A solução é o armazenamento híbrido ou out-of-core, onde o grafo de navegação reside parcialmente ou totalmente no disco (SSD/NVMe). É aqui que a física do NAND flash colide com a matemática dos grafos.
Por que índices vetoriais HNSW odeiam seu SSD
Diferente de um banco de dados relacional (SQL) que pode fazer varreduras sequenciais ou usar índices B-Tree altamente otimizados para blocos de disco, a busca vetorial é inerentemente caótica em termos de I/O.
Imagine um grafo HNSW como uma rede de cidades conectadas por estradas. Para encontrar o destino, você viaja de uma cidade para outra. Em um cenário out-of-core (como na implementação DiskANN da Microsoft ou no Vamana), cada "cidade" (nó do grafo) é um endereço lógico no disco.
O problema é a dependência de dados. Você não sabe qual será o próximo nó a ser lido até que tenha lido e processado o nó atual.
💡 Dica Pro: Em ciência da computação, chamamos isso de "pointer chasing" (perseguição de ponteiros). Isso impede que o controlador do SSD faça prefetching eficaz, pois não há um padrão previsível para o próximo endereço LBA (Logical Block Address).
Isso força o SSD a operar quase exclusivamente em Queue Depth 1 (QD1) por thread de busca. Se você tem 4 vCPUs fazendo buscas, seu SSD está vendo QD4. A maioria dos drives de consumo é otimizada para QD32 ou QD128 para atingir aqueles números bonitos da caixa. Em QD1, a latência nativa da célula de memória é exposta sem piedade.
 Fig. 5: Visualização de uma 'Beam Search'. Cada salto no grafo pode representar uma leitura física no disco em arquiteturas DiskANN.
Fig. 5: Visualização de uma 'Beam Search'. Cada salto no grafo pode representar uma leitura física no disco em arquiteturas DiskANN.
A falácia dos benchmarks sintéticos de 4k
Vamos analisar um cenário real de laboratório. Pegamos um SSD Gen4 topo de linha de consumo (focado em gamers) e um SSD Enterprise Datacenter (focado em consistência), ambos lançados por volta de 2023/2024.
O marketing do drive gamer promete "1.500.000 IOPS". O drive enterprise promete modestos "200.000 IOPS". Um usuário leigo escolheria o drive gamer para seu servidor de vetores. Seria um erro catastrófico.
Esses 1,5 milhão de IOPS são medidos em QD256 com múltiplos threads. Mas veja o que acontece em QD1 Random Read 4k:
Drive Gamer: ~60-80 µs (microssegundos) de latência média.
Drive Enterprise: ~30-50 µs de latência média.
A diferença parece pequena? Multiplique isso pelo número de saltos no grafo. Uma busca vetorial pode exigir visitar 200 a 500 nós.
500 saltos x 80 µs = 40ms apenas de tempo de disco.
500 saltos x 30 µs = 15ms apenas de tempo de disco.
Estamos falando de uma diferença de mais de 100% no tempo de resposta, antes mesmo de a CPU fazer qualquer cálculo de similaridade de cosseno. E isso é considerando a latência média. A situação piora quando olhamos para a estabilidade.
 Fig. 2: A ilusão da largura de banda. Buscas vetoriais raramente saturam o barramento, tornando a latência em baixa QD o fator crítico.
Fig. 2: A ilusão da largura de banda. Buscas vetoriais raramente saturam o barramento, tornando a latência em baixa QD o fator crítico.
Metodologia de teste para algoritmos out-of-core
Se você vai validar armazenamento para cargas de trabalho de IA/Vetores, pare de usar o CrystalDiskMark padrão. Ele é uma ferramenta de "verificação rápida", não de diagnóstico de engenharia.
Para simular uma carga de trabalho de banco vetorial, utilizamos o FIO (Flexible I/O Tester) no Linux, mas com parâmetros muito específicos que isolam a latência de leitura randômica.
O script de teste recomendado
Não basta rodar randread. Precisamos travar a profundidade de fila e usar a engine de I/O correta. Em kernels Linux modernos (5.10+), o io_uring é mandatório para reduzir o overhead de syscalls, permitindo que vejamos a latência do dispositivo, não do kernel.
fio --name=vector_sim_qd1 \
--filename=/dev/nvme0n1 \
--ioengine=io_uring \
--rw=randread \
--bs=4k \
--direct=1 \
--numjobs=1 \
--iodepth=1 \
--runtime=60 \
--time_based \
--group_reporting
⚠️ Perigo: O parâmetro
--direct=1é crucial. Ele ignora o Page Cache do sistema operacional (RAM). Se você não usar isso, estará testando a velocidade da sua memória DDR4/DDR5, invalidando o teste de storage. Bancos vetoriais out-of-core são desenhados assumindo que os dados NÃO estão em cache.
Ao analisar os resultados, ignore a coluna "Bandwidth". Foque exclusivamente em:
lat (usec) avg: Latência média.
clat (usec) p99: Latência no percentil 99.
clat (usec) p99.99: Latência de cauda extrema.
 Fig. 3: A interface física importa. NVMe reduz a latência de protocolo, crucial para os milhares de saltos em um grafo HNSW.
Fig. 3: A interface física importa. NVMe reduz a latência de protocolo, crucial para os milhares de saltos em um grafo HNSW.
Interpretando a latência de cauda p99 em pipelines RAG
A latência média é uma métrica de vaidade. A latência p99 é onde a realidade reside.
Em um sistema RAG, a busca vetorial raramente busca apenas um segmento. Frequentemente, fazemos uma busca "Beam Search" ou buscamos múltiplos candidatos para re-ranking posterior. Se você pede ao banco de dados os "Top 10" resultados, o banco pode ter que acessar milhares de páginas de disco.
Se o seu SSD tem uma latência média de 50µs, mas a cada 100 leituras ele engasga para 2ms (2000µs) devido a uma operação de Garbage Collection interna ou superaquecimento do controlador, sua busca inteira será penalizada por esse atraso.
Isso é a "Latência de Cauda". Em SSDs de consumo baseados em QLC (Quad-Level Cell) ou mesmo TLC de baixa qualidade sem DRAM cache dedicada, esses picos são frequentes. O controlador precisa pausar as leituras para reorganizar blocos de dados ou limpar células inválidas.
Para vetores, a consistência é rei. Um drive Optane (agora descontinuado, mas ainda a referência técnica) ou drives baseados em SLC/ZNS (Zoned Namespaces) oferecem uma linha quase plana de latência. Drives NVMe Gen5 modernos focam tanto em throughput sequencial que muitas vezes negligenciam essa consistência em baixa QD.
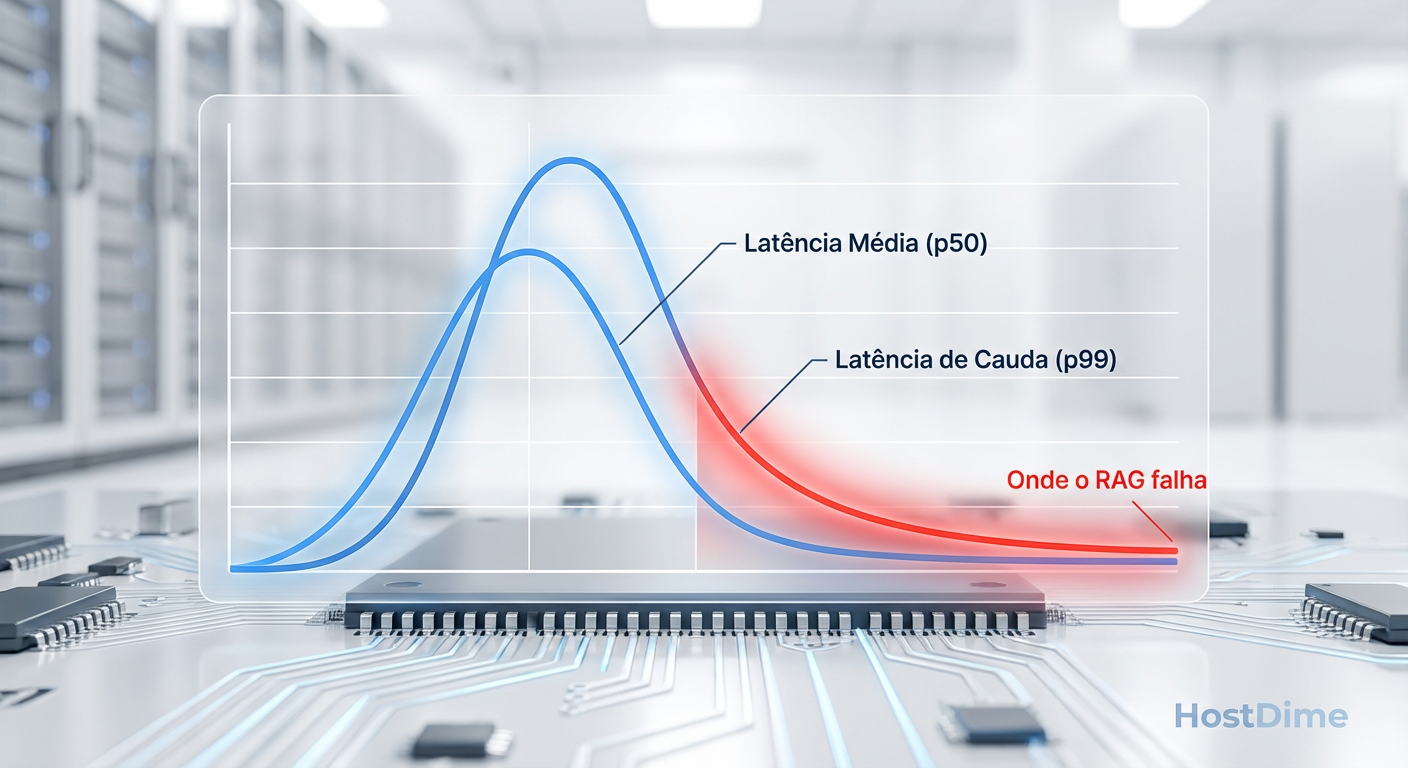 Fig. 4: A tirania do p99. Em RAG, se um vetor demora, toda a resposta da IA trava.
Fig. 4: A tirania do p99. Em RAG, se um vetor demora, toda a resposta da IA trava.
O impacto da interface e protocolo
Muitos entusiastas perguntam se vale a pena migrar de SATA para NVMe para um Home Lab de IA. A resposta é um "sim" retumbante, mas não pelos motivos que você pensa (MB/s).
A interface NVMe reduz drasticamente a latência de protocolo em comparação ao AHCI (SATA). Cada microssegundo economizado na pilha de software conta quando você está fazendo milhares de pequenas leituras sequenciais dependentes.
Além disso, tecnologias emergentes como CXL (Compute Express Link) prometem trazer a latência do armazenamento para níveis próximos da memória. No entanto, no cenário atual de 2025/2026, para a maioria das implementações, um bom SSD Enterprise NVMe U.2 ou U.3 conectado via PCIe Gen4 é o "sweet spot".
Tabela Comparativa: Hierarquia de Latência para Vetores
| Tecnologia | Latência Típica (QD1 4k Read) | Adequação para Vector Search |
|---|---|---|
| DRAM (In-Memory) | ~0.1 µs | Perfeito (mas caro e volátil) |
| Optane (P5800X) | ~5-10 µs | O "Santo Graal" do armazenamento tiering |
| SSD Enterprise (SLC/TLC) | ~20-40 µs | Excelente para DiskANN/SPANN |
| SSD Consumo High-End | ~50-80 µs | Aceitável para labs, risco de p99 alto |
| SSD QLC / SATA | >100 µs (picos de ms) | Inviável para produção séria |
| HDD (Mecânico) | ~10.000 µs | Inútil para busca vetorial randômica |
Alerta Técnico
Não caia na armadilha de superdimensionar a capacidade em detrimento da latência. Para bancos vetoriais, 1TB de armazenamento flash de baixa latência (como drives baseados em Kioxia XL-FLASH ou Samsung Z-NAND) vale muito mais do que 8TB de QLC lento.
Se você está projetando a infraestrutura para sua empresa ou seu laboratório pessoal de IA, priorize IOPS em QD1 e estabilidade de latência (QoS). Ignore os números sequenciais da caixa. Seu banco vetorial nunca lerá arquivos sequencialmente. Ele saltará pelo disco como uma agulha em um palheiro, e a velocidade com que seu disco consegue mudar de posição é o único fator que determinará se seu chatbost responde instantaneamente ou deixa o usuário esperando.
Referências & Leitura Complementar
Subramanya, S. J., et al. (2019). "DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node." NeurIPS. (O paper fundamental que descreve o uso de SSDs para índices vetoriais).
SNIA (Storage Networking Industry Association). "Solid State Storage Performance Test Specification (PTS)". (Metodologia padrão ouro para teste de SSDs, focada em pré-condicionamento).
JEDEC. "JESD218: Solid-State Drive (SSD) Requirements and Endurance Test Method".
Perguntas Frequentes
P: Posso usar SSDs SATA para bancos vetoriais em um Home Lab? R: Pode, mas espere um gargalo severo. A latência inerente do protocolo SATA e a fila de comando limitada (AHCI) adicionarão um overhead significativo a cada salto do grafo HNSW. Para testes pequenos funciona, para produção ou datasets grandes (>10M vetores), evite.
P: O que é "Warmup" no contexto de storage vetorial? R: Muitos bancos de dados (como Qdrant ou Elasticsearch) tentam carregar as partes mais acessadas do índice (os nós superiores do grafo HNSW) para a RAM ou para o cache do sistema operacional. O "warmup" é o processo de rodar queries falsas para forçar esse carregamento antes de abrir o sistema para usuários reais.
P: RAID 0 ajuda na performance de busca vetorial? R: Surpreendentemente, nem sempre. RAID 0 aumenta o throughput e IOPS em altas QDs. Mas em QD1 (latência pura), o overhead do software de RAID ou da controladora pode até adicionar latência. Para vetores, um único drive muito rápido geralmente supera dois drives médios em RAID 0.
P: Qual a diferença entre HNSW e DiskANN? R: HNSW é uma estrutura de dados projetada primariamente para RAM. DiskANN (e variantes como Vamana) é uma modificação dessa estrutura otimizada para minimizar o número de acessos ao disco e agrupar dados vizinhos no mesmo bloco físico, tornando-o viável para armazenamento flash.

Dr. Elena Kovic
Metodologista de Benchmark
"Desmonto o marketing com análise estatística rigorosa. Meus benchmarks isolam cada variável para revelar a performance crua e sem filtros do hardware corporativo."