Alta disponibilidade de bolso: cluster Proxmox com mini PCs e Ceph

Transforme mini PCs N100 em um datacenter resiliente. Guia prático para configurar Proxmox HA, rede 2.5GbE e storage distribuído Ceph no seu home lab.
Alta disponibilidade de bolso: cluster Proxmox com mini PCs e Ceph
Você já acordou no meio da noite com aquele silêncio ensurdecedor? Não o silêncio da paz, mas o silêncio de quando as ventoinhas do seu servidor pararam de girar. O home lab caiu. O Plex está offline, o Home Assistant não responde e sua automação de café da manhã falhou. Se você roda tudo em uma única máquina, você tem um SPOF (Single Point of Failure ou Ponto Único de Falha).
A solução corporativa seria comprar dois servidores Dell R740, uma SAN dedicada e licenças caríssimas. Mas nós somos entusiastas de home lab. Nós queremos redundância de datacenter com orçamento de mesada e consumo de energia de uma lâmpada LED. É aqui que entra a mágica dos Mini PCs modernos, redes 2.5GbE e o sistema de arquivos Ceph.
Resumo em 30 segundos
- Adeus Ponto Único de Falha: Um cluster de 3 nós permite que um servidor morra fisicamente sem derrubar seus serviços críticos.
- Hardware Acessível: Mini PCs com processador Intel N100 e switches 2.5GbE baratos tornaram a hiperconvergência (HCI) viável para uso doméstico.
- Ceph é a Chave: Em vez de RAID local ou um NAS central, o Ceph espalha seus dados entre os três nós em tempo real. Se um nó cai, os dados continuam acessíveis nos outros dois.
O fim do ponto único de falha no home lab
Durante anos, a "alta disponibilidade" em casa significava ter um backup frio em um HD externo USB. Se o servidor principal queimasse a fonte, você passava o fim de semana reinstalando o Linux e restaurando backups. Isso não é disponibilidade, é recuperação de desastre (e das lentas).
A verdadeira Alta Disponibilidade (HA - High Availability) significa que, se eu puxar o cabo de força do "Nó 1", a Máquina Virtual (VM) que estava rodando nele reinicia automaticamente no "Nó 2" em questão de segundos. Ou melhor, se usarmos migração ao vivo antes da falha, ninguém na casa percebe que algo aconteceu.
Para conseguir isso, precisamos de três pilares: computação redundante (mais de um PC), rede rápida (para eles conversarem) e armazenamento compartilhado. Antigamente, armazenamento compartilhado exigia um NAS caro via iSCSI ou NFS. Hoje, usamos o armazenamento local dos próprios nós para criar um "NAS virtual distribuído".
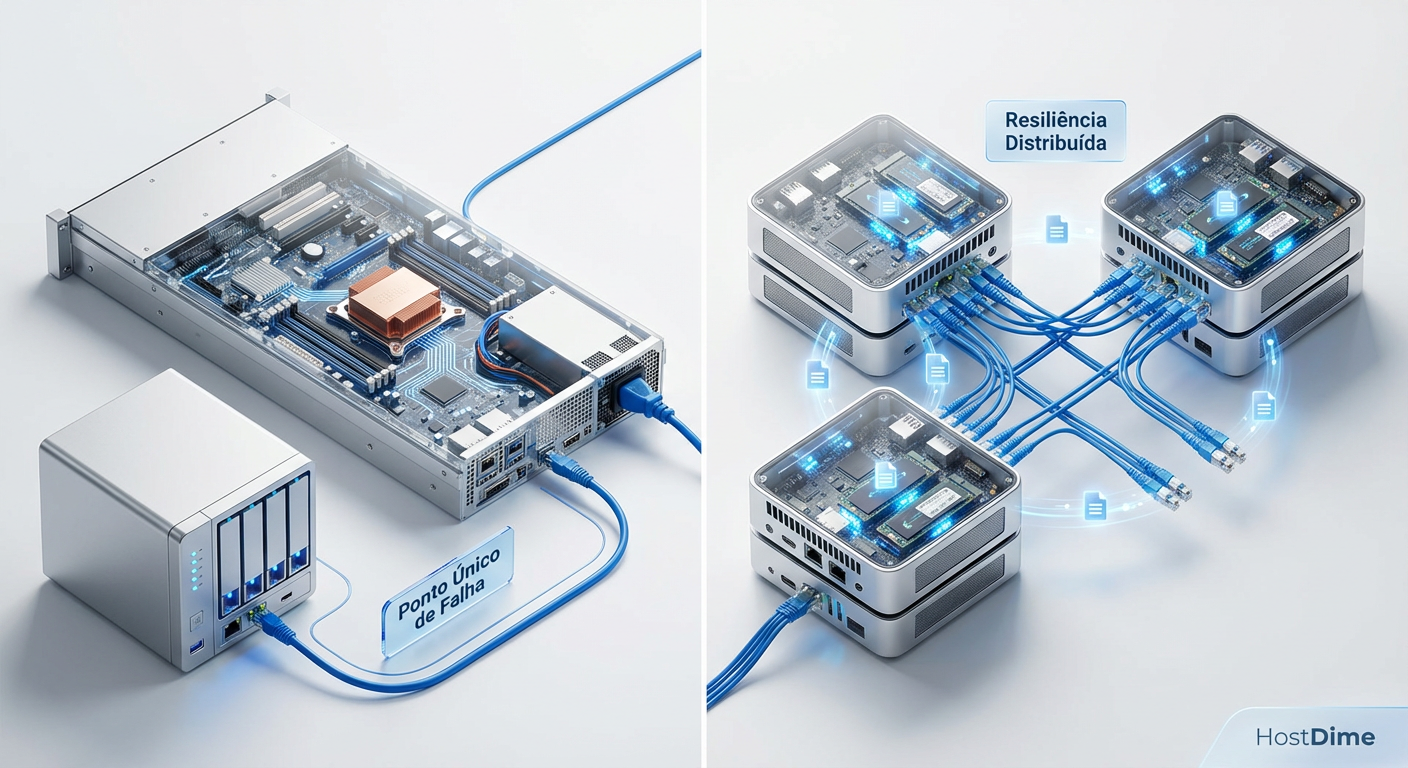 Figura: Comparativo visual: Infraestrutura tradicional com ponto único de falha vs. Cluster Hiperconvergente distribuído.
Figura: Comparativo visual: Infraestrutura tradicional com ponto único de falha vs. Cluster Hiperconvergente distribuído.
A trindade do hardware: escolhendo mini PCs N100 e switches 2.5GbE
Por que estamos falando disso agora? Porque o hardware finalmente alcançou o software. O lançamento dos processadores Intel N100 (arquitetura Alder Lake-N) mudou o jogo. Esses chips quad-core consomem cerca de 6W a 15W, custam uma fração de um servidor usado e entregam performance suficiente para rodar o Proxmox e várias VMs leves.
Para montar um cluster de HA confiável, você precisa de três nós. "Ah, mas eu não posso fazer com dois?" Poder, pode. Mas não deve. Um cluster de 2 nós sofre do problema de "split-brain" (cérebro dividido). Se a rede entre eles cai, ambos acham que são o único sobrevivente e tentam assumir o controle, corrompendo os dados. Com três nós, sempre haverá uma maioria (2 contra 1) para manter o quórum e a sanidade do cluster.
💡 Dica Pro: Ao escolher seus Mini PCs, procure modelos que tenham duas portas de rede 2.5GbE. Você vai precisar separar o tráfego de gerenciamento do tráfego de replicação de dados (Ceph). Misturar tudo em uma única porta Gigabit é pedir para ter gargalo.
Tabela: O Custo-Benefício do Cluster N100
| Característica | Servidor Enterprise Usado (ex: R720) | Cluster Raspberry Pi 5 (3 Nós) | Cluster Mini PC N100 (3 Nós) |
|---|---|---|---|
| Custo Inicial | Baixo/Médio | Médio (após comprar SSDs/Cases) | Médio |
| Consumo Energia | Alto (150W+ em idle) | Muito Baixo (15W total) | Baixo (30-45W total) |
| Armazenamento | SAS/SATA Enterprise | USB/NVMe (limitado via HAT) | NVMe Nativo + SATA |
| Rede | 10GbE/40GbE (Barulhento) | 1GbE (Gargalo sério) | 2.5GbE Nativo |
| Arquitetura | x86_64 (Compatibilidade total) | ARM64 (Alguns containers não rodam) | x86_64 (Compatibilidade total) |
Preparando a rede para o tráfego de storage e corosync
O segredo de um cluster Proxmox estável não é a CPU, é a latência da rede. O Proxmox usa um protocolo chamado Corosync para que os nós conversem entre si a cada milissegundo, dizendo "Estou vivo!". Se essa comunicação atrasar por causa de um download pesado na sua rede, o cluster acha que o nó morreu e inicia o processo de fencing (isolamento), reiniciando máquinas desnecessariamente.
Além disso, o Ceph (nosso storage) precisa replicar cada bit gravado no "Nó 1" para o "Nó 2" e "Nó 3" instantaneamente. Fazer isso em uma rede 1GbE compartilhada é doloroso.
A configuração ideal para nossos Mini PCs de duas portas é:
Porta 1 (vmbr0): Conectada ao seu switch principal. Tráfego de internet, acesso à interface web do Proxmox e tráfego das VMs.
Porta 2 (Rede Privada): Conectada a um switch 2.5GbE barato e não gerenciável, exclusivo para o cluster. Aqui rodará o Corosync e a replicação do Ceph.
Se você tiver apenas uma porta 2.5GbE, o uso de VLANs é obrigatório, mas esteja ciente de que a performance de gravação do disco vai competir com o Netflix da sala.
 Figura: Diagrama de topologia de rede: Separação física entre a rede LAN (azul) e a rede de Backend de Storage 2.5GbE (vermelho).
Figura: Diagrama de topologia de rede: Separação física entre a rede LAN (azul) e a rede de Backend de Storage 2.5GbE (vermelho).
Implementando o Ceph para armazenamento distribuído em três nós
O Ceph é o coração pulsante deste projeto. Ele pega o SSD NVMe de 1TB de cada um dos seus três mini PCs e os funde em um único pool de armazenamento de 3TB brutos (ou cerca de 1TB utilizável com redundância máxima).
Diferente do RAID tradicional que protege contra falha de disco, o Ceph protege contra falha de nó inteiro. Quando você grava um arquivo, o Ceph garante que uma cópia esteja no PC 1, outra no PC 2 e outra no PC 3.
A configuração no Proxmox é surpreendentemente simples:
Instale o Ceph via interface web em todos os nós.
Crie os "Monitors" (MON) e "Managers" (MGR) nos três nós.
Crie os OSDs (Object Storage Daemons). OSD é o termo chique para "o disco que vamos usar". Selecione seu NVMe vazio em cada nó.
Crie um Pool. Para um cluster de 3 nós, a regra de ouro é
size=3, min_size=2. Isso significa: "Mantenha 3 cópias dos dados. Se falhar, aceite escrever desde que tenhamos pelo menos 2 cópias vivas".
⚠️ Perigo: Nunca use discos conectados via USB para Ceph. A latência do USB e a instabilidade da conexão podem causar corrupção de dados ou fazer o OSD cair constantemente. Use sempre NVMe ou SATA nativo.
 Figura: Visualização da replicação síncrona do Ceph: Um dado sendo gravado e instantaneamente copiado para os três nós do cluster.
Figura: Visualização da replicação síncrona do Ceph: Um dado sendo gravado e instantaneamente copiado para os três nós do cluster.
Configurando grupos de alta disponibilidade e fencing
Com o Ceph rodando, o armazenamento é compartilhado. Agora precisamos dizer ao Proxmox para proteger nossas VMs. No menu "Datacenter > HA", criamos grupos. Você pode definir, por exemplo, que o Home Assistant deve rodar preferencialmente no "Nó 1", mas se ele falhar, pode ir para qualquer outro.
Mas como o cluster sabe que o "Nó 1" realmente morreu e não está apenas travado? Aqui entra o Fencing. Em servidores Enterprise, usamos placas IPMI para desligar a energia do servidor travado remotamente. Em Mini PCs baratos, não temos IPMI.
A solução "gambiarra técnica" aceitável é usar Watchdogs de Hardware. O processador N100 tem um timer interno. O Proxmox "chuta" esse timer a cada segundo. Se o sistema operacional travar, ele para de chutar o timer. Quando o timer zera, o hardware força um hard reset na máquina. Isso garante ao cluster que o nó travado foi reiniciado e é seguro subir as VMs em outro lugar.
O teste do cabo de rede: validando a migração automática
Chegou a hora da verdade. Você montou tudo, o painel está verde, o Ceph está saudável.
Abra um terminal na sua VM de teste e deixe rodando um ping 8.8.8.8.
Vá até o Mini PC onde essa VM está rodando e puxe o cabo de força. Sem dó.
O que acontece?
O ping vai parar.
Os outros dois nós percebem o silêncio do nó caído.
O quórum é mantido (2 de 3 votos).
O Proxmox espera um tempo configurável (geralmente 1-2 minutos para evitar falsos positivos).
O sistema marca o nó como "Dead".
A VM é reiniciada automaticamente em um dos nós sobreviventes.
O ping volta a responder.
Se você tivesse usado armazenamento local (LVM), a VM estaria morta para sempre (ou até você consertar o nó). Com Ceph, ela renasce em outro hardware, pois os dados já estavam lá.
 Figura: O teste de fogo: Removendo a energia de um nó e observando a recuperação automática do serviço no monitor ao fundo.
Figura: O teste de fogo: Removendo a energia de um nó e observando a recuperação automática do serviço no monitor ao fundo.
Quando o quorum é perdido e o split-brain acontece
Nem tudo são flores. O que acontece se dois dos seus três Mini PCs perderem energia simultaneamente?
Você perde o Quorum.
O nó sobrevivente tem apenas 1 voto de 3. Isso é menos de 50%.
Para proteger seus dados de corrupção, o Ceph entra em modo de "pausa" e o Proxmox bloqueia alterações em arquivos de configuração /etc/pve.
O cluster se torna "somente leitura" ou para completamente. Isso é um recurso de segurança, não um bug. Se o último nó continuasse gravando dados, quando os outros dois voltassem, haveria versões conflitantes da realidade. Para recuperar, você precisa trazer pelo menos mais um nó online. Assim que 2 nós se enxergam, o cluster revive, sincroniza as diferenças e volta ao normal.
Veredito Técnico
Montar um cluster Proxmox com Mini PCs N100 e Ceph é a forma mais educativa e eficiente de ter um "Private Cloud" em casa hoje. O custo de entrada é razoável (aproximadamente o preço de um NAS Synology de 4 baias vazio), mas a flexibilidade é infinita.
Você aprende sobre redes, armazenamento distribuído, Linux e virtualização de nível empresarial. E o melhor: quando você precisar fazer manutenção em um nó, não precisa mais esperar todo mundo ir dormir para desligar a internet. Basta clicar em "Migrate", mover as VMs e trabalhar em paz.
Isso não é apenas um home lab; é infraestrutura resiliente que cabe na mochila.
FAQ
É possível rodar Ceph em rede Gigabit?
Tecnicamente sim, mas não recomendo. A latência de gravação será alta e a reconstrução (rebalance) em caso de falha de disco deixará o cluster inutilizável devido ao congestionamento da rede. O padrão 2.5GbE é o novo mínimo viável para Ceph em home labs que buscam performance decente.Preciso de 3 nós obrigatoriamente para HA?
Para Ceph e HA automático confiável, sim. Com 2 nós, você precisa de um 'QDevice' (um dispositivo externo como um Raspberry Pi ou VM em outro lugar) para manter o quorum de votos. Além disso, com apenas 2 nós, o Ceph entra em modo degradado se um nó cair, perdendo a redundância de dados e colocando seu pool em risco.SSDs de consumo (Consumer) funcionam bem no Ceph?
Eles funcionam, mas o Ceph exige escritas síncronas (sync writes) para garantir a integridade dos dados. SSDs domésticos sem proteção contra perda de energia (PLP) terão performance de gravação muito inferior a SSDs Enterprise, pois precisam confirmar a gravação na flash antes de responder. Para home lab, NVMe modernos mitigam isso com velocidade bruta, mas tenha ciência do desgaste acelerado (TBW).
Roberto Almeida
Auditor de Compliance (LGPD/GDPR)
"Especialista em mitigação de riscos regulatórios e governança de dados. Meu foco é blindar infraestruturas corporativas contra sanções legais, garantindo a estrita conformidade com a LGPD e GDPR."