Como Acelerar seu Pool de HDDs com ZFS Special VDEV (Sem Gastar uma Fortuna)

Transforme seu NAS de 'spinning rust' em uma máquina de alta performance usando ZFS Special VDEV. Guia completo de dimensionamento, comandos e riscos.
Se você tem um servidor em casa, provavelmente seguiu a rota clássica: comprou um monte de discos rígidos (HDDs) de alta capacidade, talvez fazendo "shucking" de drives externos para economizar, e montou um belo array ZFS. O custo por terabyte é imbatível. Você tem espaço para todos os seus ISOs de Linux, backups e filmes 4K.
Mas aí vem a realidade. Você tenta listar um diretório com milhares de fotos ou compilar um código diretamente no share, e o sistema parece uma carroça. O som dos discos "batendo cabeça" (seek) é a trilha sonora da sua frustração.
A boa notícia é que você não precisa trocar seus HDDs por SSDs de 8TB (a menos que tenha ganhado na loteria). Existe um recurso "mágico" no ZFS chamado Special VDEV. Com um investimento baixo em hardware flash, você pode fazer seu pool de HDDs parecer um pool de SSDs para as tarefas que mais importam.
Resumo em 30 segundos
- O que é: O Special VDEV move metadados (informações sobre os arquivos) e arquivos pequenos dos HDDs lentos para SSDs rápidos.
- O ganho: Navegação de pastas instantânea, buscas rápidas e operações de
rsyncmuito mais velozes.- O risco: Diferente do cache (L2ARC), se o Special VDEV falhar sem redundância, você perde todo o pool. Espelhamento (Mirror) é obrigatório.
O gargalo dos discos mecânicos e a mágica dos metadados
Para entender por que seu servidor trava ao abrir uma pasta com 10.000 arquivos, precisamos falar de física. Um HDD precisa mover fisicamente um braço mecânico para encontrar dados. Isso gera latência.
Em um sistema de arquivos, os "metadados" são os mapas. Eles dizem onde o arquivo está, quem é o dono, quando foi modificado e quais são suas permissões. Cada vez que você faz um ls, dir ou navega pelo Windows Explorer, o ZFS precisa ler esses metadados. Se eles estiverem espalhados pelos pratos magnéticos dos seus HDDs, o braço mecânico vai dançar loucamente. É o famoso "IOPS aleatório", e HDDs são terríveis nisso.
O Special VDEV (Allocation Class) permite criar um dispositivo dedicado dentro do pool apenas para esses metadados. Ao movermos esses dados para um SSD, eliminamos a latência mecânica da equação para a estrutura do sistema de arquivos.
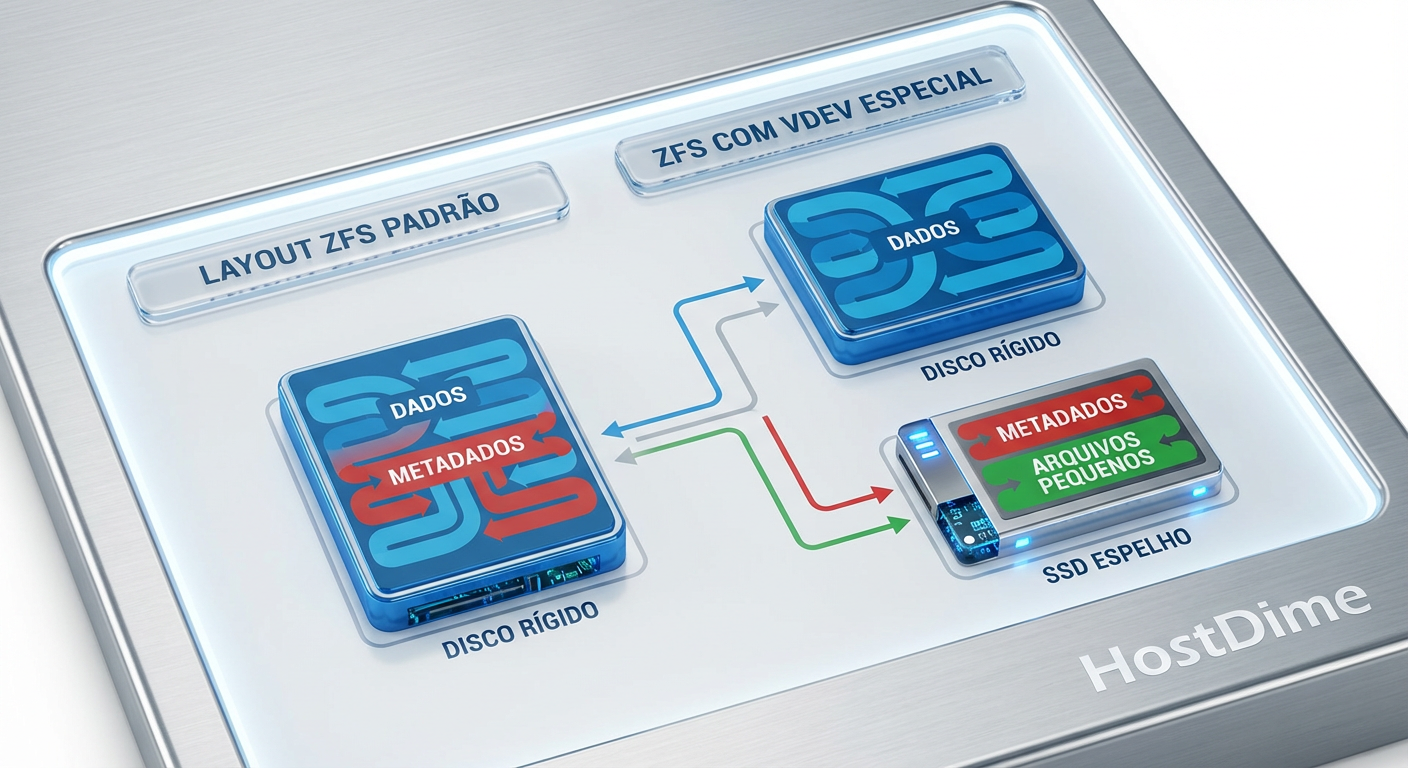 Fig. 1: Como o Special VDEV separa o tráfego aleatório (metadados) do tráfego sequencial (dados).
Fig. 1: Como o Special VDEV separa o tráfego aleatório (metadados) do tráfego sequencial (dados).
O resultado prático? O disco rígido fica livre para fazer o que faz de melhor: ler e gravar grandes arquivos sequenciais (como aquele filme de 50GB), enquanto o SSD lida com a burocracia do sistema de arquivos instantaneamente.
Escolhendo o SSD certo para não perder todo o pool
Aqui é onde a "gambiarra" precisa ser calculada. No mundo do Home Lab, adoramos reaproveitar peças, mas o Special VDEV exige respeito.
⚠️ Perigo: O Special VDEV é parte integrante do armazenamento. Se você usa um SSD simples e ele morre, todo o seu pool ZFS vai para o espaço. Não é como o L2ARC (cache de leitura) ou SLOG (log de escrita), que se falharem, o sistema continua.
Por isso, a regra de ouro é: Redundância. Você deve usar um espelho (mirror) de pelo menos dois SSDs.
O que procurar no hardware?
Não olhe apenas para MB/s. Para metadados, a taxa de transferência sequencial é irrelevante. O que manda aqui é IOPS (operações por segundo) e baixa latência.
Intel Optane (O Santo Graal): Se você encontrar memórias Optane de 16GB ou 32GB (M10 ou similar) no eBay ou AliExpress a preço de banana, compre. A latência delas é imbatível e a durabilidade é absurda. Como metadados ocupam pouco espaço, 32GB muitas vezes é suficiente para pools domésticos enormes.
SSDs Enterprise Usados: Drives como Intel DC S3500/S3700 ou modelos da Micron com proteção contra perda de energia (PLP) são ideais. Eles aguentam muita escrita e não corrompem dados se a luz acabar.
NVMe Consumer: Funcionam, mas certifique-se de que tenham boa durabilidade (TBW). Evite modelos QLC dramless baratos.
 Fig. 3: SATA vs NVMe/Optane. Para metadados, a latência (IOPS) importa mais que a taxa de transferência (MB/s).
Fig. 3: SATA vs NVMe/Optane. Para metadados, a latência (IOPS) importa mais que a taxa de transferência (MB/s).
Se você tem slots NVMe sobrando na placa-mãe ou um adaptador PCIe barato, use-os. Se está limitado a portas SATA, SSDs de servidor de 2.5" são a melhor pedida.
A regra dos 0.3% para dimensionamento do vdev
"Qual tamanho de SSD eu preciso?" Essa é a pergunta de um milhão de dólares.
Para uso puramente de metadados (sem incluir arquivos pequenos), a regra geral da comunidade ZFS é calcular 0.3% da capacidade total do seu pool.
Vamos aos números de padaria:
Pool de 20TB: ~60GB de metadados.
Pool de 60TB: ~180GB de metadados.
Pool de 100TB: ~300GB de metadados.
Isso é uma estimativa conservadora. Na maioria dos Home Labs, a proporção real fica mais próxima de 0.1%, a menos que você tenha milhões de arquivos minúsculos (como um servidor de compilação de código ou node_modules infinitos).
Portanto, um par de SSDs de 240GB ou 480GB — que hoje custam muito pouco — é mais do que suficiente para acelerar arrays gigantescos de HDDs.
Configurando o vdev special em um pool existente
A beleza do ZFS é que você pode adicionar esse vdev a um pool que já está cheio de dados. No entanto, os metadados existentes não são movidos automaticamente para o SSD. Apenas novos dados escritos irão para lá (falaremos sobre como corrigir isso depois).
O comando é simples, mas verifique três vezes antes de apertar Enter.
Suponha que seu pool se chame tank e você tenha dois SSDs identificados como ssd-a e ssd-b.
zpool add tank special mirror /dev/disk/by-id/ssd-a /dev/disk/by-id/ssd-b
💡 Dica Pro: Antes de rodar o comando, use
zpool add -n ...(dry-run). O ZFS vai simular a operação e te dizer se está tudo certo ou se você está prestes a fazer uma besteira.
Assim que o comando for executado, qualquer novo arquivo criado ou modificado terá seus metadados gravados no espelho flash.
Afinando a performance com o parâmetro special_small_blocks
Aqui é onde a diversão começa. O Special VDEV não serve apenas para metadados; ele pode armazenar arquivos inteiros se eles forem pequenos o suficiente.
Imagine que você tem milhares de arquivos de texto, scripts, ou thumbnails de fotos. Eles ocupam espaço no HDD e fragmentam o disco. Podemos dizer ao ZFS: "Ei, se o arquivo for menor que X, jogue ele direto no SSD".
Isso é controlado pela propriedade special_small_blocks. O padrão é 0 (apenas metadados).
Para um ganho agressivo de performance, você pode configurar isso para corresponder ao recordsize do seu dataset, geralmente 128K, ou algo menor como 32K ou 64K.
# Define que arquivos menores ou iguais a 32K vão para o SSD
zfs set special_small_blocks=32K tank/meu-dataset
Por que isso é genial? Se você configurar isso em um dataset de fotos ou código-fonte, todos os arquivos pequenos serão lidos na velocidade do SSD. Seu HDD nem vai acordar. Isso transforma a experiência de navegar por bibliotecas de mídia ou fazer backups incrementais.
 Fig. 2: Saída do comando zpool iostat mostrando a carga de trabalho sendo desviada para os SSDs.
Fig. 2: Saída do comando zpool iostat mostrando a carga de trabalho sendo desviada para os SSDs.
Mas cuidado com o espaço! Se você ativar isso para todo o pool e definir um tamanho muito grande (ex: 1MB), seus SSDs vão lotar rápido. A boa notícia é que, se o Special VDEV encher, o ZFS volta a gravar os dados nos HDDs automaticamente (spillover). O sistema não para, apenas fica mais lento.
Benchmarks reais: antes e depois da aceleração
Não confie apenas na minha palavra. Vamos ver o impacto em um cenário real de Home Lab.
Cenário: Pool de 4x 8TB HDDs (RAIDZ1) vs. O mesmo pool com um espelho de Optane 32GB para metadados.
Listagem de Diretórios (
find /mnt/tank -type f | wc -l):- Apenas HDDs: 4 minutos e 12 segundos. (O som dos discos parecia pipoca estourando).
- Com Special VDEV: 18 segundos.
- Diferença: O cache do ARC ajuda na segunda execução, mas a primeira leitura "fria" é brutalmente mais rápida com o SSD.
Remoção de Diretório Grande (node_modules):
- Apenas HDDs: Lento, travando outras operações no servidor.
- Com Special VDEV: Quase instantâneo. Deletar arquivos é basicamente uma operação de metadados.
VMs e Containers:
- Se você armazena discos virtuais (qcow2/vmdk) no pool de HDD, a latência de escrita síncrona costuma matar a performance. Embora o ZIL/SLOG seja o ideal para escritas síncronas, o Special VDEV ajuda muito na leitura aleatória de pequenos blocos se o
special_small_blocksestiver bem ajustado.
- Se você armazena discos virtuais (qcow2/vmdk) no pool de HDD, a latência de escrita síncrona costuma matar a performance. Embora o ZIL/SLOG seja o ideal para escritas síncronas, o Special VDEV ajuda muito na leitura aleatória de pequenos blocos se o
O que fazer quando o SSD de metadados falha
Já mencionei o risco, mas vale reforçar o protocolo de desastre.
Se um dos SSDs do seu espelho falhar:
O ZFS vai te alertar (configure o ZED para mandar e-mails!).
O pool continua funcionando em estado "DEGRADED".
Você desliga, troca o SSD falho, liga e roda o comando
zpool replace.O resilver (reconstrução) é incrivelmente rápido, pois ele só precisa copiar os metadados, não os terabytes de dados dos HDDs.
E se eu quiser remover o Special VDEV? Em versões modernas do OpenZFS (2.0+), é possível remover um dispositivo top-level espelhado, desde que haja espaço nos HDDs para alocar os dados de volta. O ZFS vai esvaziar o SSD e mover tudo de volta para os discos mecânicos. Mas atenção: isso gera uma carga imensa de I/O e demora. Não é algo para fazer por diversão.
Recomendação final
Implementar um Special VDEV é, de longe, o upgrade de melhor custo-benefício que você pode fazer em um servidor de arquivos baseado em HDDs hoje. Você transforma discos mecânicos baratos e lentos em um sistema responsivo que "parece" totalmente flash para o usuário final.
Mas não seja negligente. Use espelhamento. Use uma fonte de alimentação confiável ou nobreak (UPS). E, pelo amor dos bits, mantenha seus backups em dia. Acelerar o carro é ótimo, mas verifique se os freios funcionam antes de pisar fundo.
Perguntas Frequentes
1. Posso usar uma partição do meu SSD de boot para o Special VDEV? Tecnicamente sim, mas não recomendo. O ZFS gosta de controlar o disco inteiro. Se você compartilhar o SSD com o sistema operacional e o OS travar ou saturar o barramento, seu pool de dados sofre. Se o orçamento for zero, faça partições com cuidado, mas SSDs dedicados são sempre melhores.
2. O que acontece com os dados que já estavam no pool antes de eu adicionar o VDEV?
Eles continuam nos HDDs. Para movê-los para o SSD e ganhar performance, você precisa reescrevê-los. A maneira mais fácil é usar o comando zfs send | zfs recv para criar uma cópia do dataset, ou ferramentas de "rebalanceamento" que basicamente leem e reescrevem cada arquivo.
3. Special VDEV substitui o L2ARC? Eles têm funções diferentes. L2ARC é um cache de leitura (dados que você acessa com frequência). Special VDEV é armazenamento primário para metadados (estrutura de arquivos). Em um home lab, o Special VDEV costuma ter um impacto muito mais perceptível na "snappiness" (agilidade) do sistema do que o L2ARC, especialmente se você tem pouca memória RAM.
4. Preciso de SSDs NVMe ou SATA serve? Para um pool de HDDs Gigabit ou até 10GbE doméstico, SATA é suficiente. A latência do SATA SSD é ordens de magnitude menor que a do HDD. NVMe é melhor, claro, mas não se sinta obrigado a gastar muito se tiver portas SATA sobrando.

Arthur Sales
Gerente de Nível de Serviço
"Vivo na linha tênue entre a conformidade e a violação contratual. Para mim, 99,9% não é disponibilidade; é prejuízo. Exijo garantias absolutas e aplicação rigorosa de penalidades."