Ceph Rolling Upgrades: Como Evitar o Downtime Invisível e Latência Alta
Upgrades no Ceph prometem zero downtime, mas picos de latência podem travar suas VMs. Aprenda a usar flags, monitorar slow requests e orquestrar a atualização sem paradas reais.
O upgrade de um cluster de armazenamento distribuído é a cirurgia de coração aberto da infraestrutura de TI. A promessa do Ceph é sedutora: "Rolling Upgrades" sem interrupção de serviço. O marketing diz "Zero Downtime". A realidade operacional, no entanto, diz "Latência Alta" e "Timeouts de Aplicação".
Como arquiteto, minha postura padrão é o ceticismo. O cluster pode continuar respondendo a pings, mas se a latência de gravação subir de 2ms para 200ms porque um Placement Group (PG) entrou em estado de peering, seu banco de dados transacional vai travar. Para a aplicação cliente, isso é downtime, não importa o que o dashboard do Ceph diga.
Neste artigo, vamos desmontar a mecânica do upgrade, focar nos trade-offs de disponibilidade versus consistência e definir como executar essa operação sem destruir seus SLAs.
O Que é um Ceph Rolling Upgrade e Onde Está o Risco?
Ceph Rolling Upgrade é o processo de atualizar os daemons do cluster (MONs, MGRs, OSDs) sequencialmente, um por um ou em pequenos lotes, mantendo o serviço de dados ativo. O risco crítico não é a queda do cluster, mas o "Downtime Invisível": picos de latência causados pelo bloqueio de I/O durante o peering dos PGs quando um OSD reinicia, podendo exceder os timeouts dos clientes (iSCSI, RBD, CephFS) e causar falhas em cascata na camada de aplicação.
A Mentira do "Zero Downtime" vs. Latência Operacional
Vamos ser claros: "Disponibilidade" (o serviço está up?) é diferente de "Latência Operacional" (o serviço responde rápido o suficiente?).
Durante um upgrade, você está reiniciando processos. No Ceph, a consistência é garantida pelo algoritmo CRUSH e pelo estado dos Placement Groups. Quando você reinicia um OSD para aplicar um novo binário, a "mágica" do armazenamento distribuído cobra um preço em física computacional.
Não existe almoço grátis. Para garantir que os dados não se corrompam enquanto um nó volta, o Ceph precisa pausar brevemente as operações naquele pedaço específico dos dados. Se você não planejar esse "pause", ele se torna um "stop" para sua aplicação.
A Física do OSD Restart: Onde o I/O Trava
Para entender como mitigar o impacto, você precisa visualizar o que acontece quando um daemon ceph-osd reinicia. Não é apenas "desligar e ligar".
Stop: O OSD recebe o sinal
SIGTERM. As conexões TCP são fechadas.Boot: O novo binário sobe, lê o
bluestore(metadados), e se reconecta aos Monitores (MONs).Peering (O Momento Crítico): O OSD informa aos outros OSDs do grupo: "Estou de volta e tenho estas versões dos dados". Eles precisam comparar logs para garantir que todos concordam sobre qual é a versão mais recente de cada objeto.
Active+Clean: O I/O é desbloqueado.
Durante a fase de Peering, o I/O para os PGs que residem naquele OSD fica bloqueado. O Ceph não pode permitir escrita porque não sabe quem é o dono da verdade (o Primary) naquele milissegundo.
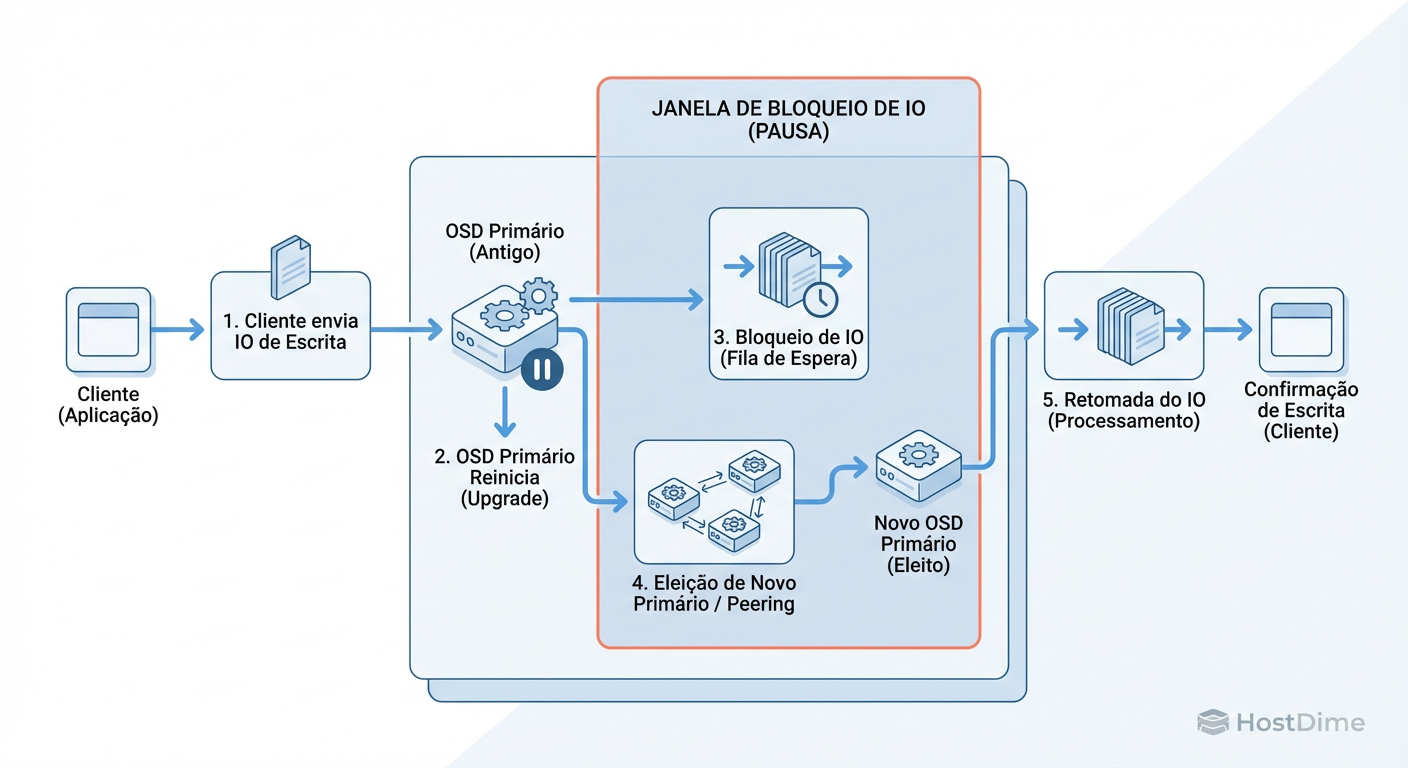 Figura: Anatomia de um Bloqueio: Onde o 'Downtime Invisível' acontece durante o Peering dos Placement Groups (PGs).
Figura: Anatomia de um Bloqueio: Onde o 'Downtime Invisível' acontece durante o Peering dos Placement Groups (PGs).
Se o seu cluster tem milhares de PGs por OSD, esse peering pode levar segundos. Se o seu disco de WAL/DB for lento, pode levar dezenas de segundos. Se isso exceder 30 segundos, muitos initiators iSCSI ou montagens Linux desconectam o volume como "Read-Only".
Checklist Pré-Voo: Validações e Flags de Proteção
Antes de tocar em qualquer pacote, você precisa preparar o terreno. A falha mais comum é confiar na automação padrão sem ajustar as proteções.
1. Flags de Proteção: noout e norebalance
O comportamento padrão do Ceph é: se um OSD fica fora por X minutos (geralmente 10 min, mon_osd_down_out_interval), o cluster assume que ele morreu para sempre e começa a reconstruir (rebalancear) os dados para outros discos.
Durante um upgrade, você não quer isso. Você sabe que o OSD vai voltar. Rebalancear dados durante um upgrade é queimar CPU e I/O de rede desnecessariamente, saturando o cluster.
ceph osd set noout
ceph osd set norebalance
noout: Impede que o CRUSH map marque o OSD como "out" e inicie a recuperação. O OSD ficará apenas "down".norebalance: Impede movimentação de dados não essencial.
Atenção: Não use
nodown. O cluster precisa saber que o OSD está down para que os outros OSDs assumam temporariamente as leituras/escritas (se tiverem réplicas). Se você usarnodown, o I/O vai para o buraco negro até o processo voltar.
2. Validação de Saúde
Nunca inicie um upgrade se o cluster não estiver HEALTH_OK. Parece óbvio, mas "HEALTH_WARN" com "1 pgs inconsistent" é um convite para o desastre. O upgrade estressa o sistema; problemas latentes vão se tornar problemas agudos.
O Lado do Cliente: Compatibilidade e Timeouts
Você pode ter o cluster de storage mais resiliente do mundo, mas se o cliente (o servidor Linux consumindo o volume RBD, ou o VMware via iSCSI) tiver "pavio curto", você terá downtime.
O Problema do Kernel e Feature Bits
Versões mais novas do Ceph introduzem novas features no CRUSH map ou no formato do RBD. Se o seu cliente Linux está rodando um Kernel antigo (ex: CentOS 7 antigo, Ubuntu 16.04), ele pode não saber "falar" as novas features.
Antes do upgrade, verifique a matriz de compatibilidade do cliente. Em muitos casos, você deve configurar o cluster para não habilitar novas features automaticamente até que todos os clientes sejam atualizados.
Timeouts Escondidos
Se um OSD demora 45 segundos para reiniciar e fazer peering, e seu cliente iSCSI tem um timeout de 30 segundos, a aplicação cai.
Linux (RBD/CephFS): Verifique configurações de
osd_client_watch_timeout.VMware/Windows (iSCSI): Aumente os valores de timeout de disco (Disk Timeout/SCSI Timeout) para pelo menos 60-120 segundos durante a janela de manutenção. Isso instrui o SO a "esperar e tentar de novo" em vez de "declarar o disco morto".
Execução Cirúrgica: Orquestração do Upgrade
Aqui entramos no debate de TCO e Operação: Cephadm (Automático) versus Manual (Ansible/CLI).
O Cephadm (introduzido no Octopus/Pacific) tenta abstrair a complexidade. Ele faz o upgrade daemon por daemon. É seguro para a maioria, mas em ambientes de ultra-baixa latência, o controle manual ainda vence.
Tabela Comparativa: Estratégias de Upgrade
| Característica | Cephadm / Orchestrator | Upgrade Manual / Ansible |
|---|---|---|
| Complexidade | Baixa (Comando único) | Alta (Controle granular) |
| Velocidade | Lento e sequencial (seguro por padrão) | Configurável (paralelismo arriscado) |
| Controle de Reinício | O sistema decide quando reiniciar o próximo | O operador decide (pode esperar o load baixar) |
| Risco de Erro Humano | Baixo | Médio/Alto |
| Caso de Uso Ideal | Clusters padrão, Web, Arquivos | HPC, Bancos de Dados Críticos, Edge |
A Abordagem Híbrida (Recomendada)
Mesmo usando Cephadm, não dê "play" e vá tomar café. Monitore. Se for manual, a ordem sagrada é:
Deployers/Admins
Monitores (MONs): Um por vez. Verifique o quorum a cada reinício.
Managers (MGRs): Verifique se o dashboard volta.
Metadata Servers (MDS): Se usar CephFS. Cuidado com o failover do MDS ativo.
Object Storage Daemons (OSDs): O passo mais longo. Reinicie por Rack ou Failure Domain para garantir que você nunca derrube duas réplicas do mesmo PG ao mesmo tempo.
Evidência de Sucesso: Métricas Cruciais para Monitorar
Como saber se o upgrade está matando a performance? Não olhe para a largura de banda (throughput). Olhe para a latência de cauda (Tail Latency) e operações bloqueadas.
Durante o processo, mantenha um terminal com ceph -w e outro com seu sistema de monitoramento (Grafana/Prometheus).
O Que Medir (KPIs de Upgrade)
slow_requests: Se este número começar a subir e não descer em segundos, pare o upgrade. Indica que o OSD reiniciado não está conseguindo servir os pedidos ou o peering está travado.blocked_ops: O indicador mais direto de "Downtime Invisível". Se > 0, alguém está esperando I/O.Latência de Recuperação: O tráfego de recuperação não deve saturar o link de cluster.
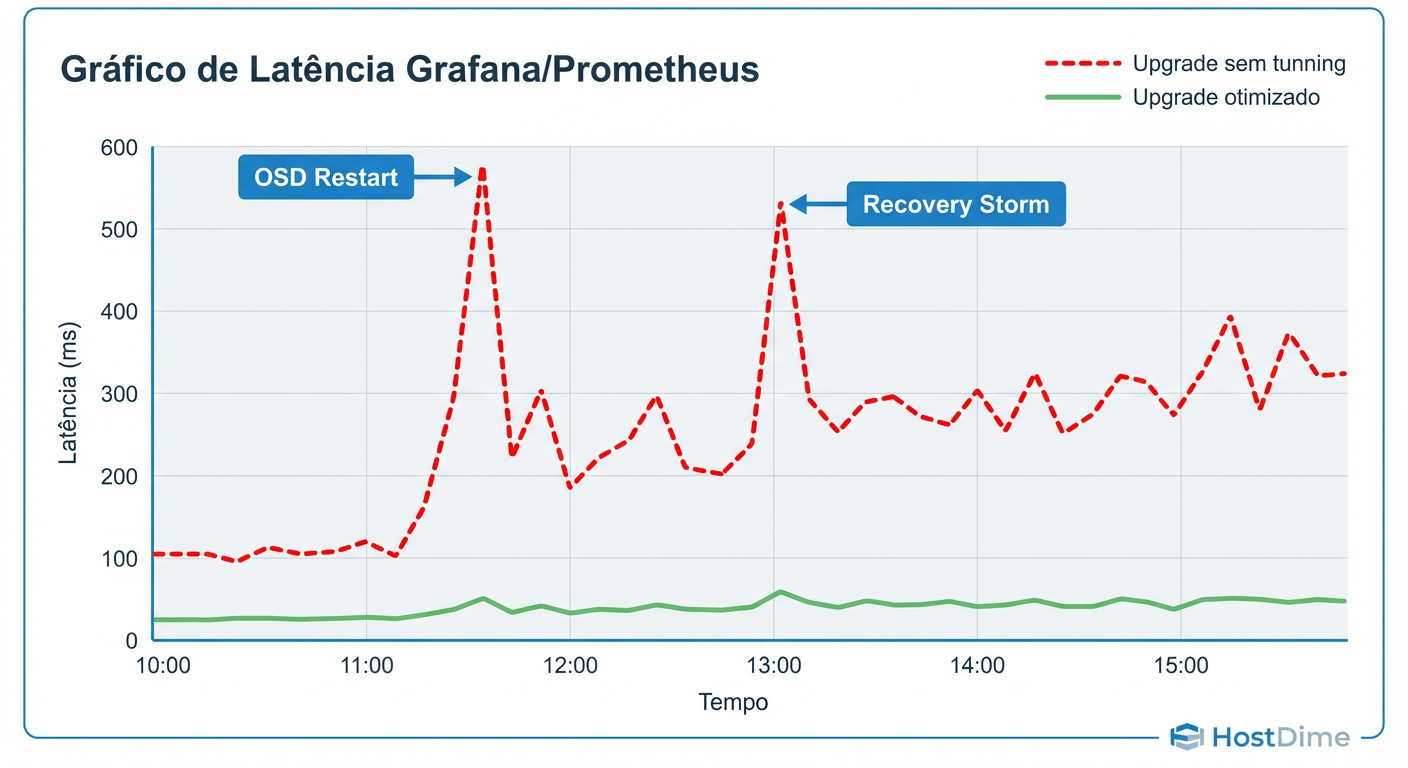 Figura: Expectativa vs. Realidade: Como a recuperação agressiva pode saturar a latência (p99) e derrubar aplicações sensíveis.
Figura: Expectativa vs. Realidade: Como a recuperação agressiva pode saturar a latência (p99) e derrubar aplicações sensíveis.
O Perigo da Recuperação Agressiva
Se, por algum motivo, um OSD demorar muito e o cluster decidir iniciar uma recuperação (mesmo com flags, às vezes forçamos manualmente), monitore o impacto no cliente. O Ceph prioriza a recuperação (segurança dos dados) sobre o I/O do cliente por padrão.
Você pode ajustar isso dinamicamente se a latência subir demais:
# Reduzir prioridade de recuperação para salvar a latência do cliente
ceph tell osd.* injectargs --osd_max_backfills 1
ceph tell osd.* injectargs --osd_recovery_max_active 1
Veredito Técnico: Operando com a Realidade
Evitar o "Downtime Invisível" em upgrades do Ceph não é sobre sorte; é sobre entender a física do peering e controlar as variáveis de tempo.
O segredo não é apenas o comando de upgrade, mas o trabalho preparatório:
Definir
noout.Garantir que os clientes tolerem pausas de 30-60s.
Reiniciar OSDs lentamente, validando a limpeza dos PGs antes de passar para o próximo.
No mundo Enterprise, o sucesso não é medido pelo esforço, mas pela invisibilidade da manutenção para o usuário final. Se ninguém notou que você atualizou o storage, você fez seu trabalho.
Referências & Leitura Complementar
Ceph Documentation: "Upgrade Strategies and Best Practices" (Docs oficiais do projeto).
RFC 3720 (iSCSI): Para entendimento profundo de timeouts e recuperação de erros em sessões SCSI.
Sage Weil (Ceph Creator): Papers sobre o algoritmo CRUSH e distribuição de dados pseudo-aleatória (CRUSH: Controlled, Scalable, Decentralized Placement of Replicated Data).
Brendan Gregg: "Systems Performance: Enterprise and the Cloud" (Metodologia de análise de latência).

Ricardo Vilela
Especialista em Compras/Procurement
"Especialista em dissecar contratos e destruir argumentos de vendas. Meu foco é TCO, SLAs blindados e evitar armadilhas de lock-in. Se não está no papel, não existe."