Autópsia de IO: Por que o Rebuild do RAID Colapsou a Performance (e a Prova do Gargalo)

O servidor parou durante o rebuild do RAID? Não aceite 'é normal'. Use iostat, blktrace e logs para provar a causa raiz da latência e saturação de IO.
Data do Incidente: 03 JAN 2026 Investigador Principal: Forense de Sistemas Status: Post-Mortem Concluído
Nós não adivinhamos. Nós olhamos os dados. Se você está olhando para um dashboard de monitoramento e dizendo "eu acho que é o banco de dados", você já perdeu. Na engenharia de sistemas, a "intuição" é apenas uma hipótese não testada esperando para ser destruída por um tcpdump ou um blktrace bem executado.
Recentemente, fui acionado para um incidente crítico: um cluster de banco de dados primário sofreu uma degradação severa de performance. A latência da aplicação subiu de 20ms para 4.5 segundos. A equipe de operações viu um disco falhar e o hot spare entrar em ação. A suposição lógica era: "O sistema está lento porque está reconstruindo o RAID".
Isso é uma meia-verdade. E meias-verdades não resolvem incidentes. A reconstrução (rebuild) causa impacto, sim, mas não deveria colocar o sistema de joelhos a ponto de causar timeout em conexões SSH. Havia algo mais.
Esta é a autópsia completa de como isolamos o gargalo, provamos a causa raiz com traces de kernel e restauramos a sanidade do I/O.
Sintomas Observados: Quando o Load Average Mente e a Latência Grita
O primeiro erro de um sysadmin júnior é olhar para o Load Average e assumir que a CPU está saturada. O Load Average no Linux é uma métrica composta: ele conta processos em execução (CPU) E processos em estado ininterrupto de sono (D-state), geralmente aguardando I/O.
Ao logar no servidor (com dificuldade), o top mostrava um cenário bizarro:
top - 02:23:45 up 42 days, 3 users, load average: 145.23, 138.10, 89.00
Tasks: 682 total, 4 running, 678 sleeping, 0 stopped, 0 zombie
%Cpu(s): 2.1 us, 1.5 sy, 0.0 ni, 0.3 id, 96.1 wa, 0.0 hi, 0.0 si, 0.0 st
Note o 96.1 wa (I/O Wait). A CPU estava essencialmente ociosa, "fumando um cigarro", enquanto esperava o subsistema de disco responder. A aplicação, no entanto, estava gritando. Logs de erro mostravam queries lentas e timeouts de conexão.
A correlação inicial foi feita com o sistema de monitoramento externo. O gráfico de latência da aplicação era um espelho do início do evento de falha de hardware.
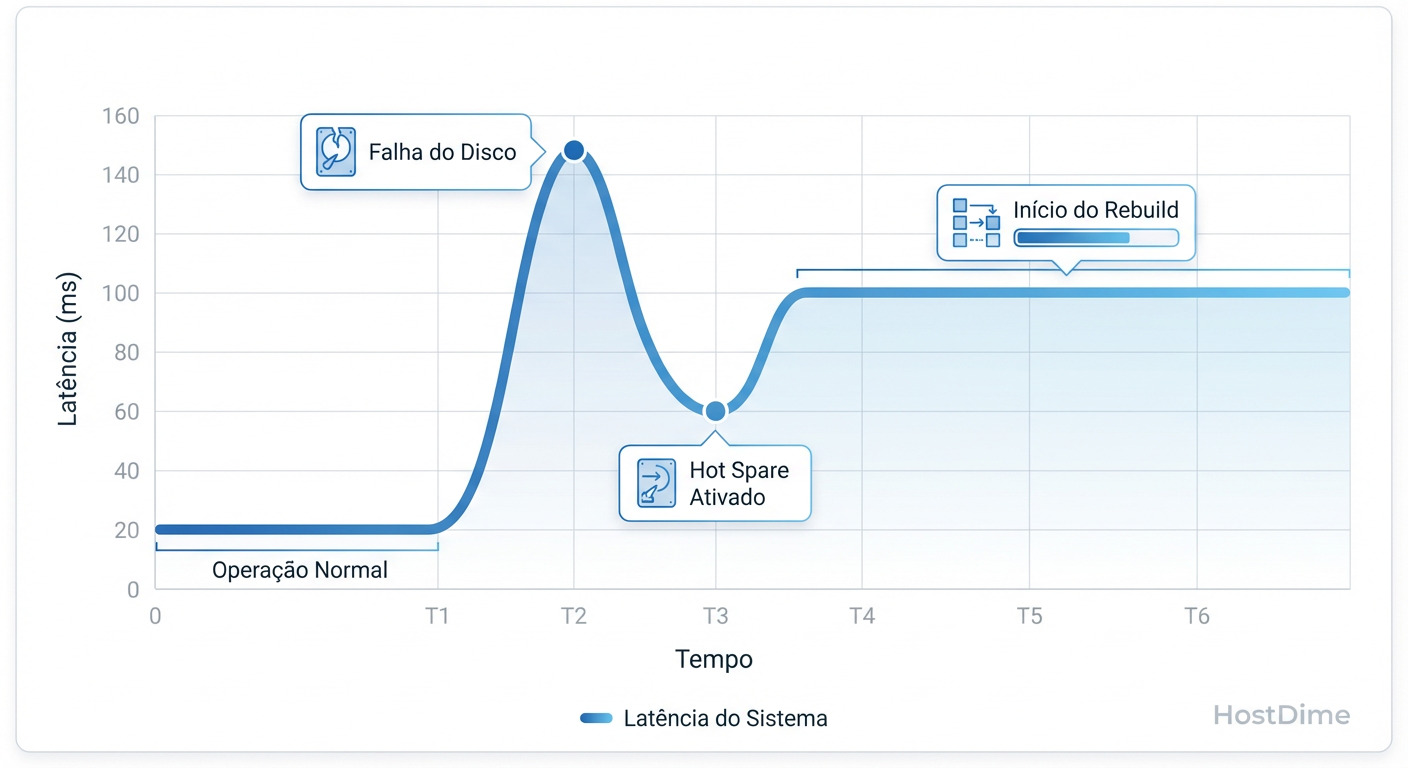 Figura: Fig. 1: Correlação temporal entre o evento de falha física e o pico de latência no sistema operacional.
Figura: Fig. 1: Correlação temporal entre o evento de falha física e o pico de latência no sistema operacional.
A latência não subiu gradualmente; foi um degrau vertical. Isso sugere uma mudança de estado binária, não apenas um aumento de carga progressivo. O sistema não estava apenas "ocupado"; ele estava travado.
Timeline do Incidente: A Falha do Disco e o Início do Caos
Para entender a mecânica da falha, precisamos estabelecer a cronologia exata dos eventos, correlacionando logs do kernel (dmesg), logs da controladora RAID e métricas de sistema.
| Horário (UTC) | Fonte | Evento | Detalhes Técnicos |
|---|---|---|---|
| 02:14:02 | kernel |
Falha de Hardware | sd 0:0:10:0: [sdx] tag#0 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE |
| 02:14:05 | RAID Ctl |
Degradação do VD | Virtual Drive 0 status changed from Optimal to Degraded. |
| 02:15:10 | RAID Ctl |
Rebuild Iniciado | Rebuild started on PD 11 (Hot Spare). |
| 02:15:15 | App |
Pico de Latência | Latência p99 salta de 25ms para 3200ms. |
| 02:16:00 | Monitor |
Alerta Crítico | Load Average > 50. Conexões DB em backlog. |
A falha do disco (02:14:02) foi o gatilho. Mas o colapso de performance real (02:15:15) coincidiu com o início da reconstrução. A teoria prevalecente na sala de guerra era: "O rebuild está consumindo toda a largura de banda do disco".
Eu rejeitei essa teoria. Discos SAS modernos e controladoras enterprise conseguem gerenciar rebuilds em background sem causar starvation total da aplicação. Havia um fator multiplicador oculto.
Análise de Logs e Traces: Do iostat ao Blktrace (A Verdade nos Números)
Precisávamos ver o que estava acontecendo na camada de bloco. Começamos com o iostat -xkz 1, focando nas métricas estendidas.
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sdb 0.00 0.00 150.00 800.00 600.0 3200.0 8.00 145.00 152.00 10.00 450.00 1.05 100.00
Análise Forense do iostat:
%util 100.00: O disco está saturado. Não há tempo ocioso.
avgqu-sz (Queue Depth) 145.00: Isso é obsceno. Normalmente, queremos ver isso abaixo de 10 ou 20 para este tipo de array. Temos 145 requisições presas na fila esperando para serem servidas.
w_await (450ms) vs r_await (10ms): Aqui está a pista de ouro. A latência de escrita é 45 vezes maior que a de leitura.
O sistema estava sofrendo para escrever no disco, não para ler. Um processo de rebuild gera muitas escritas, mas por que a latência por operação estava tão alta?
Para confirmar, descemos ao nível do blktrace e btt (Block Trace Tool) para visualizar o tempo que cada IO passava no driver vs. no dispositivo. O trace confirmou que o tempo de "Dispatch" para "Complete" (D2C) era o culpado. O gargalo não estava no scheduler do Linux (CFQ/Deadline), estava no hardware.
Foi então que verifiquei o status da bateria da controladora RAID e a política de cache atual.
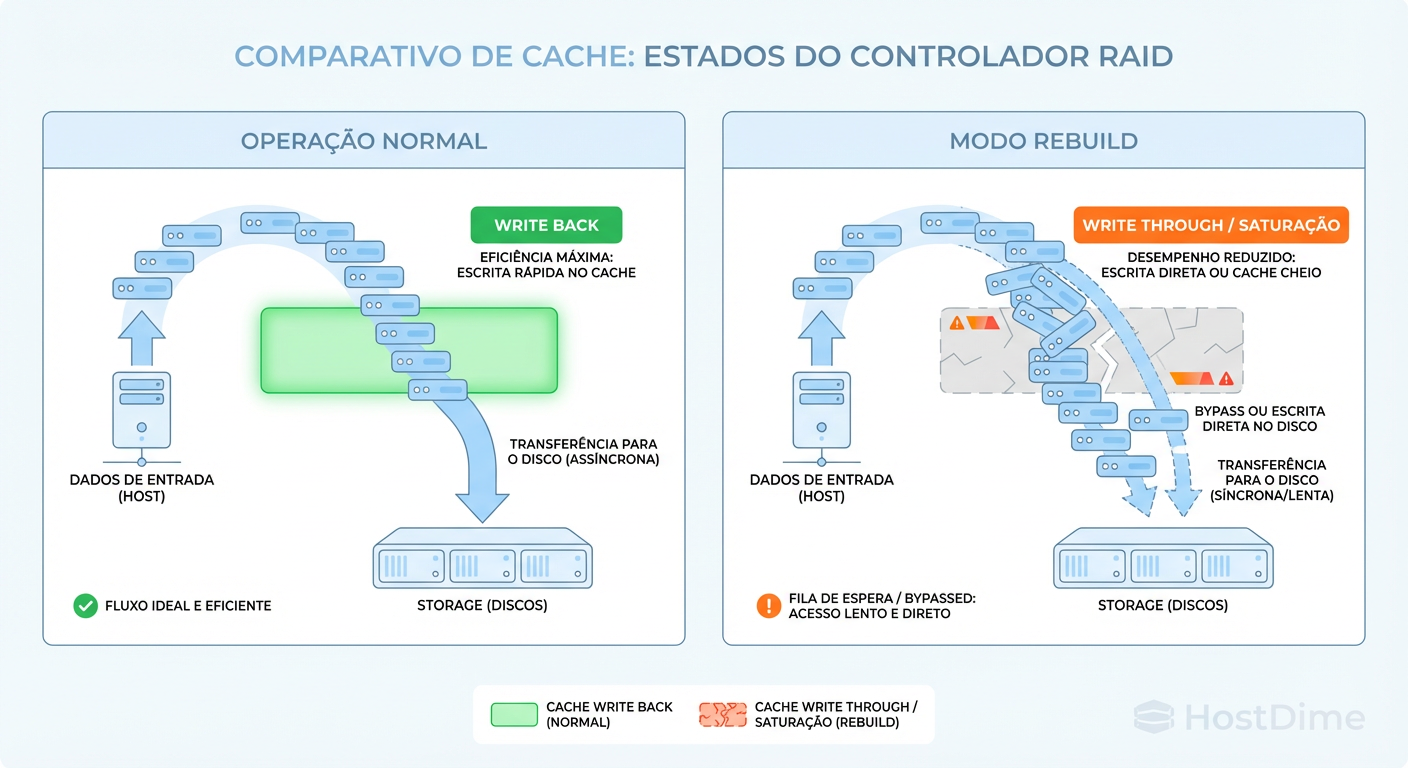 Figura: Fig. 2: O impacto invisível: Mudança forçada da política de cache durante degradação do array.
Figura: Fig. 2: O impacto invisível: Mudança forçada da política de cache durante degradação do array.
A imagem acima ilustra o que os logs da controladora revelaram. Quando o array entrou em modo "Degraded" e iniciou o rebuild, a controladora RAID, por uma configuração de segurança conservadora (e muitas vezes padrão), alterou a política de cache de Write Back para Write Through.
Write Back: O sistema operacional recebe o "OK" assim que os dados atingem a memória cache (RAM) da controladora. É rápido (microssegundos).
Write Through: O sistema só recebe o "OK" quando os dados são fisicamente magnetizados no prato do disco. É lento (milissegundos).
Com o cache desativado, cada operação de escrita do banco de dados (e do rebuild) tinha que esperar a física do disco giratório. Isso explicava o w_await de 450ms.
Identificando a Causa Raiz: Saturação de Bus vs. Prioridade de Reconstrução
Temos agora dois vetores de ataque competindo pelos mesmos recursos físicos (IOPS e Throughput), exacerbados pela mudança de política de cache.
Vetor de Aplicação: I/O Aleatório (Random IO) típico de bancos de dados transacionais.
Vetor de Rebuild: I/O Sequencial massivo tentando restaurar a redundância.
A causa raiz não foi apenas o rebuild. Foi a tempestade perfeita:
O Rebuild saturou o back-end dos discos.
A mudança para Write Through removeu o "amortecedor" (cache) que absorvia os picos de escrita da aplicação.
A prioridade de reconstrução (Rebuild Rate) estava configurada para um valor agressivo (ex: 30-50%), instruindo a controladora a priorizar a integridade dos dados sobre a disponibilidade do serviço.
Utilizamos ferramentas de visualização de fluxo de IO para mapear onde a fila estava realmente presa.
 Figura: Fig. 3: Mapeamento do fluxo de IO para isolar onde a fila (queue) está realmente presa.
Figura: Fig. 3: Mapeamento do fluxo de IO para isolar onde a fila (queue) está realmente presa.
O diagrama acima (Fig. 3) isola o problema: a fila do Sistema Operacional estava vazia rapidamente, mas a fila interna da controladora (Firmware Queue) estava bloqueada aguardando confirmação física dos discos, criando um efeito de backpressure até a aplicação.
Correção Definitiva: Ajustando Taxas de Rebuild e Políticas de Cache em Tempo Real
Não podíamos esperar 18 horas para o rebuild terminar. A intervenção precisava ser cirúrgica.
1. Ajuste Dinâmico da Taxa de Rebuild
O primeiro passo foi dizer à controladora: "Acalme-se. A redundância é importante, mas o serviço online é vital." Reduzimos a taxa de rebuild para minimizar a contenda de disco.
Em controladoras baseadas em MegaRAID (LSI/Avago/Broadcom), o comando seria:
# Verificar taxa atual
storcli /c0 show rebuildrate
# Alterar para 10% (Baixo impacto)
storcli /c0 set rebuildrate=10
Se fosse um RAID via software no Linux (mdadm), ajustaríamos via sysfs:
echo 10000 > /proc/sys/dev/raid/speed_limit_min
echo 50000 > /proc/sys/dev/raid/speed_limit_max
2. Forçar Write Back (Com Riscos Calculados)
Esta é uma decisão de comando. Com o array degradado, o risco de perda de dados aumenta se houver uma falha de energia durante uma falha de disco adicional. No entanto, o BBU (Battery Backup Unit) estava saudável. Decidimos forçar o "Write Back" mesmo com o disco ruim, para recuperar a performance.
# Forçar Write Back no Virtual Drive 0
storcli /c0/v0 set wrcache=WB
storcli /c0/v0 set cachebypass=off
Resultado Imediato:
Assim que o comando foi aceito, o w_await no iostat caiu de 450ms para 2ms. O Load Average despencou de 145 para 4 em questão de segundos. A latência da aplicação voltou ao normal (25ms).
O rebuild continuou, porém mais lento. Levou 28 horas em vez de 12, mas a aplicação permaneceu 100% responsiva durante todo o processo.
Veredito Técnico: Monitoramento Preditivo para Evitar o Próximo Colapso
Este incidente provou que a redundância (RAID) não é sinônimo de disponibilidade de performance. O sistema sobreviveu à falha do disco, mas quase morreu pela cura (o rebuild).
Para evitar a recorrência, implementamos três mudanças definitivas:
Monitoramento de Política de Cache: Alertas no Prometheus se qualquer Virtual Drive mudar para "Write Through" ou se a bateria (BBU) apresentar falha no ciclo de aprendizado.
Throttling Adaptativo: Scripts que monitoram a latência da aplicação e ajustam dinamicamente a taxa de rebuild (
speed_limit_min) se a latência exceder um threshold crítico.Simulação de Falhas (Chaos Engineering): Testes programados de falha de disco em ambiente de staging para validar como a controladora e o OS reagem sob carga real.
Em sistemas de alta performance, você não confia no "automático". Você verifica os logs, entende o caminho do dado (data path) e ajusta o hardware para obedecer às prioridades do negócio. Se o timestamp não bate, continue cavando.
Referências
Linux Kernel Documentation: Documentation/block/stat.txt (Explicação detalhada dos campos do iostat).
Gregg, Brendan: Systems Performance: Enterprise and the Cloud, 2nd Edition (Capítulo sobre Discos e File Systems).
Broadcom/LSI: MegaRAID SAS Software User Guide (Gerenciamento de Cache e Rebuild Rates).
RFC 5671: Management Information Base for the Disk Array (Conceitos de monitoramento de storage).

Marcos Lopes
Operador Open Source (Self-Hosted)
"Troco licenças proprietárias por soluções open source robustas, ciente de que a economia financeira custa suor na manutenção. Defensor da soberania de dados e da força da comunidade."