Arquitetura de Domínio de Falha: Como Conter o Raio de Explosão e Evitar Apagões

Não deixe um erro derrubar seu sistema. Aprenda a projetar domínios de falha, usar o padrão Bulkhead e garantir que sua arquitetura sobreviva ao caos.
A esperança não é uma estratégia de engenharia. Se você constrói sistemas distribuídos acreditando que a rede é confiável, que a latência é zero e que seus provedores de nuvem nunca vão piscar, você não está construindo software; você está construindo um castelo de cartas em cima de uma falha geológica.
Como Engenheiro do Caos, minha função não é apenas quebrar coisas. É incinerar as suposições otimistas da sua arquitetura para revelar a verdade nua e crua. A verdade é que a falha é inevitável. Discos rígidos morrem, cabos de fibra são cortados por escavadeiras e deploys ruins acontecem numa sexta-feira à tarde.
O que diferencia um sistema resiliente de um brinquedo frágil não é a ausência de erros, mas a capacidade de conter o dano. Hoje, vamos dissecar a Arquitetura de Domínio de Falha. Vamos injetar caos para entender como isolar componentes, conter o raio de explosão e garantir que, quando um serviço arder em chamas, o resto do seu ecossistema continue operando friamente.
Hipótese de Falha: Assumindo que o Componente Crítico Vai Quebrar
Para começar qualquer experimento de Engenharia do Caos, precisamos de uma hipótese. A maioria dos engenheiros projeta para o "Caminho Feliz" (Happy Path). Nós vamos projetar para o apocalipse.
A Hipótese: Se o nosso serviço de Pagamentos (Payment Gateway) sofrer uma degradação severa de latência ou ficar indisponível, o restante da plataforma de E-commerce (Catálogo, Carrinho, Login) deve permanecer 100% funcional, servindo conteúdo aos usuários, mesmo que a finalização da compra esteja temporariamente bloqueada.
Parece óbvio, certo? Mas a realidade da maioria das arquiteturas de microsserviços é um emaranhado de acoplamento temporal. Se o serviço A chama o serviço B de forma síncrona, e o serviço B decide demorar 30 segundos para responder, o serviço A não é apenas um espectador; ele é uma vítima. Ele segura conexões, consome threads e memória enquanto espera.
Ao assumirmos que o componente crítico vai quebrar, paramos de perguntar "como mantê-lo online?" e passamos a perguntar "o que acontece com quem depende dele?". Se a resposta for "tudo cai", você não tem domínios de falha; você tem um monólito distribuído — o pior dos dois mundos.
O Experimento: Injetando Latência e Erros em Dependências Compartilhadas
Não vamos apenas desligar o servidor. Desligar é fácil; a maioria dos balanceadores de carga detecta um nó morto instantaneamente e para de enviar tráfego. O inimigo silencioso e mortal é a latência. Um serviço "zumbi" que responde, mas demora uma eternidade, causa muito mais danos do que um serviço morto.
Para este experimento, utilizaremos uma ferramenta de injeção de falhas (como Chaos Mesh ou Gremlin) para introduzir latência na camada de rede entre o nosso Frontend e o Serviço de Recomendação.
Configuração do Ataque (Chaos Mesh)
Como engenheiros, falamos através de código e configuração. Abaixo está um exemplo de manifesto YAML para injetar um atraso de rede (NetworkChaos) de 3 segundos em 50% das requisições:
apiVersion: chaos-mesh.org/v1alpha1
kind: NetworkChaos
metadata:
name: latencia-recomendacao
namespace: e-commerce
spec:
action: delay
mode: one
selector:
namespaces:
- e-commerce
labelSelectors:
app: recomendacao-service
delay:
latency: "3000ms"
correlation: "100"
jitter: "0ms"
duration: "5m"
Ao aplicar este manifesto, estamos simulando um cenário comum: um banco de dados sobrecarregado ou uma dependência de terceiros lenta. O Serviço de Recomendação não está morto, ele está apenas lento.
O objetivo aqui é observar o comportamento do Frontend. Se o seu site inteiro ficar carregando infinitamente (o famoso "spinner da morte") porque um widget irrelevante no rodapé está lento, acabamos de provar que seu isolamento de falhas é inexistente.
Analisando o Raio de Explosão: O Efeito Dominó vs. Isolamento Real
O Raio de Explosão (Blast Radius) é a medida de quanto do seu sistema é impactado por uma falha pontual. Em um sistema ideal, o raio de explosão de um microsserviço deve ser limitado ao próprio microsserviço. Na prática, vemos o Efeito Dominó (Cascading Failure).
Quando injetamos a latência de 3 segundos no exemplo acima, o que acontece fisicamente nos servidores?
Exaustão de Threads: O servidor web (ex: Tomcat, Jetty ou mesmo workers do Node.js) tem um limite finito de threads ou conexões simultâneas.
Bloqueio: Cada requisição que chega e precisa chamar o serviço lento ocupa um slot.
Saturação: Em poucos segundos, sob carga normal, todos os slots disponíveis estão ocupados esperando a resposta de 3 segundos.
Negação de Serviço: Novas requisições — mesmo aquelas que não precisam do serviço de recomendação (como a Home Page ou o Login) — são rejeitadas porque não há threads livres para processá-las.
O sistema inteiro para. O raio de explosão, que deveria ser contido em um único pod, expandiu-se para derrubar toda a plataforma.
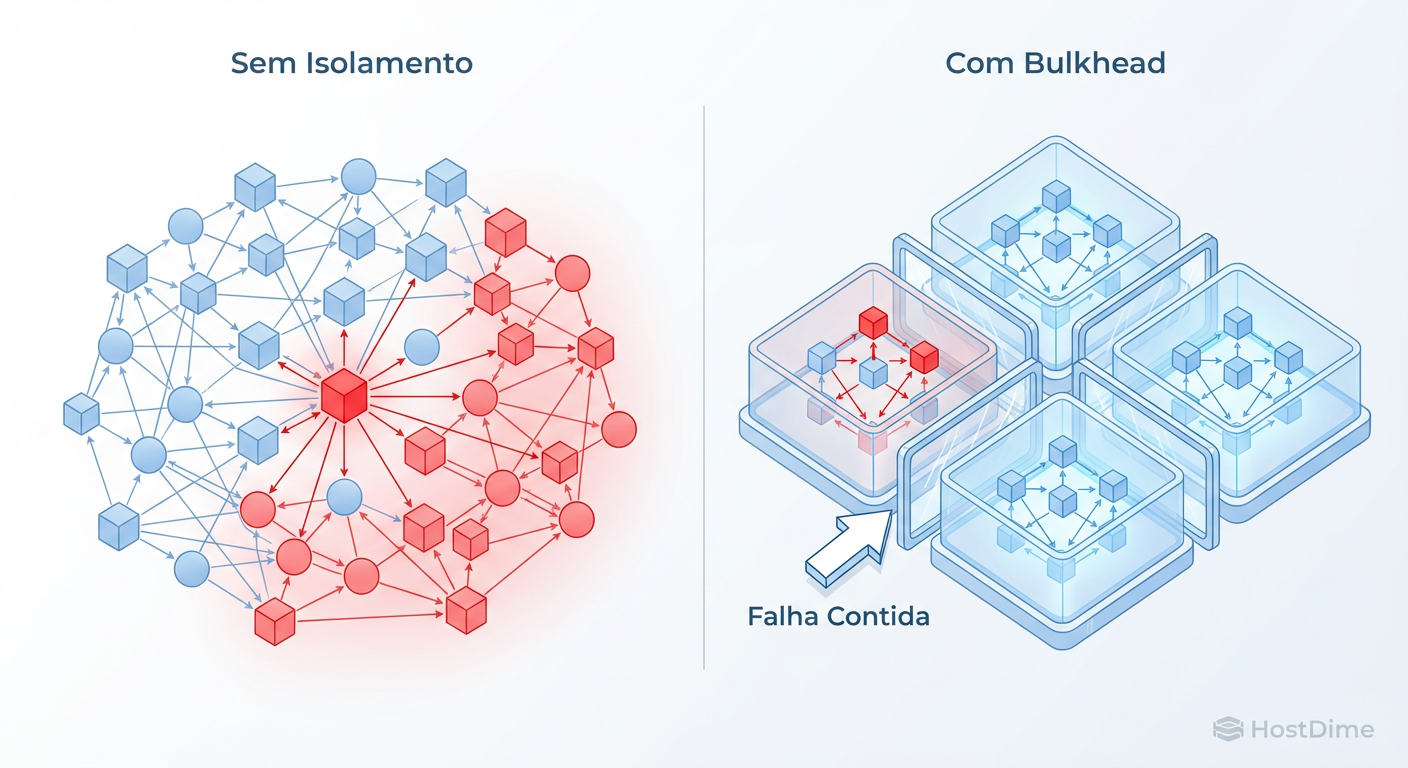 Figura: Fig. 1: Comparação visual do impacto de uma falha em arquiteturas monolíticas versus arquiteturas baseadas em isolamento (Bulkhead).
Figura: Fig. 1: Comparação visual do impacto de uma falha em arquiteturas monolíticas versus arquiteturas baseadas em isolamento (Bulkhead).
A tabela abaixo ilustra a diferença crítica entre uma arquitetura acoplada e uma baseada em Domínios de Falha bem definidos:
| Característica | Arquitetura Acoplada (Frágil) | Arquitetura de Domínio de Falha (Resiliente) |
|---|---|---|
| Reação à Latência | Espera indefinida ou timeouts longos. | Falha rápida (Fail Fast) e fallback. |
| Gerenciamento de Recursos | Pool de threads compartilhado globalmente. | Pools de threads segregados por dependência (Bulkheads). |
| Experiência do Usuário | Erro 500 ou loading infinito em tudo. | Funcionalidade parcial (Modo Degradado). |
| Recuperação | Requer reinício de múltiplos serviços. | Recuperação automática assim que a dependência volta. |
Se a falha de um componente não crítico (como recomendações ou comentários) pode derrubar o fluxo crítico (checkout), sua arquitetura falhou no teste de isolamento.
O que Sobreviveu? Identificando os Limites dos Seus Domínios de Falha
Após o caos, caminhamos sobre as cinzas para ver o que ficou de pé. Esta etapa é crucial para mapear os limites reais dos seus domínios de falha. Um Domínio de Falha deve ser uma fronteira lógica e física onde uma falha é contida.
No nosso experimento, se o Frontend caiu completamente, o domínio de falha abrange o Frontend e o Serviço de Recomendação. Eles são, para todos os fins práticos, uma única unidade de falha. Isso é ruim.
Para identificar os limites ideais, faça as seguintes perguntas durante a análise pós-incidente (Post-Mortem):
O Checkout funcionou? Se o sistema de recomendações morreu, eu ainda consigo ganhar dinheiro?
A latência vazou? O tempo de resposta (P99) de serviços não relacionados aumentou?
O monitoramento alertou corretamente? Você recebeu um alerta de "Latência Alta no Serviço de Recomendação" ou um alerta genérico de "CPU Alta no Frontend"?
Se o que sobreviveu foi "nada", precisamos redesenhar as fronteiras. O objetivo é transformar dependências fortes em dependências fracas. O sistema deve ser capaz de operar em Modo Degradado.
Modo Degradado significa que, em vez de mostrar uma página de erro, o site carrega sem a seção de recomendações. O usuário talvez nem perceba. O negócio continua rodando. A resiliência não é sobre perfeição; é sobre a elegância com que você falha.
Lições de Resiliência: Implementando Bulkheads e Circuit Breakers na Prática
Agora que queimamos o sistema e entendemos o problema, vamos reconstruí-lo mais forte. As duas ferramentas táticas mais eficazes para definir domínios de falha e conter o raio de explosão são os padrões Bulkhead e Circuit Breaker.
1. O Padrão Bulkhead (Anteparas)
O termo vem da engenharia naval. Navios são divididos em compartimentos estanques (anteparas). Se o casco for perfurado em uma seção, a água inunda apenas aquele compartimento, e o navio não afunda.
No software, aplicamos isso segregando recursos. Não permita que todas as chamadas externas usem o mesmo pool de threads.
- Na Prática: Se você usa Java/Spring, não use o pool padrão para tudo. Crie um
ThreadPoolExecutorespecífico para o Serviço de Recomendação com, digamos, 20 threads. Se o serviço travar, ele consumirá apenas essas 20 threads. As outras 980 threads do seu servidor continuarão livres para processar o Checkout e o Login.
2. O Padrão Circuit Breaker (Disjuntor)
O Circuit Breaker é o guarda-costas do seu sistema. Ele monitora as falhas. Se uma dependência começar a falhar repetidamente ou ficar lenta (timeout), o disjuntor "abre" e impede novas chamadas para aquele serviço por um tempo determinado.
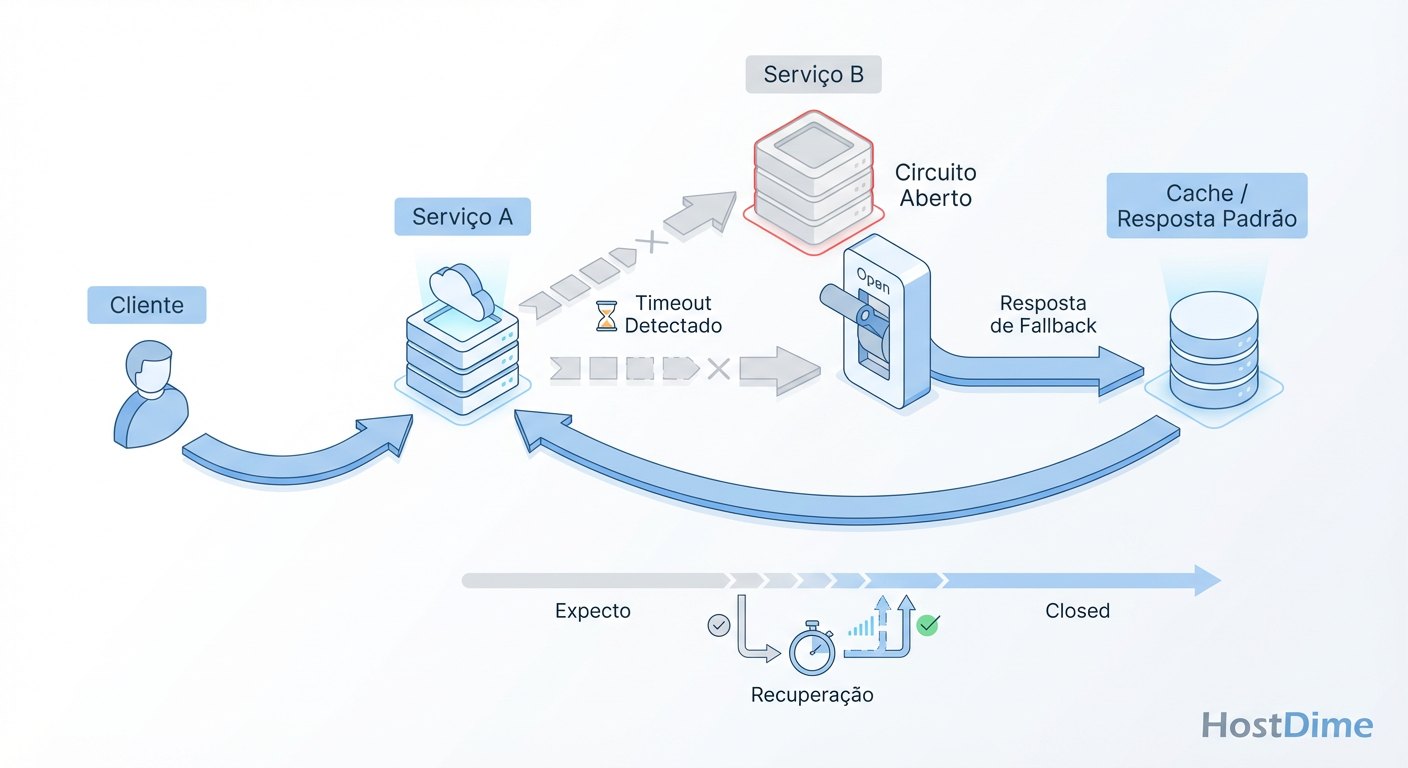 Figura: Fig. 2: Mecânica de um Circuit Breaker impedindo que a latência de um domínio de falha esgote os recursos de todo o sistema.
Figura: Fig. 2: Mecânica de um Circuit Breaker impedindo que a latência de um domínio de falha esgote os recursos de todo o sistema.
Por que isso é vital?
Protege o Chamador: Evita que o Frontend fique esperando 3 segundos por requisição. Ele recebe um erro imediato (em milissegundos) e pode entregar um fallback.
Protege o Chamado: Dá tempo para o serviço em dificuldade se recuperar, em vez de continuar martelando-o com requisições que ele não consegue processar.
Aqui está um exemplo de implementação agnóstica de lógica de Circuit Breaker para ilustrar o conceito técnico:
// Exemplo conceitual usando padrão Resilience4j
CircuitBreakerConfig config = CircuitBreakerConfig.custom()
.failureRateThreshold(50) // Abre se 50% das chamadas falharem
.waitDurationInOpenState(Duration.ofMillis(10000)) // Espera 10s antes de tentar de novo
.permittedNumberOfCallsInHalfOpenState(2) // Testa com 2 chamadas
.slidingWindowSize(100)
.build();
CircuitBreaker registry = CircuitBreaker.of("recomendacaoService", config);
Supplier<String> decoratedSupplier = CircuitBreaker
.decorateSupplier(registry, () -> recomendacaoService.getRecomendacoes());
// Se o circuito estiver aberto, executa o fallback imediatamente
String result = Try.ofSupplier(decoratedSupplier)
.recover(throwable -> "Recomendações Indisponíveis no Momento") // Fallback
.get();
A Combinação Vencedora
Ao combinar Bulkheads e Circuit Breakers, você cria uma Arquitetura de Domínio de Falha robusta.
O Bulkhead garante que, mesmo que o Circuit Breaker demore a abrir, a exaustão de recursos seja contida no compartimento específico.
O Circuit Breaker garante que o sistema pare de tentar realizar uma operação fútil, liberando recursos rapidamente e permitindo o modo degradado.
A injeção de falhas nos ensina que a perfeição é inatingível, mas a resiliência é engenharia pura. Não espere o "Big One" acontecer para descobrir que seus microsserviços são, na verdade, um monólito disfarçado. Injete a falha hoje. Isole os domínios. Contenha a explosão.
Deixe o mundo arder, desde que o seu Core Business permaneça à prova de fogo.
Referências
Google Site Reliability Engineering (SRE) Book - Chapter 22: Addressing Cascading Failures. Disponível em: https://sre.google/sre-book/addressing-cascading-failures/
Netflix Tech Blog - Fault Tolerance in a High Volume, Distributed System. Discussão sobre Hystrix e padrões de isolamento.
AWS Well-Architected Framework - Reliability Pillar. Foco em design de carga de trabalho e recuperação de falhas.
Nygard, Michael T. - Release It!: Design and Deploy Production-Ready Software. (O livro definitivo sobre Bulkheads e Circuit Breakers).

Magnus Vance
Engenheiro do Caos
"Quebro sistemas propositalmente porque a falha é inevitável. Transformo desastres simulados em vacinas para sua infraestrutura. Se não sobrevive ao meu caos, não merece estar em produção."