Ceph OSD: Container vs. Bare Metal — A Realidade da Performance em Produção

Esqueça o hype do Kubernetes. Analisamos a sobrecarga real de IOPS, latência de rede e a complexidade operacional entre rodar OSDs em containers versus bare metal.
Há uma guerra religiosa silenciosa nos corredores dos datacenters: de um lado, os puristas do Bare Metal, armados com Ansible e scripts bash, jurando que qualquer camada de abstração é um crime contra a latência. Do outro, os arquitetos de Kubernetes e entusiastas do Rook, prometendo que a orquestração resolve a dor operacional sem custo de performance.
A verdade? Ambos estão mentindo para você — ou, no mínimo, omitindo as letras miúdas.
Se você gerencia storage distribuído, sabe que "best practices" são apenas falhas que ainda não aconteceram no seu ambiente. Vamos cortar o marketing e olhar para o que acontece quando o bit toca o metal. Não estamos aqui para discutir conveniência, estamos aqui para discutir IOPS, latência de cauda (tail latency) e ciclos de CPU.
O que é a performance de Ceph em Container?
A execução de Ceph OSDs em containers não introduz sobrecarga significativa de I/O de disco, pois o engine BlueStore acessa dispositivos de bloco brutos diretamente, ignorando o sistema de arquivos do container. A perda de performance real ocorre frequentemente na camada de rede (overlays CNI) ou em configurações incorretas de cgroups, e não na containerização do processo em si.
A Ilusão da Sobrecarga: Onde a Performance do OSD Realmente se Perde
O argumento clássico contra containers é: "Eu não quero uma camada extra entre meu disco e meu software". Esse é um modelo mental herdado da virtualização pesada (VMs). Um container Docker ou Podman não é uma VM. Não há hypervisor traduzindo instruções.
Um container é apenas um processo isolado por Namespaces (o que ele vê) e limitado por Cgroups (o que ele usa). Quando você roda um binário ceph-osd em um container, ele está agendado pelo mesmo kernel do host que rodaria o binário "bare metal".
A instrução da CPU para calcular o checksum CRC32C ou o algoritmo de Erasure Coding é idêntica. A perda de ciclos de CPU por overhead do runtime do container é estatisticamente irrelevante (menos de 1-2%) em cargas modernas. Se o seu cluster está lento, pare de culpar o Docker e comece a olhar para o seu layout de NUMA ou para a saturação do barramento PCIe.
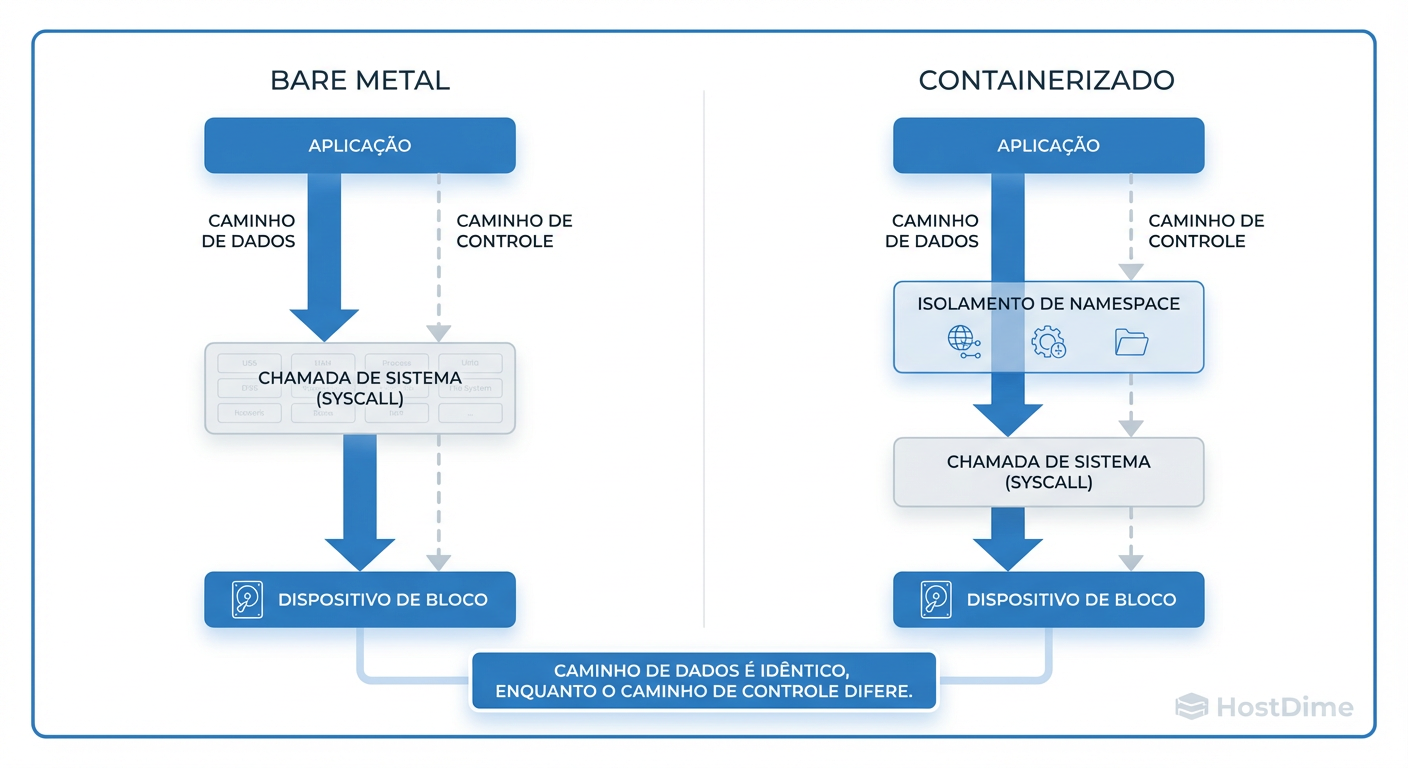 Figura: Pilha de I/O comparada: O mito da camada extra. Note que o caminho de dados (Data Path) para o dispositivo de bloco ignora o sistema de arquivos do container.
Figura: Pilha de I/O comparada: O mito da camada extra. Note que o caminho de dados (Data Path) para o dispositivo de bloco ignora o sistema de arquivos do container.
Como ilustrado acima, o caminho crítico de dados (Data Path) é o que importa. Se o container for configurado corretamente, o OSD não "vê" o sistema de arquivos do container para gravar dados; ele vê o dispositivo bruto.
Mapeamento de Dispositivos: OSD BlueStore Direto vs. Camadas de Abstração
Aqui é onde a maioria das implementações falha. O Ceph moderno usa BlueStore, que foi desenhado especificamente para consumir dispositivos de bloco brutos (/dev/nvme0n1), gerenciando seu próprio layout de disco e ignorando sistemas de arquivos POSIX como XFS ou ext4 (exceto por uma pequena partição de metadados RocksDB/WAL, se separada).
O Erro Fatal: FileStore em Container
Se você, por algum motivo insano, estiver usando o antigo FileStore dentro de um container, ou se mapear um arquivo de imagem dentro do container para simular um disco, você está introduzindo o OverlayFS no caminho de escrita.
Cenário Errado: OSD escreve em
/var/lib/ceph/osd/-> OverlayFS (Container) -> XFS (Host) -> Disco. Isso é suicídio de performance. O write amplification (amplificação de escrita) vai destruir seus SSDs e sua latência.Cenário Correto (Rook/Cephadm): O orquestrador detecta o dispositivo
/dev/sdbno host. Ele passa esse device handle diretamente para o container (flag--deviceou volume modeBlockno K8s).
Quando o OSD BlueStore inicia dentro do container com acesso direto ao dispositivo, o caminho de I/O é:
OSD Process (Container) -> Syscall -> Kernel Block Layer -> Hardware.
Exatamente o mesmo caminho do Bare Metal.
O Gargalo Invisível: Rede Host (Host Networking) vs. CNI e Overlays
Se o disco não é o problema, quem é o vilão? A Rede.
No mundo Kubernetes, a rede padrão envolve plugins CNI, VXLAN, encapsulamento IP-in-IP e tabelas de nat/iptables gigantescas para fazer a mágica dos Services funcionar. Para uma aplicação web, perder 50 microssegundos e alguns ciclos de CPU desencapsulando pacotes é aceitável. Para um sistema de storage distribuído que precisa replicar dados 3x através da rede com latência de sub-milissegundos, isso é desastroso.
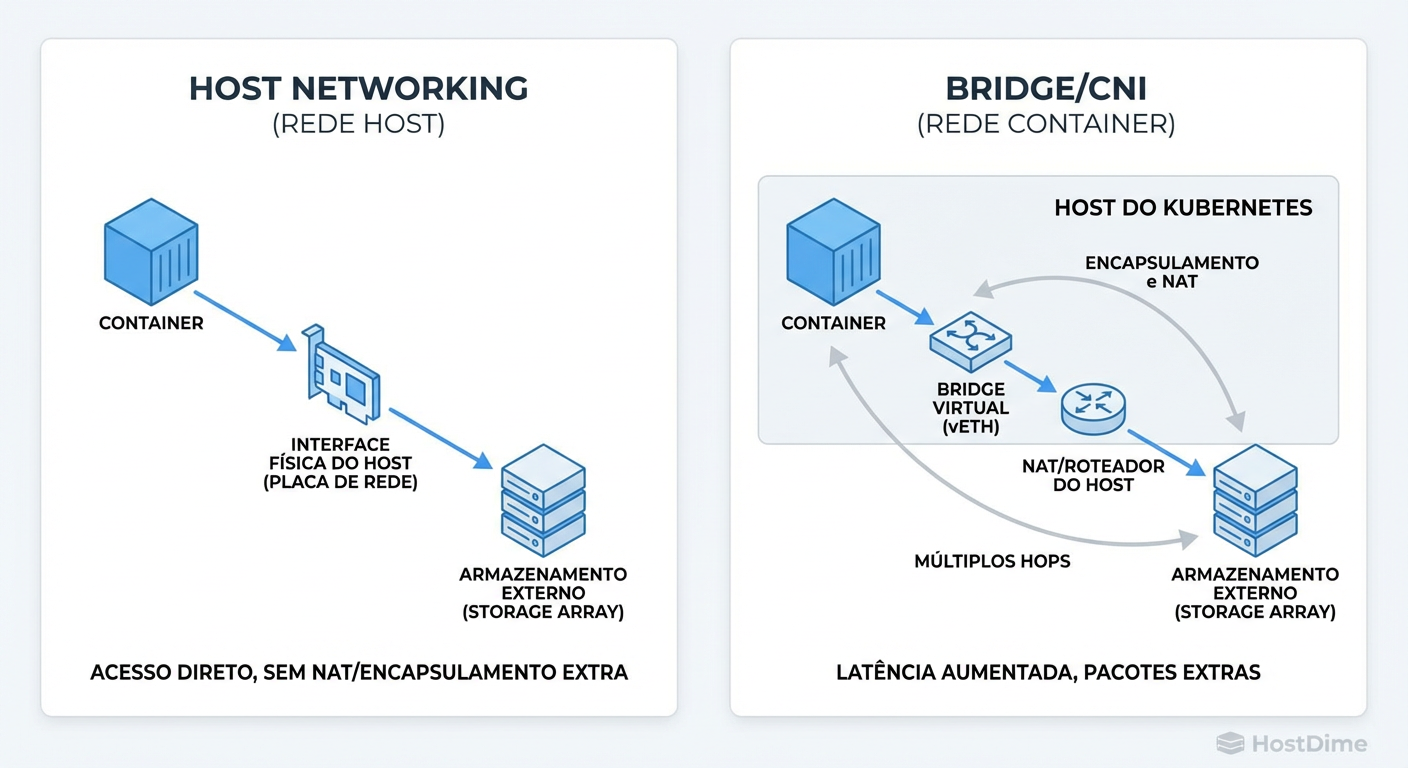 Figura: O verdadeiro vilão da latência: Comparação entre Rede Host (acesso direto) e Bridge/CNI (encapsulamento desnecessário para storage).
Figura: O verdadeiro vilão da latência: Comparação entre Rede Host (acesso direto) e Bridge/CNI (encapsulamento desnecessário para storage).
A Regra de Ouro: hostNetwork: true
Para performance de produção em Ceph rodando em Kubernetes (Rook):
Nunca use a rede do Pod (Overlay).
Sempre use
hostNetwork: true.
Ao ativar a rede de host, o container do OSD compartilha o namespace de rede do servidor físico. Ele abre os sockets TCP diretamente na interface física (ex: eth0 ou bond0). Isso elimina:
Overhead de encapsulamento VXLAN.
NAT (Network Address Translation).
Context switch desnecessário de pacotes entre namespaces.
Se você está rodando Ceph sobre uma rede overlay SDN, seus NVMe's de última geração estão esperando pacotes chegarem processados por software. Você transformou uma Ferrari em um trator.
Isolamento de Recursos: Cgroups protegem ou sufocam o OSD?
No Bare Metal clássico, um OSD "vazando" memória ou entrando em loop de CPU pode derrubar o servidor inteiro. Containers trazem a promessa de contenção via Cgroups. Mas há um trade-off perigoso aqui: o Throttling.
Se você define limites rígidos (Limits) de CPU em seus containers de OSD, você pode induzir latência artificial.
O Fenômeno do "Flapping" OSD
O Ceph OSD precisa de explosões de CPU (CPU bursts) durante operações de recuperação (recovery/backfill) ou scrubbing. Se o Cgroup cortar a CPU (throttle) exatamente nesse momento:
O OSD para de responder aos heartbeats.
Os Monitores marcam o OSD como
down.O cluster inicia um rebalanceamento (movendo dados).
O OSD ganha CPU novamente, volta como
up.O ciclo se repete.
Como medir se o container está sufocando:
Não confie no top. Olhe para as métricas de throttled time do cgroup.
# Verifique se seus OSDs estão sofrendo throttling
# (Caminho varia dependendo da versão do cgroup v1/v2)
cat /sys/fs/cgroup/cpu/kubepods/.../cpu.stat
# Procure por:
# nr_throttled: Quantas vezes foi cortado
# throttled_time: Quanto tempo (ns) ficou esperando
Recomendação Prática: Em produção, defina Requests (reserva garantida) altos para CPU e Memória, mas seja extremamente cuidadoso com Limits de CPU. Frequentemente, é melhor deixar o OSD "roubar" ciclos ociosos do host do que causar latência de I/O por throttling forçado.
Operações 'Day 2': A Diferença Brutal entre Ansible e Orchestrators (Rook)
Performance não é apenas IOPS; é também a velocidade com que você recupera o cluster de uma falha. Aqui a comparação muda de figura.
Tabela Comparativa: Gestão de Ciclo de Vida
| Característica | Bare Metal (Ansible/Ceph-Deploy) | Container (Rook/K8s) | Impacto Real |
|---|---|---|---|
| Upgrade do Ceph | Sequencial, lento, propenso a erro humano em apt-get upgrade. |
Rolling update automatizado, gerenciado pelo Operator. | Rook ganha em consistência e uptime durante upgrades. |
| Substituição de Disco | Manual: Zap disk, re-run playbook, pray. | Declarativo: O Operator detecta o disco novo e provisiona. | Rook reduz toil (trabalho braçal), mas abstrai o erro se falhar. |
| Debug de Falhas | Acesso direto: gdb, strace no PID, logs em /var/log. |
Indireto: kubectl logs, entrar no pod, ferramentas limitadas na imagem. |
Bare Metal é muito superior para diagnósticos complexos de kernel/hardware. |
O risco do container (especificamente via Kubernetes/Rook) é a complexidade da camada de controle. Se o etcd do Kubernetes falhar, você perde a capacidade de gerenciar seus OSDs, mesmo que os dados estejam lá. No Bare Metal, o OSD é um daemon systemd simples; ele sobrevive a quase tudo, exceto falha de hardware ou kernel panic.
Checklist de Decisão: Quando o Bare Metal ainda é obrigatório
Apesar da paridade de performance de I/O, existem cenários onde containers não valem o risco ou a complexidade.
Use este checklist para decidir sua arquitetura:
Hardware Exótico? Se você usa placas aceleradoras customizadas, RDMA complexo ou hardware que exige drivers de kernel muito específicos e instáveis -> Bare Metal. Montar drivers dentro de containers é dor pura.
Kernel Tuning Extremo? Se sua carga de trabalho exige parâmetros de
sysctlque conflitam com o padrão do orquestrador ou afetam vizinhos -> Bare Metal (ou Nodes dedicados).Equipe de Ops: Sua equipe sabe debugar um
CrashLoopBackOffno Kubernetes às 3 da manhã? Se a resposta for não -> Bare Metal. A latência cognitiva de resolver o problema da plataforma é maior que o ganho técnico.HCI (Hyper-Converged Infrastructure): Se você quer rodar compute e storage no mesmo hardware -> Container (Rook). O isolamento de recursos do K8s é superior para garantir que uma VM não mate o OSD e vice-versa.
Veredito do Cético
A performance bruta de um OSD em container, quando configurado com hostNetwork e acesso direto ao dispositivo de bloco, é indistinguível do Bare Metal. O medo de overhead é infundado.
O verdadeiro custo é a complexidade operacional. Você não está pagando com IOPS, está pagando com complexidade de arquitetura. Se você já domina Kubernetes, o Rook é o caminho. Se você quer simplicidade brutal e acesso direto ao hardware para debug, o Bare Metal (via Cephadm ou Ansible) ainda é o rei da estabilidade.
Referências & Leitura Complementar
Ceph Docs - BlueStore: Documentação oficial sobre a arquitetura de armazenamento direto em bloco.
Rook Design Specs: Detalhes sobre como o Rook orquestra OSDs e gerencia dispositivos.
Kernel Cgroups v2 Documentation: Para entender profundamente como o isolamento de recursos afeta a latência de processos I/O bound.
Intel/Mellanox Tuning Guides: Whitepapers sobre NUMA affinity e otimização de NICs para Storage.

Marcus Duarte
Tradutor de Press Release
"Ignoro buzzwords e promessas de marketing para focar no que realmente importa: especificações técnicas, benchmarks reais e as letras miúdas que os fabricantes tentam esconder."