Clock Skew em Storage Distribuído: Diagnóstico, Impacto e Consistência de Dados

O tempo é a variável mais perigosa do seu cluster. Entenda como o clock skew causa corrupção de dados, falhas de consenso (Raft/Paxos) e split-brains em sistemas como Ceph e MinIO.
Você confia no relógio do seu servidor. Esse é o seu primeiro erro.
A maioria dos administradores de sistemas trata o tempo como uma constante universal, algo que o sistema operacional obtém magicamente e mantém preciso. Na realidade, o tempo em computação é uma alucinação coletiva mantida por cristais de quartzo baratos, protocolos de rede com latência variável e kernels sobrecarregados.
Quando operamos um servidor isolado, um desvio de alguns segundos é apenas um incômodo nos logs. Mas quando entramos no território do Storage Distribuído (Ceph, Gluster, MinIO, vSAN) ou bancos de dados distribuídos (Cassandra, CockroachDB), o tempo não é apenas um metadado: é a base da consistência dos seus dados. Um relógio "mentiroso" pode causar desde reeleições de líder desnecessárias até a perda silenciosa de dados que foram gravados com sucesso.
Aqui não vamos falar sobre como configurar o fuso horário. Vamos dissecar como o Clock Skew (desvio de relógio) destrói clusters e como provar que o problema é o tempo, e não a rede.
O que é Clock Skew em Storage Distribuído? Clock Skew é a diferença instantânea de tempo entre dois relógios em nós diferentes de um cluster. Em sistemas distribuídos, esse desvio compromete a ordenação de eventos (causalidade), invalida mecanismos de lease (aluguel de liderança) e corrompe estratégias de resolução de conflitos como "Last Write Wins", resultando em sobrescrita de dados recentes por dados antigos ou cenários de Split-Brain.
O Mito do Tempo Absoluto e a Realidade do Timestamp
Para entender o risco, você precisa abandonar a ideia de que existe um "agora" sincronizado. O hardware subjacente aos seus servidores de storage utiliza osciladores de cristal que sofrem deriva (drift) baseada em temperatura, vibração e idade.
Se você tem um cluster Ceph com 50 OSDs, você tem 50 realidades temporais diferentes. O protocolo NTP (Network Time Protocol) tenta disciplinar esses relógios, mas ele luta contra a latência da rede (jitter).
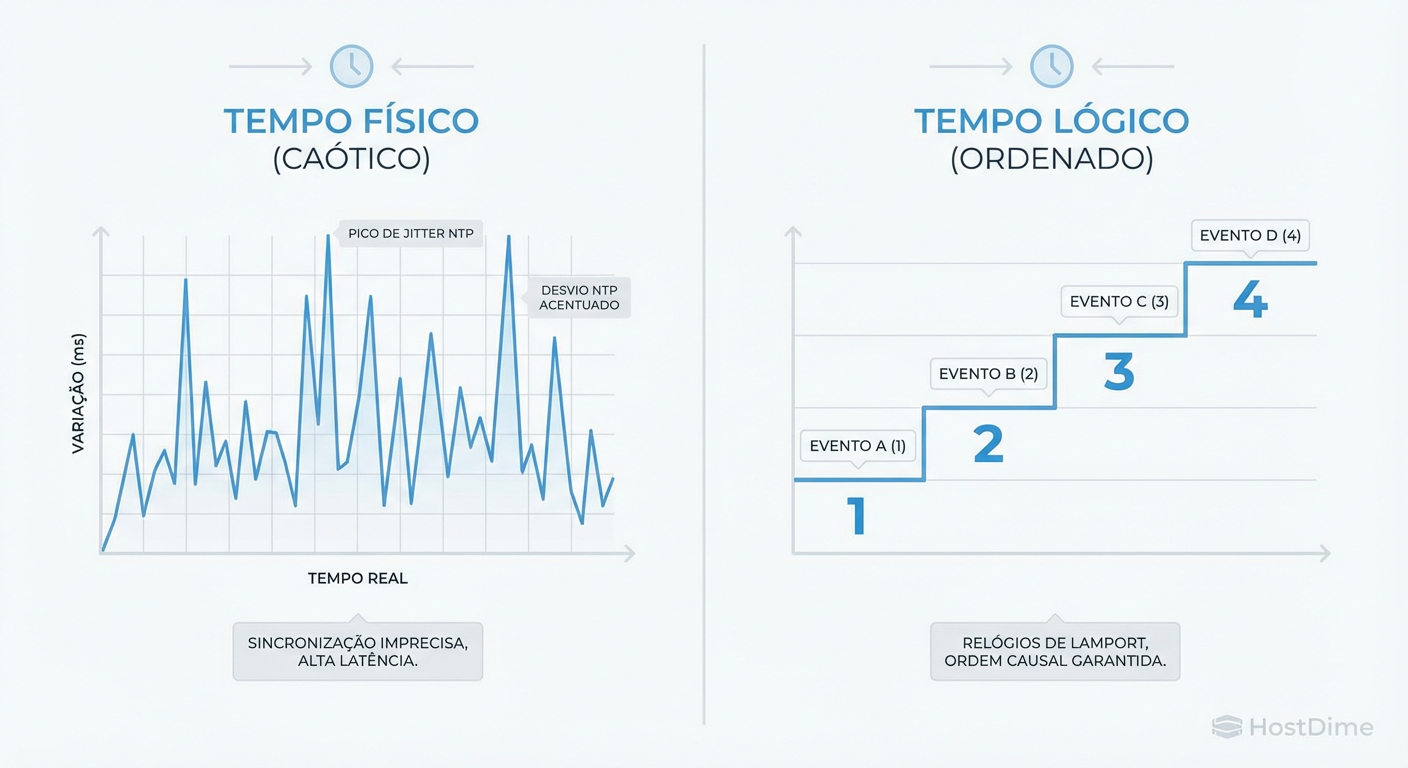 Figura: Tempo Físico vs. Relógios Lógicos: A diferença entre tentar sincronizar relógios de quartzo (impreciso) e ordenar eventos por causalidade (seguro).
Figura: Tempo Físico vs. Relógios Lógicos: A diferença entre tentar sincronizar relógios de quartzo (impreciso) e ordenar eventos por causalidade (seguro).
O problema central é que muitos sistemas de arquivos e bancos de dados distribuídos utilizam o Wall-Clock Time (o relógio físico do sistema) para carimbar transações. Se o Servidor A está 100ms à frente do Servidor B, e ambos recebem uma gravação quase simultânea, o sistema pode interpretar que a gravação de A aconteceu depois, mesmo que fisicamente tenha ocorrido antes.
Isso cria uma violação de causalidade. O sistema acredita na etiqueta de tempo (timestamp), não na física.
A Mecânica do Desastre: Algoritmos de Consenso e Clock Skew
A maioria dos sistemas de storage modernos utiliza algoritmos de consenso como Raft, Paxos ou variantes (como o ZAB do ZooKeeper) para gerenciar o estado do cluster e eleger líderes. Esses algoritmos dependem criticamente de Timeouts e Leases.
O Perigo do "Lease" Expirado
Imagine que o Nó 1 é o líder. Ele detém um "lease" (contrato) de 10 segundos. Ele promete renovar esse lease a cada 5 segundos.
O Nó 1 acredita que passaram-se 4 segundos (baseado no seu relógio local lento).
O Nó 2 (com um relógio rápido) acredita que já se passaram 11 segundos desde a última renovação do Nó 1.
O Nó 2 declara o líder morto e inicia uma nova eleição.
O Nó 1 ainda acha que é o líder e continua processando gravações.
Nesse breve intervalo, temos dois líderes aceitando escritas. Isso é o clássico Split-Brain. Embora protocolos robustos tenham mecanismos de "fencing" (cercamento) e term numbers (épocas) para evitar isso, o clock skew severo pode induzir um estado de instabilidade onde o cluster passa mais tempo elegendo líderes do que gravando dados.
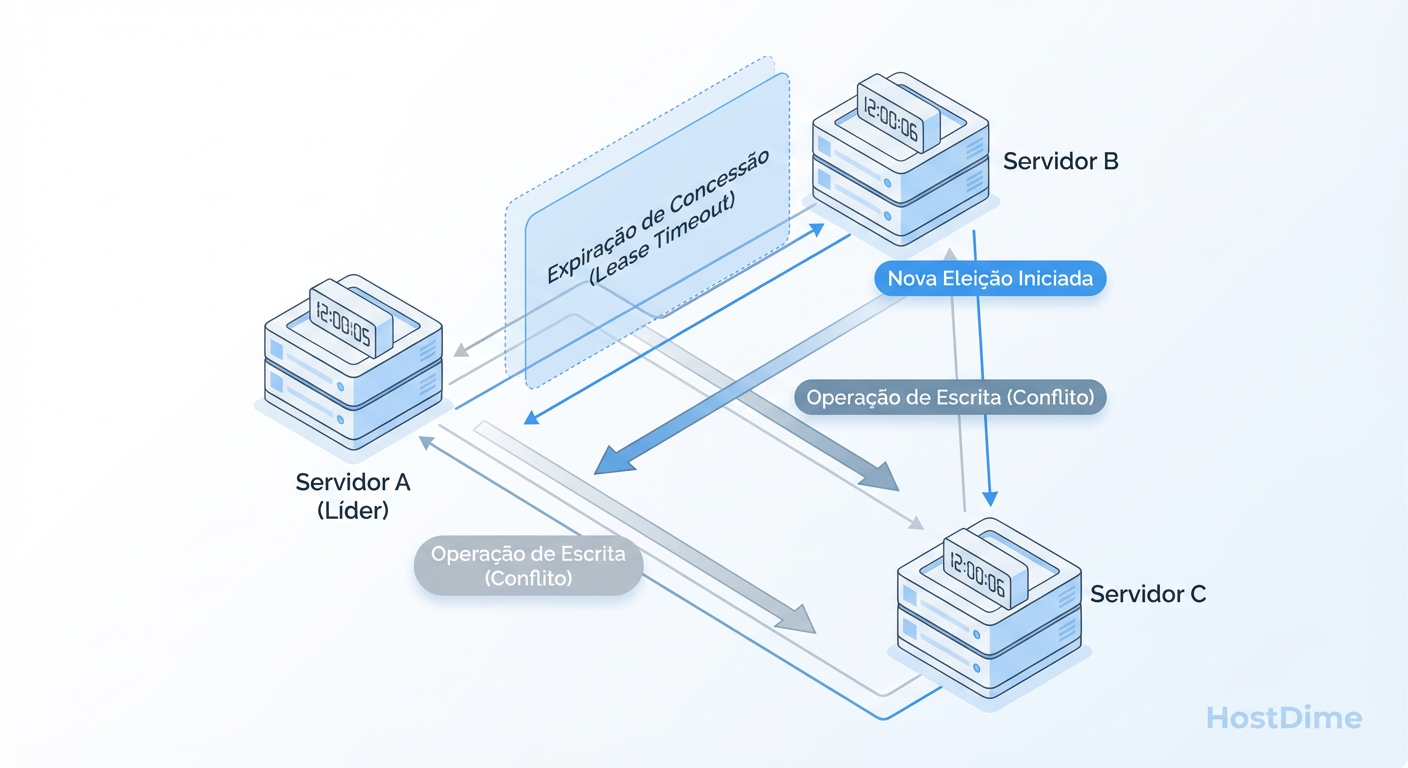 Figura: Diagrama de Falha de Consenso: Como o desvio de relógio cria cenários de duplo líder (Split-Brain) ao invalidar timeouts de lease.
Figura: Diagrama de Falha de Consenso: Como o desvio de relógio cria cenários de duplo líder (Split-Brain) ao invalidar timeouts de lease.
Last Write Wins (LWW) e a Sobrescrita Silenciosa
O cenário mais aterrorizante para um engenheiro de dados não é o cluster cair (disponibilidade), mas sim o cluster mentir (consistência). Estratégias de resolução de conflito baseadas em Last Write Wins (A Última Escrita Vence) são extremamente vulneráveis ao skew.
Considere o Amazon S3 ou o Cassandra. Se dois clientes enviam uma atualização para o mesmo objeto:
Cliente A (Relógio Certo): Envia
DATA_v2às 12:00:01.Cliente B (Relógio Atrasado 5s): Envia
DATA_v1(dado antigo) às 12:00:02 (tempo real), mas seu relógio diz 11:59:57.
O storage recebe ambos. Ele olha os timestamps.
Timestamp A: 12:00:01
Timestamp B: 11:59:57
O sistema conclui que a gravação de A é a "mais recente" e descarta a gravação de B? Ou pior: se o Cliente B tivesse o relógio adiantado, ele poderia sobrescrever o dado novo de A com um dado velho, porque o sistema acharia que a ação de B veio do futuro.
A regra de ouro: Se sua aplicação ou storage depende de LWW, você está a um desvio de relógio de corromper seu banco de dados silenciosamente.
O Pesadelo da Virtualização: Steal Time e Migrações
Rodar storage distribuído em ambientes virtualizados ou em Nuvem Pública adiciona uma camada de complexidade brutal.
As máquinas virtuais não têm cristais de quartzo; elas têm contadores de software emulados pelo hypervisor.
Steal Time: Se o host físico está sobrecarregado, ele "rouba" ciclos de CPU da sua VM. Durante esse tempo, o relógio da VM pode congelar ou saltar. Para o algoritmo de consenso, a VM "dormiu" e acordou no futuro.
Live Migration (vMotion): Quando uma VM migra de um host físico para outro, ela é pausada por milissegundos (ou segundos). Ao chegar no novo host, o relógio pode sofrer um salto abrupto para se alinhar ao novo hardware.
Esse salto repentino é devastador para bancos de dados time-series (como InfluxDB ou Prometheus) e para monitores de heartbeat de clusters.
Comparativo: Fontes de Tempo e Riscos
| Fonte de Tempo | Precisão Típica | Risco Principal | Cenário de Uso |
|---|---|---|---|
| Hardware (Quartzo) | Desvio de ~1s/dia | Drift térmico, bateria CMOS fraca | Servidores Bare-metal (base) |
| NTP (Público) | 10ms - 100ms | Latência de WAN, ataques MITM | Servidores Web, Logs não-críticos |
| NTP (Local/LAN) | < 1ms | Falha do servidor NTP local | Clusters de Storage, Databases |
| PTP (Hardware) | < 10µs (microssegundos) | Complexidade de rede (switches especiais) | Trading de Alta Frequência, Telco |
| Hypervisor Clock | Imprevisível | Steal time, Pausas de migração | VMs (requer tools de guest) |
Monitorando Drift e Latência de NTP em Produção
Não use date para verificar a hora. O comando date mostra a hora que o sistema acha que é, o que é inútil para diagnóstico. Você precisa medir a discrepância em relação à fonte da verdade.
Esqueça o systemctl status ntpd. Ele só diz se o daemon está rodando, não se o tempo está correto.
Ferramentas Reais de Diagnóstico
Se você usa Chrony (padrão na maioria das distros modernas e superior ao ntpd para ambientes instáveis), use o tracking para ver a realidade:
# Verifique o desempenho do sistema em relação à fonte
chronyc tracking
O que olhar na saída:
System time: Mostra quantos segundos o relógio do sistema está adiantado ou atrasado.
Last offset: A diferença estimada na última medição.
RMS offset: A média de longo prazo. Se este valor estiver alto (ex: > 0.05s em LAN), você tem um problema de rede ou sobrecarga de CPU.
Para ver a qualidade das suas fontes:
# Detalhes das fontes de tempo (NTP servers)
chronyc sources -v
Procure pelo símbolo * (fonte atual sincronizada) e ? (fontes inalcançáveis). O valor na coluna LastRx (tempo desde a última recepção) deve ser baixo.
O "Pulo do Gato" no Monitoramento
Configure seu sistema de monitoramento (Prometheus/Zabbix) para alertar não apenas quando o NTP cai, mas quando o offset excede um limiar seguro.
Para Ceph: Alerta se offset > 50ms.
Para Logs gerais: Alerta se offset > 500ms.
Estratégias de Mitigação e Configuração
Não confie no padrão da distribuição. Para storage distribuído, você precisa de uma configuração agressiva de tempo.
1. Use Chrony em vez de NTPd
O Chrony converge mais rápido e lida muito melhor com mudanças súbitas de frequência de clock e interrupções de rede. Ele é desenhado para funcionar bem até em VMs instáveis.
2. Configure o "Slew" vs. "Step"
Quando o relógio está errado, você tem duas opções:
Step: Mudar a hora imediatamente. (Risco: Logs saltam, cron jobs falham ou rodam duas vezes).
Slew: Acelerar ou desacelerar o relógio suavemente até ele alcançar a hora certa.
Para storage, Slew é geralmente preferível para pequenos desvios, pois mantém a monotonicidade do tempo. No entanto, se o desvio for enorme (ex: boot da máquina), o Step é necessário.
No chrony.conf:
# Permite step (salto) apenas nos primeiros 3 updates do clock se o erro for > 1s
makestep 1.0 3
3. Use Relógios Monotônicos no Código (Para Desenvolvedores/DevOps)
Se você escreve scripts ou ferramentas que medem duração, nunca use Wall Clock (ex: Time.now()). O usuário pode mudar a hora, ou o NTP pode fazer um "step" para trás.
Use Monotonic Clocks (ex: CLOCK_MONOTONIC no Linux, time.monotonic() no Python). Eles garantem que o tempo sempre avance e são imunes a ajustes de NTP. Eles não dizem "que horas são", mas medem "quanto tempo passou" com precisão.
4. Hardware Timestamping (PTP)
Se você opera em um ambiente onde microssegundos importam (NVMe-oF de altíssimo desempenho), NTP não é suficiente. Considere PTP (Precision Time Protocol). Isso requer suporte da placa de rede e do switch, permitindo que o timestamp seja gerado no hardware da NIC, eliminando a latência do kernel e interrupções do SO.
Veredito Técnico: O Ceticismo Salva Dados
O tempo não é garantido. Em sistemas distribuídos, assuma sempre que os relógios estão desincronizados. Projete sua infraestrutura para tolerar o skew, monitore o offset obsessivamente e nunca, jamais, confie cegamente em um timestamp para resolver conflitos de dados críticos sem entender a topologia do seu tempo.
A consistência dos seus dados depende de você tratar o tempo como uma variável hostil, não como um serviço público garantido.
Referências & Leitura Complementar
Leslie Lamport (1978): "Time, Clocks, and the Ordering of Events in a Distributed System" - O paper fundamental que explica por que relógios físicos não são confiáveis para ordenação.
Google Spanner Whitepaper: "TrueTime API" - Como o Google usa relógios atômicos e GPS para criar limites de erro conhecidos e garantir consistência global.
Jepsen Analysis: Diversos relatórios de Kyle Kingsbury demonstrando como bancos de dados famosos perdem dados devido a clock skew (Ex: MongoDB, Cassandra).
RFC 5905: Network Time Protocol Version 4: Protocol and Algorithms Specification.
Red Hat Enterprise Linux: "Configuring NTP Using the chrony Suite".

Roberto Holanda
Guru de Sistemas de Arquivos (ZFS/Btrfs)
"Dedico minha carreira à integridade dos dados. Para mim, o bit rot é o inimigo e o Copy-on-Write é a salvação. Exploro a fundo ZFS, Btrfs e a beleza dos checksums."