Ciclo de vida do hardware e a blindagem de SLAs em storage corporativo

Análise técnica sobre como a gestão do ciclo de vida do hardware define a conformidade de SLAs. Riscos de EOSL, cálculo de TCO e estratégias para evitar multas contratuais em data centers.
A estabilidade de um ambiente de armazenamento de dados não é uma questão de sorte; é uma equação matemática de probabilidade e consequência. Quando assinamos um Acordo de Nível de Serviço (SLA) prometendo 99,999% de disponibilidade, estamos nos comprometendo legalmente a não exceder 5 minutos e 15 segundos de inatividade não planejada por ano. Manter hardware de storage além do seu ciclo de vida ideal (EOSL - End of Service Life) não é apenas uma estratégia de economia de CAPEX; é uma aposta de alto risco contra a física dos componentes e a paciência dos stakeholders.
No cenário corporativo, a infraestrutura de dados é a base da continuidade de negócios. Um servidor pode ser reiniciado, uma aplicação pode ser redeployada, mas um array de discos corrompido por falhas mecânicas em cascata é um evento catastrófico. A gestão de nível de serviço exige uma visão fria sobre quando o ativo deixa de ser um recurso e passa a ser um passivo jurídico e operacional.
Resumo em 30 segundos
- Risco Exponencial: A probabilidade de falha em HDDs e SSDs não é linear; ela dispara após o quinto ano de uso, entrando na zona crítica da "curva da banheira".
- Ilusão de Economia: Manter hardware legado via suporte de terceiros (TPM) reduz custos imediatos, mas aumenta drasticamente o MTTR (Tempo Médio para Reparo) e a exposição a multas contratuais.
- Blindagem Jurídica: A renovação tecnológica (Tech Refresh) atua como evidência de diligência técnica, protegendo a organização em litígios sobre perda de dados ou indisponibilidade.
O dilema financeiro e a exposição ao risco operacional
A tensão entre o CFO (focado em reduzir CAPEX) e o Gerente de Nível de Serviço (focado em garantir disponibilidade) é clássica. A extensão da vida útil de um storage array de 5 para 7 ou 8 anos parece, na planilha contábil, uma vitória de eficiência. No entanto, essa visão ignora a degradação física dos componentes e a obsolescência do firmware.
Em ambientes de missão crítica, o custo do hardware é frequentemente uma fração do custo de uma hora de parada. Se um storage SAN Enterprise sofre uma falha catastrófica devido a um backplane envelhecido, as multas por violação de SLA, somadas aos danos reputacionais e perda de produtividade, podem superar o valor de compra de um equipamento novo.
💡 Dica Pro: Ao apresentar o caso para um refresh tecnológico, não fale apenas em "velocidade". Traduza o risco técnico em moeda. Calcule o custo da hora parada da empresa e multiplique pelo MTTR estimado de um equipamento sem suporte oficial do fabricante.
A saturação da curva da banheira em discos rígidos
Para entender a inevitabilidade da falha, utilizamos o conceito da "Curva da Banheira" (Bathtub Curve). Este modelo estatístico descreve as taxas de falha de componentes eletrônicos e mecânicos ao longo do tempo.
Mortalidade Infantil: Falhas precoces devido a defeitos de fabricação. Geralmente cobertas pela garantia inicial e resolvidas nos primeiros meses.
Vida Útil (Taxa de Falha Constante): O período de operação estável. As falhas são aleatórias e raras.
Zona de Desgaste (Wear-Out): O ponto crítico. Em HDDs mecânicos, os rolamentos do motor e os atuadores começam a falhar por fadiga física. Em SSDs, as células de memória NAND atingem seus limites de ciclos de programação/apagamento (P/E cycles), resultando em retenção de dados comprometida.
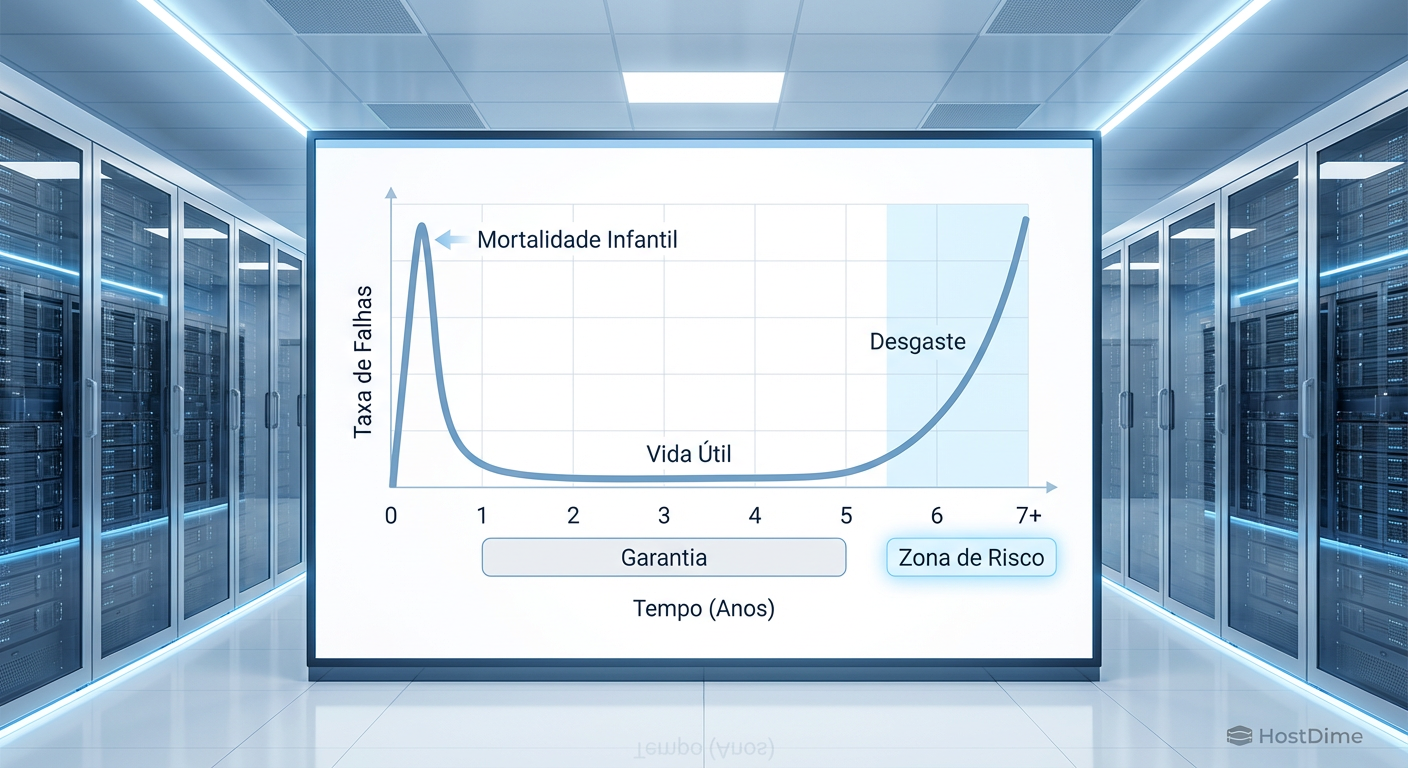 Figura: Gráfico da Curva da Banheira demonstrando as três fases de vida de um componente de storage: mortalidade infantil, vida útil estável e a zona de desgaste acelerado após o quinto ano.
Figura: Gráfico da Curva da Banheira demonstrando as três fases de vida de um componente de storage: mortalidade infantil, vida útil estável e a zona de desgaste acelerado após o quinto ano.
Quando um array RAID entra na zona de desgaste, a probabilidade de uma segunda falha ocorrer durante a reconstrução (rebuild) de um disco defeituoso aumenta significativamente. Em discos de alta capacidade (18TB+), um rebuild pode levar dias. Se outro disco do mesmo lote, com o mesmo desgaste mecânico, falhar nesse processo, o resultado é a perda total do volume e uma violação irreversível do SLA.
Matemática do TCO: Suporte de terceiros (TPM) vs Refresh
Quando o fabricante declara o EOSL (End of Service Life), muitas empresas recorrem à Manutenção de Terceiros (TPM - Third-Party Maintenance). Embora seja uma opção válida para ambientes de teste ou arquivamento frio, aplicá-la em Produção Tier 1 é um risco calculado que muitas vezes é subestimado.
O problema central do TPM não é a competência dos técnicos, mas a logística de peças e a ausência de engenharia de software. O fabricante (OEM) não fornece mais patches de segurança ou correções de microcódigo para equipamentos em EOSL. Se um bug de firmware for descoberto, não haverá correção.
Comparativo: OEM Support vs TPM
| Critério | Suporte OEM (Fabricante) | Suporte TPM (Terceiros) | Impacto no SLA |
|---|---|---|---|
| Acesso a Peças | Estoque global garantido e novo. | Estoque de mercado secundário (peças usadas/recondicionadas). | Alto risco de atraso no MTTR. |
| Firmware/Patches | Desenvolvimento contínuo de correções. | Sem acesso a novas correções de engenharia. | Vulnerabilidade a bugs e segurança. |
| Expertise | Engenheiros que projetaram o produto. | Generalistas multimarca. | Resolução de problemas complexos mais lenta. |
| Custo | Premium (Alto). | Econômico (50-70% menor). | Redução de OPEX, aumento de risco. |
Para um Gerente de Nível de Serviço, a economia do TPM só se justifica se o SLA acordado com o cliente permitir janelas de manutenção estendidas e tempos de recuperação (RTO) elásticos. Se o contrato exige "cinco noves", o TPM é tecnicamente inviável.
Protocolos de migração e disponibilidade contínua
A substituição de hardware não pode ser a causa da violação que tentamos evitar. O processo de migração de dados de um storage legado para um novo deve seguir protocolos rígidos para garantir zero downtime perceptível.
A utilização de tecnologias de virtualização de storage ou migração baseada em host (como vMotion em ambientes VMware ou Live Migration em Hyper-V) é mandatória. No entanto, o risco reside na integridade dos dados. Discos antigos sob estresse de leitura intensa durante uma migração total têm maior propensão a apresentar erros de leitura irrecuperáveis (URE).
⚠️ Perigo: Nunca inicie uma migração em massa de um storage em fim de vida sem antes validar a integridade dos backups e realizar uma verificação de consistência (scrubbing) nos dados. O estresse mecânico da migração é frequentemente o "tiro de misericórdia" para discos já fragilizados.
Modernização como blindagem jurídica
Além dos aspectos técnicos, existe a camada de responsabilidade civil e contratual. Em caso de perda de dados sensíveis ou indisponibilidade que gere prejuízo financeiro a terceiros, a auditoria investigará se a organização agiu com a devida diligência.
Operar infraestrutura crítica em hardware declarado como obsoleto pelo fabricante, sem suporte oficial de engenharia, pode ser interpretado como negligência. Manter o ciclo de vida do hardware atualizado não é apenas sobre performance; é uma blindagem jurídica. Demonstra que a empresa utiliza o "estado da arte" para proteger os ativos digitais sob sua custódia.
Contratos de SLA bem redigidos devem incluir cláusulas que preveem janelas de manutenção para refresh tecnológico, eximindo a TI de penalidades durante essas operações planejadas. A falha em planejar o ciclo de vida força a TI a operar em modo reativo, onde as paradas são não planejadas e, portanto, passíveis de multa.
Veredito Técnico
Como gestores focados em garantias, devemos ser categóricos: a extensão da vida útil de storage via TPM é uma ferramenta tática para ambientes não críticos, nunca uma estratégia de longo prazo para o core business. O custo da redundância e da renovação é o prêmio de seguro que pagamos para manter a continuidade. Ignorar a curva da banheira e a obsolescência de firmware é garantir que, eventualmente, o SLA será violado, e a justificativa de "economia de custos" não será aceita no tribunal ou na reunião de diretoria.
Perguntas Frequentes (FAQ)
Como o fim da vida útil (EOSL) do storage afeta o cumprimento do SLA?
O EOSL elimina o suporte oficial do fabricante, o que significa que não há mais garantia de peças novas nem correções de engenharia (firmware). Isso aumenta drasticamente o MTTR (Tempo Médio para Reparo) e a probabilidade de falhas recorrentes, elevando o risco de violação das garantias de disponibilidade e resultando em penalidades contratuais severas.Qual é a relação entre a "curva da banheira" e os custos de data center?
A curva da banheira demonstra estatisticamente que as taxas de falha em HDDs e SSDs aumentam exponencialmente após 4 ou 5 anos de uso (fase de desgaste). Isso eleva os custos operacionais (OPEX) devido à necessidade frequente de substituições manuais, consumo de horas técnicas e, principalmente, o risco crítico de perda de dados durante reconstruções de RAID em arrays degradados.Vale a pena usar manutenção de terceiros (TPM) para estender o hardware?
Financeiramente, o TPM reduz o CAPEX imediato e o custo de manutenção. No entanto, essa economia deve ser calculada contra o risco aumentado de downtime prolongado. Para cargas de trabalho críticas (Tier 1) que exigem alta disponibilidade, o refresh tecnológico geralmente oferece melhor ROI a longo prazo e maior segurança jurídica do que depender de peças de mercado secundário via TPM.Referências Bibliográficas
SNIA (Storage Networking Industry Association). "Data Storage Endurance and Reliability Standards."
ITIL 4 Foundation. "Service Level Management Practice Guide."
Backblaze. "Annual Hard Drive Failure Stats and Analysis."
Gartner. "Market Guide for Data Center and Network Third-Party Hardware Maintenance."

Arthur Sales
Gerente de Nível de Serviço
"Vivo na linha tênue entre a conformidade e a violação contratual. Para mim, 99,9% não é disponibilidade; é prejuízo. Exijo garantias absolutas e aplicação rigorosa de penalidades."