Autópsia de um Snapshot Imutável: Onde a Segurança Falha

Uma análise forense profunda sobre como snapshots imutáveis são comprometidos via ataques de NTP e falhas de API. Aprenda a auditar seus logs de storage.
O silêncio em um datacenter é o som mais aterrorizante que um engenheiro de armazenamento pode ouvir. Não o silêncio acústico das ventoinhas, mas o silêncio nos gráficos de IOPS de leitura logo após um alerta de ransomware. Recentemente, fui chamado para investigar um incidente em uma infraestrutura crítica onde a "bala de prata" da segurança moderna falhou: os snapshots imutáveis foram deletados.
A promessa do marketing é sedutora: "WORM (Write Once, Read Many) garante que seus dados estão salvos, mesmo se o admin for comprometido". A realidade forense, no entanto, é que a imutabilidade é frequentemente uma construção de software, e todo software obedece a entradas que podem ser manipuladas.
Não estamos aqui para discutir políticas de backup em fita. Vamos abrir os logs, analisar os timestamps e entender como, tecnicamente, um atacante pode contornar travas de retenção em sistemas de armazenamento modernos (seja S3 Object Lock, ZFS ou appliances dedicados).
Resumo em 30 segundos
- O Relógio é o Inimigo: A maioria dos sistemas de retenção baseia-se na lógica
data_atual < data_retenção. Se o atacante ganha root e altera o NTP/relógio do sistema para o ano 2099, a trava expira instantaneamente.- Governança vs. Compliance: Modos de retenção "soft" (Governance) permitem que usuários com permissões especiais (frequentemente roubadas) ignorem a imutabilidade. Apenas o modo "Compliance" ou WORM de hardware oferecem resistência real.
- Logs Internos não Mentem: Em sistemas como ZFS, o comando
zpool history -ilrevela as chamadas de sistema exatas, mostrando a sequência de manipulação de tempo seguida pela destruição do dataset, mesmo que os logs do syslog tenham sido limpos.
O alerta de integridade e a latência no commit
O incidente começou com uma anomalia de performance, não de segurança. O sistema de monitoramento (Prometheus/Grafana) registrou um pico absurdo de latência na operação de sync de disco, seguido por uma queda vertical na capacidade utilizada do pool de armazenamento.
Em sistemas de arquivos copy-on-write (CoW) como ZFS ou Btrfs, ou em backends de Object Storage (Ceph/MinIO), a deleção massiva de snapshots não é gratuita. Ela gera uma tempestade de metadados. O sistema precisa marcar blocos como livres e atualizar árvores B-tree gigantescas.
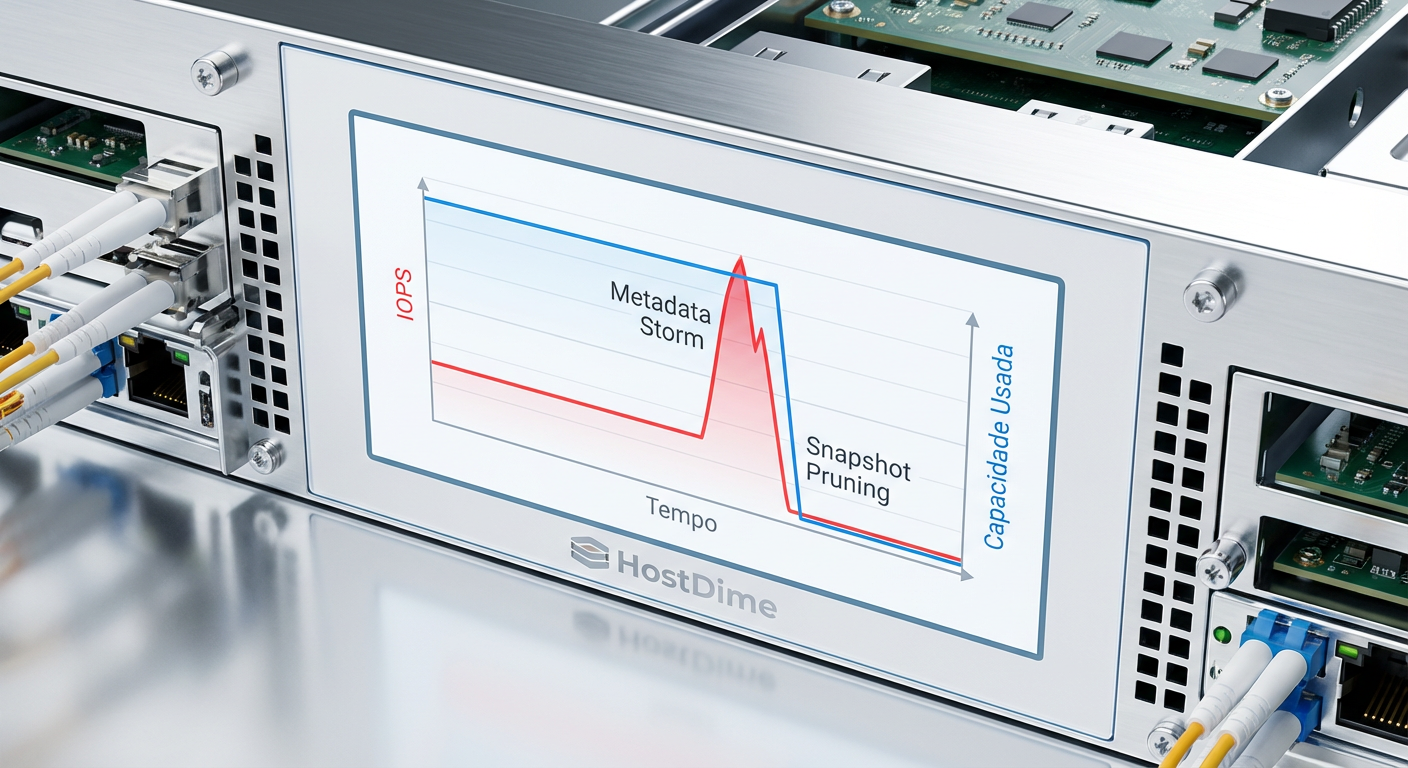 Figura: Visualização da anomalia de I/O durante a destruição de snapshots.
Figura: Visualização da anomalia de I/O durante a destruição de snapshots.
Ao analisar os logs de latência do subsistema de disco, notamos que o tempo de serviço (svctm no iostat) para operações de metadados disparou. O atacante não apenas deletou os dados; ele forçou o sistema a processar a liberação de petabytes de referências lógicas.
💡 Dica Pro: Configure alertas de "taxa de variação negativa" no seu armazenamento. Se o seu storage libera 20% da capacidade total em menos de 10 minutos, isso raramente é uma limpeza de rotina. É um ataque ou um erro catastrófico de script.
O vetor de ataque via NTP: Time Shift
A análise forense revelou que as credenciais de root do appliance de storage haviam sido comprometidas. No entanto, a pergunta permanecia: como eles deletaram snapshots configurados com retenção de 30 dias, criados apenas 48 horas antes?
A resposta estava no daemon de tempo.
A imutabilidade lógica é uma equação simples:
if (current_system_time > retention_end_date):
allow_delete()
else:
throw_error("WORM Protected")
O atacante não tentou quebrar a criptografia ou explorar um bug de buffer overflow no kernel do storage. Eles simplesmente usaram o acesso root para:
Parar o serviço NTP (
systemctl stop chronyd).Avançar o relógio do sistema para o ano 2035 (
date -s "2035-01-01 12:00:00").Executar o comando de deleção.
Para o kernel do storage, a retenção havia expirado legitimamente há anos. O sistema, obediente, permitiu a destruição dos dados.
⚠️ Perigo: Muitos appliances de storage "Enterprise" são apenas servidores Linux endurecidos. Se não houver uma validação de tempo baseada em hardware (RTC inviolável) ou consenso externo que não possa ser vetado pelo root local, a imutabilidade é ilusória.
A falácia da imutabilidade lógica: Governance vs. Compliance
Nem toda imutabilidade nasce igual. No ecossistema de Object Storage (S3, compatível com AWS, Azure Blob, Google Cloud Storage), existe uma distinção crítica que frequentemente passa despercebida durante a configuração inicial e se torna fatal durante um ataque.
Muitas equipes configuram o Object Lock no modo Governance. Este modo protege contra deleções acidentais por usuários comuns, mas permite que uma identidade com a permissão s3:BypassGovernanceRetention delete os objetos ou altere a retenção.
Se o atacante compromete a conta de serviço do software de backup (ex: Veeam, Commvault) e essa conta tem permissões administrativas totais sobre o bucket (o que é comum por preguiça de configuração), o modo Governance não oferece proteção alguma. O script de ataque simplesmente insere o header x-amz-bypass-governance-retention: true na requisição HTTP DELETE, e o storage obedece.
Comparativo: Níveis de Proteção de Retenção
| Característica | Governance Mode (S3) | Compliance Mode (S3) | WORM de Hardware / Air Gap |
|---|---|---|---|
| Proteção contra Root/Admin | Baixa. Admins podem remover a trava. | Alta. Ninguém (nem root) remove a trava antes do prazo. | Máxima. Fisicamente impossível alterar. |
| Vetor de Ataque Principal | Roubo de credenciais privilegiadas. | Manipulação de NTP (Time Shift) ou destruição física do array. | Acesso físico ao datacenter. |
| Flexibilidade | Alta. Permite correções de retenção. | Nula. Errou o prazo? Vai pagar pelo armazenamento até expirar. | Nula. |
| Complexidade de Gestão | Baixa. | Média. Requer planejamento rigoroso de capacidade. | Alta. Requer gestão de mídia física ou hardware dedicado. |
Autópsia forense: rastreando o zpool history
Voltando ao incidente em questão, o sistema subjacente era baseado em ZFS. O atacante foi inteligente o suficiente para limpar o .bash_history e rotacionar os logs do /var/log. No entanto, eles esqueceram que sistemas de arquivos avançados mantêm seus próprios diários de transações.
O ZFS possui um log interno de comandos que modificam o estado do pool, armazenado nos metadados do próprio disco, não no sistema de arquivos raiz do SO. Isso significa que, mesmo formatando o disco de boot, se o pool de dados sobreviver, o histórico sobrevive.
Executei o seguinte comando para extrair a verdade:
zpool history -il tank
A flag -i mostra os eventos internos e -l mostra o formato longo com timestamps e IDs de usuário.
 Figura: Log forense do ZFS revelando a sequência de comandos destrutivos.
Figura: Log forense do ZFS revelando a sequência de comandos destrutivos.
O output foi conclusivo:
Timestamp Real (T-10min):
zfs set readonly=off tank/backups(Tentativa falha, retornou erro de WORM).Timestamp Falso (T+10anos): O log do kernel registrou um salto no TXG (Transaction Group). O relógio do sistema foi alterado.
Timestamp Falso (T+10anos + 1min):
zfs destroy -r tank/backups. Sucesso.
O atacante não sabia que o zpool history registra o timestamp do kernel no momento da execução. A correlação entre os logs de acesso SSH (que recuperamos de um servidor syslog remoto) e os TXGs do ZFS provou a manipulação.
Implementando WORM rígido e isolamento
Para evitar que essa autópsia seja do seu sistema, precisamos endurecer a implementação. A imutabilidade baseada apenas em software, onde o plano de controle (o SO do storage) e o plano de dados (os discos) compartilham o mesmo domínio de confiança, é inerentemente falha.
1. Isolamento do Plano de Controle
O storage imutável não deve ser membro do domínio do Active Directory. Ele não deve usar as mesmas senhas de root que seus servidores Linux padrão. O acesso à interface de gerenciamento (IPMI/iDRAC e SSH) deve ser restrito a uma VLAN de gerenciamento isolada, acessível apenas via Jump Host com MFA.
2. NTP Seguro e Consenso
Configure o storage para rejeitar alterações de tempo que excedam um desvio (drift) máximo (ex: 15 minutos) sem uma reinicialização física ou uma chave de autorização secundária. Alguns vendors implementam um "relógio de conformidade" interno que corre independentemente do relógio do sistema operacional e não pode ser alterado via CLI.
3. A Regra dos Dois Homens (Four-Eyes Principle)
Operações destrutivas ou alterações na política de retenção devem exigir aprovação de dois usuários distintos. No mundo de Object Storage, isso pode ser implementado via políticas de IAM que exigem MFA especificamente para a ação DeleteObject, ou via workflows de aprovação no software de backup.
 Figura: Arquitetura de isolamento para repositórios imutáveis.
Figura: Arquitetura de isolamento para repositórios imutáveis.
O veredito forense
A segurança de armazenamento não é um produto que você compra; é uma arquitetura que você mantém. Neste incidente, a organização comprou "Imutabilidade" como um checkbox em uma planilha de aquisição, mas falhou em proteger o anel de chaves que controlava essa imutabilidade.
Se você gerencia petabytes, pare de confiar cegamente na flag "Locked". Audite seus vetores de tempo. Verifique quem tem a permissão de BypassGovernance. E, acima de tudo, assuma que o root do seu storage será comprometido. Quando isso acontecer, a física do seu hardware será a única coisa entre a recuperação e o desastre.
Referências & Leitura Complementar
NTP Security Analysis: RFC 5905 (Network Time Protocol Version 4).
ZFS Internals: OpenZFS Documentation -
zpool-history(8).S3 Object Lock Specs: AWS S3 API Reference -
PutObjectRetention.SNIA: Storage Networking Industry Association - "Data Protection & Privacy".
FAQ: Perguntas Frequentes sobre Segurança de Storage
O que é o ataque de 'Time Shift' em repositórios de backup?
É uma técnica onde atacantes manipulam o relógio do sistema (via NTP comprometido ou acesso root direto) para uma data futura. Isso faz com que o sistema de armazenamento acredite que o período de retenção (WORM) dos snapshots já expirou, permitindo sua exclusão prematura e contornando a proteção de imutabilidade.Qual a diferença forense entre Governance Mode e Compliance Mode?
No Governance Mode, logs de auditoria mostrarão a chamada de API `s3:BypassGovernanceRetention` sendo usada com sucesso para deletar objetos antes do prazo. No Compliance Mode, essa chamada é rejeitada pelo sistema (mesmo para o usuário root), e tentativas de exclusão geram erros de `Access Denied` ou `403 Forbidden` visíveis nos logs de erro do storage, preservando os dados.Como verificar se um snapshot ZFS foi destruído maliciosamente?
O comando `zpool history -il` revela o log interno de transações (TXG) do ZFS, que é independente dos logs do sistema operacional. Procure por comandos `zfs destroy` executados logo após alterações de tempo ou a liberação de um `zfs release`. A correlação dos timestamps dessas transações com logins SSH suspeitos é a prova definitiva.
Bruno Albuquerque
Investigador Forense de Sistemas
"Não aceito 'falha aleatória'. Com precisão cirúrgica, mergulho em logs e timestamps para expor a causa raiz de qualquer incidente. Se deixou rastro digital, eu encontro."