Arquitetura de Storage Tiering: Integrando NVMe, SSD e Object Storage sem Latência
Domine a engenharia de Storage Tiering. Do NVMe-oF ao S3, aprenda a desenhar topologias SAN eficientes, configurar QoS e evitar gargalos em ambientes híbridos.
Para um Operador de Storage, a "latência zero" é o Santo Graal. No entanto, a realidade econômica dos Data Centers impõe uma necessidade brutal de eficiência: não podemos armazenar petabytes de logs frios em flash NVMe, nem podemos tolerar bancos de dados transacionais rodando em discos rotacionais ou Object Storage via HTTP.
A resposta está na Arquitetura de Storage Tiering Inteligente. Mas, diferentemente do que o marketing dos vendors sugere, o tiering não é apenas uma funcionalidade de software "set-and-forget". É um desafio de engenharia de tráfego. Mover blocos quentes de um Tier 2 (S3/NL-SAS) para um Tier 0 (NVMe) sem saturar os ISLs (Inter-Switch Links) ou causar buffer credit starvation exige um domínio profundo da fabric.
Neste artigo, vamos dissecar a infraestrutura necessária para suportar um ambiente onde NVMe, SSD SAS e Object Storage coexistem, focando no que importa: a integridade do sinal, a otimização do protocolo e a garantia de IOPS.
Topologia da Rede: Desenhando o Fluxo entre Tiers Físicos e Lógicos
A topologia de rede para um ambiente de tiering moderno deve abandonar o conceito legado de silos isolados. Não desenhamos mais uma SAN FC para o banco de dados e uma rede Ethernet separada para o backup. Hoje, buscamos uma Fabric Convergente ou, no mínimo, altamente integrada, capaz de sustentar diferentes classes de serviço (CoS).
Para suportar a baixa latência do NVMe e a largura de banda massiva do Object Storage, a topologia recomendada é a Spine-Leaf (para implementações baseadas em IP/Ethernet) ou Core-Edge (para Fibre Channel dedicado), com foco em oversubscription controlado.
O Desafio do Tiering Físico
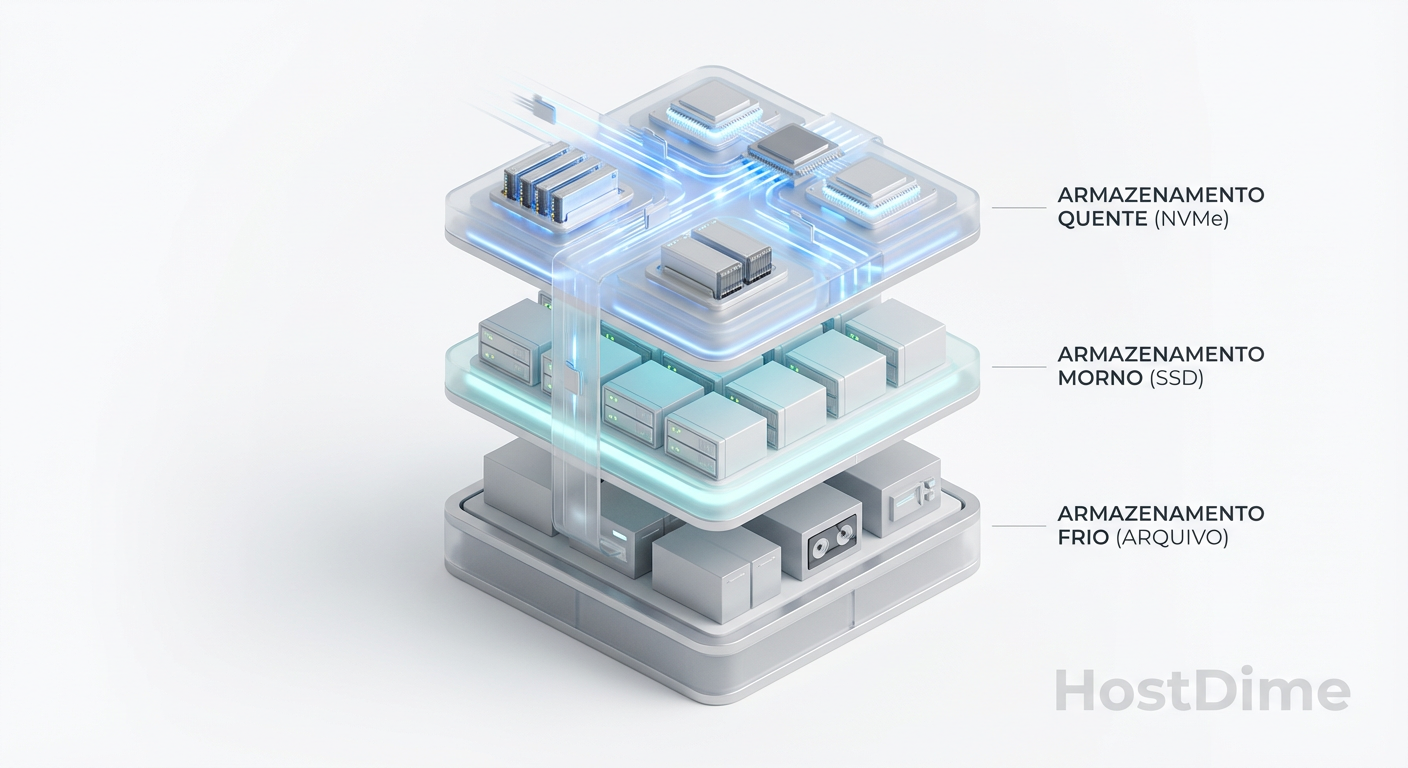
O tiering eficaz depende da proximidade do dado com a computação.
Tier 0 (Performance Extrema): Arrays All-NVMe conectados via NVMe-oF (over Fabrics) ou FC-NVMe de 32G/64G. Aqui, cada microssegundo conta. A topologia deve garantir no máximo um hop de switch.
Tier 1 (Performance/Capacidade): SSDs SAS/SATA conectados via iSCSI ou FC padrão. Ideal para virtualização geral.
Tier 2 (Cold/Archive): Object Storage (S3 compatible) em servidores densos, acessados via HTTP/TCP sobre Ethernet de alta largura de banda (25GbE/100GbE).
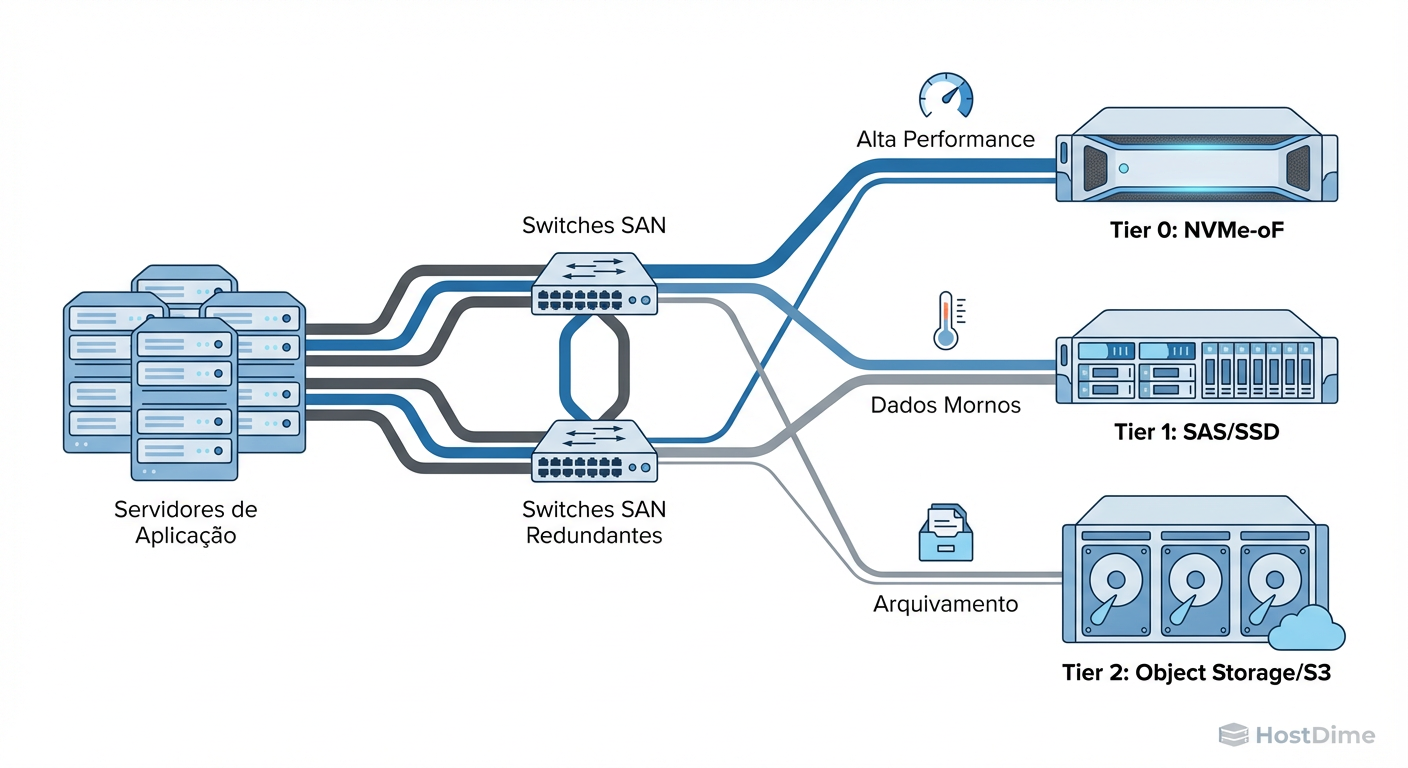 Figura: Fig. 1: Topologia física unificada suportando múltiplos protocolos e níveis de serviço (SLA) na mesma fabric.
Figura: Fig. 1: Topologia física unificada suportando múltiplos protocolos e níveis de serviço (SLA) na mesma fabric.
Ao desenhar esta topologia, o operador deve calcular o Fan-in ratio (relação entre portas de host e portas de storage). Para o Tier 0, buscamos uma relação de 1:1 ou no máximo 4:1 para evitar Head-of-Line Blocking. Já no Tier 2, podemos tolerar taxas de 10:1 ou superiores, pois o throughput é priorizado sobre a latência.
A chave aqui é garantir que o tráfego de backend (o movimento automático de dados entre tiers realizado pelo storage controller) não colida com o tráfego de frontend (I/O da aplicação). Idealmente, utilizamos VLANs ou VSANs dedicadas para o tráfego de replicação e tiering.
Protocolo em Detalhe: A Coexistência de NVMe-oF, FC e iSCSI/S3
A grande revolução no tiering não é apenas a mídia (Flash), mas o protocolo de transporte. O SCSI tradicional foi desenhado para discos que giram, com uma única fila de comandos. O NVMe foi desenhado para memória não volátil, suportando paralelismo massivo.
NVMe over Fabrics (NVMe-oF): O Motor do Tier 0
Enquanto o iSCSI e o FC tradicional encapsulam comandos SCSI, o NVMe-oF estende o conjunto de comandos NVMe nativos através da rede. A diferença na eficiência é brutal.
Filas: O SCSI tem uma fila única. O NVMe suporta até 64.000 filas, cada uma com 64.000 comandos.
Overhead: O NVMe-oF elimina a camada de tradução SCSI, reduzindo drasticamente os ciclos de CPU no host e no target.
Existem três sabores principais de NVMe-oF que você encontrará:
NVMe/FC: A implementação mais estável para quem já possui infraestrutura Fibre Channel Gen 6 (32G) ou superior. Utiliza a confiabilidade do FC (buffer credits) para transporte sem perdas.
NVMe/RoCEv2 (RDMA over Converged Ethernet): Oferece a menor latência possível em Ethernet, realizando o bypass do kernel do SO. Exige switches com suporte a DCB (Data Center Bridging) e Lossless Ethernet.
NVMe/TCP: A opção mais flexível e barata, rodando em switches Ethernet padrão, mas com um overhead de latência ligeiramente maior que o RoCE.
Comparativo de Eficiência de Protocolo
Abaixo, comparamos como cada protocolo se comporta em um cenário de tiering híbrido:
| Característica | NVMe-oF (Tier 0) | Fibre Channel (Tier 1) | iSCSI (Tier 1/2) | S3 / HTTP (Tier 2/3) |
|---|---|---|---|---|
| Mecanismo de Transporte | RDMA ou FC nativo | SCSI encapsulado | SCSI via TCP/IP | REST API via TCP/IP |
| Latência Típica | < 100 µs | 500 µs - 1 ms | 1 ms - 5 ms | 10 ms - 100+ ms |
| Paralelismo (Queue Depth) | Massivo (64k filas) | Limitado (Single Queue) | Limitado | Alto (via múltiplas conexões) |
| Uso de CPU (Host) | Mínimo (Offload) | Moderado | Alto (Cálculo CRC/TCP) | Baixo |
| Caso de Uso no Tiering | Dados Quentes (OLTP/AI) | VMs Críticas | File Services/General | Backup/Archive/Logs |
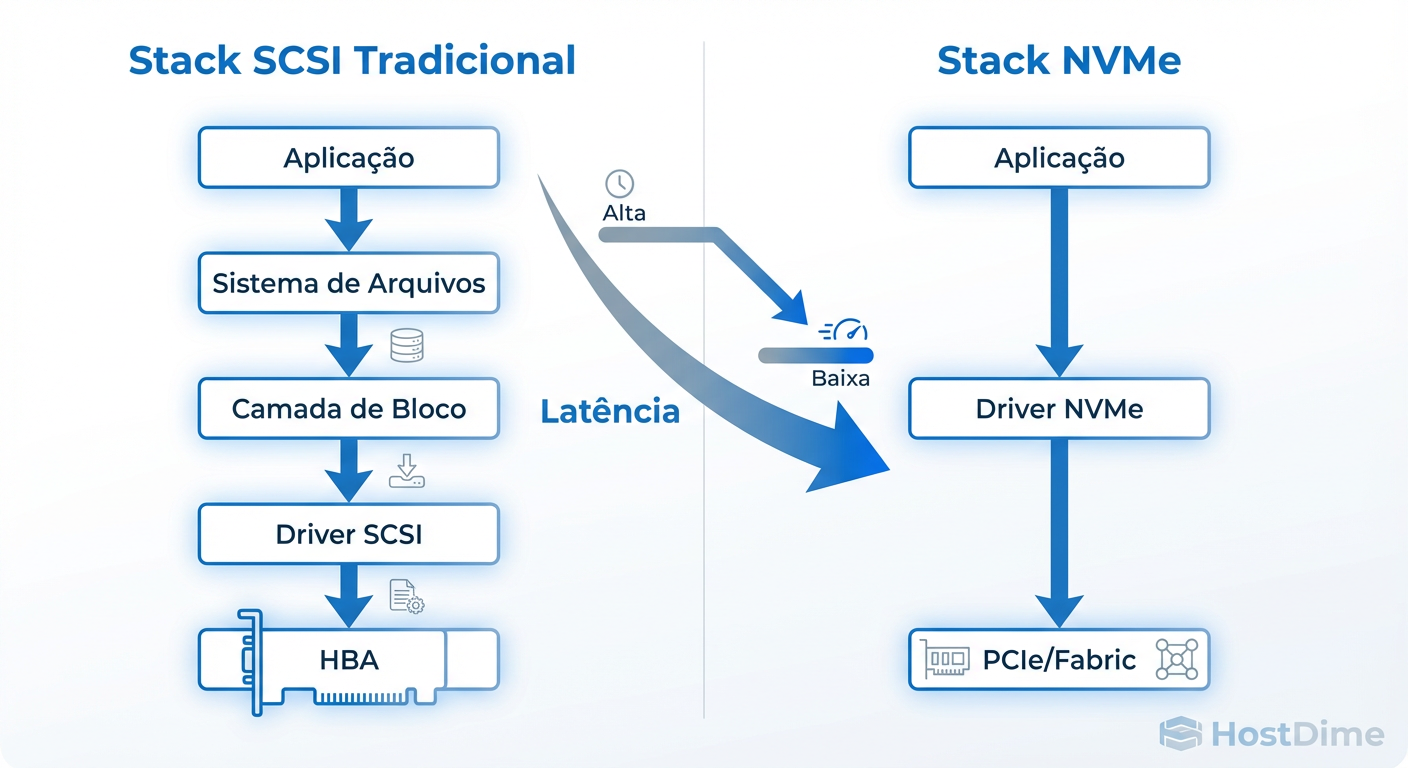 Figura: Fig. 2: Comparativo de eficiência de protocolo. O NVMe reduz ciclos de CPU e latência ao eliminar a tradução SCSI legada.
Figura: Fig. 2: Comparativo de eficiência de protocolo. O NVMe reduz ciclos de CPU e latência ao eliminar a tradução SCSI legada.
A coexistência é possível porque as fabrics modernas são multiprotocolo. Um switch Cisco MDS ou Brocade moderno pode trafegar FC tradicional e NVMe/FC na mesma porta e no mesmo cabo fibra óptica. O storage array inteligente decide, baseado em políticas de ILM (Information Lifecycle Management), se o dado deve ser servido via NVMe ou rebaixado para um protocolo de menor custo.
Configuração de Switch e HBA: Implementando QoS e Buffer Credits para Tiering
Aqui é onde separamos os arquitetos dos amadores. Para que o tiering funcione sem degradar a produção, a configuração da fabric deve ser impecável. O foco é evitar o congestionamento.
Fibre Channel: Buffer-to-Buffer Credits
No mundo FC, o controle de fluxo é baseado em créditos (R_RDY). Se um dispositivo (target) não processa frames rápido o suficiente, ele para de enviar créditos de volta ao switch, que por sua vez para de enviar para o host. Isso cria o temido Slow Drain Device.
Em um ambiente de tiering, quando grandes blocos de dados são movidos do Tier 0 para o Tier 2, o risco de esgotar os buffer credits é alto.
- Ação: Monitore as portas conectadas aos arrays de storage. Se notar contadores de
time_at_zero_creditsubindo, você precisa aumentar a alocação de buffers para essas portas ou investigar gargalos no storage.
Ethernet (RoCEv2 e iSCSI): Data Center Bridging (DCB)
Para NVMe/RoCE, a perda de pacotes é inaceitável. O TCP retransmite, mas o RDMA depende de uma rede sem perdas para manter a performance. Você deve configurar:
Priority Flow Control (PFC - IEEE 802.1Qbb): Permite pausar apenas classes de tráfego específicas (ex: prioridade 3 para Storage) sem parar todo o link.
Enhanced Transmission Selection (ETS - IEEE 802.1Qaz): Garante banda mínima para o tráfego de storage, mesmo sob congestionamento.
Explicit Congestion Notification (ECN): Sinaliza ao host para reduzir a taxa de transmissão antes que o buffer do switch estoure.
Exemplo de Configuração de Interface (Perfil Engenheiro)
Abaixo, um exemplo de configuração de uma interface em um switch Nexus para suportar tráfego jumbo e QoS para NVMe/iSCSI:
interface Ethernet1/1
description UPLINK_STORAGE_TIER0_NVME
mtu 9216
switchport mode trunk
switchport trunk allowed vlan 100,200
service-policy type qos input POLICY_CLASSIFY_NVME
service-policy type queuing input POLICY_QUEUING_NVME
service-policy type queuing output POLICY_QUEUING_NVME
service-policy type network-qos POLICY_NETWORK_NVME
# Controle de Fluxo
priority-flow-control mode auto
no shutdown
Nota: A consistência do MTU é vital. Um MTU de 9000 no switch e 1500 no host resultará em fragmentação ou falha total de conexão.
Zoning e Masking: Segregação de Tráfego por Criticidade de Dados
Segurança e performance caminham juntas. O Zoning (na fabric) e o LUN Masking (no storage) são as ferramentas primárias para isolamento.
Em arquiteturas de tiering, é comum ter múltiplos initiators acessando o mesmo target físico, mas visando LUNs (Logical Unit Numbers) com níveis de serviço diferentes.
Single Initiator, Single Target (SIST)
A regra de ouro permanece: crie zonas pequenas.
Zona A: Host_DB_HBA1 + Storage_CtlrA_NVMe_Port
Zona B: Host_Backup_HBA1 + Storage_CtlrA_SATA_Port
Nunca misture tráfego de fita (Tape) ou tráfego de replicação massiva na mesma zona que seus HBAs de produção NVMe. O tráfego de burst sequencial do backup pode causar latência no tráfego randômico do banco de dados devido ao fenômeno de Microbursts.
Masking e Storage Groups
No array, utilize Storage Groups (ou Host Groups) para mapear volumes específicos.
Host de Aplicação Crítica: Vê apenas Volumes Flash/NVMe.
Host de Analytics: Pode ver um snapshot do volume Flash e volumes diretos no Tier Object/SATA.
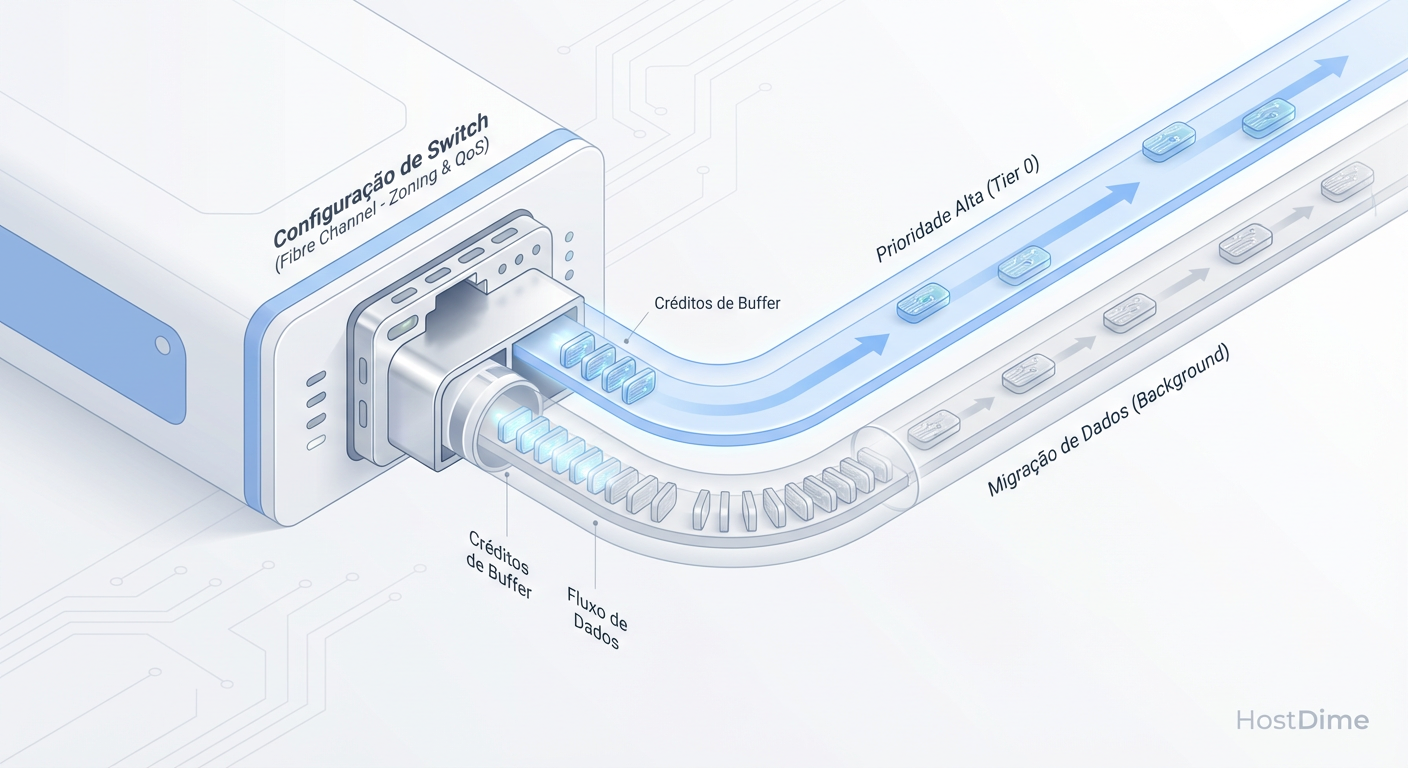 Figura: Fig. 3: Mecanismos de QoS e Zoning no Switch para garantir que o tráfego de rebalanceamento entre tiers não afete a latência da produção.
Figura: Fig. 3: Mecanismos de QoS e Zoning no Switch para garantir que o tráfego de rebalanceamento entre tiers não afete a latência da produção.
Se você estiver utilizando NVMe-oF, o conceito de Subsystem NQN (NVMe Qualified Name) substitui o WWPN do FC e o IQN do iSCSI. O masking é feito permitindo que apenas NQNs específicos se conectem a determinados Namespaces NVMe.
Otimização de Throughput: Ajustando MTU e Queue Depth para Migração Automática
O processo de tiering automático (ex: mover dados que não são acessados há 30 dias para Object Storage) gera um I/O de background constante. Se não otimizado, esse processo compete com a produção.
Jumbo Frames (MTU 9000+)
Para iSCSI, NVMe/TCP e S3, habilitar Jumbo Frames é obrigatório para eficiência de throughput.
Por que? Reduz a taxa de interrupções na CPU (menos pacotes para processar para a mesma quantidade de dados) e aumenta a eficiência do payload (menos cabeçalho por byte de dado).
Impacto no Tiering: A migração de grandes arquivos para o Tier Object (S3) é significativamente acelerada com frames maiores.
Queue Depth Tuning
O Queue Depth (profundidade da fila) define quantos comandos de I/O podem estar "em voo" simultaneamente.
Para SSD/NVMe: Precisamos de filas profundas (High Queue Depth) para manter o drive ocupado e aproveitar o paralelismo interno. Configurações padrão de SO (ex: 32 ou 64) são frequentemente baixas demais para NVMe, que pode suportar milhares.
Para HDD/SATA: Filas muito profundas apenas aumentam a latência, pois o disco mecânico não consegue processar os comandos rapidamente.
Estratégia de Ajuste: Em um ambiente híbrido, configure o HBA para um Queue Depth alto (ex: 128 ou 256) para acomodar o Tier NVMe. No entanto, utilize as configurações de Adaptive Queueing no driver do HBA ou no Hypervisor (VMware SIOC, por exemplo). Isso permite que o sistema reduza dinamicamente a fila se detectar latência vinda de LUNs que residem em tiers mais lentos, evitando o congestionamento da porta.
Veredito Técnico: O Equilíbrio entre Custo e IOPS na Estratégia de Dados
Implementar uma arquitetura de storage tiering que integre NVMe, SSD e Object Storage não é apenas uma questão de comprar hardware de ponta; é um exercício de orquestração de protocolos. O NVMe-oF elimina os gargalos históricos de latência para dados quentes, enquanto o Object Storage oferece a escala econômica necessária para a retenção de longo prazo.
Como operadores de storage, nossa responsabilidade é garantir que a "estrada" (a fabric) esteja pavimentada corretamente. Isso significa:
Topologias limpas sem gargalos de fan-in.
Configurações de switch que priorizem o tráfego Lossless para NVMe.
Segregação rigorosa via Zoning para proteger cargas de trabalho críticas.
Ajustes finos de MTU e Queue Depth para maximizar o throughput de migração.
A latência zero pode ser uma meta assintótica, mas com a engenharia correta, podemos tornar a latência irrelevante para a experiência do usuário final, entregando o dado certo, no tier certo, na velocidade da luz.
Referências Bibliográficas
NVM Express Organization. "NVM Express over Fabrics (NVMe-oF) Specification 1.1".
SNIA (Storage Networking Industry Association). "Performance Implications of Storage Class Memory and NVMe".
INCITS T11 Committee. "Fibre Channel - Physical Interface-6 (FC-PI-6) Standard".
Cisco Systems. "White Paper: Intelligent Traffic Management with Cisco MDS 9000".
IETF RFC 7143. "Internet Small Computer System Interface (iSCSI) Protocol (Consolidated)".

Dr. Elena Kovic
Metodologista de Benchmark
"Desmonto o marketing com análise estatística rigorosa. Meus benchmarks isolam cada variável para revelar a performance crua e sem filtros do hardware corporativo."