Bypass de kernel no KubeVirt: como o SPDK elimina o overhead de CPU em clusters NVMe/TCP

Descubra como a arquitetura de kernel bypass com SPDK no KubeVirt reduz a latência e o consumo de CPU em infraestruturas de storage NVMe/TCP, otimizando o TCO do seu datacenter.
A transição de máquinas virtuais legadas para plataformas nativas de nuvem trouxe um desafio arquitetural severo para a camada de armazenamento. Quando executamos instâncias através do KubeVirt, a promessa é unificar o gerenciamento de contêineres e máquinas virtuais sob a mesma API do Kubernetes. No entanto, a física do processamento de dados não perdoa abstrações mal otimizadas. O uso de protocolos modernos como o NVMe/TCP para conectar essas máquinas virtuais a volumes remotos expôs uma falha fundamental na forma como os sistemas operacionais lidam com o tráfego de rede e armazenamento simultaneamente.
Resumo em 30 segundos
- O tráfego NVMe/TCP em ambientes KubeVirt gera um alto volume de interrupções no kernel Linux, consumindo ciclos de CPU que deveriam ser destinados às aplicações.
- A adoção do SPDK (Storage Performance Development Kit) permite o bypass do kernel, movendo o processamento de I/O para o user space através de um modelo de polling contínuo.
- Essa mudança arquitetural reduz drasticamente a latência de cauda (p99) e melhora o TCO do cluster, liberando núcleos de processamento caros para cargas de trabalho reais.
A latência invisível que consome os ciclos de CPU dos worker nodes
Em arquiteturas de data center modernas, o protocolo NVMe (Non-Volatile Memory Express) tornou-se o padrão de fato para comunicação com mídias flash. Para estender essa performance através da rede, a indústria adotou o NVMe-oF (NVMe over Fabrics), sendo a variante TCP a mais popular devido à sua compatibilidade com infraestruturas de rede Ethernet já existentes. O problema surge quando combinamos a alta taxa de pacotes do NVMe/TCP com a virtualização aninhada do KubeVirt.
Cada operação de leitura ou escrita gerada por uma máquina virtual precisa atravessar o driver Virtio, chegar ao processo QEMU no host e, em seguida, descer por toda a pilha de rede e armazenamento do kernel Linux. Esse trajeto é pavimentado por interrupções de hardware (IRQs) e mudanças de contexto (context switches).
⚠️ Perigo: Em clusters de alta densidade, o volume de interrupções gerado pelo tráfego NVMe/TCP pode causar o fenômeno de "interrupt storm". Isso força a CPU a pausar constantemente a execução das máquinas virtuais para atender às requisições de rede, degradando a performance de todo o nó.
A latência introduzida não é apenas um problema de tempo de resposta para o banco de dados rodando dentro da VM. É um problema de eficiência computacional. Estamos utilizando núcleos de processamento de alto custo, projetados para cálculos complexos, apenas para mover pacotes de dados entre buffers de memória.
O gargalo do kernel Linux no roteamento de pacotes NVMe/TCP
Para entender a necessidade de uma solução radical, precisamos olhar para a anatomia do kernel Linux. Ele foi desenhado para ser um sistema de propósito geral, focado em justiça (fairness) e segurança no compartilhamento de recursos. Quando um pacote NVMe/TCP chega à placa de rede (NIC), a placa envia uma interrupção para a CPU. O kernel suspende o que está fazendo, copia os dados do buffer da placa para a memória do sistema (sk_buff), processa os cabeçalhos TCP/IP e, finalmente, entrega o payload para a camada de blocos.
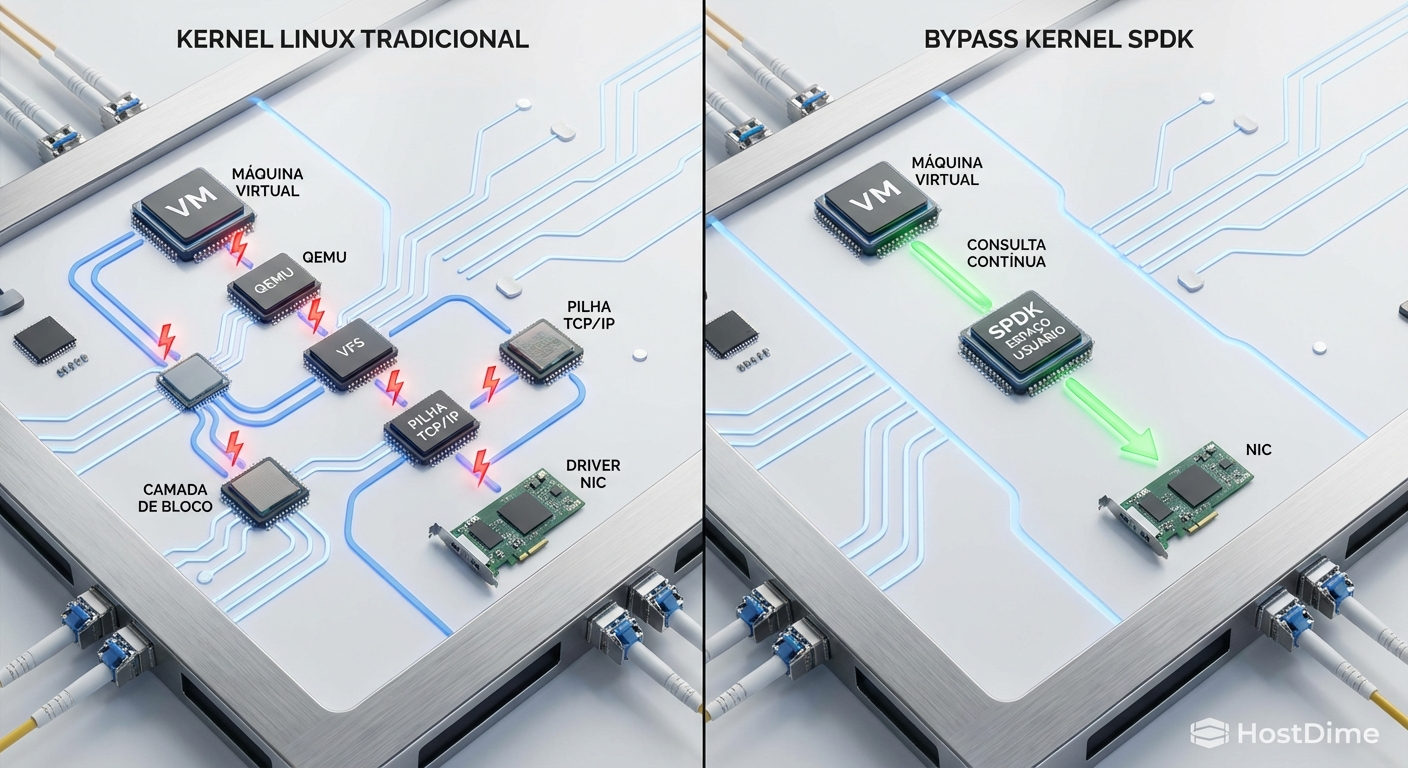 Figura: Diagrama arquitetural comparando a pilha de I/O tradicional do kernel Linux com o modelo de bypass do SPDK.
Figura: Diagrama arquitetural comparando a pilha de I/O tradicional do kernel Linux com o modelo de bypass do SPDK.
Esse processo envolve múltiplas cópias de dados e transições entre o modo usuário (user space) e o modo núcleo (kernel space). Em discos rígidos mecânicos (HDDs) ou até mesmo em SSDs SATA antigos, esse overhead era mascarado pela lentidão da própria mídia física. Hoje, com drives NVMe capazes de entregar milhões de IOPS (operações de entrada e saída por segundo) com latências na casa dos microssegundos, o software tornou-se o gargalo absoluto.
A ilusão de escalar verticalmente com mais núcleos de processamento
Diante de gargalos de performance, a resposta instintiva de muitas equipes de engenharia é adicionar mais hardware. Se o processamento de I/O está consumindo 30% da CPU do worker node, a solução aparente seria migrar para processadores com mais núcleos. Como arquitetos, sabemos que essa abordagem falha miseravelmente na análise de TCO (Custo Total de Propriedade).
Depende do seu modelo de licenciamento, mas softwares corporativos e hypervisors frequentemente cobram por núcleo de CPU. Gastar núcleos caros para gerenciar interrupções de rede é um desperdício financeiro. Além disso, a lei de Amdahl nos lembra que a escalabilidade de um sistema é limitada pela sua porção serial. Adicionar mais núcleos não resolve a contenção nos locks do kernel Linux durante o processamento da pilha TCP.
A verdadeira engenharia de performance não busca processar interrupções mais rápido. Ela busca eliminar a necessidade de interrupções.
Implementando o SPDK para polling em user space no KubeVirt
É aqui que o SPDK (Storage Performance Development Kit) muda as regras do jogo. Mantido pela comunidade e originalmente criado pela Intel, o SPDK é um conjunto de bibliotecas projetado para escrever aplicações de armazenamento de alta performance no espaço do usuário (user space).
A premissa do SPDK é o "kernel bypass". Em vez de deixar o sistema operacional gerenciar a placa de rede e o armazenamento, o SPDK assume o controle direto do hardware através de drivers em user space (como o VFIO-PCI). A segunda mudança fundamental é a substituição das interrupções pelo modelo de "polling" (sondagem contínua).
💡 Dica Pro: No modelo de polling, um núcleo de CPU é dedicado exclusivamente a verificar as filas de hardware em um loop infinito, buscando novos pacotes. Embora esse núcleo opere a 100% de utilização, ele processa milhões de pacotes sem uma única mudança de contexto, liberando todos os outros núcleos do nó para as máquinas virtuais.
No contexto do KubeVirt, a integração geralmente ocorre através do protocolo vhost-user. O processo QEMU que encapsula a máquina virtual se comunica diretamente com um contêiner rodando o SPDK no mesmo nó, utilizando memória compartilhada (HugePages). O SPDK, por sua vez, gerencia a conexão NVMe/TCP com o storage array remoto.
Comparativo arquitetural: I/O tradicional vs SPDK no KubeVirt
| Característica | Pilha Tradicional (Kernel Linux) | Kernel Bypass (SPDK) |
|---|---|---|
| Modelo de Execução | Baseado em Interrupções (IRQs) | Polling contínuo (Loop) |
| Context Switches | Altos (Kernel <-> User space) | Zero (Apenas User space) |
| Consumo de CPU | Distribuído, mas imprevisível | 1 núcleo dedicado a 100% |
| Latência de Cauda (p99) | Alta e variável sob carga | Baixa e determinística |
| Complexidade de Setup | Baixa (Nativa do SO) | Alta (Requer HugePages e VFIO) |
 Figura: Arquitetura de um worker node KubeVirt utilizando vhost-user e memória compartilhada para comunicação direta com o contêiner SPDK.
Figura: Arquitetura de um worker node KubeVirt utilizando vhost-user e memória compartilhada para comunicação direta com o contêiner SPDK.
Métricas de validação e o impacto real no TCO do cluster
A adoção do SPDK não é um exercício acadêmico. Ela deve ser justificada por métricas de negócios e eficiência de infraestrutura. Ao implementar essa arquitetura em clusters de produção que dependem de NVMe/TCP, observamos uma mudança drástica no comportamento dos worker nodes.
A métrica mais importante a ser monitorada é a eficiência de IOPS por núcleo de CPU. Em uma configuração padrão do kernel, atingir 500.000 IOPS de leitura aleatória 4K via NVMe/TCP pode consumir o equivalente a 4 ou 5 núcleos de CPU espalhados pelo sistema, gerando picos de latência devido ao agendamento de tarefas. Com o SPDK, o mesmo volume de IOPS pode ser processado por um único núcleo dedicado, mantendo a latência de cauda (p99) estritamente determinística e abaixo de 100 microssegundos.
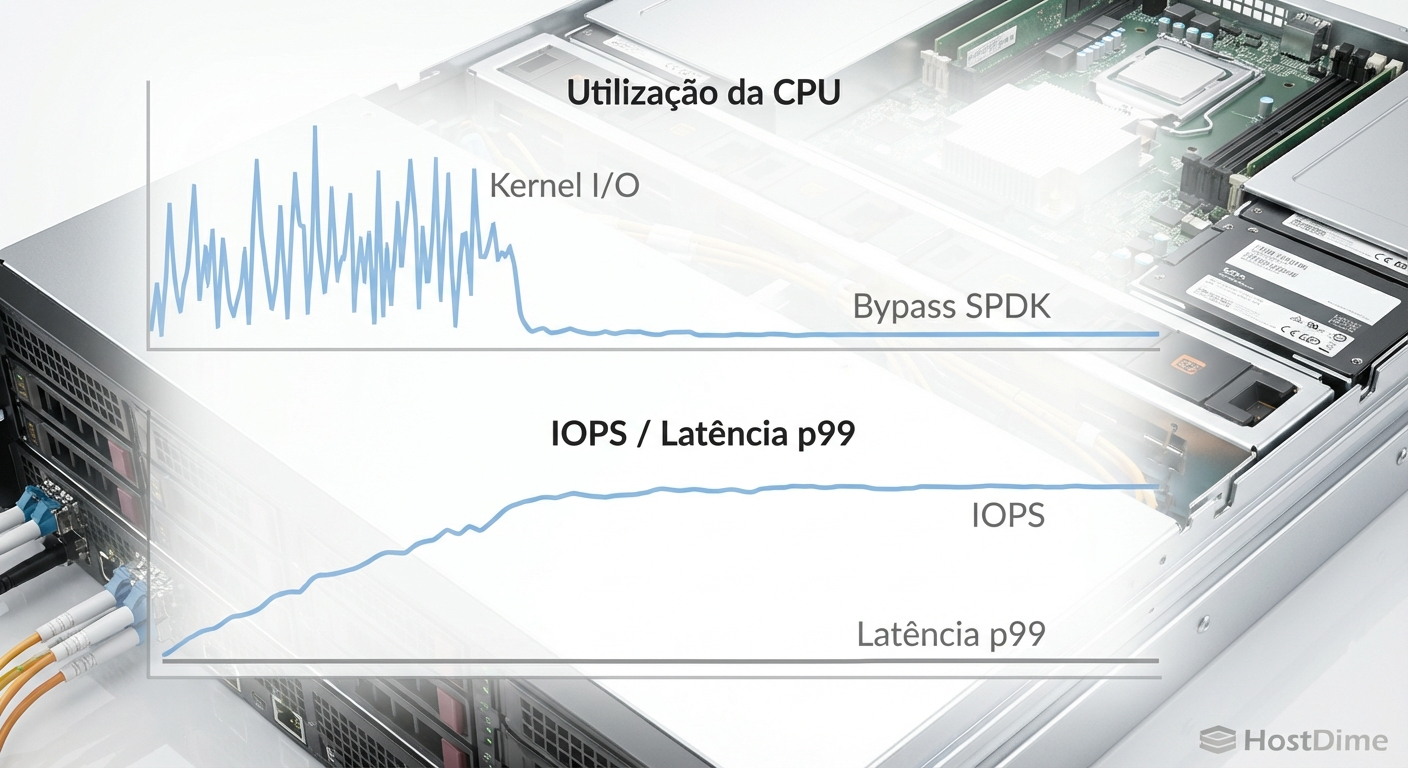 Figura: Dashboard ilustrando a queda no consumo global de CPU e a estabilização da latência de cauda após a ativação do SPDK.
Figura: Dashboard ilustrando a queda no consumo global de CPU e a estabilização da latência de cauda após a ativação do SPDK.
O impacto no TCO é direto. Se você possui um cluster de 50 nós e consegue recuperar 4 núcleos por nó que antes eram desperdiçados com overhead de I/O, você efetivamente ganha 200 núcleos de processamento livres. Isso permite aumentar a densidade de máquinas virtuais por nó no KubeVirt, adiando a compra de novos servidores físicos e reduzindo custos com energia e licenciamento.
O veredito arquitetural
A decisão de implementar o bypass de kernel com SPDK em ambientes KubeVirt depende fundamentalmente da densidade de I/O da sua carga de trabalho. Para clusters que hospedam aplicações web leves ou serviços stateless, a complexidade operacional de gerenciar HugePages, isolamento de CPU (core pinning) e drivers VFIO não se justifica. A pilha padrão do Linux será suficiente.
No entanto, minha recomendação é clara para arquiteturas que hospedam bancos de dados transacionais pesados, sistemas de mensageria de alta vazão ou cargas de trabalho de IA/ML consumindo dados via NVMe/TCP. Nesses cenários, o sistema operacional tradicional tornou-se um obstáculo físico.
A previsão para os próximos anos é que essa necessidade de descarregamento de CPU impulsione ainda mais a adoção de DPUs (Data Processing Units) e IPUs (Infrastructure Processing Units), além de novos padrões de interconexão como o CXL (Compute Express Link). Até que essas peças de hardware se tornem onipresentes e baratas, o SPDK continuará sendo a ferramenta de software mais poderosa no arsenal de um arquiteto de storage para extrair o valor real dos investimentos em NVMe.
Referências e leitura complementar
NVM Express Base Specification: Documentação oficial do PCI-SIG e consórcio NVMe sobre o protocolo NVMe over Fabrics (NVMe-oF) e a implementação TCP.
Storage Performance Development Kit (SPDK) Documentation: Guias de arquitetura sobre vhost-user, NVMe-oF target e polling mode drivers (spdk.io).
KubeVirt User Guide: Especificações sobre a alocação de HugePages, isolamento de CPU (CPU Manager) e integração de volumes de alta performance em máquinas virtuais nativas do Kubernetes.
O que é SPDK e como ele se diferencia do I/O tradicional?
O Storage Performance Development Kit (SPDK) é um conjunto de ferramentas que move o processamento de storage do kernel do sistema operacional para o user space. Em vez de depender de interrupções de hardware que causam context switches custosos, o SPDK utiliza um modelo de polling contínuo, lendo e gravando dados diretamente na fila do dispositivo NVMe.Por que o NVMe/TCP gera alto overhead de CPU em ambientes KubeVirt?
Em uma arquitetura padrão, o tráfego NVMe sobre TCP precisa atravessar múltiplas camadas do kernel Linux: a pilha de rede (TCP/IP) e a camada de blocos (block layer). Cada pacote recebido gera interrupções de hardware e software, forçando a CPU a pausar as tarefas das máquinas virtuais (KubeVirt) para processar o I/O, resultando em alta latência de cauda e desperdício de ciclos de processamento.O kernel bypass compromete a segurança ou o isolamento do cluster Kubernetes?
Depende da arquitetura de implantação. O uso de SPDK exige a alocação de HugePages e o uso de drivers como VFIO-PCI para mapear a memória do dispositivo diretamente para o pod. Embora isso exija privilégios elevados no nível do contêiner de storage, o isolamento da máquina virtual cliente permanece intacto se as políticas de RBAC e os Security Contexts do Kubernetes forem configurados com rigor.
Otávio Henriques
Arquiteto de Soluções Enterprise
"Com duas décadas desenhando infraestruturas críticas, olho além do hype. Foco em TCO, resiliência e trade-offs, pois na arquitetura corporativa a resposta correta quase sempre é 'depende'."