Anatomia do S3 Express One Zone: como directory buckets eliminam gargalos de indexação

Descubra como a AWS reescreveu a arquitetura do S3 com directory buckets para entregar latência de milissegundos, e por que você deve monitorar o egress.
O Amazon Simple Storage Service (S3) é indiscutivelmente a espinha dorsal da internet moderna. Para a esmagadora maioria das aplicações, ele se comporta como um buraco negro de armazenamento com capacidade infinita e durabilidade mágica. No entanto, quando você começa a construir clusters de Machine Learning ou sistemas de computação de alta performance (HPC), a ilusão da escalabilidade infinita encontra as duras leis da física e da arquitetura de banco de dados.
Resumo em 30 segundos
- O S3 Standard utiliza um namespace plano que cria gargalos severos de indexação quando submetido a milhares de requisições por segundo no mesmo prefixo.
- A AWS introduziu o S3 Express One Zone com "directory buckets", alterando a arquitetura de backend para uma árvore hierárquica real que entrega latência de um dígito de milissegundo.
- A performance extrema vem com um risco financeiro letal. Cruzar fronteiras de Zonas de Disponibilidade (AZs) com esse volume de dados vai gerar uma fatura de egress catastrófica.
O limite invisível do S3 Standard e o colapso do namespace plano
Muitos arquitetos de nuvem descobrem da pior maneira que o S3 não é um sistema de arquivos. Ele é um gigantesco banco de dados de chave-valor distribuído. Quando você cria uma "pasta" no S3 Standard, você está apenas adicionando barras (/) no nome da chave do objeto. O arquivo dados/2024/log.txt não está dentro de um diretório. O nome completo da chave é literalmente a string inteira.
Isso cria o que chamamos de namespace plano. Para gerenciar trilhões de objetos, a AWS particiona os metadados do S3 baseando-se nos prefixos das chaves. O problema arquitetural surge quando você tem milhares de nós de computação tentando ler ou gravar dados no mesmo prefixo simultaneamente.
A documentação oficial estabelece limites claros. Você consegue cerca de 3.500 requisições PUT/COPY/POST/DELETE ou 5.500 requisições GET/HEAD por segundo, por prefixo particionado. Se o seu cluster de treinamento de IA tentar gravar 50.000 checkpoints por segundo no prefixo modelo-v2/pesos/, o banco de dados de metadados da AWS vai superaquecer aquela partição específica. O resultado imediato são erros HTTP 503 (Slow Down) e uma latência de cauda que destrói a eficiência do seu cluster de GPUs caríssimas.
A ilusão de particionar prefixos com hashes aleatórios
Historicamente, a solução de engenharia para contornar esse gargalo de indexação era brutal. Nós instruíamos os desenvolvedores a injetar hashes hexadecimais aleatórios no início das chaves dos objetos. Em vez de salvar em logs/app1/data.json, você salvava em 3f2a-logs/app1/data.json.
Isso forçava o backend do S3 a espalhar os metadados por dezenas de partições físicas diferentes nos discos e servidores da AWS. Funcionava, mas destruía completamente a usabilidade humana dos dados. Listar objetos se tornava um pesadelo computacional, exigindo agregações complexas no lado do cliente. A AWS melhorou a escalabilidade automática de partições ao longo dos anos, mas a latência de dezenas de milissegundos inerente à arquitetura de armazenamento de objetos distribuído em múltiplas zonas continuava lá.
 Figura: Comparação visual entre o gargalo de um namespace plano e a fluidez de uma estrutura hierárquica de diretórios.
Figura: Comparação visual entre o gargalo de um namespace plano e a fluidez de uma estrutura hierárquica de diretórios.
A engenharia por trás dos directory buckets
Para resolver o problema de latência e o limite de Transactions Per Second (TPS), a AWS precisou quebrar suas próprias regras e lançar o S3 Express One Zone. A grande revolução técnica aqui não é apenas o hardware subjacente (provavelmente frotas massivas de discos NVMe), mas a introdução dos directory buckets.
Ao contrário dos buckets padrão, os directory buckets abandonam o namespace plano. Eles implementam uma estrutura hierárquica real no backend. Quando você cria um diretório nesse novo modelo, o sistema de armazenamento aloca recursos de indexação específicos para aquele caminho. Isso significa que as operações de listagem e acesso não precisam varrer um índice global gigantesco.
A latência despenca para um dígito de milissegundo de forma consistente. O gargalo de indexação desaparece porque o sistema de arquivos distribuído agora entende a topologia dos seus dados. Além disso, a AWS alterou o protocolo de autenticação. O S3 Express introduz um modelo de sessão onde você solicita um token temporário para o bucket, eliminando a necessidade de assinar criptograficamente cada requisição individual com o SigV4. Em escalas de centenas de milhares de requisições por segundo, o tempo de CPU economizado apenas por não calcular hashes de assinatura é massivo.
Comparativo de arquitetura de armazenamento
Para entender o impacto dessa mudança no design de infraestrutura, precisamos olhar para as especificações lado a lado.
| Característica | S3 Standard | S3 Express One Zone |
|---|---|---|
| Estrutura de Metadados | Namespace Plano (Chave-Valor) | Hierárquica (Directory Buckets) |
| Latência Média | 10 a 20 milissegundos | < 10 milissegundos (Um dígito) |
| Limite de TPS (por prefixo) | 3.500 PUT / 5.500 GET | Centenas de milhares |
| Resiliência Física | Múltiplas AZs (Mínimo 3) | Única AZ (Risco de perda de acesso) |
| Autenticação de API | SigV4 por requisição | Token de Sessão (CreateSession) |
Testando o throughput real e o perigo oculto dos custos de egress
A promessa de latência de disco NVMe local com a conveniência de uma API RESTful é inebriante. Workloads como Apache Spark, Trino ou frameworks de Machine Learning como PyTorch apresentam ganhos de performance absurdos quando apontados para directory buckets. O tempo de espera por I/O (Input/Output) despenca, mantendo suas instâncias de computação ocupadas processando dados em vez de esperar pela rede.
No entanto, é aqui que a arquitetura de nuvem se transforma em um campo minado financeiro. O nome "One Zone" não é apenas um detalhe sobre durabilidade, é um alerta de faturamento.
💡 Dica Pro: O S3 Express One Zone cobra um valor por gigabyte armazenado significativamente maior que o S3 Standard. Ele foi desenhado para ser um armazenamento de rascunho (scratch space) de alta velocidade, não um arquivo morto.
Os dados residem fisicamente em uma única Availability Zone (AZ). A AWS não cobra pela transferência de dados entre o seu directory bucket e as instâncias EC2 que estão exatamente na mesma AZ. Mas se o seu cluster de computação escalar automaticamente e instanciar nós em uma AZ diferente, o tráfego de dados vai cruzar a fronteira da zona.
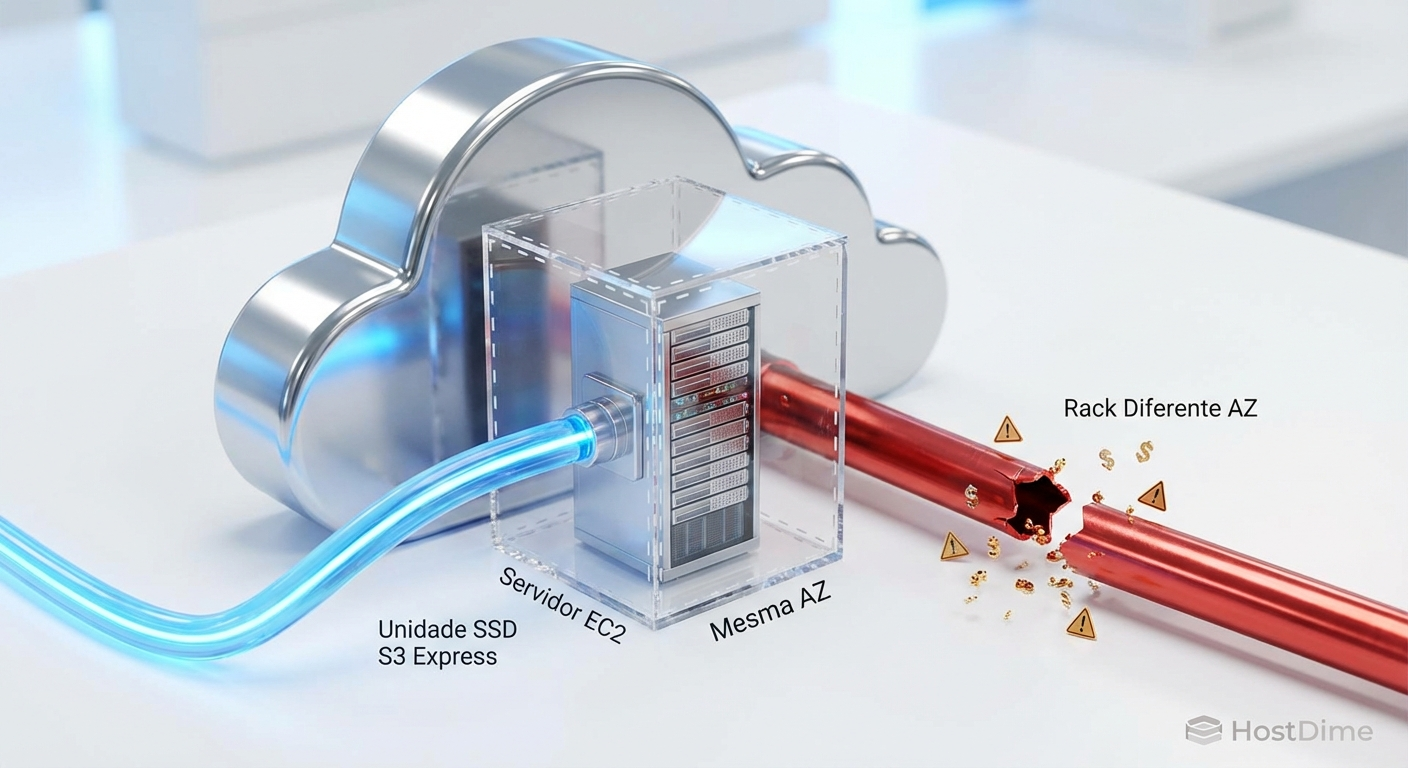 Figura: A armadilha do egress: tráfego intra-AZ é rápido e barato, mas cruzar zonas de disponibilidade destrói seu orçamento.
Figura: A armadilha do egress: tráfego intra-AZ é rápido e barato, mas cruzar zonas de disponibilidade destrói seu orçamento.
Quando você está operando na escala de centenas de gigabytes por segundo, cruzar zonas de disponibilidade aciona os custos de transferência de dados regionais da AWS. Uma configuração de rede mal planejada pode gerar dezenas de milhares de dólares em custos de egress em questão de dias. A velocidade extrema do S3 Express significa que você pode cometer erros financeiros muito mais rápido do que antes.
O veredito arquitetural
O S3 Express One Zone com seus directory buckets é uma obra-prima da engenharia de armazenamento. Ele resolve um problema fundamental de indexação de metadados que assombra o object storage há mais de uma década.
Minha recomendação arquitetural é tratar esse serviço como um cache de altíssima performance ou um disco efêmero compartilhado para clusters de computação. Use o S3 Standard como seu data lake principal. Quando um job de alta intensidade começar, mova os dados necessários para o S3 Express na mesma AZ do seu cluster, processe tudo com latência mínima e grave os resultados finais de volta no S3 Standard.
Se você não amarrar rigidamente a afinidade zonal da sua computação com o seu armazenamento, a AWS ficará extremamente feliz em enviar uma fatura de egress que fará seu CFO questionar todas as suas escolhas de carreira.
Referências & leitura complementar
SNIA (Storage Networking Industry Association): Object Storage and Metadata Management Architecture.
AWS Architecture Blog: Design Patterns for High-Performance Object Storage.
RFC 7230: Hypertext Transfer Protocol (HTTP/1.1): Message Syntax and Routing (Para entender o overhead de requisições RESTful em storage).
O que diferencia um directory bucket de um bucket S3 padrão?
Buckets padrão usam um namespace plano onde as pastas são apenas chaves de texto no nome do objeto. Directory buckets utilizam uma estrutura hierárquica real no backend, o que elimina o gargalo de indexação e permite escalar o TPS (Transactions Per Second) para centenas de milhares com latência de um dígito de milissegundo.O S3 Express One Zone é seguro contra falhas de data center?
A disponibilidade é restrita. Como o nome indica, os dados residem em uma única Zona de Disponibilidade (AZ). Se a AZ sofrer uma interrupção, o acesso aos dados é paralisado. Ele é ideal para dados temporários, caches de machine learning ou workloads onde a performance extrema justifica o risco de disponibilidade zonal.Como a arquitetura afeta os custos de egress da AWS?
A transferência de dados entre o S3 Express One Zone e instâncias EC2 na mesma AZ é gratuita. No entanto, se a sua frota de computação estiver em uma AZ diferente ou se os dados precisarem sair para a internet, os custos de egress tradicionais da AWS serão aplicados, o que pode destruir o orçamento de projetos mal arquitetados.
Rafael Barros
Arquiteto de Cloud Storage
"Desenho arquiteturas de object storage escaláveis e guiadas por API. Meu foco é performance máxima sem deixar o orçamento sangrar com taxas de egress ocultas."