Armazenamento Enterprise em 2026: Escolhendo entre Block, File e Object Storage

Guia para arquitetos: compare Block, File e Object Storage. Analise TCO, latência e escalabilidade para decidir sua infraestrutura de dados em 2026.
Na arquitetura de sistemas distribuídos, poucas decisões são tão fundamentais — e tão difíceis de reverter — quanto a escolha da camada de persistência de dados. Como Arquiteto de Soluções, a resposta padrão para "qual é o melhor storage?" continua sendo a mesma que Martin Fowler ou qualquer engenheiro sênior lhe daria: depende.
Depende dos padrões de acesso, depende dos requisitos de consistência e, inevitavelmente, depende do Custo Total de Propriedade (TCO). Em 2026, com a onipresença de cargas de trabalho de Inteligência Artificial Generativa e a computação de borda (Edge Computing), as linhas entre Block, File e Object estão se tornando turvas, mas as leis da física e os trade-offs fundamentais permanecem inalterados.
Este artigo disseca essas três topologias sob a ótica da engenharia de sistemas, focando não em features de fornecedores, mas em princípios arquiteturais.
O Problema de Negócio: A Explosão de Dados e a Pressão no TCO
O cenário corporativo atual enfrenta um paradoxo. Por um lado, a demanda por armazenamento cresce exponencialmente, impulsionada por datasets de treinamento para LLMs (Large Language Models), logs de observabilidade e mídia de alta definição. Por outro, os orçamentos de TI não acompanham essa curva na mesma proporção.
O problema de negócio não é apenas "onde guardar os dados", mas como fazê-lo de forma que o custo do armazenamento não inviabilize o modelo de negócio da aplicação. Armazenar Petabytes é trivial; acessar esses Petabytes com a latência necessária para uma transação financeira em tempo real — sem falir a empresa — é o desafio real.
Arquitetos devem equilibrar três vetores de pressão:
Performance (IOPS e Throughput): A velocidade necessária para não gargalar a CPU/GPU.
Escalabilidade: A capacidade de crescer sem re-arquitetura (scale-out vs. scale-up).
Durabilidade e Disponibilidade: A garantia de que o dado sobreviverá a falhas de hardware e zonas de disponibilidade.
Ignorar as nuances entre os tipos de armazenamento resulta em super-provisionamento (pagar por performance de Block para dados frios) ou latência inaceitável (tentar rodar um banco de dados transacional sobre Object Storage).
Opções Arquiteturais: Definindo Block, File e Object sem Misticismo
Para tomar uma decisão informada, precisamos desconstruir as abstrações. Cada tipo de armazenamento oferece uma interface diferente para o sistema operacional e para a aplicação, o que dita diretamente o overhead e a flexibilidade.
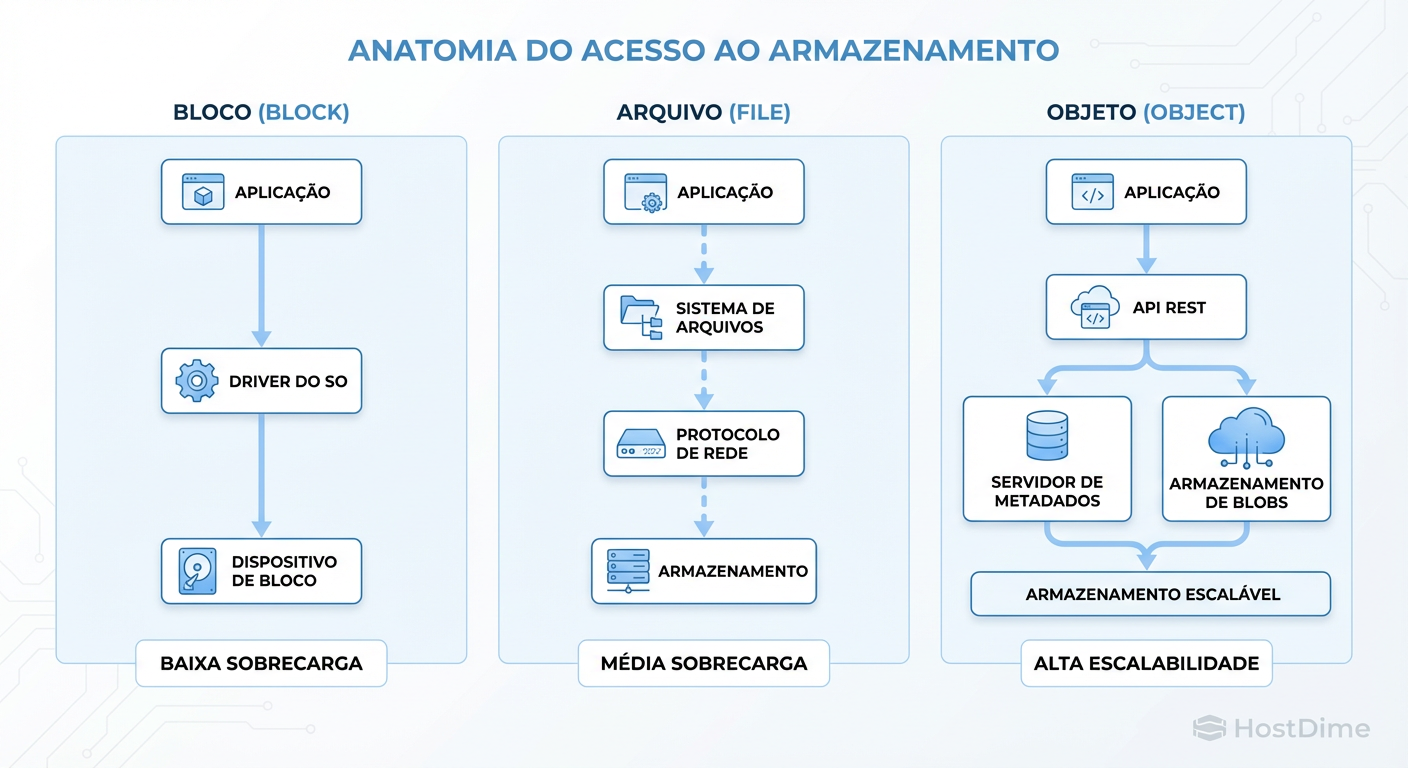 Figura: Fig. 1: Comparativo de sobrecarga (overhead) e camadas de acesso entre os protocolos.
Figura: Fig. 1: Comparativo de sobrecarga (overhead) e camadas de acesso entre os protocolos.
1. Block Storage: A Fundação de Baixa Latência
O Block Storage (Armazenamento em Bloco) é a forma mais nativa de persistência. Pense nele como o disco rígido cru entregue ao servidor. Os dados são divididos em blocos de tamanho fixo (ex: 4KB ou 8KB) e não possuem metadados sobre o que representam (não sabem se é uma foto ou uma linha de banco de dados).
Protocolos Típicos: iSCSI, Fibre Channel, NVMe-oF (NVMe over Fabrics).
Característica Chave: O sistema operacional (OS) vê o storage como um disco local montável. O OS é responsável pelo sistema de arquivos.
Onde brilha: Performance bruta e baixa latência. Como não há camada de tradução de arquivos ou objetos, o caminho do dado é curto.
2. File Storage: A Hierarquia Colaborativa
O File Storage (Armazenamento de Arquivo) adiciona uma camada de abstração: o sistema de arquivos. Ele organiza os dados em uma hierarquia de pastas e arquivos, gerenciando metadados como nome, data de criação e permissões de acesso.
Protocolos Típicos: NFS (Linux/Unix), SMB/CIFS (Windows).
Característica Chave: Múltiplos servidores podem acessar e editar os mesmos arquivos simultaneamente (com mecanismos de locking).
Onde brilha: Colaboração humana e aplicações legadas que dependem de semântica POSIX (Portable Operating System Interface).
3. Object Storage: A Escala da Web
O Object Storage (Armazenamento de Objeto) trata os dados como objetos binários (BLOBs) em um espaço de endereçamento plano (flat), sem hierarquia de pastas real. Cada objeto contém o dado, metadados customizáveis e um identificador único. O acesso é feito via API RESTful (HTTP/HTTPS).
Protocolos Típicos: S3 API (o padrão de facto), Azure Blob.
Característica Chave: Desacoplamento total entre o local físico do dado e o acesso lógico. A aplicação não "monta" um drive; ela faz requisições
GET,PUTeDELETE.Onde brilha: Escalabilidade massiva (Exabytes), metadados ricos e acesso via internet.
Trade-offs Críticos: Latência, Consistência e Complexidade de Gestão
Como Werner Vogels costuma enfatizar, na engenharia distribuída, "tudo falha o tempo todo" e não existe almoço grátis. A escolha entre Block, File e Object é um exercício de trade-offs.
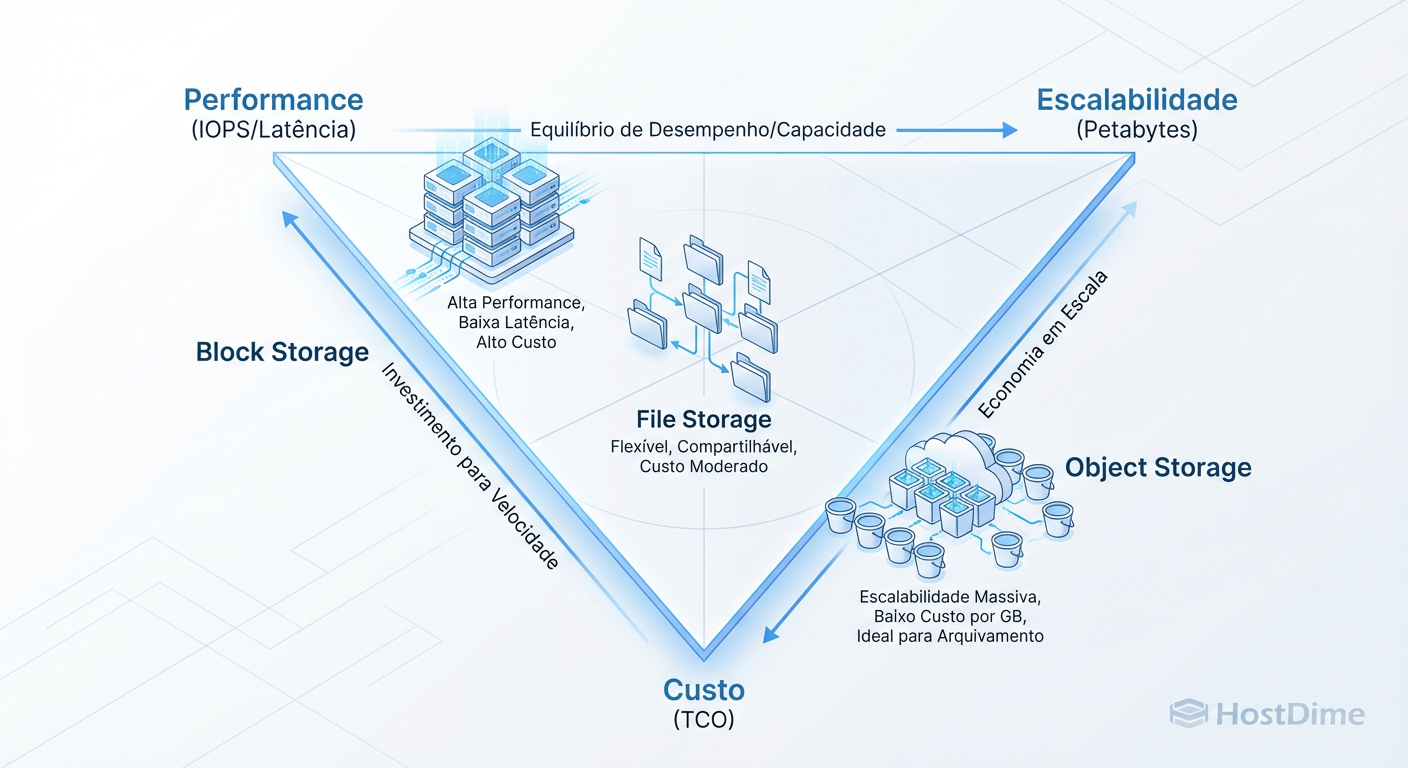 Figura: Fig. 2: O Triângulo de Ferro do Armazenamento: equilibrando performance, custo e escala.
Figura: Fig. 2: O Triângulo de Ferro do Armazenamento: equilibrando performance, custo e escala.
Latência vs. Throughput
Block oferece a menor latência possível. O overhead do protocolo é mínimo. Para bancos de dados como PostgreSQL ou Oracle, onde cada milissegundo de espera no disco trava uma thread de CPU, Block é inegociável.
Object, por outro lado, carrega o peso do protocolo HTTP. Estabelecer conexões TCP/TLS e processar headers HTTP adiciona latência. No entanto, Object Storage moderno (especialmente All-Flash) oferece Throughput (vazão) gigantesco. Você pode não conseguir ler um arquivo pequeno em 1ms, mas pode ler 10GB de dados em paralelo com velocidade impressionante.
Consistência de Dados (CAP Theorem)
Block e File geralmente oferecem consistência forte. Quando você grava um bloco e o sistema confirma, a próxima leitura garantirá aquele dado. Isso é vital para integridade transacional.
Object Storage foi historicamente desenhado com consistência eventual em mente (embora provedores como AWS S3 agora ofereçam consistência forte de leitura após escrita). Contudo, a natureza distribuída do Object Storage significa que a propagação de alterações de metadados pode ter um lag, o que o torna inadequado para locks de arquivos rápidos ou operações atômicas complexas.
Complexidade de Gestão e Escalabilidade
File Storage sofre com problemas de escala. Gerenciar milhões de arquivos pequenos em uma árvore de diretórios profunda causa gargalos severos nos metadados (o clássico problema do inode exhaustion).
Block Storage é difícil de gerenciar em escala. Provisionar LUNs, gerenciar multipathing e expandir volumes requer intervenção administrativa e muitas vezes downtime ou complexidade de orquestração.
Object Storage vence na gestão de escala. Ele é elástico. Você não provisiona "tamanho"; você apenas consome. A complexidade é transferida para o desenvolvedor, que deve lidar com APIs em vez de chamadas de sistema de arquivos simples.
Decisão Recomendada: Matriz de Escolha Baseada em Workloads
Não existe "o melhor storage", existe o storage correto para o workload. Abaixo, apresento uma matriz de decisão que utilizo em projetos enterprise para guiar a seleção tecnológica, focando na adequação técnica e eficiência de custos.
| Categoria do Workload | Exemplo de Aplicação | Recomendação Arquitetural | Justificativa Técnica (O "Porquê") |
|---|---|---|---|
| Bancos de Dados Transacionais | PostgreSQL, MySQL, Oracle, SQL Server | Block Storage | Exige latência de sub-milissegundos e consistência forte garantida. Dependência de IOPS aleatórios (Random I/O). |
| Boot de VMs e Containers | EC2 Root Vol, K8s Persistent Volumes | Block Storage | O SO precisa de um dispositivo de bloco montável para iniciar. |
| Diretórios Compartilhados / CMS | Home directories, WordPress, Edição de Código | File Storage (NAS/EFS) | Necessidade de acesso concorrente (N:1 ou N:M) e semântica de sistema de arquivos (pastas, permissões POSIX). |
| Big Data & Data Lakes | Spark, Hadoop, Presto, Athena | Object Storage | O throughput paralelo é mais importante que a latência. Custo por GB é crítico dado o volume. Separação de Compute e Storage. |
| Treinamento de IA / GenAI | Checkpoints de Modelos, Datasets de Imagens | Object Storage (Fast/Flash) | Escala para Petabytes. Metadados customizáveis ajudam na classificação de dados para ML. |
| Backup e Arquivamento | Retenção de longo prazo, Logs de Compliance | Object Storage (Cold/Archive) | Menor TCO possível. Durabilidade extrema (ex: 11 noves). Latência de recuperação é aceitável. |
| Conteúdo Estático Web | Imagens, Vídeos, CSS/JS (CDN Origin) | Object Storage | Acesso nativo via HTTP/HTTPS facilita integração com CDNs. |
O Caso Específico dos Containers (Kubernetes)
Em ambientes Kubernetes (K8s), a interface CSI (Container Storage Interface) abstraiu grande parte da complexidade.
Use Block (ReadWriteOnce) para bancos de dados dedicados dentro do cluster.
Use File (ReadWriteMany) se múltiplos pods precisarem ler/escrever no mesmo volume simultaneamente.
Use Object diretamente na aplicação (via SDK) para qualquer estado que precise persistir além do ciclo de vida do cluster ou para compartilhar dados externamente.
Visão de Longo Prazo: A Convergência dos Protocolos e o Futuro Híbrido
Olhando para o horizonte de 2026 e além, a rigidez dessas definições está diminuindo. Estamos observando uma convergência de protocolos impulsionada por hardware mais rápido e software mais inteligente.
Armazenamento Unificado e Abstração
Soluções modernas de "Universal Storage" (como as oferecidas por Pure Storage, NetApp e VAST Data) estão usando memória flash de alta velocidade (NVMe) para entregar performance de Block, com a simplicidade de gerenciamento de Object e a interface de File, tudo na mesma plataforma física.
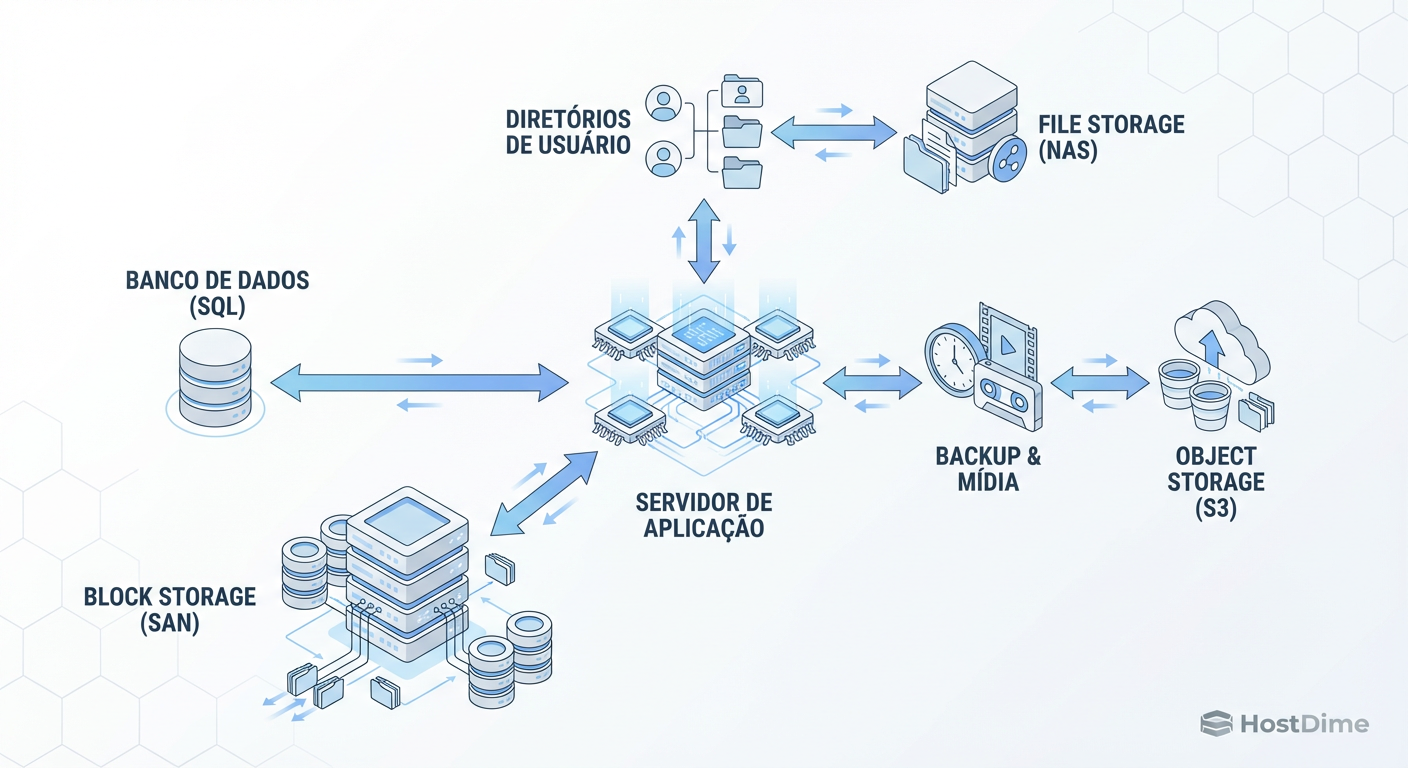 Figura: Fig. 3: Arquitetura de Referência Moderna: Orquestrando múltiplos tipos de storage em uma única solução.
Figura: Fig. 3: Arquitetura de Referência Moderna: Orquestrando múltiplos tipos de storage em uma única solução.
A arquitetura de referência moderna (Fig. 3) não isola mais esses silos fisicamente. Em vez disso, vemos uma camada de orquestração definida por software (SDS) que apresenta os dados da maneira que a aplicação necessita.
S3 sobre File: Gateways que permitem acessar arquivos NFS via API S3.
File sobre Object: Sistemas de arquivos distribuídos que usam Object Storage como backend para capacidade infinita, mantendo uma camada de cache local para performance.
O Impacto da Borda (Edge) e Híbrido
O futuro é híbrido. Dados são gerados na borda (sensores IoT, lojas de varejo), processados localmente (frequentemente em Block ou File leve) e depois movidos para a nuvem central (Object) para treinamento de modelos e arquivamento.
Arquitetos devem projetar para a mobilidade dos dados. Evitar o vendor lock-in em formatos proprietários é crucial. A adoção de padrões abertos (como a API S3, que se tornou o padrão universal de armazenamento de objetos independente do fornecedor) é uma estratégia defensiva vital para o TCO a longo prazo.
Veredito Técnico
Ao desenhar sua próxima solução enterprise, resista à tentação de usar a ferramenta mais conveniente no momento. Avalie o ciclo de vida do dado.
Se o dado é "quente", transacional e sensível a latência: Block.
Se o dado precisa ser compartilhado entre humanos ou apps legados: File.
Se o dado é massivo, precisa ser acessado via web ou arquivado: Object.
A escolha certa hoje é aquela que permite que sua empresa escale amanhã sem reescrever o código base ou migrar Petabytes de dados sob pressão.
Referências
Amazon Builders' Library. Static Stability in Under-Load. Disponível em: aws.amazon.com/builders-library.
NVM Express Organization. NVMe over Fabrics (NVMe-oF) Specification. Disponível em: nvmexpress.org.
Ghemawat, S., Gobioff, H., & Leung, S. T. (2003). The Google File System. ACM SOSP.
Vogels, W. (2009). Eventually Consistent. ACM Queue.
SNIA (Storage Networking Industry Association). Dictionary of Storage Networking Terminology.

Arthur Costas
Especialista em FinOps
"Transformo infraestrutura em números. Meu foco é reduzir TCO, equilibrar CAPEX vs OPEX e garantir que cada centavo investido no datacenter traga ROI real."