Anatomia de um vazamento: rastreando a clonagem maliciosa de snapshots em arrays de storage

Descubra como atores de ameaças exploram APIs de storage para clonar e exfiltrar snapshots silenciosamente. Aprenda a rastrear a cadeia de custódia e blindar sua infraestrutura de dados.
Anatomia de um vazamento: rastreando a clonagem maliciosa de snapshots em arrays de storage
O alerta do centro de operações de segurança chegou tarde demais. Os servidores de banco de dados não apresentavam sinais de comprometimento, os agentes de endpoint estavam ativos e nenhuma anomalia de CPU foi detectada nas máquinas virtuais. No entanto, terabytes de dados confidenciais já estavam sendo negociados em fóruns clandestinos. A investigação forense revelou uma verdade desconfortável: os atacantes não invadiram o sistema operacional. Eles desceram uma camada na infraestrutura e comprometeram o plano de controle do próprio array de storage.
Resumo em 30 segundos
- Atacantes estão ignorando o sistema operacional e atacando diretamente o plano de controle do storage via APIs REST e interfaces de hypervisors.
- Snapshots clonados e montados em LUNs obscuras permitem exfiltração silenciosa, contornando completamente as ferramentas tradicionais de segurança de endpoint.
- A resposta a incidentes exige isolamento imediato em nível de bloco, preservação da cadeia de custódia e análise profunda de logs de auditoria da controladora.
O vetor silencioso nas APIs de gerenciamento do storage
A anatomia de um ataque moderno contra infraestruturas de dados raramente começa com um ataque de força bruta contra um banco de dados. O alvo principal tornou-se a interface de gerenciamento do storage (SAN ou NAS) ou o hypervisor que orquestra os volumes. Atores de ameaças avançadas buscam credenciais administrativas para plataformas como vCenter, interfaces RESTful de controladoras all-flash ou gateways de gerenciamento de infraestrutura hiperconvergente.
Uma vez dentro do plano de gerenciamento, o atacante possui as chaves do reino em nível de bloco. Ferramentas de Endpoint Detection and Response (EDR) operam dentro do sistema operacional convidado. Elas são completamente cegas para o que acontece na camada de infraestrutura física ou lógica subjacente. Se um administrador legítimo (ou um atacante usando suas credenciais) instrui a controladora de storage a tirar um snapshot de um volume, o sistema operacional da máquina virtual sequer percebe a operação.
⚠️ Perigo: Se o seu array de storage compartilha o mesmo provedor de identidade do resto da rede sem segmentação estrita e autenticação multifator (MFA), um comprometimento de domínio significa acesso total e irrestrito aos blocos de dados brutos.
A exploração de vulnerabilidades não corrigidas em interfaces de gerenciamento out-of-band também é um vetor comum. Quando os atacantes ganham acesso à controladora, eles não precisam instalar malwares complexos. Eles utilizam as próprias ferramentas nativas do storage (Living off the Land) para manipular os dados.
Kill chain da exfiltração via montagem de volumes clonados
A execução de um vazamento via storage segue uma cadeia de eventos metódica e altamente furtiva. O objetivo do atacante é obter uma cópia dos dados sem interromper o serviço de produção, evitando assim qualquer alerta de indisponibilidade.
O primeiro passo é o reconhecimento do ambiente de armazenamento. O invasor lista os volumes lógicos (LUNs) e identifica quais contêm os bancos de dados críticos ou servidores de arquivos. Em seguida, ele aciona a criação de um snapshot do volume alvo. Como os arrays modernos baseados em NVMe (Non-Volatile Memory Express) e SSDs utilizam ponteiros de metadados para criar snapshots instantâneos (Copy-on-Write ou Redirect-on-Write), a operação leva milissegundos e não gera impacto de performance perceptível.
 Figura: Diagrama da kill chain de clonagem de snapshots no nível do storage
Figura: Diagrama da kill chain de clonagem de snapshots no nível do storage
Com o snapshot criado, o atacante executa a clonagem. Ele transforma esse snapshot de leitura em um novo volume de leitura e escrita. O passo crítico ocorre agora: o mapeamento (LUN masking). O invasor altera as permissões da rede de armazenamento (seja Fibre Channel, iSCSI ou NVMe-oF) para apresentar esse novo volume clonado a uma máquina virtual controlada por ele, frequentemente uma VM de teste esquecida ou uma instância recém-criada em um cluster menos monitorado.
Dentro dessa máquina virtual comprometida, o atacante monta o sistema de arquivos do clone. Ele agora tem acesso direto aos arquivos do banco de dados (como arquivos .mdf ou .ibd) em um estado consistente. A partir desse ponto, os dados são compactados, criptografados e exfiltrados através de canais de comando e controle (C2) já estabelecidos, enquanto o servidor de produção original continua operando normalmente, alheio ao roubo de sua cópia exata.
Por que o monitoramento tradicional de rede ignora o tráfego de replicação
A principal razão pela qual esses ataques permanecem indetectados por meses é a arquitetura das ferramentas de monitoramento de segurança. Centros de operações de segurança (SOCs) tradicionais focam no tráfego norte-sul (entrada e saída da internet) e na inspeção de pacotes TCP/IP em firewalls e sistemas de detecção de intrusão (IDS).
O tráfego de armazenamento, no entanto, flui no sentido leste-oeste, frequentemente em redes fisicamente isoladas (Fibre Channel) ou em VLANs dedicadas para iSCSI e NFS. Esse tráfego é massivo, contínuo e, na maioria das vezes, criptografado ou encapsulado em protocolos que os firewalls tradicionais não inspecionam em profundidade.
Quando o atacante clona um volume e o monta em outra máquina, os dados trafegam pela rede de storage (back-end), não pela rede de dados da aplicação (front-end). Para um analista de rede, os picos de tráfego na rede de storage parecem apenas rotinas normais de backup, migração de máquinas virtuais (como vMotion) ou rebalanceamento de cluster.
| Característica | Monitoramento de rede tradicional | Monitoramento do plano de storage |
|---|---|---|
| Foco de inspeção | Tráfego TCP/IP, payloads de aplicação | Chamadas de API REST, comandos SCSI/NVMe |
| Visibilidade de snapshots | Nenhuma (vê apenas tráfego criptografado) | Total (criação, montagem, deleção, clonagem) |
| Detecção de anomalias | Picos de banda para IPs externos | Mapeamento de LUNs para hosts não autorizados |
| Eficácia contra clonagem | Baixa | Alta |
A falta de integração entre os logs de auditoria do array de storage e o SIEM (Security Information and Event Management) corporativo cria um ponto cego fatal. Sem a ingestão dos logs da controladora, a equipe de segurança não tem como saber que um LUN foi mapeado para um host não autorizado.
Isolamento de LUNs e preservação da cadeia de custódia pós-incidente
Quando o vazamento é finalmente descoberto, a resposta a incidentes no nível do storage exige precisão cirúrgica. A reação instintiva de muitos administradores é deletar imediatamente o volume clonado e a máquina virtual invasora. Essa ação destrói evidências vitais e quebra a cadeia de custódia necessária para a investigação forense.
O procedimento correto inicia-se com o isolamento lógico. O LUN malicioso não deve ser destruído. Em vez disso, o mapeamento (LUN masking) deve ser revogado, desconectando o volume do host comprometido. Imediatamente após o isolamento, a equipe forense deve criar um snapshot imutável (WORM - Write Once Read Many) desse volume clonado. Isso garante que o estado exato dos dados manipulados pelo atacante seja preservado para análise.
 Figura: Preservação da cadeia de custódia acessando os logs da controladora de storage
Figura: Preservação da cadeia de custódia acessando os logs da controladora de storage
A análise forense deve focar nos metadados do sistema de arquivos do clone. Datas de acesso, arquivos temporários criados por ferramentas de compactação e logs residuais podem indicar exatamente quais dados foram exfiltrados. Simultaneamente, a equipe deve extrair os logs de auditoria da controladora de storage.
Esses logs de auditoria são a única fonte de verdade sobre quem ordenou a clonagem. Eles revelarão o endereço IP de origem da chamada de API, a conta de usuário utilizada e o timestamp exato da operação. É crucial que esses logs sejam exportados para um ambiente seguro antes que a rotação automática do sistema os sobrescreva.
💡 Dica Pro: Nunca reinicie a controladora de storage durante a contenção inicial. A memória volátil (NVRAM ou cache DRAM) da controladora pode conter artefatos de comandos recentes ou chaves de sessão de APIs que serão perdidas na reinicialização.
Implementando controle de acesso baseado em função e auditoria imutável
A prevenção contra a clonagem maliciosa exige uma mudança de paradigma na administração da infraestrutura. O modelo de confiança implícita para administradores de storage deve ser abandonado. A implementação de Controle de Acesso Baseado em Função (RBAC) rigoroso é o primeiro passo defensivo.
Em uma arquitetura segura, o administrador responsável por provisionar discos e LUNs não deve ter permissão para ler os dados contidos neles, nem para montar volumes em hosts arbitrários sem um processo de aprovação. A separação de privilégios garante que o comprometimento de uma única conta não resulte em exfiltração total.
Além disso, a autenticação multifator (MFA) deve ser obrigatória para qualquer acesso às interfaces de gerenciamento do storage, sejam elas via interface web, SSH ou chamadas de API REST. A automação via scripts (como Ansible ou Terraform) deve utilizar tokens de acesso com tempo de vida curto e escopo estritamente limitado.
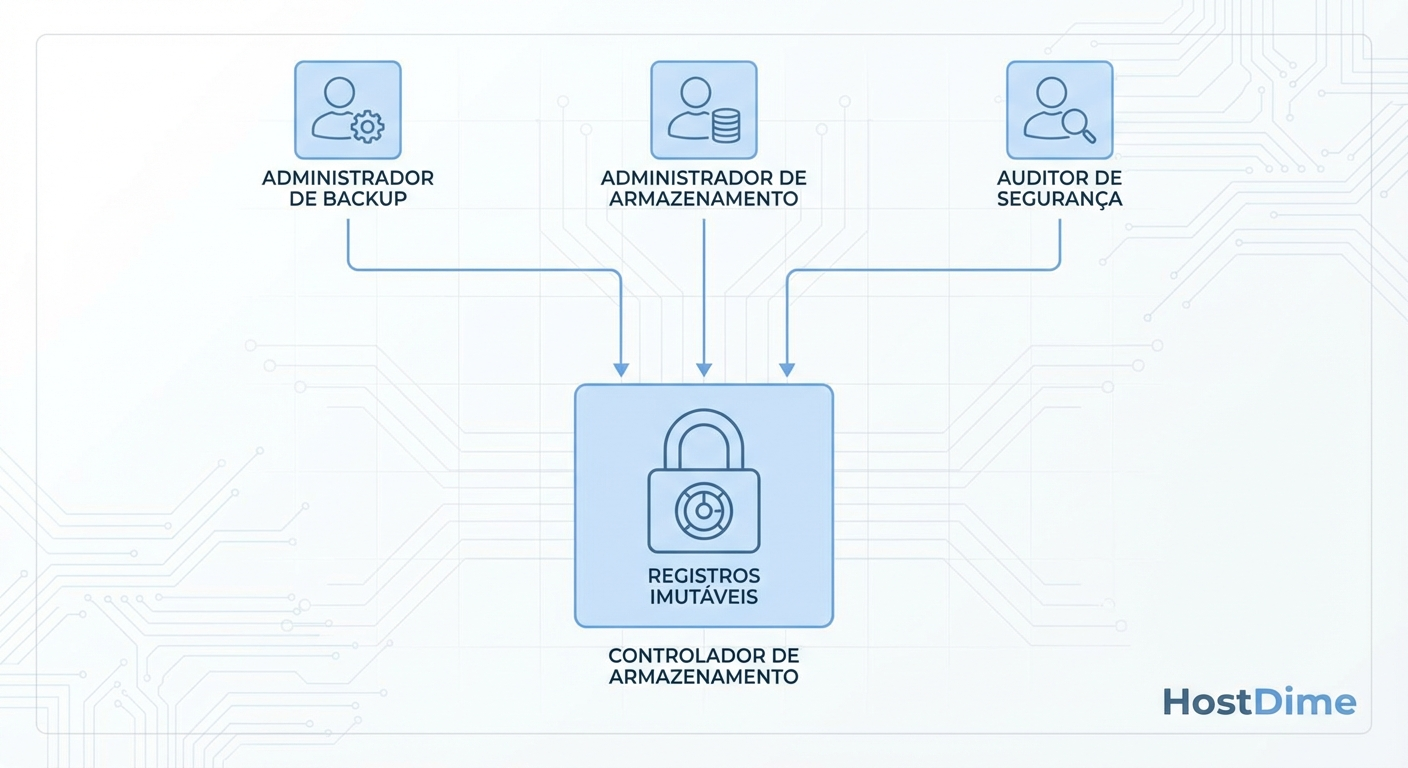 Figura: Arquitetura de separação de privilégios no gerenciamento de storage
Figura: Arquitetura de separação de privilégios no gerenciamento de storage
A auditoria imutável é a última linha de defesa para a visibilidade. Os arrays de storage modernos devem ser configurados para enviar seus logs de auditoria em tempo real para um servidor syslog remoto e seguro, preferencialmente em uma rede de gerenciamento isolada. Esses logs devem ser monitorados ativamente por regras de detecção que disparem alertas críticos sempre que um snapshot for clonado ou um LUN for mapeado para um novo host fora das janelas de manutenção programadas.
O veredito forense
A superfície de ataque mudou. Atores maliciosos entenderam que contornar as defesas do sistema operacional é muito mais eficiente do que lutar contra elas. Ao descer para a camada de armazenamento de dados, eles operam nas sombras, utilizando as próprias ferramentas de resiliência da infraestrutura contra a organização.
Se a sua estratégia de segurança cibernética termina no hypervisor e ignora o plano de controle do storage, sua rede possui um ponto cego catastrófico. A adoção de arquiteturas de storage com princípios de Zero Trust, auditoria contínua de APIs e o uso de snapshots imutáveis não são mais recomendações teóricas. São requisitos fundamentais para garantir a sobrevivência dos dados em um cenário onde o comprometimento das credenciais administrativas é apenas uma questão de tempo.
Referências & Leitura Complementar
NIST Special Publication 800-209: Security Guidelines for Storage Infrastructure.
SNIA (Storage Networking Industry Association): Storage Security Architecture and Best Practices.
JEDEC Solid State Drive Requirements and Endurance Test Method (JESD218).
Como os invasores acessam os snapshots sem disparar alertas de rede?
Eles utilizam credenciais comprometidas nas APIs de gerenciamento do storage (como vCenter ou interfaces REST do array) para montar os snapshots em VMs controladas por eles, exfiltrando os dados por canais criptografados já estabelecidos. O tráfego de movimentação de blocos ocorre na rede de back-end (SAN), invisível para os firewalls de front-end.Qual a diferença entre um snapshot tradicional e um snapshot imutável na análise forense?
Snapshots tradicionais podem ser deletados ou alterados por administradores comprometidos, destruindo evidências críticas da invasão. Snapshots imutáveis (WORM - Write Once Read Many) não podem ser modificados ou apagados por ninguém, nem mesmo pelo administrador root, até o fim do período de retenção configurado, garantindo a integridade absoluta da cadeia de custódia.Onde devo procurar os logs de clonagem de volumes durante um incidente?
Os logs críticos residem no plano de controle do array de storage (audit logs da controladora) e nos logs de auditoria do hypervisor. O sistema operacional da máquina virtual afetada geralmente não terá visibilidade sobre a clonagem em nível de bloco, tornando inútil a busca por esses eventos no Event Viewer do Windows ou no syslog do Linux da VM original.
Viktor Kovac
Investigador de Incidentes de Segurança
"Não busco apenas o invasor, mas a falha silenciosa. Rastreio vetores de ataque, preservo a cadeia de custódia e disseco logs até que a verdade digital emerja das sombras."