Arquitetura de Storage para IA: Balanceando Throughput, Latência e Capacidade

Evite a 'GPU Starvation'. Um guia para arquitetos sobre como desenhar storage para IA equilibrando throughput, latência e TCO em pipelines de Machine Learning.
Na engenharia de sistemas distribuídos, existe um ditado que costumo repetir: "Amadores discutem algoritmos; profissionais discutem dados." Quando elevamos essa conversa para o contexto de Inteligência Artificial (IA) e Machine Learning (ML), a discussão sobre armazenamento deixa de ser apenas sobre onde guardar os bits e passa a ser sobre como alimentar bestas computacionais insaciáveis.
A resposta padrão para "qual é o melhor storage para IA" é, inevitavelmente, depende. Depende do estágio do pipeline, da natureza dos dados (estruturados vs. não estruturados) e, crucialmente, do orçamento disponível. No entanto, o objetivo deste artigo não é ser evasivo, mas fornecer um framework mental para arquitetar soluções que equilibrem Throughput, Latência e Capacidade, mantendo o TCO (Total Cost of Ownership) sob controle.
O Problema de Negócio: O Custo Oculto da "GPU Starvation"
Muitas organizações cometem o erro de investir milhões em clusters de GPUs H100 ou A100, mas negligenciam a infraestrutura de I/O (Input/Output). O resultado é um fenômeno conhecido como GPU Starvation (inanição da GPU).
Imagine uma fábrica de Fórmula 1 onde o motor (a GPU) é capaz de 15.000 RPM, mas a linha de combustível (o Storage) só entrega gasolina a conta-gotas. O motor engasga. No mundo da IA, isso significa que seus ciclos de computação — que custam dezenas de dólares por hora — estão ociosos, esperando que o dado seja carregado da memória de massa para a VRAM.
O problema de negócio aqui não é técnico; é financeiro. Uma GPU ociosa é capital queimado. Se o seu subsistema de armazenamento não consegue saturar o barramento PCIe ou NVLink, você está efetivamente pagando por uma infraestrutura de supercomputação e obtendo o desempenho de um desktop. O desafio arquitetural é garantir que o gargalo nunca seja o I/O, mas sim a capacidade de computação.
Mapeando os Requisitos: O Ciclo de Vida do Dado na IA (Ingestão vs. Treino vs. Inferência)
Para desenhar a arquitetura correta, precisamos dissecar o pipeline de IA. Tratar o armazenamento como um repositório monolítico é uma receita para a ineficiência. Cada fase do ciclo de vida do dado exige características de performance distintas.
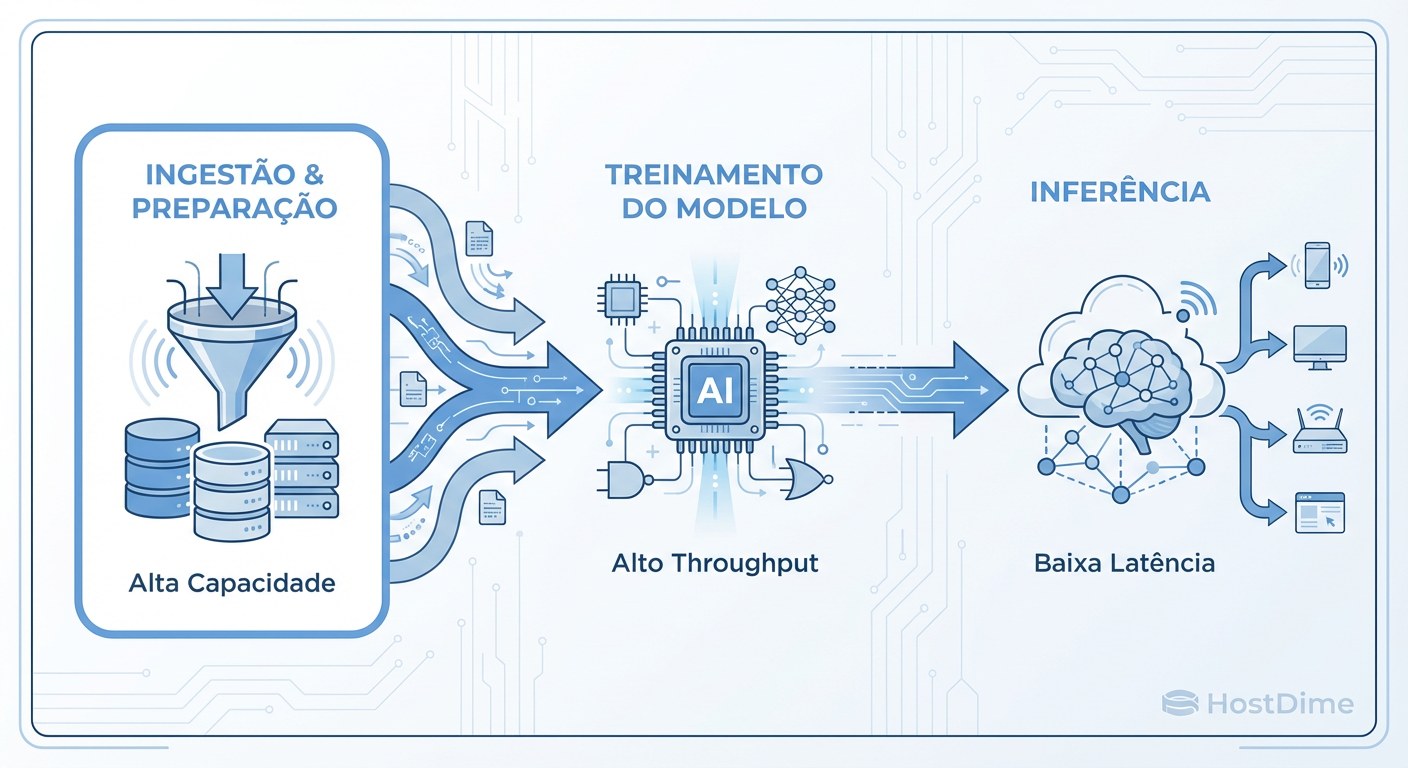 Figura: Fig. 1: O trilema do armazenamento no ciclo de vida da Inteligência Artificial.
Figura: Fig. 1: O trilema do armazenamento no ciclo de vida da Inteligência Artificial.
1. Ingestão e Pré-processamento (Write-Heavy)
Nesta fase, estamos lidando com Throughput de Escrita massivo. Dados chegam de sensores IoT, logs de servidores ou crawlers web.
Padrão: Escrita sequencial, arquivos grandes ou milhões de pequenos objetos.
Requisito: Alta capacidade de ingestão e durabilidade. A latência de leitura é secundária.
2. Treinamento do Modelo (Read-Heavy & Random Access)
Este é o ponto crítico. Durante o treinamento, o modelo precisa ler o dataset repetidamente (épocas).
Padrão: Leituras massivas. Se o treinamento usa shuffling (embaralhamento de dados para evitar viés), o padrão de acesso torna-se aleatório.
Requisito: Baixa latência e alto throughput de leitura. Storage lento aqui causa a GPU Starvation. O manuseio de metadados (abrir/fechar arquivos) torna-se um gargalo se o dataset for composto por bilhões de arquivos pequenos (ex: imagens de 50KB).
3. Inferência e Checkpointing (Latency Sensitive)
Na inferência, o modelo já está treinado e responde a requisições em tempo real.
Padrão: Leitura aleatória de baixa latência.
Requisito: O tempo de resposta para o usuário final é o que importa. Aqui, a latência de cauda (P99) é a métrica de sucesso.
Opções Arquiteturais: Object Storage, NAS All-Flash e Sistemas de Arquivos Paralelos
Ao avaliarmos as topologias de armazenamento, geralmente nos deparamos com três grandes arquétipos. Cada um possui seu lugar no trade-off de complexidade versus performance.
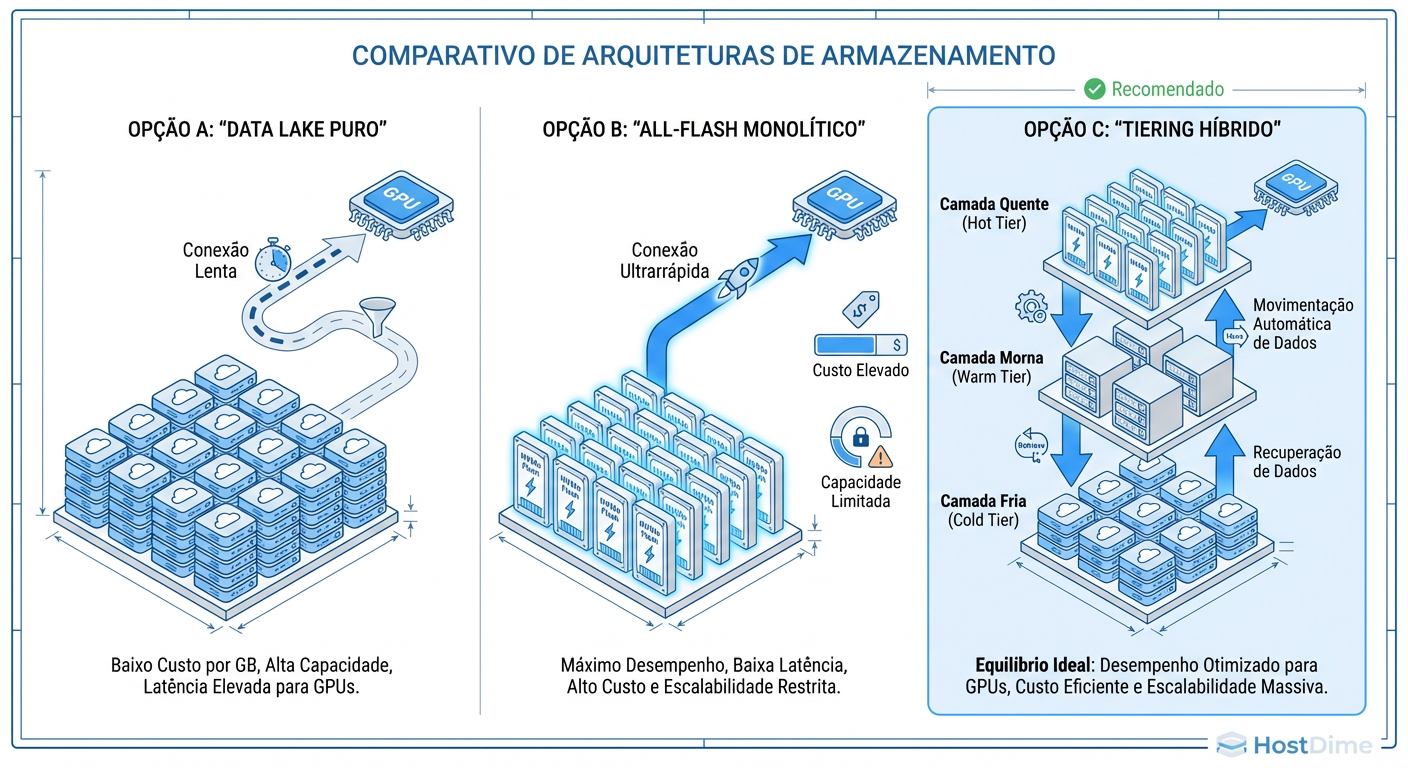 Figura: Fig. 2: Comparativo de topologias de storage: Do monolítico ao tiering inteligente.
Figura: Fig. 2: Comparativo de topologias de storage: Do monolítico ao tiering inteligente.
Object Storage (S3-Compatible)
Historicamente visto como armazenamento "frio" ou de arquivamento devido à latência do protocolo HTTP/REST.
Prós: Escalabilidade infinita de capacidade, metadados ricos, custo por GB baixo.
Contras: Latência alta para first-byte. Não é compatível com POSIX nativamente, o que exige refatoração de código legado.
Evolução: Novas implementações de Object Storage em All-Flash e aceleradores de protocolo estão tornando o S3 viável para estágios de treinamento leve.
NAS All-Flash (NFS/SMB)
O "cavalo de batalha" das empresas.
Prós: Compatibilidade POSIX completa (fácil para Cientistas de Dados usarem), boa performance para arquivos médios, recursos de enterprise (snapshots, deduplicação).
Contras: O protocolo NFS pode se tornar um gargalo (chattiness) em alta concorrência. Escalar controladores (scale-out) é complexo e caro.
Sistemas de Arquivos Paralelos (HPC)
Soluções como Lustre, IBM Spectrum Scale (GPFS) ou Weka.
Prós: Performance extrema. O cliente (nó de GPU) fala diretamente com múltiplos nós de storage simultaneamente, eliminando o gargalo do controlador único. Ideal para datasets de bilhões de arquivos.
Contras: Complexidade de gestão altíssima. Custo por TB elevado. Exige drivers específicos no cliente.
Trade-offs Críticos: Desempenho Puro vs. Escalabilidade de Custo (TCO)
Como arquitetos, nosso trabalho é gerenciar trade-offs. Não existe solução mágica que seja barata, rápida e infinitamente escalável. Abaixo, apresento uma matriz de decisão para auxiliar na escolha tecnológica baseada no workload.
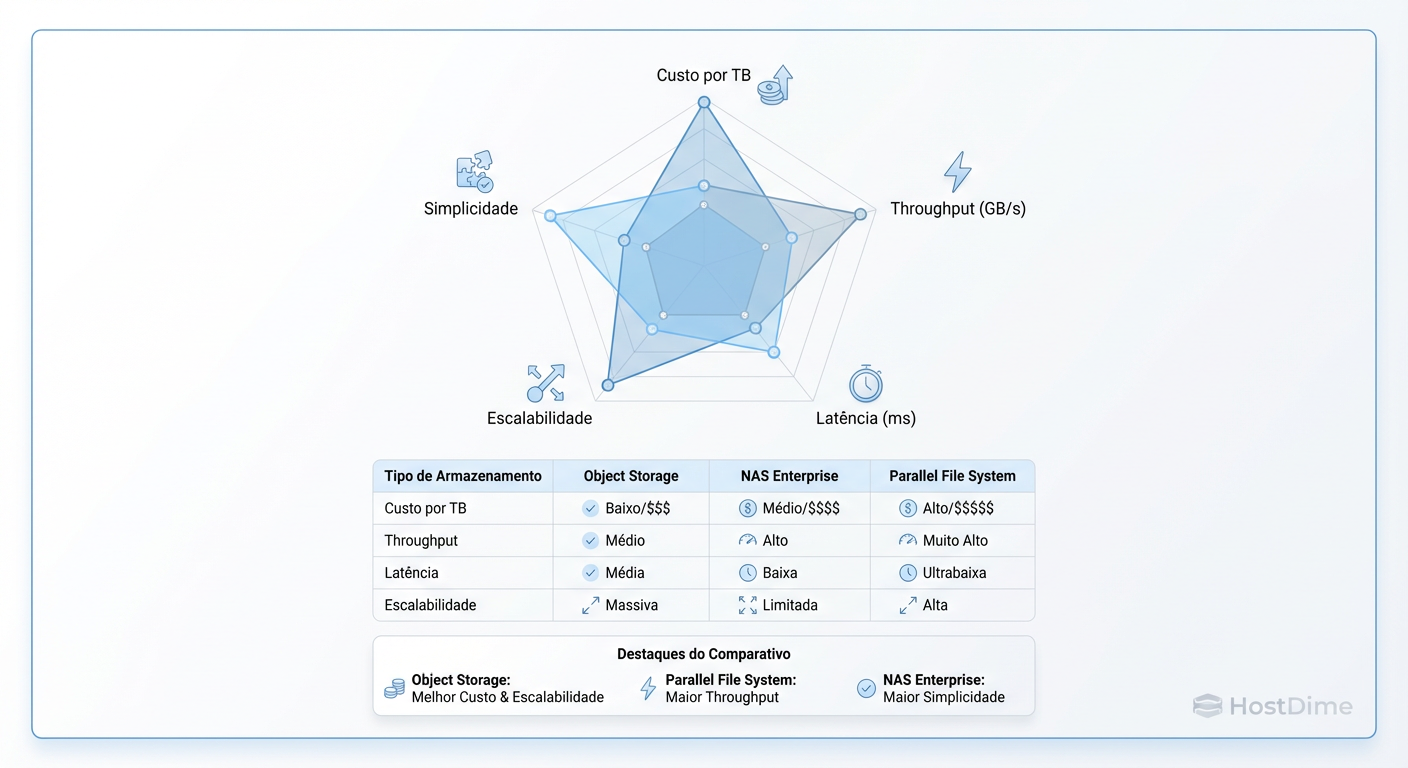 Figura: Fig. 3: Matriz de Trade-offs: Escolhendo a tecnologia certa para o workload certo.
Figura: Fig. 3: Matriz de Trade-offs: Escolhendo a tecnologia certa para o workload certo.
O Dilema dos Metadados
Um ponto frequentemente ignorado é a performance de metadados. Em Deep Learning, especialmente Visão Computacional, é comum ter datasets com 100 milhões de imagens de 20KB.
Um storage baseado em HDDs ou um Object Storage mal configurado pode levar mais tempo listando os arquivos e abrindo as conexões do que efetivamente transferindo os dados.
Trade-off: Sistemas que gerenciam metadados em memória (NVMe/RAM) são drasticamente mais rápidos, mas aumentam o custo da infraestrutura base.
Throughput vs. IOPS
Throughput (GB/s): Crítico para carregar modelos grandes (LLMs) na memória e para streaming de vídeo.
IOPS (Input/Output Operations Per Second): Crítico para processamento de texto, logs e dados tabulares onde as leituras são pequenas e aleatórias.
Decisão: Otimizar para Throughput geralmente sacrifica latência. Otimizar para IOPS exige mídia flash de alta qualidade (NVMe), elevando o TCO.
Decisão Recomendada: A Arquitetura de Tiering Inteligente
Considerando os fatores acima, raramente recomendo uma única camada de armazenamento para todo o ciclo de vida da IA. A abordagem monolítica é ineficiente financeiramente (guardar dados frios em NVMe) ou ineficiente tecnicamente (treinar modelos em HDD).
A arquitetura recomendada para ambientes Enterprise de alta escala é o Tiering Inteligente com Camada de Aceleração.
A Estrutura Lógica
Data Lake (Cold/Warm Tier): Object Storage (S3) em HDDs de alta densidade.
- Aqui reside a "Single Source of Truth". Todos os dados brutos, logs e datasets históricos. Baixo custo ($/GB).
Camada de Performance (Hot Tier): Sistema de Arquivos Paralelo ou NAS All-Flash NVMe.
- Esta camada atua como um cache gigante ou scratch space para os clusters de GPU.
Orquestração de Dados: Software que move dados transparentemente entre o Lake e a Camada de Performance.
Por que esta decisão?
Esta abordagem desacopla Capacidade de Performance. Você pode escalar o Data Lake para Petabytes sem comprar controladores flash caros. Quando um job de treinamento é agendado:
O orquestrador "hidrata" a camada Hot com o dataset específico do Data Lake.
As GPUs treinam com latência de microssegundos (NVMe).
Ao final, os resultados (checkpoints/modelos) são persistidos de volta no Data Lake.
A camada Hot é limpa para o próximo job.
Exemplo de política de orquestração (pseudocódigo conceitual):
# Exemplo conceitual de política de Tiering
def gerenciar_storage_lifecycle(dataset_id, job_status):
dataset_meta = get_metadata(dataset_id)
if job_status == 'SCHEDULED':
# Pré-aquecimento: Move do S3 (Cold) para NVMe (Hot)
if not dataset_meta.is_cached:
initiate_transfer(source='s3://datalake/ds1', target='/mnt/nvme/ds1')
elif job_status == 'COMPLETED':
# Evicção: Remove do NVMe para liberar espaço, mantém no S3
persist_checkpoints(source='/mnt/nvme/ds1/output', target='s3://datalake/ds1/output')
cleanup_cache('/mnt/nvme/ds1')
# O "Depende": Se o dataset for pequeno (< 1TB), talvez mantenha no NVMe
# para reuso imediato, evitando thrashing.
Visão de Longo Prazo: Data Gravity e o Papel do Edge na Inferência
Olhando para o horizonte de 3 a 5 anos, enfrentamos o desafio inexorável da Data Gravity (Gravidade dos Dados). À medida que os datasets crescem para a casa dos Exabytes, torna-se impossível movê-los.
O Fim do Movimento de Dados
A arquitetura futura não moverá dados para o compute (como descrevi no tiering acima), mas moverá o compute para o dado.
- Veremos mais processamento de pré-treino ocorrendo diretamente nos arrays de storage (Computational Storage), onde SSDs possuem processadores ARM ou FPGA embutidos para filtrar dados antes de enviá-los ao bus principal.
Inferência no Edge
Para inferência, a latência de rede torna a nuvem centralizada inviável para aplicações críticas (carros autônomos, robótica industrial).
A tendência é o modelo treinado no Core (Data Center) ser "podado" (pruning/quantization) e enviado para dispositivos de Edge.
O storage no Edge será efêmero, focado em ring buffers de alta velocidade que sobrescrevem dados antigos continuamente, enviando para o Core apenas os "eventos de interesse" para re-treino.
Veredito Técnico
Não existe "o melhor storage". Existe o storage que não deixa sua GPU de $30.000,00 esperando. Ao projetar para IA, comece pelo padrão de acesso aos dados, calcule o throughput necessário para saturar suas GPUs e use o tiering para manter o CFO feliz. O sucesso não é apenas treinar o modelo, é fazê-lo de forma economicamente viável.
Referências Bibliográficas
Google Cloud Architecture Center. (2023). Best practices for storage in AI and Machine Learning workloads.
NVIDIA Technical Brief. (2024). GPUDirect Storage: A Direct Path Between Storage and GPU Memory.
Vogels, W. (2022). The Distributed Computing Manifesto. Amazon Web Services.
McKusick, M. K., & Quinlan, S. (2010). GFS: Evolution on Fast-forward. ACM Queue.
Fowler, M. (2012). Patterns of Enterprise Application Architecture. Addison-Wesley Professional.

Viktor Kovac
Investigador de Incidentes de Segurança
"Não busco apenas o invasor, mas a falha silenciosa. Rastreio vetores de ataque, preservo a cadeia de custódia e disseco logs até que a verdade digital emerja das sombras."