Backup Imutável Não É Magia: O Caos da Restauração Sob Ataque

A imutabilidade protege contra deleção, mas não contra corrupção lógica. Descubra como validar a integridade de backups WORM e evitar o colapso de IOPS durante incidentes críticos.
A frase mais perigosa que um Comandante de Incidentes pode ouvir durante uma crise de ransomware não é "fomos invadidos", mas sim: "fique tranquilo, temos backup imutável". Essa falsa sensação de segurança tem transformado incidentes recuperáveis em desastres de perda total de dados.
A imutabilidade, ou WORM (Write Once, Read Many), é uma funcionalidade crítica de armazenamento, mas não é uma vacina. No cenário atual de infraestrutura, onde o armazenamento é definido por software (SDS) e reside em camadas complexas de abstração, acreditar que o "cadeado" da API do S3 salvará a empresa é um erro de arquitetura primário. Vamos dissecar o que acontece quando a teoria do vendor encontra a realidade hostil de um ataque sofisticado.
Resumo em 30 segundos
- Imutabilidade não garante limpeza: Se o ransomware criptografar os dados antes da janela de backup, você terá uma cópia imutável e perfeitamente inútil de dados criptografados.
- O gargalo da reidratação: Restaurar petabytes de dados deduplicados gera uma tempestade de IOPS de metadados que pode colapsar controladores de storage, tornando o RTO (Recovery Time Objective) inalcançável.
- Ataque ao catálogo: Cibercriminosos agora focam em corromper o banco de dados de índices do software de backup, tornando os blocos imutáveis órfãos e inacessíveis sem engenharia reversa complexa.
A injeção de payload em janelas de backup imutável
O conceito de imutabilidade protege o dado de ser deletado ou alterado após a gravação. O problema reside no tempo de permanência (dwell time) do atacante. Grupos de ransomware modernos, como BlackCat ou LockBit, não detonam a carga imediatamente. Eles permanecem na rede por semanas, escalando privilégios e compreendendo a topologia de armazenamento.
Durante esse período, o processo de backup continua operando normalmente. O software de backup lê os blocos do disco de produção (seja VMFS, NTFS ou XFS), processa a deduplicação e grava no repositório imutável. Se o atacante começar a criptografar arquivos lentamente ou injetar binários maliciosos sem detoná-los, o backup imutável protegerá esses arquivos corrompidos com a mesma diligência que protege arquivos legítimos.
⚠️ Perigo: A imutabilidade segue o princípio "Garbage In, Garbage Out". Se o dado de origem já está comprometido (criptografado ou infectado), a imutabilidade apenas garante que você não conseguirá deletar essa versão infectada antes do prazo de retenção expirar.
Isso cria um ciclo de restauração falho: a equipe de resposta a incidentes restaura o ambiente a partir do backup imutável de ontem, apenas para descobrir que o ransomware é reativado imediatamente ou que os dados já estavam ilegíveis.
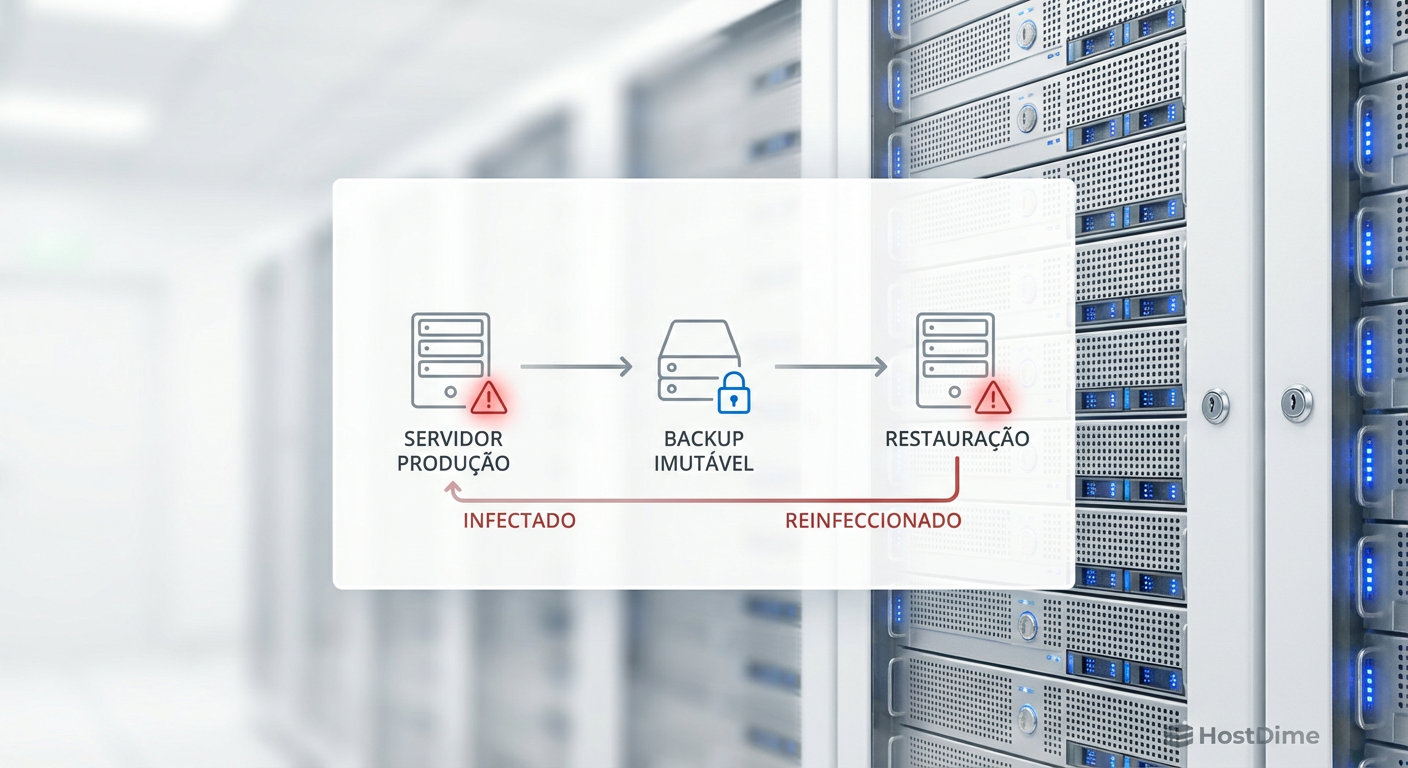 Figura: O ciclo de reinfecção através de backups imutáveis contaminados durante o dwell time do atacante.
Figura: O ciclo de reinfecção através de backups imutáveis contaminados durante o dwell time do atacante.
O ataque de negação de metadados e a orfandade de blocos
A maioria das soluções modernas de backup para disco (Disk-to-Disk) ou para nuvem (S3) depende pesadamente de deduplicação global e compressão. Isso significa que o arquivo "Financeiro.xlsx" não é gravado como um arquivo contínuo no storage. Ele é quebrado em milhares de blocos hash de 4KB ou 8KB, espalhados pelo sistema de arquivos do repositório.
Para reconstruir esse arquivo, o software de backup precisa consultar um banco de dados de metadados (o catálogo) que diz: "Para montar o arquivo X, pegue o bloco A, depois o B, depois o C".
Atacantes sofisticados pararam de tentar quebrar a criptografia do backup. Eles agora atacam a disponibilidade do catálogo. Se o atacante conseguir corromper ou deletar o banco de dados de índices do servidor de backup (que muitas vezes não é imutável ou reside em um sistema operacional Windows vulnerável), os dados brutos no storage imutável tornam-se "órfãos".
Você tem os terabytes de dados gravados no disco. Eles estão lá, imutáveis e seguros. Mas sem o mapa (o catálogo) para remontá-los, eles são apenas uma sopa de bits aleatórios. A reconstrução de um catálogo a partir dos blocos brutos pode levar dias ou semanas, um tempo que a maioria das empresas não possui.
A falácia da integridade baseada em Locking de API
Muitas implementações de armazenamento imutável baseiam-se no recurso de Object Lock do protocolo S3 ou em flags de imutabilidade em sistemas de arquivos Linux (como o chattr +i). A premissa é que, uma vez ativado o lock, nem mesmo o administrador root pode deletar o dado.
No entanto, a segurança é tão forte quanto a camada de gerenciamento. Em incidentes recentes, observamos atacantes que, ao não conseguirem deletar os buckets S3 imutáveis, optaram por:
Envenenar o ciclo de vida: Alterar as políticas de retenção para o mínimo possível em novos jobs.
Exaustão de recursos: Disparar scripts que criam milhões de pequenos objetos ou versões de arquivos, saturando a capacidade do storage ou estourando a conta de nuvem da vítima, forçando uma interrupção de serviço por falta de pagamento ou espaço.
Sequestro de Console: Se o atacante compromete as credenciais da console de gerenciamento do storage (o painel de controle do appliance físico ou da nuvem), ele pode, em alguns casos, realizar um "factory reset" ou destruir o volume lógico (LUN) onde o bucket reside. O dado dentro do bucket era imutável, mas o container que o segurava foi destruído.
💡 Dica Pro: A imutabilidade lógica (software) deve ser acompanhada de segregação física ou lógica de gerenciamento. As credenciais que acessam o software de backup NUNCA devem ter permissão para acessar a console de gerenciamento do storage array ou da conta AWS/Azure.
O pesadelo da reidratação: IOPS e Latência
Vamos falar de física de discos. Quando você precisa restaurar 500 TB de dados após um ataque total, o perfil de I/O (Input/Output) muda drasticamente em comparação com a janela de backup diária.
O backup é sequencial e previsível. A restauração de dados deduplicados é aleatória e caótica. O sistema de storage precisa buscar milhões de blocos espalhados para "reidratar" os arquivos. Isso gera uma carga massiva de leituras aleatórias (Random Read).
Se o seu repositório de backup utiliza discos rígidos mecânicos (HDD) de alta capacidade (ex: 20TB NL-SAS) sem uma camada robusta de cache em Flash/NVMe para os metadados, o desempenho cairá drasticamente. Vemos arrays de storage que prometem 5GB/s de throughput caírem para 50MB/s durante uma restauração massiva porque as cabeças de leitura dos discos não conseguem acompanhar as solicitações de busca de metadados.
Tabela Comparativa: Storage de Backup Padrão vs. Otimizado para Restauração
| Característica | Repositório Padrão (Foco em Custo) | Repositório de Alta Performance (Foco em RTO) |
|---|---|---|
| Mídia Principal | HDD NL-SAS (7.2k RPM) | HDD + Tiering Agressivo ou All-Flash |
| Tratamento de Metadados | No mesmo pool dos dados (lento) | Em SSD/NVMe dedicado (rápido) |
| Gargalo em Restore | IOPS de leitura aleatória (Seek time) | Largura de banda da rede (Network Throughput) |
| Comportamento sob Stress | Latência dispara, restore falha por timeout | Mantém fluxo constante de dados |
| Custo por TB | Baixo ($) | Médio/Alto ($$$) |
Arquitetura de validação contínua (IRE)
Para combater a injeção de payloads e a corrupção silenciosa, a indústria de storage está migrando para o conceito de IRE (Isolated Recovery Environment) ou "Cleanroom".
Não basta ter o backup imutável; você precisa provar que ele é viável. Uma arquitetura IRE automatiza o seguinte fluxo:
O backup é replicado para uma zona isolada (air-gapped), onde a rede é fechada por padrão.
O sistema de armazenamento monta o backup instantaneamente (usando snapshots ou clones de storage, sem mover dados).
Um script automatizado sobe as VMs críticas em uma sandbox isolada.
Ferramentas de segurança (antivírus, YARA rules) escaneiam o sistema de arquivos da VM em busca de IOCs (Indicadores de Comprometimento) e ransomwares latentes.
Se limpo, o ponto de restauração é marcado como "Verificado". Se infectado, é colocado em quarentena forense.
Isso muda o jogo. Em vez de descobrir que o backup está infectado às 3 da manhã durante a crise, o sistema avisa proativamente: "O ponto de restauração de terça-feira contém o binário do LockBit. Use o de segunda-feira".
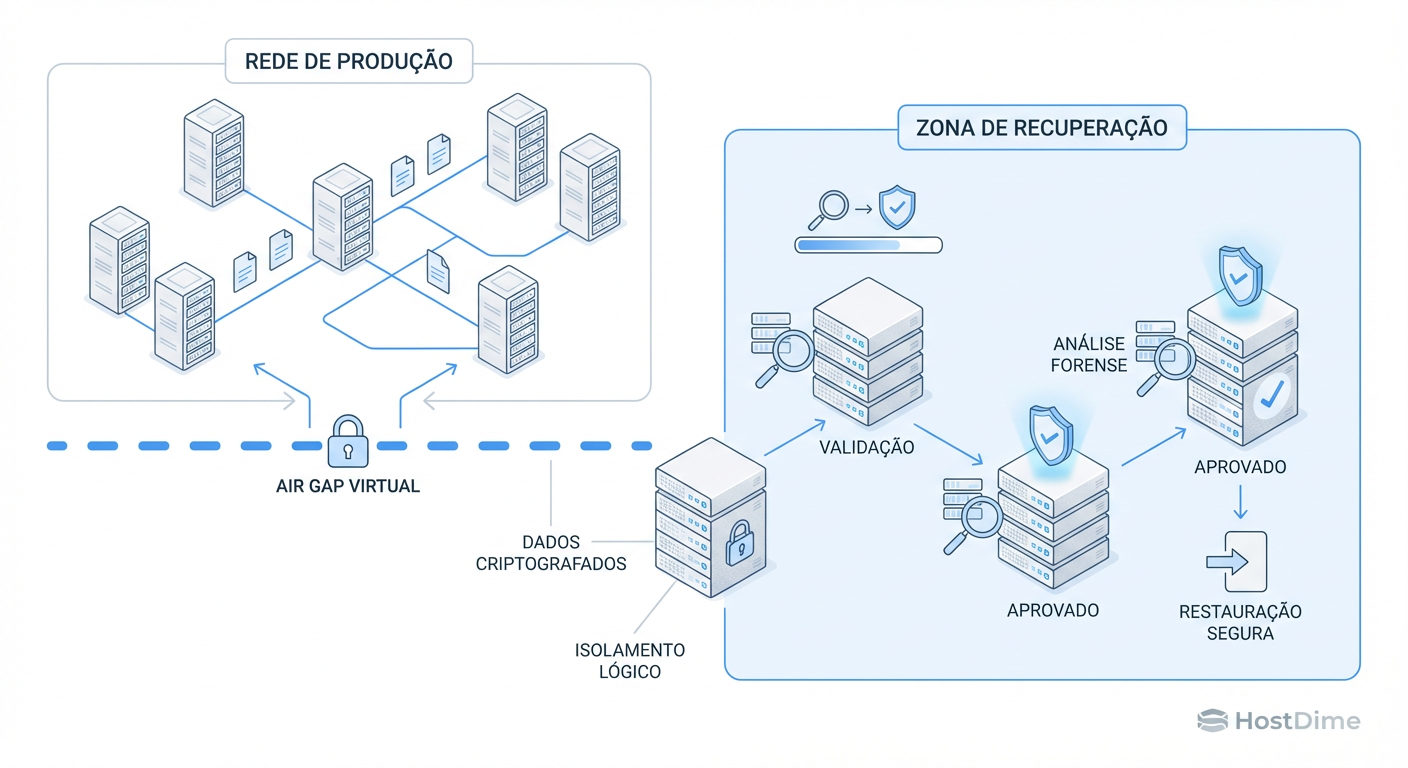 Figura: Arquitetura de IRE: Validando a integridade dos dados em uma sandbox isolada antes da restauração.
Figura: Arquitetura de IRE: Validando a integridade dos dados em uma sandbox isolada antes da restauração.
Protocolo de importação forçada em desastres
Em um cenário de "terra arrasada" onde o servidor de backup principal foi destruído, a capacidade de realizar uma importação forçada de objetos é vital.
Sistemas de storage modernos baseados em objetos ou repositórios Linux endurecidos (Hardened Repository) devem permitir que uma nova instância do software de backup, instalada do zero, leia os dados brutos e reconstrua o catálogo.
Testar esse procedimento é obrigatório. Muitos administradores descobrem, tarde demais, que suas chaves de criptografia do backup estavam armazenadas apenas no servidor que foi criptografado. Sem as chaves, a importação forçada é matematicamente impossível. A gestão de chaves (KMS) deve ser externa ao domínio de falha do backup.
O futuro é a resiliência, não apenas a retenção
A era de tratar o backup como um "arquivo morto" acabou. O armazenamento de backup é agora a última linha de defesa ativa e deve ter performance e inteligência de segurança comparáveis ao armazenamento primário.
Prevemos que, nos próximos anos, a integração entre storage arrays e ferramentas de XDR (Extended Detection and Response) será nativa. O storage informará ao firewall sobre padrões de escrita anômalos (como criptografia em massa) e bloqueará o I/O na fonte, antes mesmo que o backup seja necessário.
Até lá, pare de confiar cegamente na palavra "imutável". Valide seus dados, teste a velocidade de seus discos mecânicos sob carga de leitura aleatória e, acima de tudo, proteja suas credenciais de gerenciamento de storage como se fossem as chaves do reino. Porque elas são.
Referências & Leitura Complementar
NIST SP 800-209: Security Guidelines for Storage Infrastructure (2016/Updated). Foca na proteção de dados em repouso e planos de recuperação.
SNIA (Storage Networking Industry Association): "Protecting Data from Ransomware" - Definições de padrões de isolamento e imutabilidade.
ISO/IEC 27040: Storage security - Padrões internacionais para segurança de armazenamento.
Perguntas Frequentes (FAQ)
O backup imutável impede que o ransomware criptografe meus dados?
Não. A imutabilidade (WORM) impede que o arquivo de backup já gravado seja deletado ou alterado. Se o ransomware criptografar os dados de produção antes da janela de backup, você gravará dados ilegíveis de forma imutável (Garbage In, Garbage Out).Por que a restauração de Object Storage imutável é lenta?
A restauração de repositórios baseados em objetos (S3) com deduplicação exige um processo intensivo de 'reidratação' dos dados. Durante um restore massivo, isso gera uma tempestade de IOPS e latência de metadados que pode saturar o throughput do storage, tornando a recuperação inviável.
Roberto Xavier
Comandante de Incidentes
"Lidero equipes em momentos críticos de infraestrutura. Priorizo a restauração rápida de serviços e promovo uma cultura de post-mortem sem culpa para construir sistemas mais resilientes."