Checklist Forense para Incidentes de IO: O Que Coletar Antes do Reboot e Como Analisar Latência de Disco

Pare! Não reinicie ainda. Guia forense completo para diagnosticar incidentes de IO, capturar evidências voláteis e identificar a causa raiz de latência de disco.
Rebootar um servidor durante um incidente de I/O não é uma solução; é a destruição da cena do crime. Como investigador forense de sistemas, minha premissa é absoluta: se você reiniciou a máquina para "resolver" a lentidão, você acabou de limpar as impressões digitais, o DNA e a arma do crime. O problema voltará, e você continuará sem saber o porquê.
A latência de disco é um assassino silencioso de performance. Ela se esconde atrás de médias enganosas e métricas de CPU mal interpretadas. Para capturar a causa raiz, precisamos ser cirúrgicos. Precisamos descer do user space para o kernel space, atravessar a camada de blocos e interrogar o driver do dispositivo.
Este artigo é o seu manual de campo. Vamos dissecar a anatomia de um incidente de I/O, desde o sintoma inicial até a correção definitiva, utilizando uma abordagem baseada em dados, logs e timestamps precisos.
Sintomas Observados: O Mito do Load Average e o Estado 'D'
O primeiro erro de um administrador inexperiente é olhar para o uptime ou top, ver um Load Average de 50.00 em uma máquina de 4 cores e assumir que a CPU está saturada. Isso é uma falácia.
No Linux, o Load Average não mede apenas o uso de CPU; ele mede a demanda de execução. Isso inclui processos em estado R (Running) e, crucialmente, processos em estado D (Uninterruptible Sleep).
O Estado 'D' (Uninterruptible Sleep)
O estado D é o sintoma clínico de que um processo fez uma system call de I/O (como read() ou write()) e o kernel o colocou para dormir até que o hardware responda. Enquanto o disco não retorna os dados, esse processo não pode ser interrompido, nem mesmo por um kill -9. Ele conta para o Load Average, mas não consome ciclos de CPU.
Se o seu monitoramento mostra CPU em 5% de uso (Idle alto) mas o Load Average está nas nuvens, você tem um gargalo de I/O, não de processamento.
# Comando forense para isolar processos em estado 'D'
$ ps -eo state,pid,cmd | grep "^D"
D 14502 /usr/bin/python3 /app/data_ingestor.py
D 2045 [jbd2/sda1-8]
No exemplo acima, temos o processo da aplicação travado e, notavelmente, o jbd2 (Journaling Block Device), indicando que o sistema de arquivos (provavelmente ext4) está lutando para commitar transações no disco.
Timeline do Incidente: Correlacionando Logs do Kernel e Histórico
Antes de culpar o hardware, precisamos estabelecer a timeline. Um pico de latência às 14:00:00 deve ter uma correlação exata nos logs.
O Checklist de Reação Imediata
O momento entre a detecção da lentidão e a decisão de rebootar (que você não tomará) é crítico. Você precisa coletar dados voláteis.
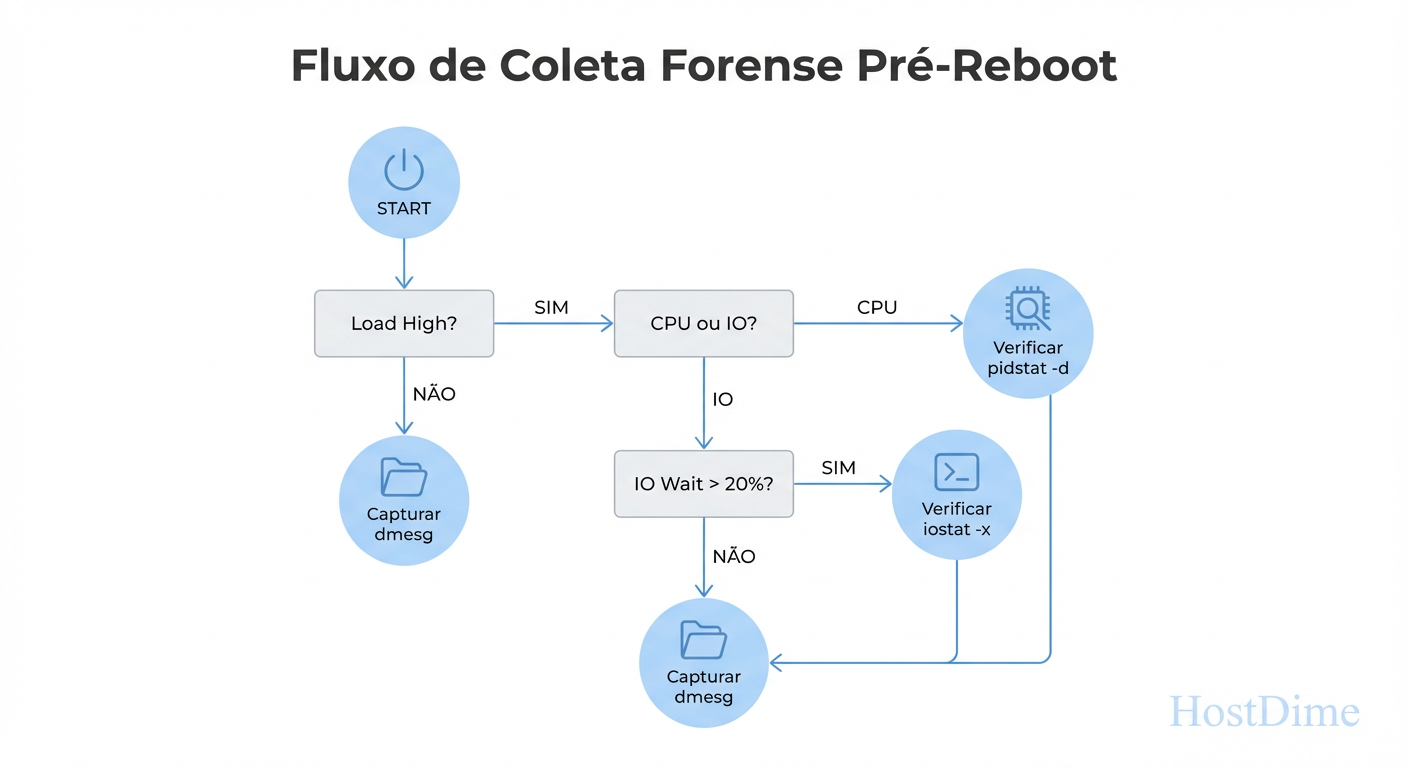 Figura: Fig. 3: O checklist de reação imediata: fluxo lógico de comandos para executar antes que o sistema trave ou seja reiniciado.
Figura: Fig. 3: O checklist de reação imediata: fluxo lógico de comandos para executar antes que o sistema trave ou seja reiniciado.
Correlacionando dmesg com SAR
O dmesg padrão mostra uptime em segundos, o que é inútil para correlação forense. Use sempre dmesg -T para obter timestamps humanos. Procure por mensagens de reset de link SATA, erros de SCSI ou timeouts de task.
# Busca por resets de link ou timeouts
$ dmesg -T | grep -iE "error|timeout|reset|sata"
[Sat Jan 3 14:05:22 2026] sd 2:0:0:0: [sda] tag#20 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE
[Sat Jan 3 14:05:22 2026] sd 2:0:0:0: [sda] tag#20 Sense Key : Hardware Error [current]
Simultaneamente, consulte o histórico via sar. O sar é a caixa-preta do seu sistema. Se o incidente ocorreu ontem, o iostat em tempo real não ajudará, mas o sar sim.
# Analisando o histórico do dia 03, focando em dispositivos de bloco (-d)
$ sar -d -p -f /var/log/sa/sa03 | head
Procure por períodos onde o %iowait foi alto concomitantemente com um aumento no await (latência média). Se o await subiu, mas o tráfego (tps, MB/s) caiu, o disco parou de responder.
Análise de Logs/Traces: Do Kit de Sobrevivência à Artilharia Pesada
Para entender onde o I/O está travando, precisamos visualizar a pilha de I/O do Linux. O caminho do dado vai da Aplicação -> VFS -> File System -> Block Layer -> Driver -> Device.
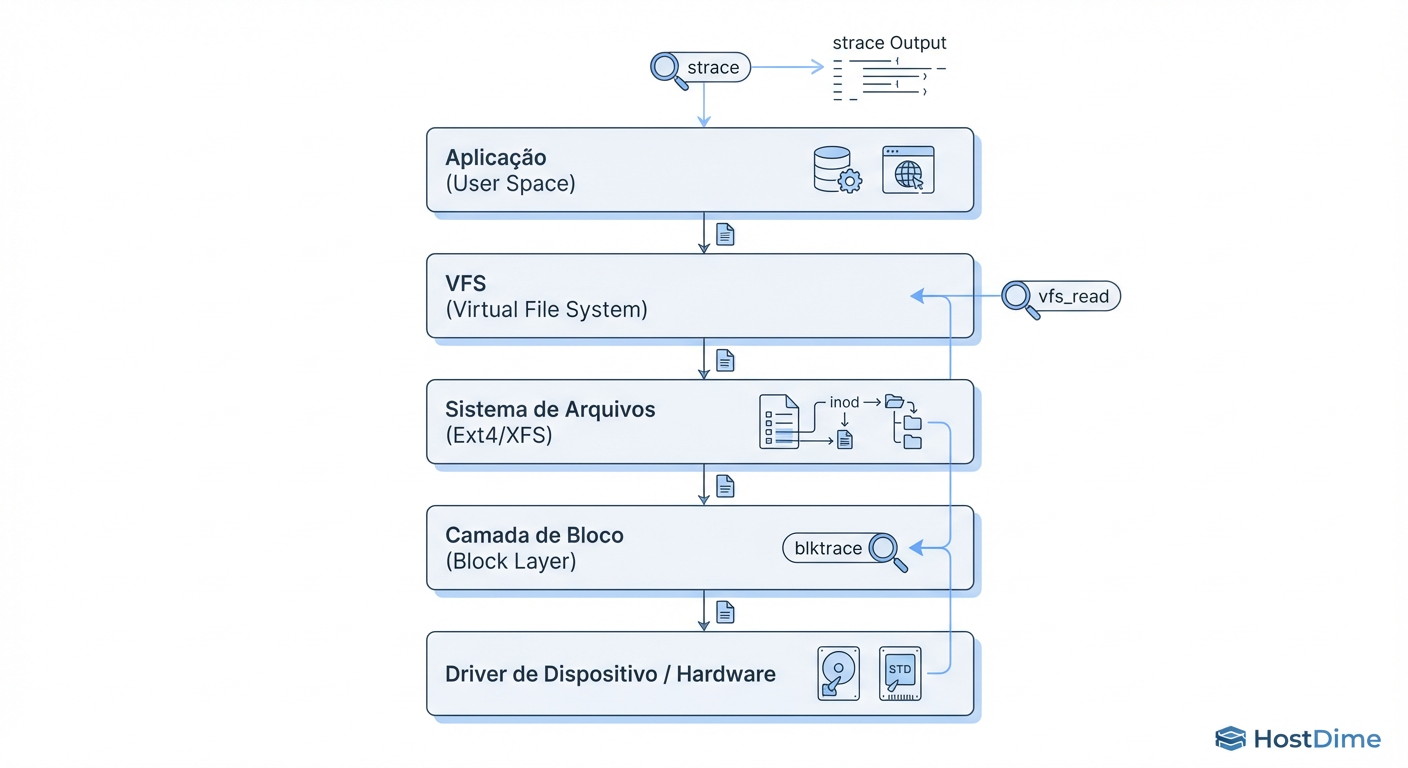 Figura: Fig. 1: A anatomia da pilha de I/O no Linux e os pontos de inserção para ferramentas de rastreamento forense.
Figura: Fig. 1: A anatomia da pilha de I/O no Linux e os pontos de inserção para ferramentas de rastreamento forense.
O Kit de Sobrevivência: iostat, pidstat e iotop
Estas ferramentas utilizam contadores do kernel expostos em /proc. Elas são leves e devem ser seu primeiro passo.
1. iostat -xz 1
O comando iostat é o padrão ouro para visão geral.
r_await / w_await: Tempo médio (em ms) que pedidos de leitura/escrita esperaram na fila + tempo de serviço. Valores acima de 10-20ms em SSDs modernos indicam problemas.
%util: Percentual de tempo que o dispositivo esteve ocupado. Cuidado: Em arranjos RAID ou SSDs modernos com filas paralelas, 100% de utilização não significa necessariamente saturação, mas é um forte indicador de contenção serial.
2. pidstat -d 1
O iostat diz que o disco está lento. O pidstat diz quem está causando isso.
$ pidstat -d 1
Linux 5.4.0-100-generic (server) 01/03/2026 _x86_64_ (4 CPU)
20:30:01 UID PID kB_rd/s kB_wr/s kB_ccwr/s Command
20:30:02 1000 14502 0.00 15400.00 0.00 python3
Aqui vemos o PID 14502 escrevendo 15MB/s.
A Artilharia Pesada: eBPF e Tracepoints
Médias mentem. Um await de 5ms pode esconder 99 pedidos de 0.1ms e 1 pedido de 500ms (timeout). Para capturar outliers, precisamos de histogramas e tracing evento-por-evento.
eBPF (bcc-tools)
Ferramentas baseadas em eBPF são seguras para produção pois não travam o kernel e têm baixo overhead.
biolatency: Mostra um histograma da latência de I/O. Permite ver se a distribuição é bimodal (cache hit vs. disk hit).
biosnoop: Traceja cada operação de I/O em tempo real, mostrando o processo, o setor do disco e a latência individual.
# Exemplo de saída do biosnoop
COMM PID DISK T SECTOR BYTES LAT(ms)
super-db 3042 sda W 123456 4096 0.15
backup-job 992 sda W 987654 1048576 255.02 <-- O Culpado
blktrace
Se você precisa saber se o problema é merge de requisições, tempo no scheduler ou tempo no driver, use blktrace seguido de blkparse.
Aviso Forense: O blktrace pode gerar gigabytes de logs em segundos. Use com triggers de tempo limitados.
Causa Raiz: Diferenciando Saturação de Hardware de Contenção de Software
Aqui separamos os amadores dos especialistas. Latência alta não significa necessariamente disco ruim. Precisamos diferenciar Wait Time (tempo na fila do OS) de Service Time (tempo que o disco levou para trabalhar).
 Figura: Fig. 2: Diferenciação crítica entre latência do disco (Service Time) e latência da fila (Wait Time) para isolar a causa raiz.
Figura: Fig. 2: Diferenciação crítica entre latência do disco (Service Time) e latência da fila (Wait Time) para isolar a causa raiz.
Tabela de Comparação Forense
| Indicador | Hardware Saturado/Falho | Contenção de Software/Kernel |
|---|---|---|
| Sintoma | await alto, %util alto |
await alto, %util baixo ou médio |
| Métrica Chave | Latência física do disco alta | Latência de fila (queue) alta |
| Causa Provável | Disco lento, IOPS excedido, RAID rebuild | Lock de Kernel, File System fragmentation, Scheduler ineficiente |
| Ferramenta | iostat, logs do storage array |
biolatency, análise de locks |
Cenários Comuns de Causa Raiz
Saturação de IOPS: O disco físico atingiu seu limite mecânico ou eletrônico. O
avgqu-sz(tamanho médio da fila) dispara. As requisições acumulam na camada de bloco esperando o hardware.Locks de Filesystem (Journaling): Se o seu
jbd2está no topo doiotopcom 99% de IO-Wait, o problema é a serialização de escritas no journal do EXT4. Isso é comum em bancos de dados fazendo muitosfsync()pequenos.Fragmentação: Em HDDs, leituras sequenciais que se tornam aleatórias devido à fragmentação matam a performance. O
iostatmostrará um throughput (MB/s) baixo apesar de IOPS altos.
Correção Definitiva: Ajustes de IO Scheduler e Isolamento
Uma vez identificada a causa raiz, aplicamos a correção. "Comprar discos mais rápidos" é a última opção.
1. Ajuste do I/O Scheduler
O scheduler decide a ordem das requisições enviadas ao disco.
Para NVMe/SSDs rápidos: Use
noneoukyber. O hardware é rápido o suficiente; não gaste CPU reordenando filas.Para HDDs/SATA: Use
bfqoumq-deadline. Obfqé excelente para garantir que uma cópia de arquivo massiva não trave a responsividade do SSH.
# Verificando e alterando o scheduler (sem reboot)
$ cat /sys/block/sda/queue/scheduler
[mq-deadline] kyber bfq none
$ echo bfq > /sys/block/sda/queue/scheduler
2. Isolamento via Cgroups (Blkio Controller)
Se um processo de backup está matando seu banco de dados, limite-o. O systemd e o Docker usam Cgroups v2 para isso. Você pode limitar IOPS ou Banda (Bps) por serviço.
# Exemplo de limitação via systemd
[Service]
IOReadBandwidthMax=/dev/sda 10M
IOWriteBandwidthMax=/dev/sda 5M
3. Redimensionamento e Ajustes de Filesystem
Barriers: Em ambientes com nobreak e bateria na controladora RAID, montar o EXT4/XFS com
nobarrierpode dobrar o throughput de escrita, removendo a obrigatoriedade de flush físico imediato (mas aumenta risco de corrupção em falha de energia).Striping: Se o volume lógico (LVM) está em um único disco físico, migre para um arranjo RAID 10 ou distribua os Logical Volumes (LVs) em múltiplos Physical Volumes (PVs).
Veredito Técnico Forense
Incidentes de I/O não são resolvidos com magia, mas com métricas. Ao seguir o fluxo Sintomas (State D) -> Timeline (dmesg/sar) -> Análise (eBPF) -> Causa Raiz (Queue vs Disk), você deixa de ser um "reiniciador de servidores" e se torna um investigador de sistemas. Colete as evidências antes que elas desapareçam.
Referências
Gregg, Brendan. Systems Performance: Enterprise and the Cloud, 2nd Edition. Addison-Wesley Professional, 2020. (Foco no Método USE e ferramentas eBPF).
Kernel.org Documentation. Block Layer Statistics & I/O Schedulers. Disponível na documentação oficial do kernel Linux.
Axboe, Jens. Linux Block IO: Present and Future. Proceedings of the Linux Symposium. (Autor do
io_uringe mantenedor do subsistema de bloco).

Roberto Almeida
Auditor de Compliance (LGPD/GDPR)
"Especialista em mitigação de riscos regulatórios e governança de dados. Meu foco é blindar infraestruturas corporativas contra sanções legais, garantindo a estrita conformidade com a LGPD e GDPR."