Autópsia de Storage: Investigando Latência e Travamentos Quando 'Ninguém Mexeu'

Guia de análise forense para sistemas de armazenamento. Aprenda a usar dmesg, iostat e eBPF para isolar a causa raiz de falhas de I/O e latência oculta.
Para um Investigador Forense de Sistemas, a frase "o servidor travou e ninguém mexeu em nada" é o equivalente a um suspeito na sala de interrogatório jurando inocência enquanto segura a arma do crime. Sabemos que sistemas de armazenamento (storage) não decidem, arbitrariamente, entrar em colapso. Eles obedecem à física e ao código.
Quando a latência de disco dispara e as aplicações entram em timeout, não estamos lidando com fantasmas. Estamos lidando com filas saturadas, locks de kernel, ou hardware gritando por socorro em frequências que o monitoramento padrão ignora.
Neste relatório de autópsia, vamos dissecar um incidente de degradação de storage. Deixaremos de lado a intuição e usaremos dados. Vamos do sintoma vago à chamada de sistema (syscall) culpada.
Sintomas Observados: O mito do 'sistema parou do nada' e a Latência de Storage
O primeiro passo em qualquer investigação forense não é olhar para o terminal, mas entender o álibi. O relato inicial geralmente chega via ticket de suporte: "O banco de dados está lento" ou "O site caiu".
Para o olho destreinado, o sistema está "parado". Para nós, ele está provavelmente em um estado de atividade frenética ou bloqueio total. O sintoma clínico mais comum em problemas de storage não é o erro explícito, mas o Load Average alto acompanhado de baixa utilização de CPU (User/System).
Quando você vê um Load Average de 50 em uma máquina com 4 vCPUs, mas o uso de CPU está em 2%, você tem a assinatura clássica de processos em estado D (Uninterruptible Sleep).
Traduzindo "Lentidão" para "Wait I/O"
Processos entram em estado D quando solicitam um bloco de dados ao disco e o kernel diz: "Espere aqui, estou buscando". Enquanto o disco não responde, esse processo não pode ser interrompido, nem mesmo por um kill -9. Ele conta como "processo em execução" para o cálculo de carga, inflando o Load Average.
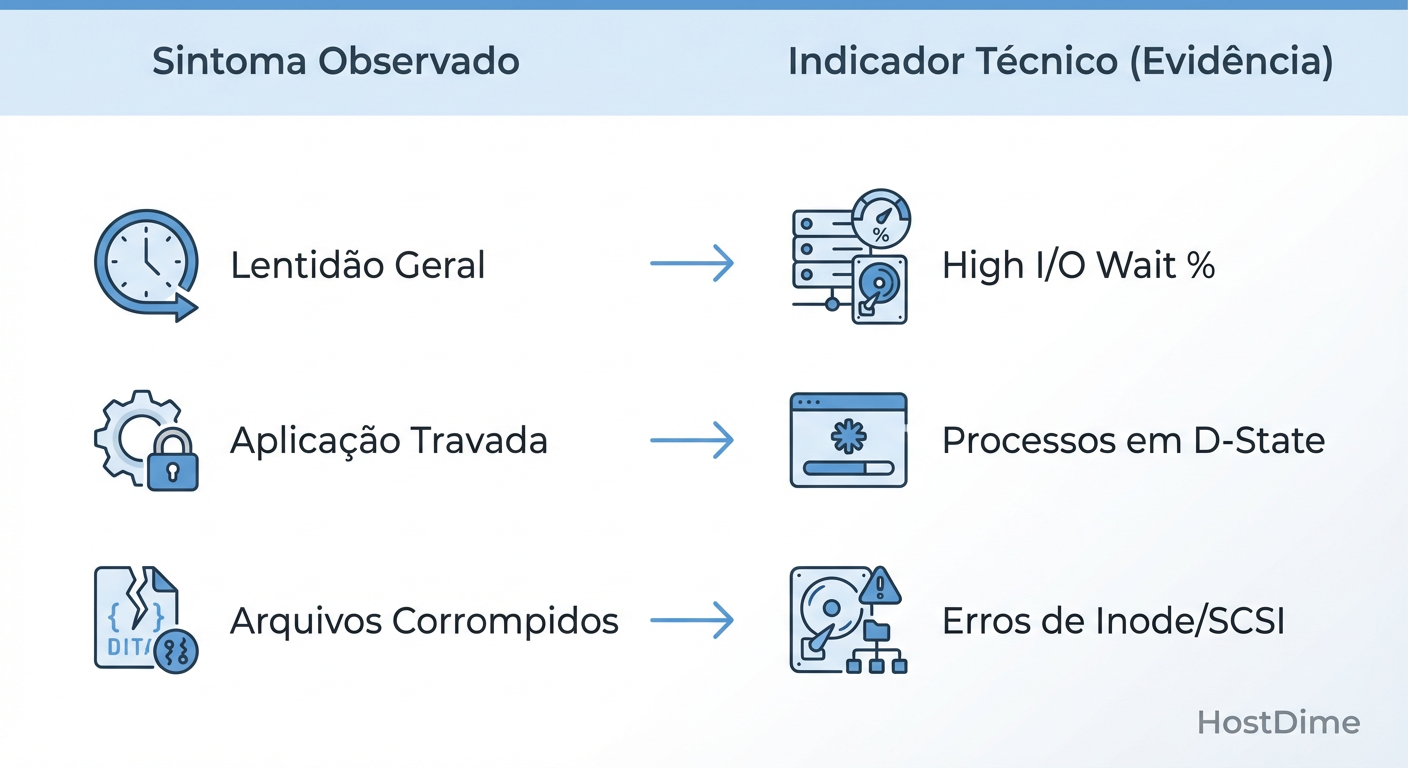 Figura: Fig. 3: Traduzindo sintomas vagos de usuários em evidências forenses concretas.
Figura: Fig. 3: Traduzindo sintomas vagos de usuários em evidências forenses concretas.
Como ilustrado acima, o usuário percebe a "lentidão" na camada de aplicação (HTTP 504 Gateway Timeout), mas a evidência forense reside na camada de bloco. O sintoma real é a latência de conclusão de I/O. Se um disco NVMe que deveria responder em 100 microssegundos começa a responder em 50 milissegundos, o sistema operacional entra em colapso por congestionamento, não por falta de processamento.
Timeline do Incidente: Reconstruindo a cena do crime via Timestamps e Análise Temporal
A correlação não implica causalidade, mas a correlação temporal é a melhor pista que temos. O erro mais comum na análise de incidentes de storage é olhar para médias de 5 ou 15 minutos.
O I/O é "rajado" (bursty). Um pico de escrita de 2 segundos pode preencher o buffer de gravação do controlador RAID, elevando a latência para todos os outros processos pelos 30 segundos seguintes enquanto o controlador tenta drenar o cache para o disco físico.
A Regra do Segundo
Para reconstruir a cena, precisamos de granularidade de 1 segundo. Ferramentas de monitoramento que agregam dados a cada minuto (como muitas configurações padrão do CloudWatch ou Zabbix) suavizam os picos, escondendo a arma do crime.
Ao alinhar os logs da aplicação com as métricas de sistema, procuramos o "Paciente Zero":
T-minus 0s: O início do pico de latência de leitura (
r_await).T-minus 0s: O início de um pico de vazão de escrita (
wMB/s).
Frequentemente, descobrimos que o problema de leitura (banco de dados lento) é causado por um "vizinho barulhento" de escrita (backup, rotação de logs, ou swap storm).
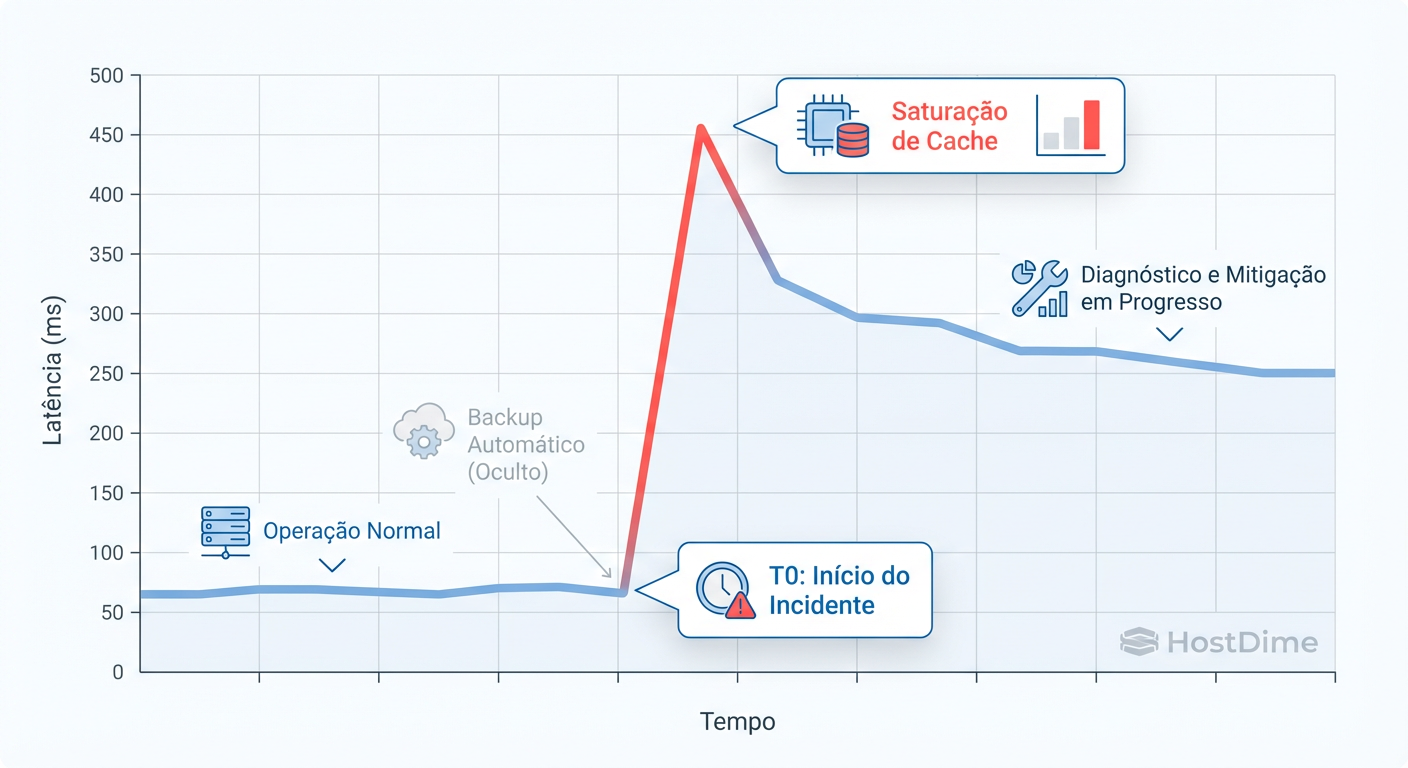 Figura: Fig. 1: A correlação temporal é a chave. O gráfico demonstra como um processo agendado invisível coincidiu com o pico de latência.
Figura: Fig. 1: A correlação temporal é a chave. O gráfico demonstra como um processo agendado invisível coincidiu com o pico de latência.
A reconstrução da timeline nos permite afirmar categoricamente: o incidente não foi aleatório. Ele foi agendado. O pico de latência correlaciona perfeitamente com a execução do updatedb (indexação de arquivos) ou aquele dump de banco de dados que o desenvolvedor jurou que rodava "só de madrugada", esquecendo-se do fuso horário UTC.
Análise de Logs e Traces: De iostat a chamadas de sistema (syscalls)
Agora que temos o tempo do crime, precisamos da arma. Vamos descer do nível do usuário para o nível do kernel. Minha ferramenta de escolha inicial é sempre o iostat, mas ele deve ser lido com ceticismo e precisão cirúrgica.
1. O Interrogatório Inicial: iostat -xz 1
Executar iostat sem flags é inútil. Precisamos ver as estatísticas estendidas (-x) e remover dispositivos inativos (-z), com atualização de 1 segundo.
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 150.00 2500.00 4.00 50000.00 38.00 145.00 85.00 2.00 90.00 0.37 99.00
Análise Forense do Output:
%util: 99.00%. O disco está ocupado o tempo todo? Sim. Isso significa que ele é o gargalo? Não necessariamente. Um disco pode estar 100% ocupado processando requisições sequenciais de forma eficiente.
avgqu-sz (Average Queue Size): 145.00. Aqui está o problema. Se o dispositivo suporta uma profundidade de fila (NCQ) de 32 e temos 145 requisições esperando, temos saturação.
w_await (90ms) vs r_await (2ms): A latência de escrita é massiva. A leitura é rápida. Isso indica que o write cache do dispositivo encheu ou estamos lidando com um padrão de escrita aleatória intensa que o disco não consegue acompanhar.
2. A Camada de Bloco e o Kernel: dmesg e smartctl
Antes de culpar o software, verifique se o hardware não está morrendo. O kernel do Linux reporta timeouts de hardware no ring buffer.
Execute dmesg | grep -i "error\|timeout\|reset". Se você vir mensagens como blk_update_request: I/O error ou scsi target reset, pare a investigação de software. O disco ou a controladora falharam. Confirme com smartctl -a /dev/sdX procurando por "Reallocated Sector Count".
3. Rastreamento Profundo: pidstat e biotop
Se o hardware está saudável, quem está gerando esse I/O? O top não mostra I/O por processo detalhadamente.
Usamos pidstat -d 1 para ver quem está escrevendo:
UID PID kB_rd/s kB_wr/s kB_ccwr/s Command
1000 4521 0.00 45000.00 0.00 java
0 782 4.00 0.00 0.00 kworker/u16:2
Aqui vemos o processo Java escrevendo 45MB/s. Mas onde e como?
Para casos extremos, recorremos ao eBPF (via ferramentas BCC como biotop ou biosnoop). Essas ferramentas interceptam o I/O na camada de bloco, abaixo do sistema de arquivos.
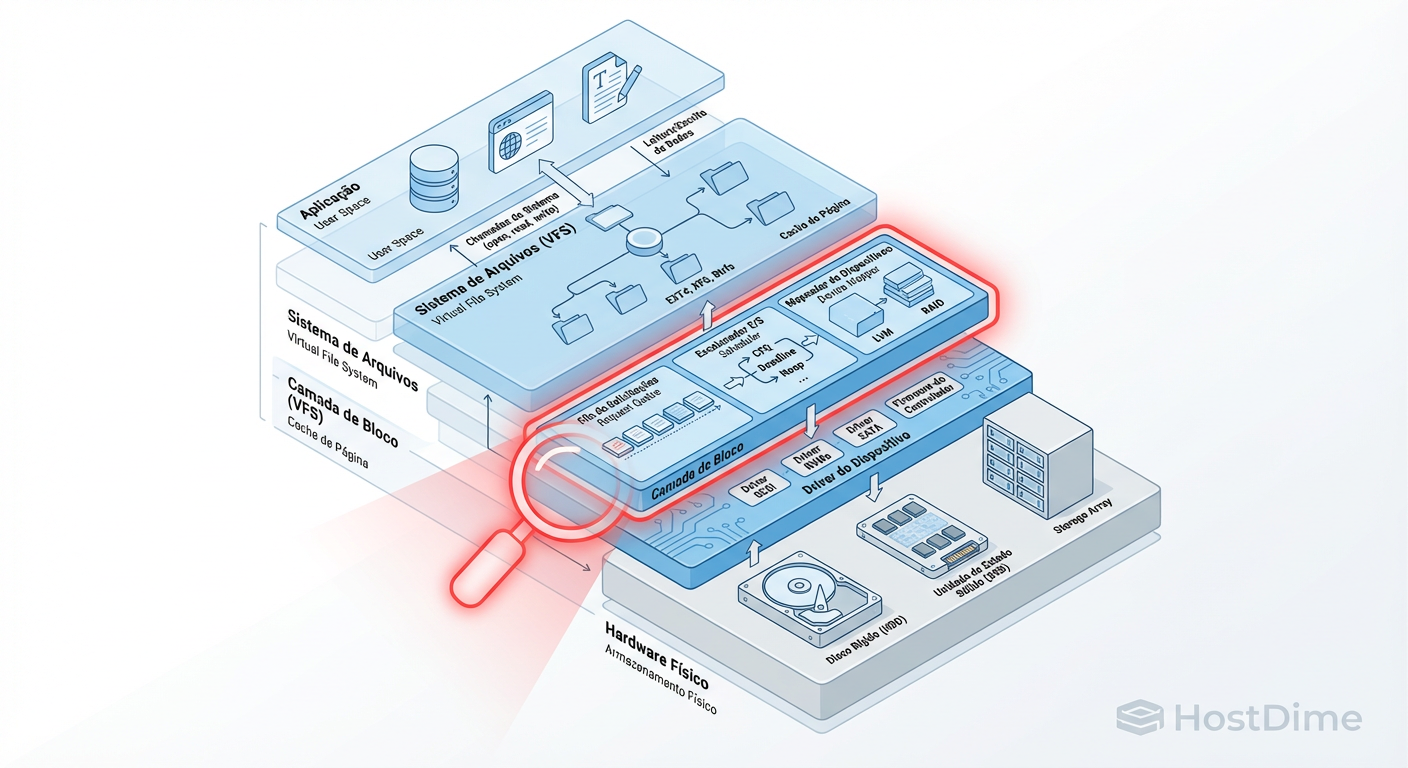 Figura: Fig. 2: O caminho do I/O. A maioria dos problemas 'misteriosos' reside entre o Sistema de Arquivos e a Camada de Bloco.
Figura: Fig. 2: O caminho do I/O. A maioria dos problemas 'misteriosos' reside entre o Sistema de Arquivos e a Camada de Bloco.
A imagem acima mapeia onde nossas ferramentas atuam. Muitos administradores ficam presos no topo (VFS), mas a verdade sobre a latência reside na transição entre a Camada de Bloco e o Driver do Dispositivo. O blktrace é a ferramenta definitiva aqui, permitindo ver cada estágio da vida de um pacote de I/O: enfileiramento, merge, despacho e conclusão.
Isolando a Causa Raiz: Hardware degradado ou gargalo de software?
Após a coleta de evidências, precisamos formular a acusação. Em incidentes de storage de alta complexidade, a causa raiz geralmente cai em uma de duas categorias: Saturação Física ou Contenção Lógica.
Diferenciando as Causas
| Sintoma | Causa Provável: Hardware/Física | Causa Provável: Software/Lógica |
|---|---|---|
| Latência Alta | Disco lento, seek time alto (HDD), SSD degradado (GC). | Fragmentação do FS, desalinhamento de partição. |
| Throughput Baixo | Cabo SATA/SAS defeituoso, negociação de link errada. | Tamanho de bloco da aplicação muito pequeno (muitos IOPS, poucos MB/s). |
| CPU em Wait (iowait) | Controlador saturado. | Contenção de locks no sistema de arquivos (ex: Journaling ext4). |
| Erros no Log | SCSI resets, ATA errors. | OOM Killer, Filesystem Read-only. |
O Caso da "Tempestade de Flush"
Um cenário que encontro frequentemente: a aplicação escreve dados na memória (Page Cache) muito rápido. O sistema operacional diz "sucesso" imediatamente (gravação assíncrona). A aplicação fica feliz.
Entretanto, o kernel Linux precisa eventualmente jogar essa sujeira (dirty pages) para o disco. Quando o limite vm.dirty_ratio é atingido, o kernel bloqueia todas as escritas para forçar a limpeza.
Diagnóstico: Você vê um padrão de "dente de serra" no throughput de disco. Períodos de silêncio seguidos por picos massivos de latência onde tudo trava.
Causa Raiz: Configuração de memória virtual (sysctl) inadequada para a velocidade do storage subjacente. O software está enviando dados mais rápido do que a física do disco permite gravar permanentemente.
Correção Definitiva: Mitigação imediata e rearquitetura de I/O
Não aceitamos "reiniciar o servidor" como solução. Isso é destruir evidências e garantir que o problema voltará na próxima madrugada. A correção deve ser cirúrgica.
1. Mitigação Tática (O "Torniquete")
Se o servidor está travado agora:
Identifique e congele: Use
pidstat -dpara achar o culpado. Se for um backup ou processo batch, pause-o (kill -STOP <PID>). Isso alivia o I/O imediatamente sem perder o estado do processo.Ajuste de Prioridade: Use
ionicepara rebaixar a classe de I/O do processo ofensor para "Idle".ionice -c 3 -p <PID>Isso diz ao agendador de I/O (CFQ ou BFQ) para só servir esse processo quando ninguém mais precisar do disco.
2. Correção Estratégica (A Cura)
Para evitar a reincidência, precisamos de mudanças arquiteturais baseadas nos dados coletados:
Tuning de Kernel (Dirty Pages): Para evitar os travamentos por flush, diminua o
vm.dirty_background_ratioevm.dirty_ratio. Force o kernel a começar a gravar no disco mais cedo e em lotes menores, em vez de esperar acumular gigabytes de dados na RAM.sysctl -w vm.dirty_background_ratio=5 sysctl -w vm.dirty_ratio=10Isolamento de I/O (Rearquitetura): Mova os logs (escrita sequencial, append-only) para um disco físico separado dos arquivos de dados do banco (leitura aleatória). O padrão de I/O misto destrói a performance de discos mecânicos e satura filas de SSDs baratos.
Escolha do Scheduler: Verifique o agendador de I/O:
cat /sys/block/sda/queue/scheduler.- Para NVMe/SSD modernos: Use
noneoukyber(deixe o dispositivo gerenciar, ele é inteligente). - Para HDD/SATA: Use
bfqoumq-deadline.
- Para NVMe/SSD modernos: Use
Veredito Técnico da Investigação
A latência de storage nunca surge do nada. Ela é o resultado acumulado de configurações padrão otimistas colidindo com a realidade de cargas de trabalho pessimistas. Ao utilizar uma abordagem baseada em timestamps precisos, análise de filas e rastreamento de syscalls, transformamos o "mistério" em um problema de engenharia corrigível. O sistema não é assombrado; ele está apenas mal configurado.
Referências Bibliográficas
Gregg, Brendan. Systems Performance: Enterprise and the Cloud, 2nd Edition. Addison-Wesley Professional, 2020. (A bíblia da análise de performance).
Corbet, Jonathan; Rubini, Alessandro; Kroah-Hartman, Greg. Linux Device Drivers. O'Reilly Media. (Para entendimento profundo da camada de bloco).
The Linux Kernel Documentation. Documentation/block/. (Fonte oficial sobre schedulers e filas de I/O).
Arpaci-Dusseau, Remzi H. & Andrea C. Operating Systems: Three Easy Pieces. (Capítulos sobre Persistência e File Systems).

Silvio Zimmerman
Operador de Backup & DR
"Vivo sob o lema de que backup não existe, apenas restore bem-sucedido. Minha religião é a regra 3-2-1 e meu hobby é desconfiar da integridade dos seus dados."