Ceph e Hiperconvergência: Arquitetura, Riscos e a Armadilha da "Espiral da Morte"
Vai além do hype do Proxmox/OpenStack. Entenda a disputa de recursos entre VMs e OSDs, o perigo do rebalanceamento e como evitar o colapso do cluster em cenários de Hiperconvergência (HCI).
A promessa da Hiperconvergência (HCI) é sedutora: colapsar silos de armazenamento e computação em hardware commodity, gerenciados por software inteligente. No papel, o Ceph rodando ao lado do KVM (via Proxmox ou OpenStack) parece a arquitetura definitiva para reduzir o TCO (Total Cost of Ownership). "Por que desperdiçar ciclos de CPU em um storage array dedicado se meus servidores de virtualização têm núcleos ociosos?"
No entanto, a realidade operacional é implacável. Tratar o armazenamento definido por software como um passageiro passivo no seu cluster de computação é o erro número um em arquiteturas enterprise. O Ceph não é apenas um disco virtual; é um sistema distribuído complexo, faminto por recursos e, em momentos de crise, agressivo.
O que é Ceph em Hiperconvergência (HCI)?
HCI com Ceph é uma arquitetura onde os processos de armazenamento (OSDs/MONs) e as cargas de trabalho (Máquinas Virtuais/Containers) compartilham o mesmo hardware físico (CPU, RAM e Rede). Embora reduza o CAPEX inicial e a pegada no datacenter, essa abordagem introduz o risco crítico de contenção de recursos, onde a recuperação de dados do storage pode degradar ou paralisar as aplicações de negócio.
A Ilusão da Economia no HCI com Ceph
Muitos arquitetos calculam o TCO baseando-se apenas na aquisição de hardware (CAPEX). Eles veem um servidor com 64 núcleos e 512GB de RAM e pensam: "Posso dedicar 8 núcleos para o Ceph e o resto para VMs".
O problema é que o CAPEX mente, e o OPEX morde. A economia inicial de não comprar switches dedicados ou nós de storage separados é frequentemente devolvida com juros durante o ciclo de vida da operação.
Existem dois trade-offs invisíveis aqui:
Recursos Encalhados (Stranded Resources): Se suas VMs são intensivas em RAM, mas leves em disco, você pode esgotar a memória do nó enquanto a CPU e o disco sobram. No HCI, você não pode escalar armazenamento e computação independentemente. Para ter mais RAM, você compra um servidor inteiro, pagando por discos e CPU que não precisa.
O Custo da Complexidade de Upgrade: Atualizar o kernel do Linux ou a versão do Ceph em um ambiente HCI é uma cirurgia de coração aberto. Reiniciar um nó afeta tanto a capacidade de computação quanto a redundância dos dados simultaneamente.
Entendendo o Processo OSD no Ceph: Não é Apenas um Disco
Para operar Ceph corretamente, você precisa mudar a forma como visualiza um "disco". Em um storage tradicional, o disco é passivo. No Ceph, cada disco físico é gerenciado por um daemon chamado OSD (Object Storage Daemon).
Um OSD não é um driver simples. É um programa C++ complexo que executa:
Cálculos de Checksum (CRC32) para integridade.
Replicação de dados pela rede.
Gerenciamento de metadados no RocksDB/BlueStore.
Heartbeats constantes com outros OSDs.
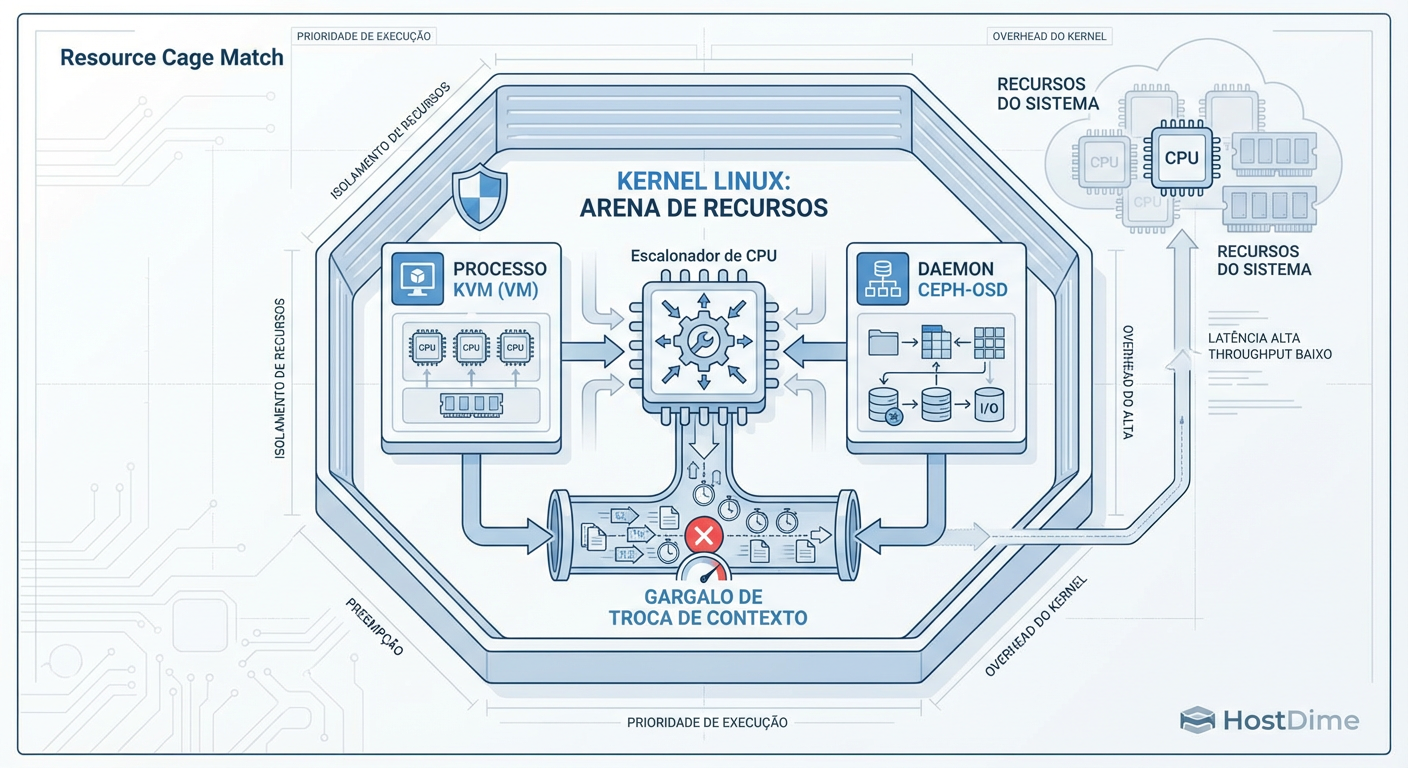 Figura: Diagrama de Contenção: No modelo HCI, seus dados (OSD) e suas aplicações (VM) lutam pelos mesmos ciclos de CPU e barramentos de memória.
Figura: Diagrama de Contenção: No modelo HCI, seus dados (OSD) e suas aplicações (VM) lutam pelos mesmos ciclos de CPU e barramentos de memória.
Quando sua VM grava um bloco de 4KB, ela não está apenas enviando elétrons para um prato magnético ou célula NAND. Ela está pedindo para a CPU do host processar essa gravação, replicá-la para outros hosts e confirmar o recebimento.
Em um cenário de HCI, o processo ceph-osd está lutando milissegundo a milissegundo pelo agendador da CPU contra o processo qemu-kvm (sua VM). Em dias calmos, o Linux gerencia isso bem. Em dias de crise, é uma briga de rua.
Anatomia da "Espiral da Morte" na Recuperação de Falhas
O maior risco do HCI não ocorre durante a operação normal, mas durante a falha. É aqui que o conceito de "Espiral da Morte" se materializa.
Imagine um cluster de 3 nós, cada um com 50% de utilização de CPU (25% VMs, 25% Ceph).
O Nó A falha.
O cluster perde 33% da capacidade de computação e armazenamento instantaneamente.
As VMs do Nó A reiniciam nos Nós B e C (HA), elevando a carga de CPU das VMs nesses nós.
Simultaneamente, o Ceph detecta a falha e inicia o Backfill/Recovery para restaurar a redundância dos dados perdidos.
O Ceph é desenhado para priorizar a consistência e a durabilidade dos dados. Ele vai tentar ler e gravar dados freneticamente nos discos restantes para criar novas cópias. Isso consome ciclos massivos de CPU e largura de banda de memória.
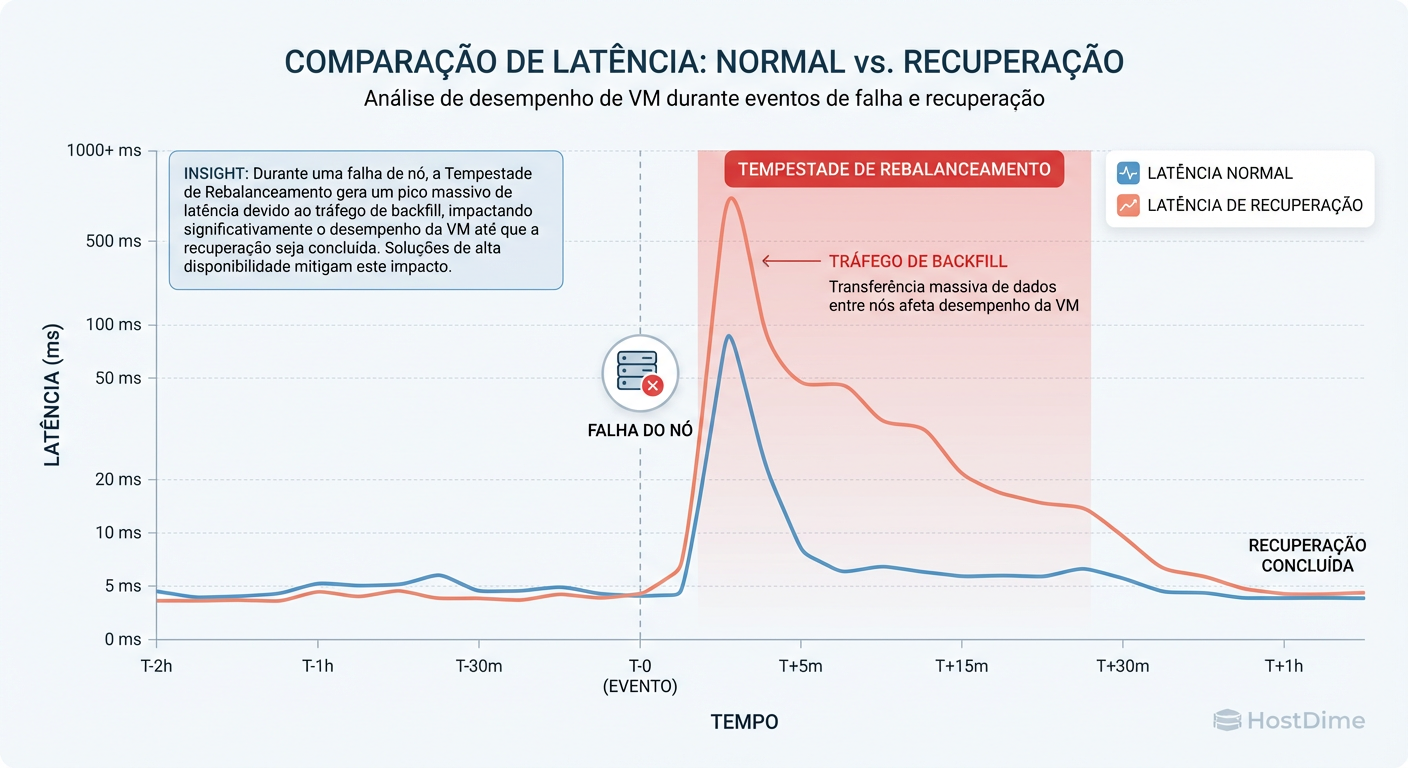 Figura: O Custo da Cura: O impacto na latência de escrita das VMs quando o Ceph inicia o processo de backfill para recuperar a redundância.
Figura: O Custo da Cura: O impacto na latência de escrita das VMs quando o Ceph inicia o processo de backfill para recuperar a redundância.
O Resultado: Os nós B e C, que agora hospedam mais VMs, também estão sob carga máxima de I/O do Ceph. A latência de disco dispara. As aplicações nas VMs começam a dar timeout. O load average sobe tanto que os heartbeats do Ceph podem falhar, fazendo o cluster marcar (falsamente) mais OSDs como "down", gerando mais tráfego de recuperação. O cluster colapsa sob o próprio peso.
Gargalos de Rede no Ceph HCI e a Necessidade da Cluster Network
Um erro comum em implementações HCI "budget" é usar a mesma interface física (mesmo com VLANs diferentes) para o tráfego de VMs (Public/Front) e o tráfego de replicação do Ceph (Cluster/Back).
O Ceph gera uma quantidade brutal de tráfego leste-oeste. Se você tem um fator de replicação de 3 (3x), cada 1GB escrito pela VM gera, no mínimo, 2GB de tráfego adicional de replicação entre os nós, mais o tráfego de acknowledgement.
Se a replicação compartilha o link com a aplicação:
Um rebalance satura o link de 10Gbps/25Gbps.
A latência de rede da VM aumenta.
Conexões de banco de dados caem.
O cluster de computação (ex: Kubernetes ou Proxmox HA) pode perder o quorum se a latência for alta demais, causando fencing de nós saudáveis.
Regra de Ouro: A cluster_network do Ceph deve ser física e isolada, ou pelo menos ter garantia de QoS rigorosa em switches de alta capacidade.
Tunando osd_memory_target e Priorização de Processos
Se você precisa usar HCI (por restrições de espaço ou orçamento), você deve aplicar uma estratégia de "Defesa em Profundidade" para proteger suas VMs da voracidade do Ceph. O padrão do Ceph é tentar usar a memória disponível para cache (BlueStore cache) para acelerar leituras. Em HCI, isso é perigoso.
1. Limite a Memória do OSD
Não deixe o Ceph decidir quanto de RAM ele quer. Defina um limite rígido. O parâmetro osd_memory_target é seu melhor amigo.
# Exemplo: Definindo alvo de 4GB por OSD (ajuste conforme sua RAM total e qtde de discos)
ceph config set osd osd_memory_target 4294967296
Nota: O Ceph pode ultrapassar ligeiramente esse alvo, então deixe uma margem de segurança.
2. Prioridade de I/O e CPU (Nice/Ionice)
Em sistemas críticos, você pode precisar ajustar a prioridade dos processos. No entanto, cuidado: se você priorizar demais as VMs e sufocar os OSDs, as requisições de disco das VMs vão empilhar porque o storage não responde, causando high load do mesmo jeito.
A melhor abordagem no Ceph moderno é configurar as opções de QoS de recuperação do próprio Ceph para que o backfill seja menos agressivo durante o dia:
# Reduz a prioridade de recuperação para não matar a latência do cliente
ceph config set osd osd_op_queue_cut_off high
ceph config set osd osd_max_backfills 1
ceph config set osd osd_recovery_max_active 1
Alerta: Reduzir esses valores torna a recuperação mais lenta. Você fica em estado degradado (risco de perda de dados se outro disco falhar) por mais tempo. É um trade-off clássico: Performance vs. Risco.
Veredito Arquitetural: Quando Abandonar a Hiperconvergência
A decisão entre HCI e Storage Desagregado (nós de computação e nós de storage separados) não é sobre "moderno vs. antigo", é sobre escala e perfil de risco.
Tabela de Decisão: HCI vs. Desagregado
| Característica | Arquitetura HCI | Arquitetura Desagregada |
|---|---|---|
| Custo Inicial (CAPEX) | Baixo (Menos chassis, menos switches). | Médio/Alto (Hardware dedicado). |
| Escalabilidade | Linear Rígida (Compra CPU+RAM+Disk juntos). | Granular (Adiciona só disco ou só CPU). |
| Performance (Latência) | Variável (Sofre com "Noisy Neighbors"). | Consistente (Recursos dedicados). |
| Risco de "Espiral da Morte" | Alto (Contenção de recursos na falha). | Baixo (Falha de compute não afeta storage). |
| Complexidade de Upgrade | Alta (Reboot afeta compute e storage). | Baixa (Manutenção isolada). |
| Caso de Uso Ideal | Edge, ROBO, Clusters Pequenos (< 10 nós). | Cloud Privada, Bancos de Dados, Clusters Médios/Grandes. |
Veredito Técnico
O Ceph em modo hiperconvergente é uma ferramenta válida, mas exige um respeito profundo pelos limites do hardware. Não caia na armadilha de dimensionar o cluster para o "dia ensolarado". Dimensione para o dia em que um nó pega fogo, o Ceph entra em pânico para recuperar os dados, e seu chefe está perguntando por que o ERP está lento.
Se a sua aplicação exige latência garantida ou se o seu cluster vai crescer além de uma dúzia de nós, a desagregação é o caminho da sanidade. Separe o problema. Deixe o Ceph comer a CPU e RAM que ele precisa em paz, longe das suas aplicações.
Referências & Leitura Complementar
Ceph Documentation - Hardware Recommendations: Foco específico nas seções de CPU e Memória para BlueStore.
Red Hat Ceph Storage - Architecture Guide: Detalhes sobre a separação de Public Network e Cluster Network.
RocksDB Tuning Guide: Para entender o impacto da compactação de metadados na CPU.
"The Thundering Herd Problem": Conceitos gerais de sistemas distribuídos aplicáveis à recuperação de falhas em clusters saturados.

Roberto Almeida
Auditor de Compliance (LGPD/GDPR)
"Especialista em mitigação de riscos regulatórios e governança de dados. Meu foco é blindar infraestruturas corporativas contra sanções legais, garantindo a estrita conformidade com a LGPD e GDPR."