Ceph Crimson e SeaStore: dissecando a arquitetura thread-per-core para NVMe

Entenda como o projeto Crimson e o backend SeaStore eliminam o gargalo de CPU no Ceph, utilizando o framework Seastar para extrair o máximo de SSDs NVMe modernos.
Se você, assim como eu, montou um cluster Ceph recentemente cheio de NVMes de segunda mão do eBay ou AliExpress, provavelmente notou algo estranho. Você tem o hardware: barramento PCIe Gen4, rede de 100GbE, latência de disco na casa dos microssegundos. Mas quando você roda aquele benchmark de IOPS aleatórios 4K, o resultado não escala como deveria. O culpado? A própria arquitetura de software que amamos. O Ceph clássico (baseado no ceph-osd tradicional) foi desenhado numa época em que discos giratórios eram reis e a CPU passava a maior parte do tempo esperando o braço do HD se mover.
Hoje, o jogo virou. O NVMe é tão rápido que agora é ele quem espera pela CPU. É aqui que entram o Crimson e o SeaStore, a tentativa ambiciosa da comunidade Ceph de reescrever o núcleo do armazenamento para a era do flash nativo, eliminando gargalos que nem sabíamos que existiam até saturarmos nossos links PCI Express.
Resumo em 30 segundos
- O Problema: A arquitetura atual do Ceph (BlueStore) sofre com trocas de contexto de CPU e bloqueios (locks) excessivos, impedindo que SSDs NVMe atinjam sua velocidade máxima.
- A Solução (Crimson): Um novo daemon OSD reescrito do zero usando o framework Seastar, adotando um modelo "thread-per-core" onde nada é compartilhado e não existem locks globais.
- O Motor (SeaStore): Um backend de armazenamento projetado especificamente para NVMe e tecnologias como ZNS, eliminando a camada intermediária do RocksDB usada no BlueStore.
 Figura: Comparação visual: O congestionamento causado por locks no modelo clássico versus as vias expressas paralelas da arquitetura Crimson.
Figura: Comparação visual: O congestionamento causado por locks no modelo clássico versus as vias expressas paralelas da arquitetura Crimson.
O gargalo invisível: Quando a CPU se torna o vilão
Para entender por que precisamos do Crimson, precisamos olhar para o que acontece dentro de um servidor quando uma gravação chega. No modelo atual (BlueStore), o Ceph utiliza uma abordagem multithreaded clássica. Temos threads para mensageria, threads para processamento de disco, threads para monitoramento.
O problema é que o kernel do Linux precisa agendar essas threads nos núcleos da CPU. Cada vez que uma thread para de rodar para dar lugar a outra, ocorre uma troca de contexto (context switch). Isso custa tempo. Em discos mecânicos (HDD), perder alguns microssegundos na CPU é irrelevante porque o disco vai demorar milissegundos para responder. A CPU é ordens de magnitude mais rápida que o HDD.
Com NVMe, a latência do dispositivo caiu para a casa dos 10 a 20 microssegundos. De repente, o custo da troca de contexto e, pior ainda, o custo de esperar por um "lock" (quando uma thread bloqueia um recurso para que outra não o acesse simultaneamente) torna-se maior que o tempo de acesso ao disco.
💡 Dica Pro: Se você monitorar seu cluster com
htope vir o uso de CPU disparar ("System" time alto) mas o throughput do disco estar baixo, você está sofrendo de contenção de locks ou overhead de interrupções. Adicionar mais vCPUs nesse cenário muitas vezes piora a performance, pois aumenta a disputa pelos mesmos recursos.
Crimson: A arquitetura Shared-Nothing
O Projeto Crimson não é apenas uma otimização; é uma reescrita do daemon ceph-osd. A base dessa revolução é o framework Seastar.
O Seastar introduz um modelo de programação assíncrona baseado em eventos e na filosofia shared-nothing (nada compartilhado). Em vez de ter centenas de threads disputando todos os núcleos, o Crimson aloca uma única thread por núcleo de CPU.
Como funciona o Thread-per-Core?
Imagine que você tem um processador de 8 núcleos. O Crimson vai subir 8 threads, e cada uma será "pinada" (fixada) em um núcleo específico.
Memória Particionada: Cada núcleo recebe sua própria fatia de memória RAM. O Núcleo 1 não acessa a memória do Núcleo 2.
Sem Locks: Como o Núcleo 1 é o único dono dos seus dados, ele não precisa usar
mutexoulockspara proteger a memória. Ele apenas processa.Mensageria Explícita: Se o Núcleo 1 precisa de algo que está no Núcleo 2, ele envia uma mensagem explícita. Não há leitura de memória cruzada.
Isso elimina quase totalmente a latência de cauda causada por bloqueios. O processador trabalha de forma linear, processando pacotes de I/O o mais rápido possível, sem parar para perguntar "posso usar essa variável agora?".
 Figura: Arquitetura Seastar: Núcleos de CPU como ilhas isoladas com memória própria, comunicando-se apenas por mensagens, eliminando a necessidade de memória compartilhada.
Figura: Arquitetura Seastar: Núcleos de CPU como ilhas isoladas com memória própria, comunicando-se apenas por mensagens, eliminando a necessidade de memória compartilhada.
SeaStore: O adeus ao RocksDB
Enquanto o Crimson é a "estrada" (o daemon), o SeaStore é o "motor" (o backend de armazenamento de objetos).
Atualmente, o BlueStore é incrível, mas ele tem uma dependência pesada: o RocksDB. O BlueStore gerencia os dados brutos, mas usa o RocksDB para gerenciar os metadados (onde os dados estão). O problema é que o RocksDB foi feito para um propósito genérico (LSM-tree) e sofre de amplificação de escrita. Para escrever um dado pequeno, o RocksDB pode precisar reescrever vários blocos no disco durante seus processos de compactação.
Em SSDs SATA, isso era aceitável. Em NVMes de alta performance, o RocksDB se torna o gargalo de CPU e de desgaste do SSD.
O SeaStore foi desenhado para ser nativo para NVMe. Suas características principais incluem:
Design Assíncrono: Ele se integra perfeitamente ao modelo de eventos do Seastar/Crimson.
Sem RocksDB: Ele gerencia seus próprios metadados.
Otimização para ZNS (Zoned Namespaces): Esta é a fronteira da tecnologia de SSDs. O ZNS permite que o software (SeaStore) saiba exatamente a topologia física do flash, escrevendo sequencialmente em zonas e eliminando a necessidade do Garbage Collection interno do SSD. Isso reduz o custo do SSD e aumenta a vida útil.
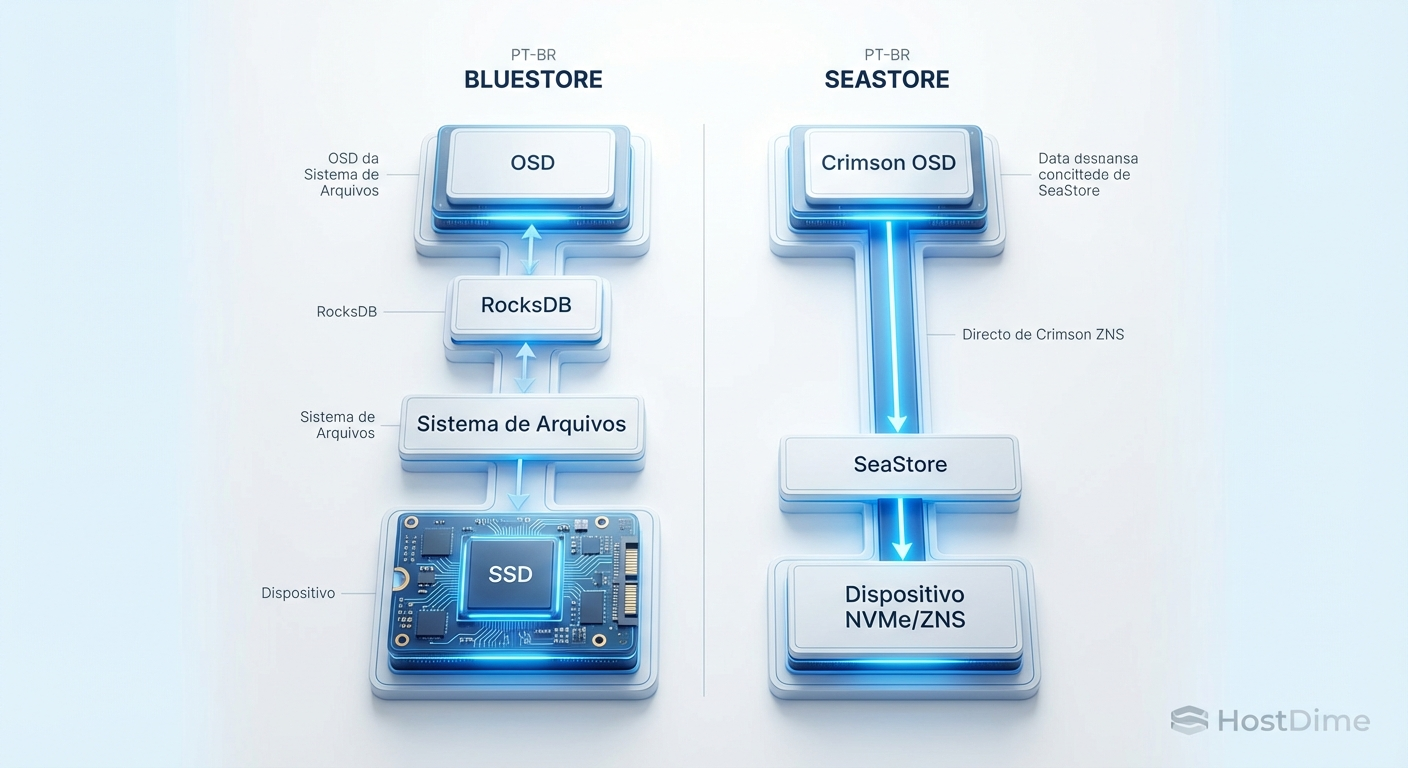 Figura: A pilha de I/O simplificada: SeaStore remove camadas intermediárias como o RocksDB, permitindo acesso direto e otimizado ao hardware NVMe.
Figura: A pilha de I/O simplificada: SeaStore remove camadas intermediárias como o RocksDB, permitindo acesso direto e otimizado ao hardware NVMe.
Comparativo: BlueStore vs. Crimson/SeaStore
Para quem gosta de números e arquitetura, a diferença é brutal na teoria e promissora nos benchmarks iniciais.
| Característica | Ceph Clássico (BlueStore) | Ceph Crimson (SeaStore) |
|---|---|---|
| Modelo de Threading | Pool de Threads (Muitas threads, trocas de contexto) | Thread-per-Core (Uma thread por núcleo, pinada) |
| Gerenciamento de CPU | Kernel Scheduler (Imprevisível) | User-space Scheduler (Determinístico) |
| Uso de Locks | Intenso (Mutexes globais e compartilhados) | Quase Zero (Shared-nothing design) |
| Metadados | RocksDB (Compactação pesada) | Nativo (B-tree otimizada para Flash) |
| Foco de Hardware | HDD e SSD SATA/SAS | NVMe, NVMe-oF, ZNS |
| Latência de Cauda | Alta sob carga (Jitter) | Baixa e previsível |
O estado da arte: Devo usar hoje?
Aqui precisamos ser realistas. A empolgação com o Crimson é enorme, mas ele ainda não está pronto para segurar os dados da sua empresa ou as fotos insubstituíveis da família.
O Crimson está em Tech Preview nas versões mais recentes do Ceph (Reef, Squid). Muitas funcionalidades críticas do BlueStore ainda não foram portadas ou estabilizadas no Crimson, como:
Erasure Coding (EC) complexo.
Snapshots robustos.
Scrubbing profundo e recuperação de desastres testada em batalha.
⚠️ Perigo: Não habilite o backend Crimson em um cluster de produção. A chance de perda de dados ou corrupção silenciosa ainda existe, pois o código é jovem comparado à década de maturação do BlueStore. Use apenas em ambientes de laboratório para testes de performance.
No entanto, para cargas de trabalho puramente aleatórias de leitura (Random Read), benchmarks preliminares mostram que o Crimson consegue entregar muito mais IOPS por núcleo de CPU do que o BlueStore, validando a tese da arquitetura.
 Figura: O sonho do homelabber: Alta performance de IOPS com carga de CPU estável, a promessa do Crimson.
Figura: O sonho do homelabber: Alta performance de IOPS com carga de CPU estável, a promessa do Crimson.
O horizonte do armazenamento
A transição para o Crimson e SeaStore não é uma questão de "se", mas de "quando". À medida que interfaces como CXL (Compute Express Link) e PCIe Gen5/Gen6 se tornam comuns, o software legado se torna uma âncora insustentável.
Para nós, operadores de infraestrutura open source, o Crimson representa a garantia de que o Ceph continuará sendo a escolha de facto para armazenamento definido por software na próxima década. Ele nos permitirá extrair cada gota de performance daquele NVMe caro que compramos, sem desperdiçar ciclos de CPU gerenciando filas de espera.
Prepare seu laboratório. O futuro é assíncrono, sem locks e incrivelmente rápido.
Referências & Leitura Complementar
Ceph Crimson Documentation: Documentação oficial do projeto Crimson dentro da árvore do Ceph.
Seastar.io Framework: Seastar: High-performance server-side application framework. Detalhes sobre a arquitetura de futures/promises e shared-nothing.
SNIA Zoned Storage: Especificações técnicas sobre ZNS (Zoned Namespaces) e como isso altera a escrita em Flash.
Netdev 0x14: The Path to 100Gbps and Beyond. Discussões sobre como o kernel bypass e arquiteturas user-space são essenciais para redes rápidas.
Perguntas Frequentes (FAQ)
O Ceph Crimson já está pronto para produção?
Ainda não. O Crimson é considerado experimental e está em desenvolvimento ativo (Tech Preview). Embora promissor para o futuro, o BlueStore continua sendo o padrão estável e recomendado para clusters de produção atuais que necessitam de confiabilidade garantida.Qual a principal diferença entre BlueStore e SeaStore?
O BlueStore foi projetado numa era de transição, atendendo bem HDDs e SSDs SATA, mas dependendo do RocksDB para metadados, o que gera overhead. O SeaStore é desenhado do zero para a era NVMe e ZNS, eliminando a camada do RocksDB e usando uma arquitetura assíncrona nativa para reduzir drasticamente a latência e a amplificação de escrita.O que é a arquitetura thread-per-core?
É um modelo de processamento onde cada núcleo da CPU gerencia seus próprios recursos (memória, filas) de forma isolada, sem precisar bloquear (lock) outros núcleos para acessar dados. Isso elimina a sobrecarga de sincronização e trocas de contexto, essencial para acompanhar a velocidade extrema dos dispositivos NVMe modernos.
Marcos Lopes
Operador Open Source (Self-Hosted)
"Troco licenças proprietárias por soluções open source robustas, ciente de que a economia financeira custa suor na manutenção. Defensor da soberania de dados e da força da comunidade."