Amplificação de Latência em Storage Distribuído: Da VM ao Disco Físico
Descubra por que seu NVMe de 0.1ms entrega 10ms na aplicação. Uma análise forense da pilha de I/O em Ceph, vSAN e storage distribuído.
Você recebe o chamado às 3 da manhã. O banco de dados está engasgando. O desenvolvedor jura que a query é otimizada. O administrador do storage aponta para o dashboard do array All-Flash e diz: "Olha aqui, latência sub-milissegundo. O problema não é o disco". Ambos estão tecnicamente certos, mas a aplicação continua lenta.
Como investigador forense de sistemas, aprendi que em ambientes distribuídos, a verdade raramente está nas pontas. O disco físico pode ser rápido como um relâmpago, e a VM pode estar saudável, mas o "tempo de viagem" entre eles é onde os milissegundos morrem. Este fenômeno não é um defeito de hardware; é uma consequência arquitetural que chamamos de amplificação de latência.
A amplificação de latência em storage distribuído é o acúmulo de tempo de espera gerado por cada camada de abstração (virtualização, rede, software-defined storage) e pelos protocolos de consistência de dados (replicação síncrona). Diferente da latência de mídia (tempo físico de gravação), ela inclui o tempo de CPU para processar o I/O, o tempo de fila em cada switch e o Round Trip Time (RTT) necessário para garantir que os dados estejam salvos em múltiplos nós antes de confirmar a gravação.
A Ilusão da Velocidade do Hardware: Tempo de Mídia vs. Tempo de Sistema
O erro mais comum ao diagnosticar lentidão é confundir a velocidade do componente com a velocidade do sistema. Um SSD NVMe moderno pode realizar uma leitura em 80 microssegundos. No entanto, se esse NVMe está do outro lado da rede, gerido por um cluster Ceph ou vSAN, e acessado por uma VM, a física do NAND é apenas uma fração da história.
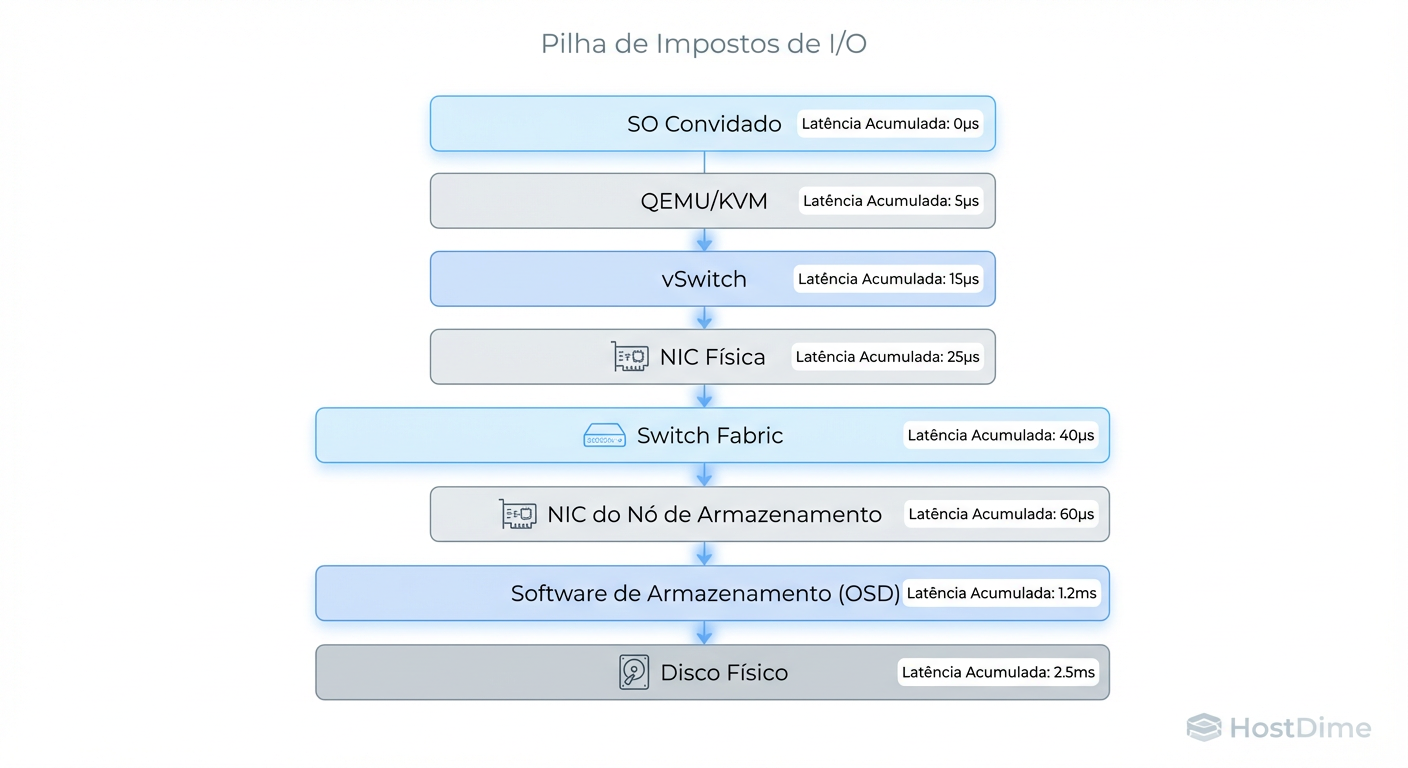 Figura: O Mapa da Amplificação de Latência: Onde os milissegundos são perdidos em cada salto da infraestrutura.
Figura: O Mapa da Amplificação de Latência: Onde os milissegundos são perdidos em cada salto da infraestrutura.
Para o sistema operacional (Guest OS), um I/O é uma "caixa preta". Ele envia um pedido e inicia um cronômetro. O cronômetro só para quando recebe o ACK (confirmação). Se o disco leva 0.1ms, mas o kernel do host leva 0.2ms para processar a interrupção, o switch adiciona 0.1ms e o software de storage gasta 0.5ms calculando hash e paridade, a latência percebida é de 0.9ms. Isso é uma amplificação de 9x em relação à capacidade do hardware.
O Álibi do Vendor
Vendors de storage adoram mostrar métricas de "Device Latency". Isso é o tempo que o controlador do disco leva para servir o dado após o pedido chegar a ele. Isso ignora completamente a jornada tortuosa que o pacote fez para chegar lá. Como investigador, você deve ignorar o álibi do vendor e focar na "Application Latency" — o tempo que a aplicação ficou parada esperando o syscall retornar.
O Caminho do I/O na Pilha de Storage Distribuído
Para entender onde o tempo é perdido, precisamos traçar a rota do pacote. Vamos dissecar a anatomia de um I/O de escrita em um ambiente virtualizado típico. Não é uma linha reta; é uma corrida de obstáculos.
Guest OS (User Space): A aplicação (ex: Postgres) faz um
write().Guest Kernel: O I/O entra na fila do elevador (scheduler) e passa para o driver virtio-blk/scsi.
Hypervisor (Context Switch): O pedido sai da VM. Aqui ocorre a primeira penalidade severa: a troca de contexto e a saída da VM (VM Exit) para o processo QEMU/KVM no host.
Host Networking: O host encapsula o I/O em pacotes TCP/IP (iSCSI, NFS, RBD).
Fabric Físico: Switches, roteadores, buffers de rede. Congestionamento aqui (Microbursts) causa retransmissão TCP, o que destrói a latência.
Storage Node (Ingestão): O nó de storage recebe o pacote, desencapsula e passa para o software de SDS (Software Defined Storage).
Lógica de Storage: Cálculo de checksum, verificação de deduplicação, compressão e decisão de placement (onde gravar).
Se parasse aqui, seria ruim, mas aceitável. O problema real começa agora: a consistência.
Impacto da Consistência e Replicação na Latência
Em storage local, quando o disco diz "gravado", está gravado. Em storage distribuído, quando o nó primário recebe o dado, ele não pode confirmar a gravação imediatamente. Se ele fizer isso e morrer um milissegundo depois, você perdeu dados (corrupção silenciosa).
Para garantir durabilidade, usamos replicação síncrona (geralmente 3 réplicas).
O Algoritmo de Consenso: O nó primário deve enviar o dado para os nós secundários.
A Regra do Mais Lento: A confirmação de escrita (
ACK) só volta para a VM quando todas (ou a maioria, dependendo do quorum) as réplicas confirmarem a gravação.
Isso significa que a latência de escrita do seu cluster não é a média dos discos. É a latência do disco mais lento somada à latência do link de rede mais congestionado no momento daquela operação específica. Se um disco em um nó secundário estiver fazendo Garbage Collection ou compactação, todo o cluster espera por ele.
Tabela Comparativa: O Custo da Arquitetura
| Característica | Storage Local (NVMe) | Storage Distribuído (All-Flash) | Storage Distribuído (Híbrido) |
|---|---|---|---|
| Latência Base (Média) | ~0.08 ms | ~0.5 - 2 ms | ~5 - 20 ms |
| Fator de Amplificação | 1x (Nativo) | 10x - 20x | 100x+ |
| Gargalo Principal | Interface PCIe | Rede / CPU do Storage | Seek Time (HDD) / Cache Miss |
| Consistência | Controlador Local | Rede (RTT) + Algoritmo Paxos/Raft | Rede + Rotação de Disco |
| Risco de Cauda (P99) | Baixo | Médio (Jitter de Rede) | Alto (Cache Miss) |
Latência de Cauda (P99) e Profundidade de Fila
A média é uma mentira estatística que esconde os crimes do sistema. Se 99 requisições levam 1ms e 1 requisição leva 1 segundo, a média é ~10ms. Parece bom, certo? Errado. Para o usuário que caiu naquele 1 segundo, o sistema travou.
Em sistemas distribuídos, a latência de cauda (P99 ou P99.9) é dominada por filas.
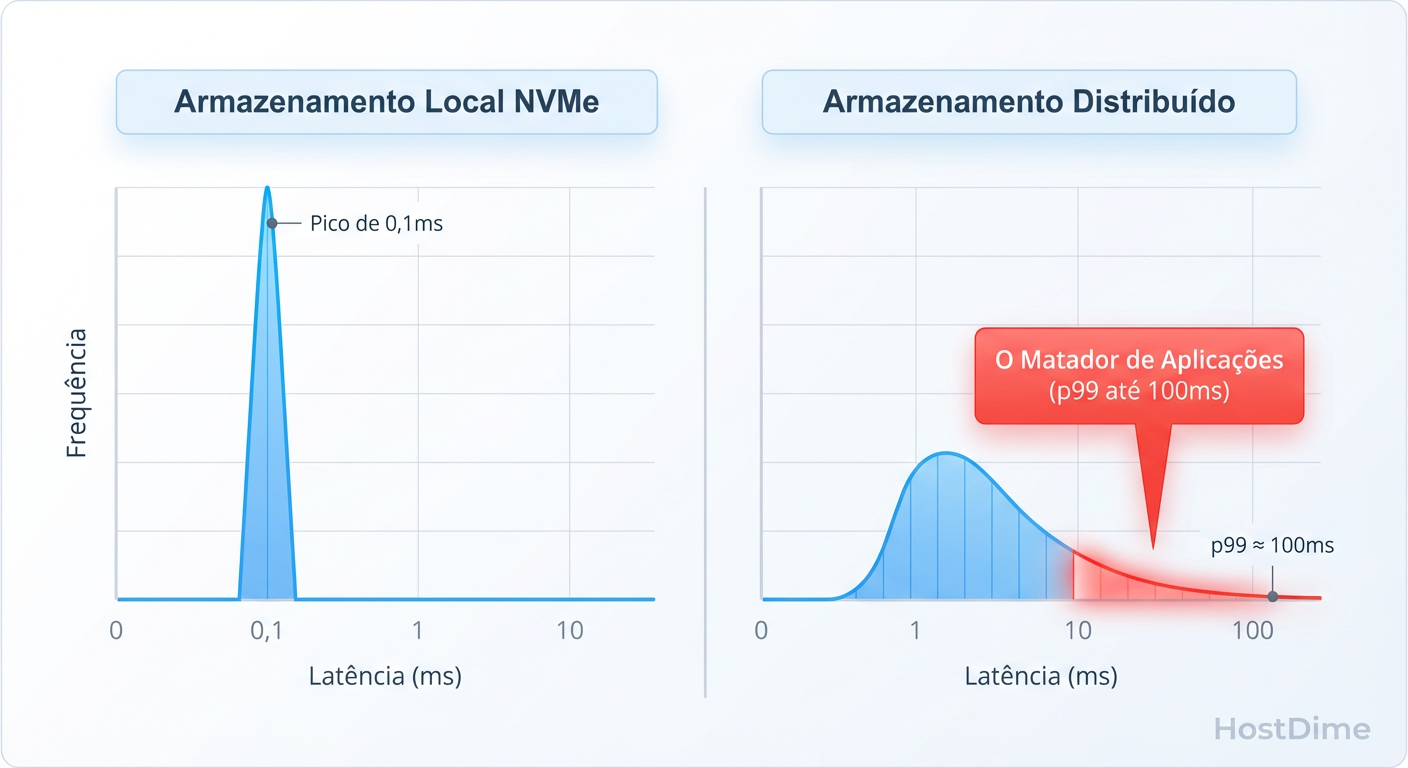 Figura: Média vs. P99: A latência de cauda em sistemas distribuídos é o que realmente derruba aplicações sensíveis.
Figura: Média vs. P99: A latência de cauda em sistemas distribuídos é o que realmente derruba aplicações sensíveis.
O Fenômeno "Noisy Neighbor" e Queue Depth
Discos e redes funcionam melhor com filas profundas (High Queue Depth) para maximizar o throughput. Porém, filas profundas são inimigas da latência.
Imagine uma fila de supermercado. Se você tem apenas um item (uma leitura pequena de 4k), mas está atrás de alguém com dois carrinhos cheios (um vizinho barulhento fazendo backup sequencial), você vai esperar. Isso é o Head-of-Line Blocking.
Em storage distribuído, filas se formam em múltiplos pontos:
Fila do vNIC da VM.
Fila do Switch (Buffer bloat).
Fila de OSD/Drive no storage.
Se o seu storage não tiver QoS (Quality of Service) granular, um batch job de um vizinho pode saturar as filas de replicação, fazendo com que a latência da sua aplicação transacional dispare, mesmo que o disco físico esteja 50% ocioso.
Diagnóstico de Latência com eBPF e Ferramentas Linux
Chega de teoria. Vamos para a autópsia. Como provar que a lentidão é amplificação e não o disco?
Não confie em médias. Use histogramas. Ferramentas tradicionais como top ou iostat mostram médias de intervalos (ex: 1 segundo). Isso é uma eternidade para um computador. Precisamos ver cada I/O individualmente.
A melhor maneira de isolar o problema é medir a latência em dois pontos:
Na aplicação/VM: O que o usuário sente.
No bloco de dispositivo: O que o kernel vê.
Se a diferença for grande, o culpado é o hypervisor ou a rede. Se ambos forem altos, o culpado é o backend de storage.
Ferramentas de Precisão (BCC / eBPF)
Esqueça o iostat para diagnósticos finos. Use o biolatency ou biosnoop do pacote BCC (BPF Compiler Collection). Essas ferramentas rastreiam o ciclo de vida do I/O no kernel com overhead mínimo.
Cenário de Investigação:
Você quer ver a distribuição de latência do disco vda.
# Instale o bcc-tools (exemplo em RHEL/CentOS)
yum install bcc-tools
# Execute o biolatency para capturar um histograma real
/usr/share/bcc/tools/biolatency -D 10
Saída Típica (Interpretada):
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 0 | |
16 -> 31 : 24 |** |
32 -> 63 : 850 |**************************************|
64 -> 127 : 121 |***** |
128 -> 255 : 12 | |
256 -> 511 : 4 | |
512 -> 1023 : 52 |** | <--- Latência de cauda!
1024 -> 2047 : 0 | |
Análise: A maioria dos I/Os está entre 32-63 microssegundos (excelente, provavelmente cache local). Mas veja aqueles 52 I/Os na faixa de 512-1023us. Se isso for um storage All-Flash local, é estranho. Se for distribuído via rede, pode ser um pico de latência de rede ou contenção de bloqueio (lock contention).
Checklist de Isolamento de Variáveis
Verifique o Host: Execute
iostat -x 1. Se%iowaitestiver alto masawait(tempo de serviço) estiver baixo, a CPU está esperando por algo que não é o disco local (provavelmente rede/NFS/iSCSI).Verifique a Rede: Use
sar -n DEV 1ouethtool -Spara procurar por "drops" ou "errors". Um cabo ruim ou porta de switch saturada cria retransmissões que aparecem como latência de disco para a aplicação.Compare VM vs Host: Se a latência dentro da VM é 10ms e no Host físico (para o volume daquela VM) é 1ms, o problema é o Hypervisor (CPU overcommitment ou filas de VirtIO saturadas).
Veredito
A amplificação de latência é o imposto que pagamos pela escalabilidade e resiliência. Não há como "consertar" a física, mas podemos gerenciar as expectativas e a arquitetura.
Ao diagnosticar lentidão em storage distribuído, pare de olhar para o disco físico como o principal suspeito. Na maioria das vezes, o disco é a vítima de uma pilha de software complexa, uma rede congestionada ou uma configuração de replicação agressiva demais. Meça a fila, verifique a rede e, acima de tudo, foque nos outliers (P99), não na média.
Referências & Leitura Complementar
Gregg, Brendan. Systems Performance: Enterprise and the Cloud, 2nd Edition. (Capítulo sobre Discos e File Systems).
RFC 3720: Internet Small Computer Systems Interface (iSCSI).
Ceph Documentation: Architecture - RADOS & OSD Replication.
VMware vSAN: Design Guide - Understanding I/O Path and Latency.
eBPF.io: Documentação oficial sobre tracing e observabilidade no kernel Linux.

Bruno Albuquerque
Investigador Forense de Sistemas
"Não aceito 'falha aleatória'. Com precisão cirúrgica, mergulho em logs e timestamps para expor a causa raiz de qualquer incidente. Se deixou rastro digital, eu encontro."