Ceph vs. Firmware de SSD: O Assassino Silencioso da Latência em Escala

Seu cluster Ceph está lento e a rede está ok? O culpado pode ser o firmware do SSD. Aprenda a diagnosticar latência de cauda, bugs de Garbage Collection e como operar updates em produção.
Você montou o cluster dos sonhos. Switches 100GbE, CPUs modernas e, claro, abandonou os discos rotacionais por SSDs NVMe. Nos benchmarks sintéticos, os números são lindos. Mas em produção, sob carga real, o monitoramento mostra algo perturbador: picos aleatórios de latência (latency spikes) no percentil 99 (p99) que sobem de 2ms para 500ms ou até 2 segundos.
Você culpa o Ceph. Você ajusta o BlueStore, mexe nas threads do RocksDB, culpa a rede. Mas o problema persiste.
A dura verdade que a maioria dos administradores ignora é que o Ceph, por design, é brutalmente honesto sobre o hardware subjacente. Se o seu cluster engasga, há uma grande chance de que o software esteja apenas esperando um controlador de SSD confuso terminar de arrumar a casa. Vamos dissecar como o firmware do seu disco — e não o código do Ceph — é frequentemente o gargalo invisível.
O Efeito Straggler e a Latência de Cauda
Em clusters distribuídos como o Ceph, a latência de escrita é ditada pelo dispositivo mais lento do grupo de replicação (Replica Set). Falhas ou ineficiências no firmware de SSDs, especialmente na gestão de Garbage Collection e FTL (Flash Translation Layer), criam pausas de I/O imprevisíveis que paralisam OSDs inteiros, forçando todo o cluster a esperar pelo disco "atrasado" (straggler), independentemente da velocidade da rede ou da CPU.
Por que o Ceph Expõe Falhas de Hardware que o RAID Esconde
Para entender o problema, precisamos abandonar a mentalidade herdada dos controladores RAID de hardware. Um controlador RAID tradicional é um mentiroso profissional. Ele possui um cache de escrita enorme (protegido por bateria) e uma lógica complexa dedicada a esconder do sistema operacional o que está acontecendo fisicamente nos discos. Se um SSD engasga por 200ms para limpar blocos, a controladora RAID absorve isso no cache e diz ao OS: "Gravação concluída!".
O Ceph, especificamente com o backend BlueStore, fala diretamente com o dispositivo de bloco bruto (raw block device). Não há intermediários para mentir. Quando o Ceph envia um fsync ou O_DSYNC (o que ele faz o tempo todo para garantir consistência no WAL/RocksDB), ele exige que o dado esteja fisicamente seguro na NAND.
Se o firmware do SSD decide que aquele é o momento de rodar uma rotina de manutenção interna, o Ceph espera. E se o Ceph espera, sua aplicação espera.
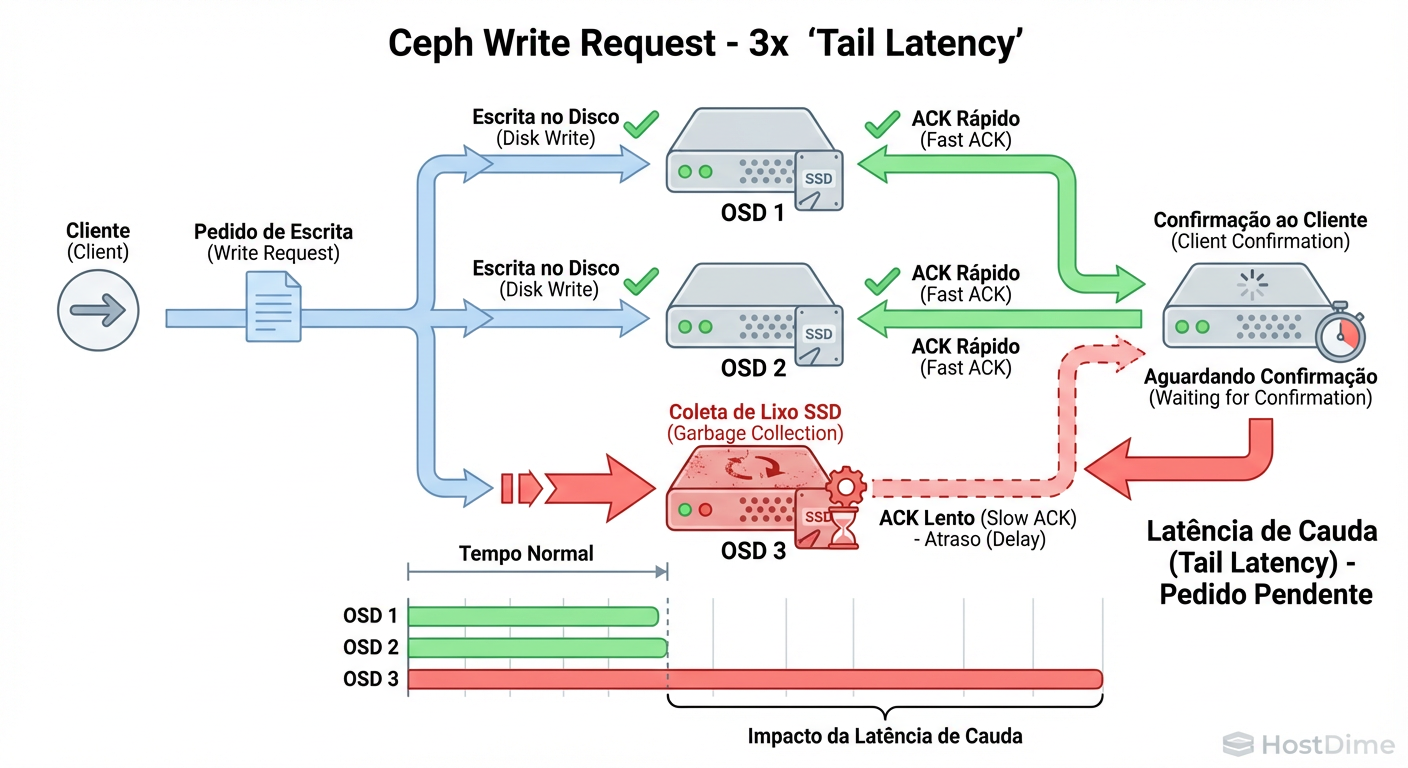 Figura: O Efeito Straggler no Ceph: Como um único firmware bugado dita a latência de todo o pool.
Figura: O Efeito Straggler no Ceph: Como um único firmware bugado dita a latência de todo o pool.
O Efeito Straggler: Quando um Único SSD em Garbage Collection Trava o Cluster
O diagrama acima ilustra o conceito de "Straggler" (o retardatário). Em um pool com replicação 3 (3x replication), uma operação de escrita só é confirmada ao cliente quando todas as réplicas estão seguras no disco.
Imagine que você tem 100 OSDs. Se apenas um desses SSDs entrar em um ciclo agressivo de Garbage Collection (GC) devido a um firmware mal otimizado, qualquer Placement Group (PG) mapeado para esse OSD sofrerá latência alta. Como os dados são distribuídos pseudo-aleatoriamente pelo algoritmo CRUSH, um único drive ruim pode afetar uma porcentagem significativa das requisições globais do cluster.
Como o FTL Reage ao WAL e DB do Ceph
O Flash Translation Layer (FTL) é o software que roda dentro do processador do seu SSD. Ele mapeia endereços lógicos (o que o Ceph vê) para endereços físicos (a célula NAND). O padrão de escrita do Ceph é particularmente tóxico para FTLs de baixa qualidade:
Writes Pequenos e Síncronos: O WAL (Write Ahead Log) e o RocksDB fazem muitas escritas pequenas que exigem confirmação imediata.
Mistura de Cargas: O mesmo dispositivo muitas vezes lida com o WAL (escrita sequencial/append) e com a compactação do RocksDB (leitura/escrita aleatória pesada).
Um firmware imaturo pode priorizar leituras em detrimento de escritas, ou pior, bloquear todo o I/O de entrada enquanto move dados internamente para liberar blocos vazios (Garbage Collection). Durante esse tempo, o drive fica efetivamente "surdo". Para o Ceph, isso parece um disco morto ou uma rede com perda de pacotes.
Mentiras de Datasheet e a Realidade do PLP em SSDs
Aqui é onde o orçamento barato sai caro. Muitos administradores tentam economizar usando SSDs "Prosumer" (Consumer High-End) em vez de Enterprise. O datasheet diz "5000 MB/s de leitura". O que o datasheet não diz é como o drive se comporta sem DRAM cache ou PLP (Power Loss Protection).
A Diferença Crítica do PLP
Em um SSD Enterprise com PLP (capacitores visíveis na placa), o drive pode confirmar um fsync assim que o dado atinge a DRAM do disco, porque ele tem energia suficiente para salvar essa DRAM na NAND se a força cair.
Em um SSD Consumer (sem PLP), para honrar um fsync verdadeiramente seguro, ele precisa escrever na NAND lenta antes de confirmar. No entanto, muitos firmwares de consumo "mentem" e confirmam antes, arriscando corrupção de dados, ou tentam escrever direto na NAND e sofrem com latência massiva sob carga sustentada.
Tabela Comparativa: O Custo Oculto do Hardware
| Característica | SSD Consumer / "Prosumer" | SSD Data Center / Enterprise | Impacto no Ceph |
|---|---|---|---|
| Proteção de Energia (PLP) | Inexistente. | Capacitores dedicados. | Sem PLP, o fsync é lento (seguro) ou mentiroso (perigoso). Com PLP, é rápido e seguro. |
| Latência de Cauda (p99) | Errática. Sobe para 100ms+ sob carga. | Consistente (< 5ms) sob carga. | Consumer causa "soluços" na aplicação. |
| Over-provisioning | Baixo (~7%). | Alto (20-30% ou configurável). | Enterprise sustenta IOPS de escrita por mais tempo sem entrar em GC agressivo. |
| Firmware | Otimizado para "Bursts" (Desktop). | Otimizado para Steady State (Servidor). | Consumer morre em cargas constantes de compactação do RocksDB. |
Diagnóstico Forense com blktrace e eBPF para Provar a Culpa do Disco
Pare de olhar para o iostat ou top. Médias de 1 segundo escondem picos de 200ms. Para provar que o firmware é o culpado, precisamos de resolução de microssegundos.
A ferramenta definitiva é o blktrace (ou ferramentas modernas de eBPF como biosnoop do pacote bcc-tools). Queremos ver o tempo entre o comando ser emitido para o driver (D - Dispatch) e a conclusão (C - Complete).
Se o tempo D2C (Dispatch to Complete) for alto, a culpa é puramente do disco. O sistema operacional entregou o comando; o disco demorou para responder.
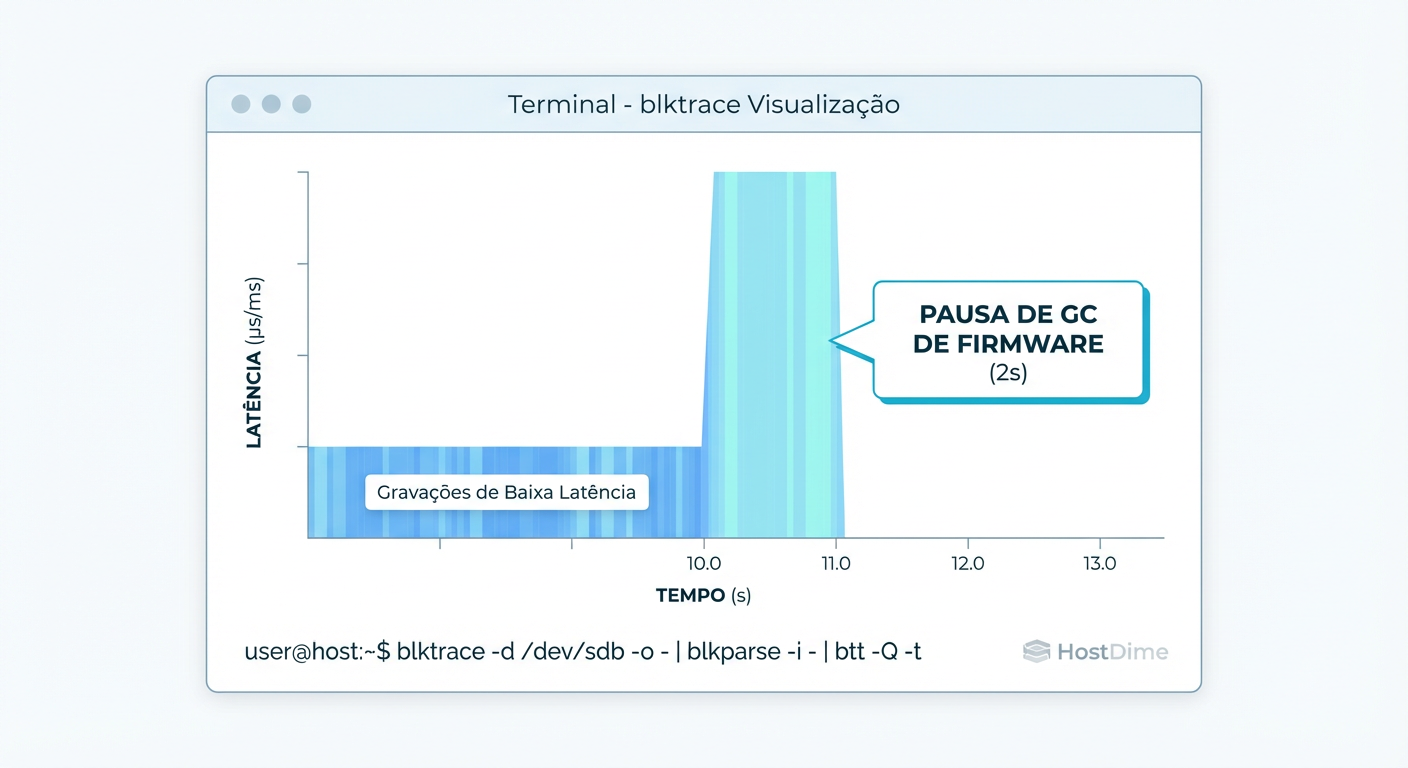 Figura: Evidência real: Um traço de I/O mostrando uma pausa de 2 segundos causada pelo controlador do SSD ignorando comandos para limpar blocos.
Figura: Evidência real: Um traço de I/O mostrando uma pausa de 2 segundos causada pelo controlador do SSD ignorando comandos para limpar blocos.
No gráfico acima, vemos um traço real. Note o "vazio" nas operações seguido por um pico de latência. O sistema operacional não parou de enviar comandos; o controlador do SSD simplesmente parou de processá-los para realizar uma limpeza interna, criando uma latência de quase 2 segundos.
Como capturar essa evidência
Não acredite na minha palavra. Rode isso no seu OSD suspeito quando a latência subir:
# Usando bcc-tools (eBPF) para ver latência por I/O individual
# Isso mostra quem está demorando mais de 10ms
/usr/share/bcc/tools/biosnoop | awk '$4 > 10.0'
# Ou a abordagem clássica com blktrace para análise posterior
# Captura 30 segundos de tráfego no dispositivo nvme0n1
blktrace -d /dev/nvme0n1 -w 30 -o trace_output
blkparse -i trace_output -d trace_output.bin
btt -i trace_output.bin > analise_final.txt
Se o relatório do btt mostrar um valor alto de D2C (Dispatch to Completion) em comparação com Q2C (Queue to Completion), você tem a "arma do crime": o drive recebeu o comando mas demorou internamente para responder.
Protocolo Seguro para Update de Firmware em Clusters Ceph Ativos
Você diagnosticou o problema. O fabricante lançou um firmware novo que promete corrigir o agendamento do Garbage Collection. Agora você tem um problema operacional: como atualizar o firmware dos discos em um cluster de produção sem corromper dados ou causar downtime?
Atualizar firmware de disco é uma operação de risco. Requer reinicialização do dispositivo (e muitas vezes do servidor).
Checklist de Sobrevivência (Rolling Update):
Verifique a Saúde:
ceph -sdeve estarHEALTH_OK. Nunca comece se já houver PGs degradados.Defina as Flags: Impeça o Ceph de rebalancear dados desnecessariamente.
ceph osd set noout ceph osd set norecoverIsole o Nó: Escolha um servidor. Coloque-o em modo de manutenção.
Update e Reboot: Aplique o firmware. A maioria dos SSDs NVMe Enterprise suporta atualização sem reboot completo do servidor (apenas reset do barramento PCIe), mas um reboot frio ("cold boot") é o único jeito de garantir que o controlador do SSD reiniciou limpo.
Verifique o Sucesso: Confirme a versão com
nvme list.Reative o OSD: Inicie o serviço do OSD.
Espere o Peering: Monitore o progresso. Apenas quando todos os PGs desse nó estiverem
active+clean, mova para o próximo nó.Limpeza: Ao final de todos os nós:
ceph osd unset noout ceph osd unset norecover
Veredito Técnico: Ceticismo é sua Melhor Ferramenta
No mundo do storage em escala, hardware "perfeito" não existe. O Ceph é uma ferramenta fantástica, mas ele opera como uma lupa sobre a infraestrutura. Se a latência está matando sua aplicação, resista à tentação de culpar a configuração do BlueStore imediatamente.
Olhe para baixo. Olhe para o firmware. Meça o tempo de resposta físico do disco. Frequentemente, a batalha pela performance não é ganha ajustando arquivos de configuração, mas escolhendo o drive certo e mantendo seu microcódigo atualizado.
Referências & Leitura Complementar
JEDEC SSD Specifications: Padrões para testes de carga de trabalho Enterprise vs. Client.
Ceph BlueStore Internals: Documentação oficial sobre como o BlueStore interage com dispositivos de bloco brutos.
eBPF & BCC Tools: Brendan Gregg’s Performance Blog – Recursos sobre
biosnoope análise de latência de disco.Samsung/Intel/Micron Data Center SSD Whitepapers: Procure especificamente por seções sobre "Quality of Service (QoS)" e consistência de latência (99.99%).

Carlos Ornelas
Mecânico de Datacenter
"Vivo nos corredores frios instalando racks e organizando cabeamento estruturado. Para mim, a nuvem é feita de metal, silício e ventoinhas que precisam girar sem parar."