Ceph Recovery Priority: Como Tunar Backfill e Salvar a Latência em Produção
Seu cluster Ceph fica lento quando um disco falha? Aprenda a equilibrar a prioridade de recuperação (backfill) versus I/O de clientes. Guia prático de tuning de OSDs.
O pesadelo de qualquer administrador de storage não é o disco que falha às 3 da manhã. Discos falham, é física. O pesadelo real é o que acontece depois: o cluster inicia a autocura, inunda a rede com tráfego de replicação e a latência da sua aplicação crítica salta de 2ms para 200ms. O telefone toca. Não é o disco quebrado que está causando o problema; é a solução.
Como Arquiteto de Soluções, vejo equipes tentando resolver isso comprando hardware mais rápido. Erro. Isso é um problema de física de filas e priorização. No Ceph, a recuperação de dados é agressiva por padrão porque a segurança dos dados é a prioridade zero. Mas em um ambiente Enterprise, a disponibilidade do serviço (SLA) compete diretamente com essa segurança.
Aqui não vamos falar de "melhores práticas" genéricas. Vamos dissecar os trade-offs entre durabilidade e latência, e como configurar o Ceph para recuperar dados sem derrubar sua produção.
O tuning de prioridade de recuperação no Ceph equilibra a velocidade de reconstrução dos dados (Backfill/Recovery) com a disponibilidade de I/O para clientes. Ajustar parâmetros como osd_recovery_sleep e perfis do mClock previne que o tráfego de rebalanceamento sature as filas dos OSDs, garantindo latência aceitável em produção mesmo durante falhas críticas de hardware.
O Paradoxo da Recuperação de Dados e Performance no Ceph
O modelo mental correto para abordar recuperação no Ceph é o Orçamento de IOPS. Cada OSD (Object Storage Daemon) tem um limite físico de operações por segundo que pode processar. Se você tem HDDs girando a 7200 RPM, esse orçamento é apertado. Se são NVMe, é largo, mas não infinito.
Quando um OSD falha, o Ceph detecta a perda de redundância. Para restaurar o nível de réplicas (digamos, de 2 para 3), ele precisa ler dados dos OSDs sobreviventes e gravá-los em novos alvos.
O paradoxo é claro:
Recuperação Rápida: Minimiza a janela de risco de perda de dados (se outro disco falhar agora, você perde dados). Consome todo o orçamento de IOPS.
Recuperação Lenta: Preserva a latência do cliente (aplicação feliz). Mantém o cluster em estado degradado (risco) por mais tempo.
A maioria dos incidentes de performance em "Day 2 Operations" ocorre porque o cluster tenta resolver o ponto 1 ignorando o ponto 2. O tráfego de recuperação e o tráfego do cliente entram na mesma fila de contenção no disco físico.
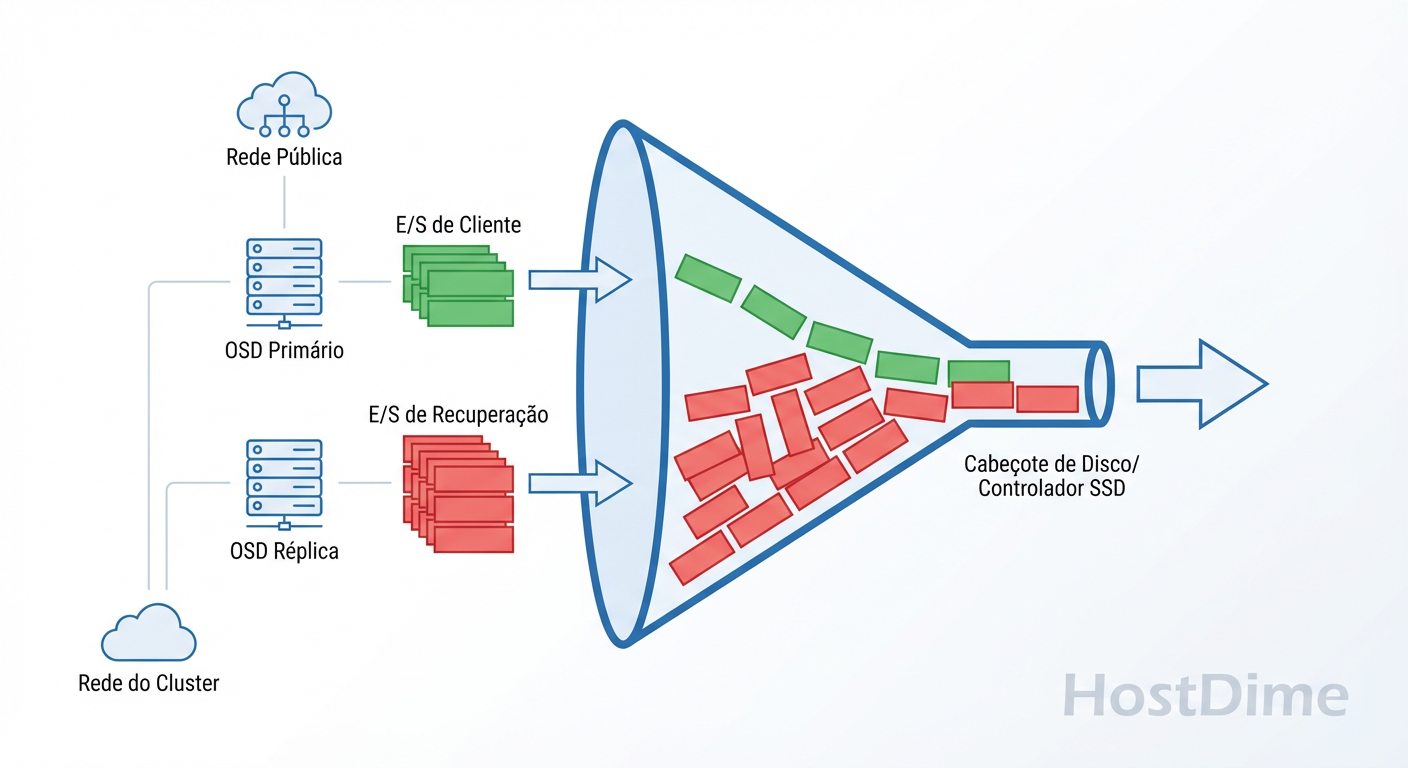 Figura: O Gargalo do OSD: Onde a recuperação e o cliente lutam pelo mesmo recurso físico.
Figura: O Gargalo do OSD: Onde a recuperação e o cliente lutam pelo mesmo recurso físico.
Se você não disser ao Ceph explicitamente para "dar passagem" ao cliente, ele vai lutar pelos recursos como se não houvesse amanhã.
Entendendo Peering, Backfill e Recovery no Fluxo de Dados
Para tunar, você precisa saber o que está tunando. O Ceph usa termos específicos que são frequentemente confundidos. Não é tudo "rebuild".
Peering: É a fase burocrática. Os OSDs conversam para concordar sobre o estado dos objetos. "Quem tem a versão mais recente do objeto X?". Isso é metadata-heavy, mas geralmente rápido. Se o peering trava, o IO para.
Recovery: Frequentemente confundido com o processo geral. Tecnicamente, no Ceph, "recovery" refere-se a consertar objetos inconsistentes ou logs ausentes. É cirúrgico.
Backfill: Aqui mora o perigo. Backfill acontece quando um novo OSD entra no cluster ou um OSD morto é substituído. O Ceph precisa copiar PGs (Placement Groups) inteiros do zero. É um movimento massivo de dados em background.
Quando a latência sobe durante um rebuild, 90% das vezes o culpado é o Backfill. É ele que satura a largura de banda da rede e os buffers de gravação dos discos.
Configurando osd_max_backfills e Parâmetros Críticos de Tuning
Antes do Ceph Quincy (e ainda relevante se você não usa mClock), a gestão era feita puramente limitando a concorrência. Existem três knobs que controlam a "violência" da recuperação.
1. osd_max_backfills
Define quantos processos de backfill um OSD pode ter ativos simultaneamente.
Padrão: 1.
Realidade: Muitos aumentam para 10 achando que vai ser mais rápido. Em HDDs, isso é suicídio. Em All-Flash, pode ser aceitável.
Recomendação: Mantenha baixo (1 ou 2) em clusters híbridos.
2. osd_recovery_max_active
Define quantas solicitações de recuperação ativa um OSD permite. Isso afeta mais a fase de Recovery (sincronização de objetos) do que o Backfill pesado.
3. O Game-Changer: osd_recovery_sleep
Aqui está o segredo que separa amadores de profissionais. Limitar a concorrência (max_backfills) apenas diz "faça 1 coisa por vez". Mas se essa "1 coisa" for contínua, o disco nunca descansa para atender o cliente.
O parâmetro osd_recovery_sleep (e suas variantes para hdd/ssd) injeta uma pausa forçada entre operações de recuperação.
Sem sleep: O OSD termina um bloco de recuperação e imediatamente pega o próximo. O cliente entra na fila e espera.
Com sleep (ex: 0.1s): O OSD termina um bloco, dorme 100ms, e só então pega o próximo. Nesse intervalo de 100ms, as requisições do cliente furam a fila e são atendidas.
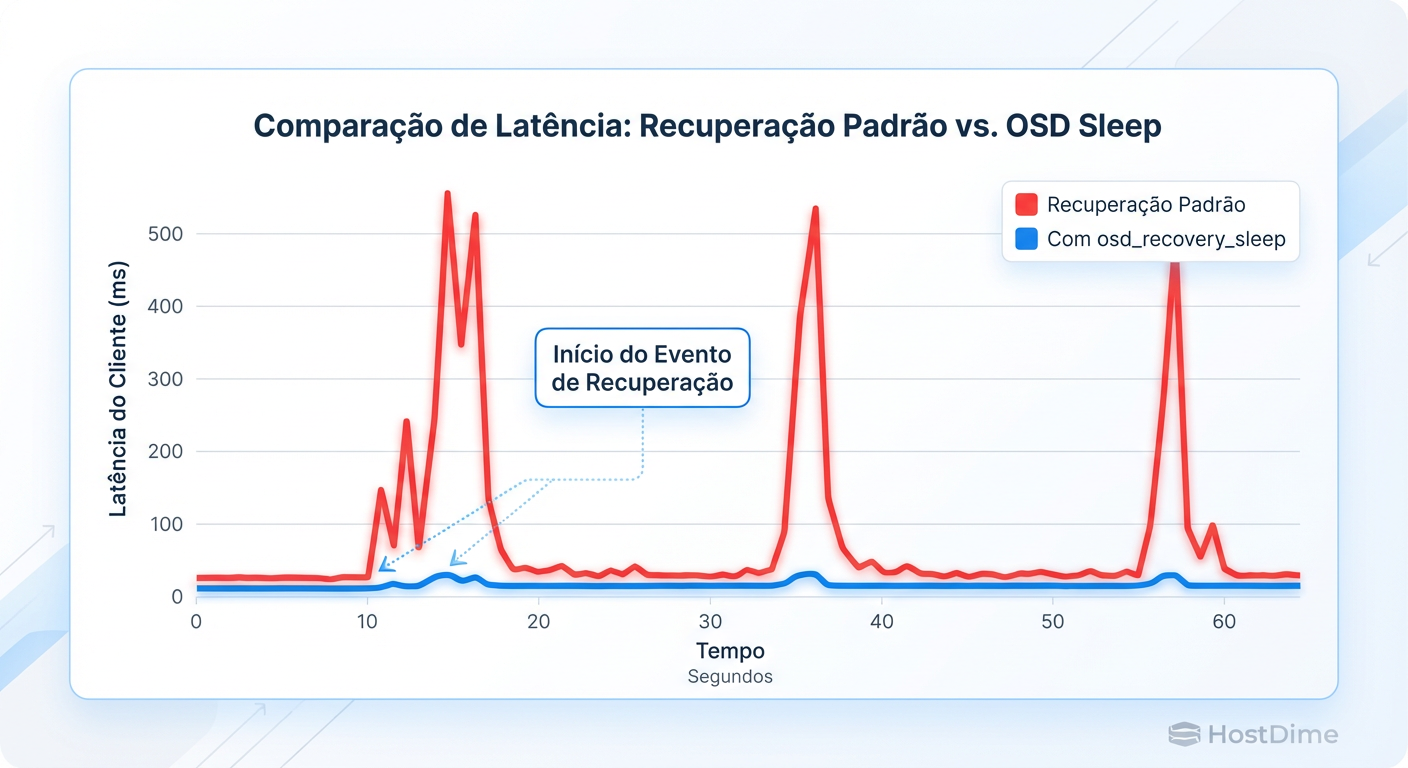 Figura: Impacto do osd_recovery_sleep: A diferença entre um cluster inutilizável e uma degradação imperceptível.
Figura: Impacto do osd_recovery_sleep: A diferença entre um cluster inutilizável e uma degradação imperceptível.
O impacto na latência do cliente é dramático. Você troca um tempo de rebuild ligeiramente maior por uma latência de aplicação estável.
ceph tell osd.* injectargs --osd_recovery_sleep_hdd=0.1
O Scheduler mClock e QoS no Ceph Quincy e Versões Recentes
A partir da versão Quincy, o Ceph introduziu o algoritmo mClock (mClockScheduler) para substituir o antigo WPQ (Weighted Priority Queue).
O mClock tenta automatizar o que fazíamos manualmente. Ele trabalha com o conceito de QoS (Quality of Service), definindo reservas (mínimos garantidos) e limites (máximos) para diferentes tipos de tráfego: cliente, recuperação e background.
Em vez de ajustar 10 parâmetros, você escolhe um perfil:
| Perfil | Comportamento | Uso Recomendado |
|---|---|---|
| high_client_ops | Prioriza agressivamente o I/O do cliente. A recuperação fica em segundo plano e pode ser muito lenta. | Clusters de produção crítica onde latência é tudo. |
| high_recovery_ops | Prioriza a recuperação. A latência do cliente vai sofrer. | Janelas de manutenção ou clusters novos (populando dados). |
| balanced | Tenta um meio termo. É o padrão (default). | Maioria dos cenários gerais. |
Atenção: O perfil balanced nem sempre é perfeito. Em situações de saturação extrema, o mClock pode não reagir rápido o suficiente para evitar timeouts na aplicação. O Arquiteto cético sabe que "automático" não significa "infalível". Em casos graves, voltar para o controle manual ou forçar high_client_ops é necessário.
Para verificar e alterar o perfil:
# Verificar configuração atual
ceph config show-with-defaults osd.0 | grep mclock_profile
# Alterar para priorizar clientes
ceph config set osd osd_mclock_profile high_client_ops
Como Medir o Impacto do Rebuild na Latência com Grafana e CLI
Você não pode gerenciar o que não mede. "O sistema está lento" não é uma métrica. Durante um evento de recuperação, você precisa monitorar duas coisas lado a lado:
Latência de Commit do Cliente: Quanto tempo o OSD leva para persistir o dado do cliente.
Taxa de Recuperação: Quantos objetos/bytes por segundo estão sendo movidos.
Via CLI (Rápido e Sujo)
Use o ceph osd perf para identificar OSDs com latência alta. Procure por outliers.
# Observe as colunas 'commit_latency_ms' e 'apply_latency_ms'
ceph osd perf
Se você ver um OSD com latência de 500ms enquanto os outros estão em 10ms, e esse OSD está participando de um backfill, você achou o gargalo.
Via Grafana (Ceph Dashboard)
No dashboard padrão do Ceph (geralmente via Prometheus), observe o painel OSD Overview.
Cruze o gráfico "Recovery Rate" com "Client Latency".
Se as curvas subirem juntas, você tem contenção.
O objetivo do tuning é achatar a curva de latência enquanto mantém a curva de recuperação acima de zero.
Protocolo de Emergência: Comandos para Estancar o Sangramento de I/O
Imagine que você perdeu um chassi inteiro de OSDs. O cluster entra em pânico e começa a reconstruir tudo. A latência sobe para 1 segundo. O banco de dados da aplicação começa a dar timeout. O chefe está na sua mesa.
Você precisa parar a recuperação agora para salvar o serviço, e depois retomá-la controladamente.
Passo 1: Parar o Backfill e Recovery Globalmente Isso "congela" a recuperação, liberando todo o I/O para os clientes.
ceph osd set nobackfill
ceph osd set norecover
Resultado: Latência deve cair instantaneamente. O cluster ficará em estado HEALTH_WARN, mas a aplicação voltará a respirar.
Passo 2: Tunar para "Modo Suave" Reduza a agressividade antes de religar.
# Reduzir concorrência
ceph tell osd.* injectargs --osd_max_backfills=1
ceph tell osd.* injectargs --osd_recovery_max_active=1
# Injetar sleep (CRÍTICO)
ceph tell osd.* injectargs --osd_recovery_sleep=0.5
Passo 3: Reativar Gradualmente Remova as flags e monitore.
ceph osd unset norecover
ceph osd unset nobackfill
Se a latência subir demais, aumente o osd_recovery_sleep. É um botão de volume que você gira até achar o equilíbrio entre "recuperando" e "funcionando".
Referências & Leitura Complementar
Para aprofundamento técnico e validação dos conceitos apresentados:
Ceph Documentation - mClock Config: Detalhes sobre os parâmetros
osd_mclock_profilee limites de QoS.Ceph Docs - OSD Config Reference: Definições completas de
osd_recovery_sleepeosd_max_backfills.The Rados Paper (Weil et al.): A arquitetura fundamental de replicação e recuperação do Ceph.
RFC 7636 (PKCE) / QoS Concepts: Embora específico para OAuth, os conceitos de Backpressure e Throttling em sistemas distribuídos são universais e aplicáveis aqui.

Viktor Kovac
Investigador de Incidentes de Segurança
"Não busco apenas o invasor, mas a falha silenciosa. Rastreio vetores de ataque, preservo a cadeia de custódia e disseco logs até que a verdade digital emerja das sombras."