Ceph vs ZFS no Proxmox: O Guia Definitivo de Performance e Arquitetura

Local ou distribuído? Analisamos IOPS, latência e custos reais do ZFS versus Ceph em clusters Proxmox. Descubra qual storage vence para o seu cenário.
Se você está construindo uma infraestrutura no Proxmox, seja um home lab robusto ou um cluster corporativo, você inevitavelmente colidirá com a grande questão do armazenamento. De um lado, temos o ZFS, o sistema de arquivos "alienígena" que promete integridade de dados absoluta em escala local. Do outro, o Ceph, o monstro do armazenamento distribuído que alimenta nuvens inteiras.
A escolha errada aqui não resulta apenas em perda de performance. Ela pode custar a integridade dos seus dados ou transformar seu orçamento de hardware em fumaça. Vamos dissecar essas duas tecnologias, bit a bit, para entender qual arquitetura merece o controle dos seus discos.
Resumo em 30 segundos
- Escala vs Velocidade: O ZFS (local) oferece a melhor latência e IOPS brutos para setups menores. O Ceph (distribuído) oferece escalabilidade infinita e alta disponibilidade real, mas cobra um "imposto de latência" por isso.
- O Fator Rede: O ZFS vive de RAM e CPU. O Ceph vive de rede. Se você não tem um backbone de 10GbE ou superior, o Ceph será dolorosamente lento.
- Regra de Ouro: Use ZFS para 1 ou 2 nós. Use Ceph para clusters de 3 nós ou mais onde a redundância automática supera a necessidade de velocidade bruta.
A filosofia do armazenamento: local vs distribuído
Para entender a performance, precisamos entender a arquitetura. O ZFS e o Ceph tentam resolver o problema de "onde guardar os dados" de maneiras opostas.
O ZFS (Zettabyte File System) é o ápice do armazenamento Scale-Up. Ele foi projetado para gerenciar discos diretamente conectados a uma única máquina. Ele combina o gerenciador de volumes e o sistema de arquivos em uma única camada. Quando você grava um dado no ZFS, o caminho é curto: RAM (ARC) -> Controlador de Disco -> Disco. A integridade é garantida por checksums matemáticos em cada bloco.
O Ceph, por outro lado, é o rei do Scale-Out. Ele é um armazenamento de objetos definido por software. No Proxmox, usamos o protocolo RBD (RADOS Block Device) para apresentar esse armazenamento como "discos virtuais" para as VMs. O Ceph não se importa com qual disco o dado está; ele se importa com a saúde do cluster. Ele espalha os dados por vários nós via rede.
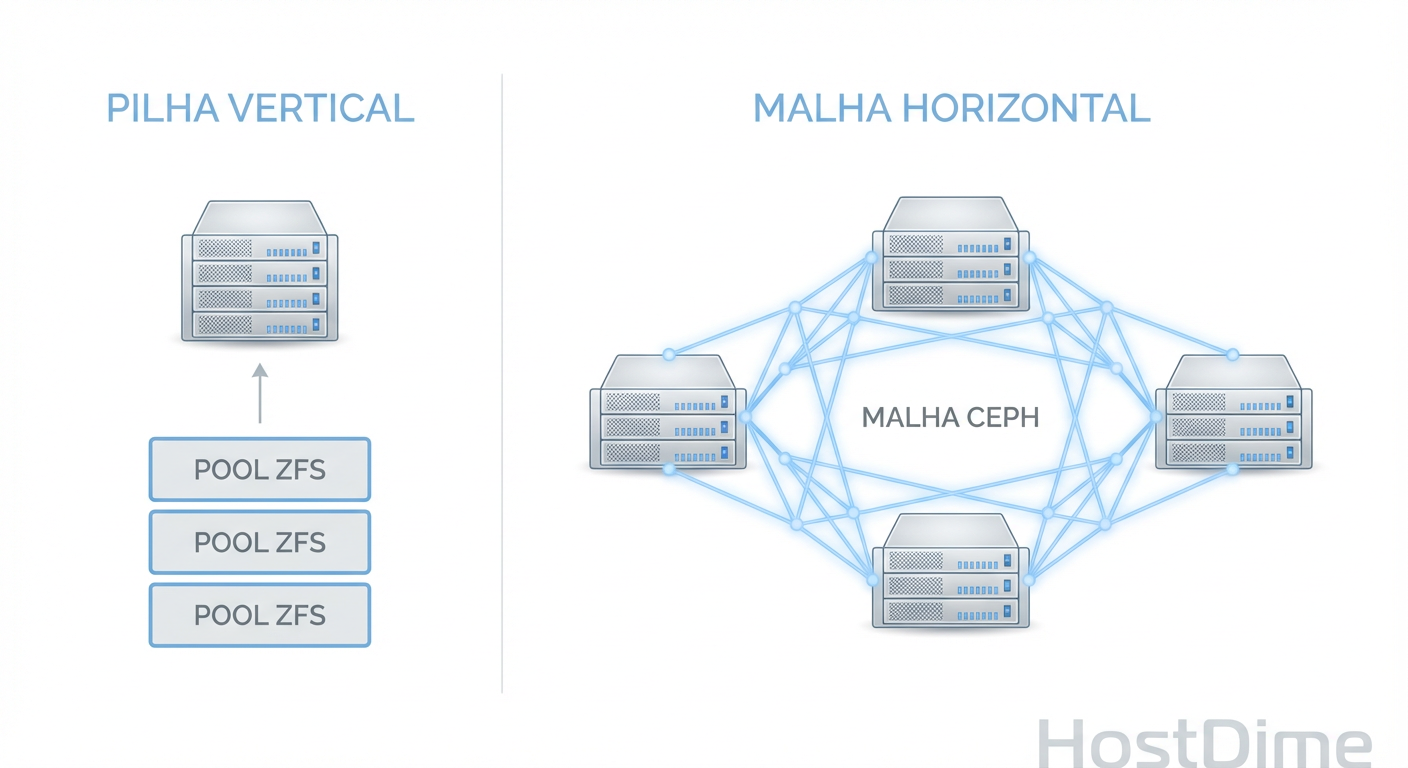 Fig 1. A diferença fundamental: ZFS escala verticalmente (dentro do nó), Ceph escala horizontalmente (entre nós).
Fig 1. A diferença fundamental: ZFS escala verticalmente (dentro do nó), Ceph escala horizontalmente (entre nós).
💡 Dica Pro: Pense no ZFS como um carro de Fórmula 1: incrivelmente rápido e complexo, mas projetado para um piloto (nó). O Ceph é um trem de carga: não faz curvas rápidas e demora para acelerar, mas carrega uma quantidade absurda de carga e, se um vagão quebrar, o trem continua andando.
Arquitetura sob o capô: ARC vs CRUSH
A mágica (e o gargalo) de cada sistema reside em como eles decidem onde colocar os bits.
ZFS e o ARC (Adaptive Replacement Cache)
O ZFS utiliza a RAM do sistema de forma agressiva para cache de leitura, o famoso ARC. Diferente do cache LRU (Least Recently Used) comum dos sistemas operacionais, o ARC balanceia entre dados acessados recentemente e dados acessados frequentemente.
Isso significa que, em um servidor Proxmox com ZFS local, grande parte das leituras nem sequer toca nos discos físicos se você tiver RAM suficiente. A latência é medida em nanossegundos (acesso à memória).
Ceph e o algoritmo CRUSH
O Ceph não usa uma tabela central de metadados para saber onde os arquivos estão (o que seria um gargalo enorme). Em vez disso, ele usa o algoritmo CRUSH (Controlled Replication Under Scalable Hashing).
Quando uma VM no Proxmox pede para gravar um dado, o cliente Ceph calcula matematicamente em qual OSD (Object Storage Daemon - geralmente um disco físico) aquele dado deve ser gravado. O problema? Esse cálculo e a subsequente distribuição dos dados dependem pesadamente da latência da rede e da CPU de múltiplos nós.
O campo de batalha da performance: IOPS e latência
Aqui é onde a realidade bate forte. Muitos administradores migram do ZFS para o Ceph esperando a mesma performance "snappy" e se decepcionam.
Em um cenário ZFS Local (RAID 10 ou RAIDZ), a latência de escrita é limitada apenas pela velocidade dos seus discos e controladores. Com SSDs NVMe modernos, você alcança centenas de milhares de IOPS com latência sub-milissegundo facilmente.
No Ceph, cada operação de escrita precisa ser confirmada. Se você configurou uma réplica de 3 (o padrão seguro), o fluxo é:
A VM envia o dado.
O OSD primário recebe.
O OSD primário replica o dado para dois OSDs secundários (em outros nós, via rede).
Os OSDs secundários gravam no disco e confirmam.
O OSD primário confirma para a VM.
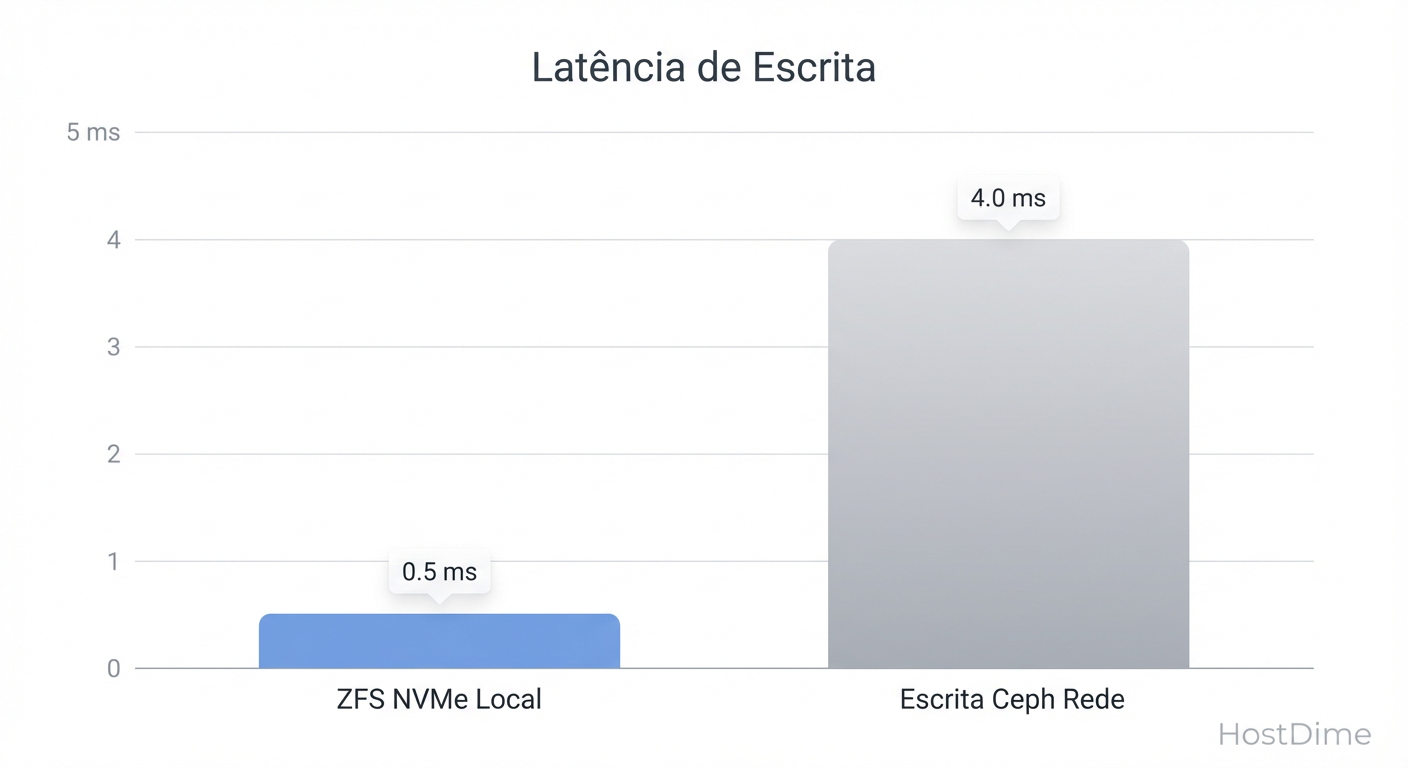 Fig 2. O custo da consistência: Ceph paga um 'imposto de latência' para garantir que os dados existam em 3 lugares ao mesmo tempo.
Fig 2. O custo da consistência: Ceph paga um 'imposto de latência' para garantir que os dados existam em 3 lugares ao mesmo tempo.
Esse "round-trip" de rede triplo é o que chamamos de Imposto de Latência. Mesmo com redes de 10GbE, a latência do Ceph será invariavelmente maior que a do ZFS local. Para cargas de trabalho sensíveis à latência (como bancos de dados transacionais pesados), o Ceph exige hardware de rede de ponta (25GbE/100GbE) e discos NVMe para competir com um ZFS SATA básico.
⚠️ Perigo: Jamais tente rodar um cluster Ceph em produção usando links de rede de 1GbE ou discos HDD sem um cache SSD/NVMe robusto (DB/WAL). O resultado será uma performance de IOPS pior que um pendrive USB 2.0, causando iowait alto nas suas VMs.
Alta disponibilidade e o dilema da replicação
Se o ZFS é mais rápido, por que alguém usaria Ceph? A resposta é: Tempo de Atividade (Uptime).
ZFS com Replicação (Proxmox Replication)
O Proxmox permite replicar volumes ZFS de um nó para outro. Isso é fantástico, mas é assíncrono. Você define um agendamento (ex: a cada 15 minutos).
Cenário de falha: Se o Nó A pega fogo, você pode subir a VM no Nó B, mas perderá os dados gravados desde a última replicação (até 15 minutos de perda).
Recuperação: Não é automática/instantânea na mesma escala que o armazenamento compartilhado real.
Ceph: O Santo Graal do HA
O Ceph é síncrono. O dado existe em três lugares ao mesmo tempo, sempre.
Cenário de falha: Se o Nó A pega fogo, o Proxmox detecta a falha e reinicia a VM no Nó B imediatamente. O Nó B lê os mesmos dados que já estão acessíveis na rede.
Perda de dados: Zero (teoricamente, para dados confirmados).
Self-Healing: Se um disco morre, o Ceph começa automaticamente a criar novas cópias dos dados perdidos em outros discos disponíveis para restaurar a redundância.
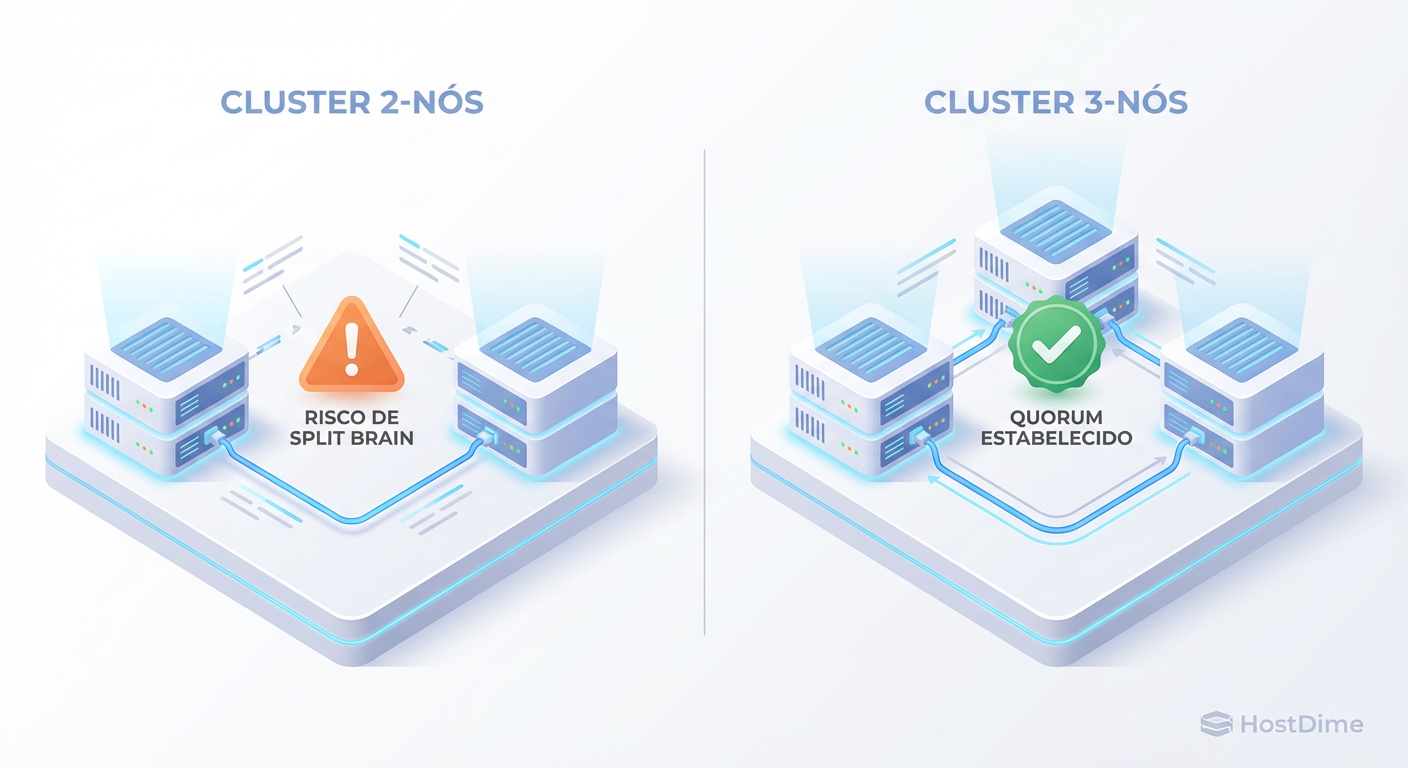 Fig 3. A regra de ouro do Quórum: Por que 3 é o número mágico para o Ceph.
Fig 3. A regra de ouro do Quórum: Por que 3 é o número mágico para o Ceph.
Requisitos de hardware: fome de RAM versus necessidade de banda
O custo de entrada varia drasticamente entre as duas tecnologias.
ZFS: Fome de RAM
A regra clássica de "1GB de RAM para cada 1TB de armazenamento" é um pouco exagerada para uso doméstico, mas para performance real com deduplicação ativada, ela é válida. O ZFS precisa de ECC RAM (recomendado) e CPU decente, mas é indulgente com a rede. Você pode rodar um storage ZFS incrível com uma placa de rede de 1GbE, desde que o acesso seja local ou o gargalo seja aceitável.
Ceph: Sede de Rede e CPU
O Ceph é um devorador de recursos.
Rede: Recomenda-se separar a rede de cluster (backend) da rede pública (frontend). Latência de rede é crítica. Switches de alta qualidade são obrigatórios.
CPU: Cada OSD (disco) consome recursos de CPU. Discos NVMe rápidos exigem núcleos de CPU rápidos para não se tornarem o gargalo.
Discos: O Ceph odeia HDDs mecânicos para armazenar seu banco de dados interno (BlueStore DB/WAL). Se for usar HDDs para dados (bulk storage), é obrigatório ter SSDs ou NVMes dedicados para o journal, ou a performance será abismal.
Veredito: definindo a escolha pelo tamanho do seu cluster
A decisão final não deve ser baseada em "qual é a melhor tecnologia", mas sim em "qual é a topologia física".
1. O Lobo Solitário (Single Node)
Escolha: ZFS. Não há motivo para rodar Ceph em um único nó (o Minikube do Ceph existe, mas não para produção no Proxmox). O ZFS lhe dará integridade de dados, snapshots instantâneos e performance máxima.
2. O Cluster Pequeno (2 Nós)
Escolha: ZFS + Replicação. Rodar Ceph em 2 nós é perigoso (falta de quórum/monitoramento adequado em caso de split-brain) e geralmente não recomendado sem gambiarras. Use ZFS em ambos e configure a replicação do Proxmox para cada 5 ou 15 minutos. É simples, robusto e rápido.
3. O Ponto de Virada (3 Nós ou mais)
Escolha: Ceph. Aqui a mágica acontece. Com 3 nós, você tem quórum real. Você pode perder um nó inteiro e o sistema continua rodando. Se você precisa de migração ao vivo (Live Migration) sem copiar a RAM inteira e o disco pela rede, ou se precisa de HA com RPO (Recovery Point Objective) zero, o Ceph é imbatível. A complexidade extra e o custo de rede se pagam pela resiliência.
4. O Cenário Híbrido
Muitos arquitetos experientes usam ambos. Discos locais NVMe formatados em ZFS para bancos de dados que exigem IOPS insanos, e um pool Ceph maior (HDD+SSD Cache) para armazenamento de arquivos, backups e VMs de uso geral. O Proxmox gerencia ambos nativamente, permitindo que você tenha o melhor dos dois mundos, desde que tenha o hardware para suportá-los.
Perguntas Frequentes
Posso usar ZFS como disco base para o OSD do Ceph? Tecnicamente sim, mas não faça isso. O Ceph moderno usa o BlueStore, que acessa o disco cru diretamente para máxima performance. Colocar ZFS embaixo do Ceph adiciona uma camada de complexidade e overhead (CoW sobre CoW) que mata a performance. Deixe o Ceph gerenciar o disco cru.
Preciso de controlador RAID de hardware para ZFS ou Ceph? Não! Ambos preferem acesso direto aos discos (HBA/IT Mode). Controladores RAID escondem a geometria real do disco e impedem que o ZFS/Ceph realizem suas tarefas de autocorreção e gerenciamento inteligente de blocos.
O que acontece se eu encher meu armazenamento Ceph? Diferente do ZFS, que apenas fica lento ou impede escritas, o Ceph pode se tornar instável se ultrapassar 85-90% de uso. O algoritmo CRUSH começa a ter dificuldade em balancear os dados. Planeje a expansão (adicionar mais nós ou discos) antes de chegar aos 80%.

Dr. Elena Kovic
Metodologista de Benchmark
"Desmonto o marketing com análise estatística rigorosa. Meus benchmarks isolam cada variável para revelar a performance crua e sem filtros do hardware corporativo."