Como configurar um cluster Ceph no Proxmox VE: Guia Definitivo

Aprenda a construir uma infraestrutura hiperconvergente (HCI) com Proxmox e Ceph Reef. Guia passo a passo: rede 10GbE, OSDs NVMe e otimização de performance.
A integração nativa do Ceph com o Proxmox VE transformou a maneira como pequenas e médias empresas, bem como entusiastas de homelab, abordam a infraestrutura hiperconvergente (HCI). Ao eliminar a necessidade de um SAN (Storage Area Network) dedicado e caro, o Ceph permite utilizar o armazenamento local de cada servidor para criar um pool distribuído, resiliente e escalável.
No entanto, a facilidade de clicar em "Instalar" na interface do Proxmox esconde complexidades arquiteturais que, se ignoradas, resultam em performance medíocre e risco de perda de dados. Este guia detalha o processo de implementação de um cluster Ceph Reef (versão padrão no Proxmox VE 8), focando nas melhores práticas de hardware e configuração de rede.
Resumo em 30 segundos
- Regra de Ouro: Um cluster Ceph saudável exige no mínimo 3 nós para garantir quórum e proteção de dados adequada.
- Rede é Gargalo: Jamais utilize a mesma interface de rede para tráfego de VM e replicação de dados do Ceph. Separe fisicamente ou via VLANs, preferencialmente com 10GbE ou superior.
- Discos: Controladoras RAID de hardware são proibidas. Seus discos devem estar em modo HBA/IT Mode (acesso direto) para que o Ceph gerencie a integridade dos dados.
1. Arquitetura e Requisitos de Hardware
Antes de digitar qualquer comando, é preciso validar se o "ferro" suporta a carga. O Ceph é um sistema de armazenamento definido por software (SDS) que consome recursos de CPU e RAM para gerenciar a replicação e a integridade dos dados em tempo real.
O Papel do Ceph na Hiperconvergência
Em um setup tradicional, você tem servidores de computação e um storage separado. Na hiperconvergência com Proxmox + Ceph, cada nó do cluster contribui com CPU, RAM e Discos. O Ceph distribui os dados em blocos (Objects) através dos OSDs (Object Storage Daemons). Se um disco ou um servidor inteiro falhar, o dado continua acessível através das réplicas nos outros nós.
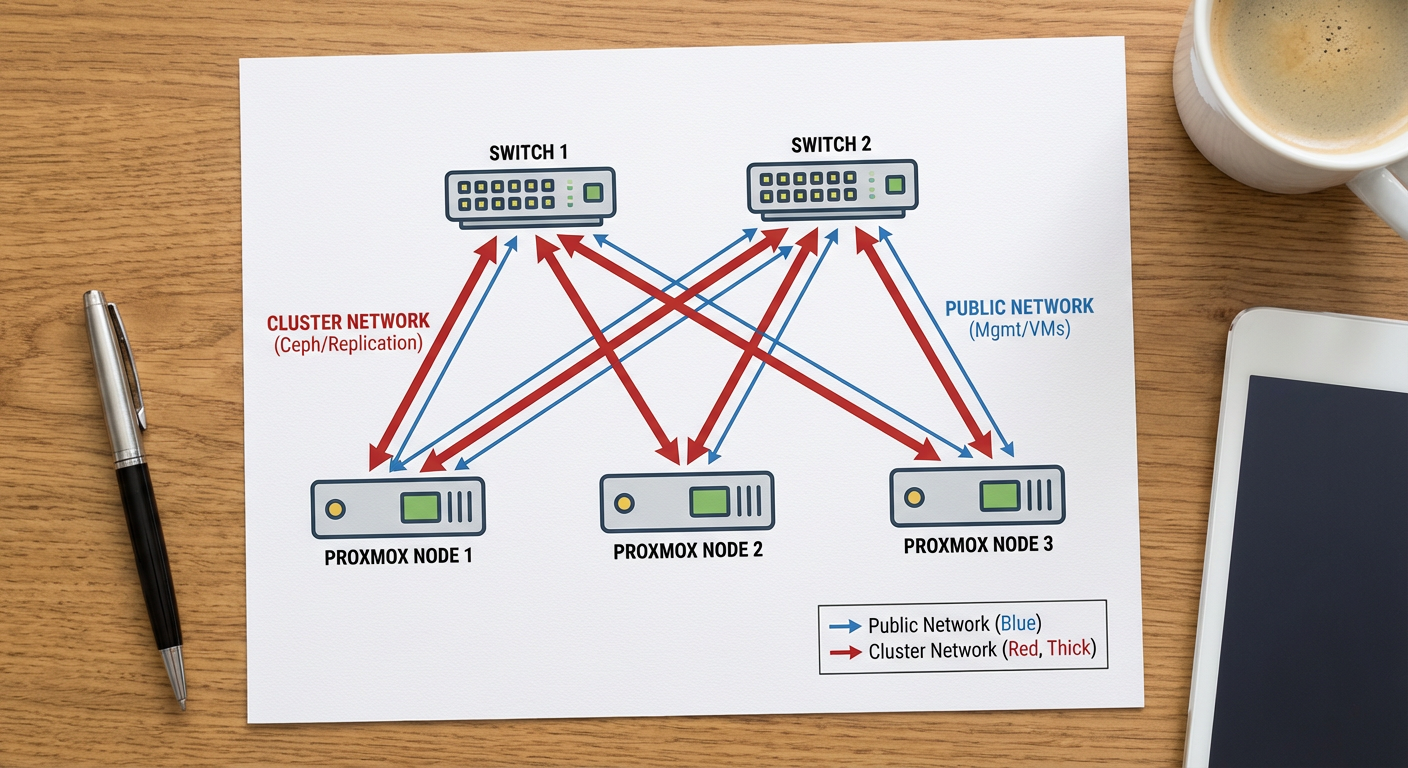 Figura: Topologia recomendada: Separação física entre tráfego público e tráfego de replicação (backend).
Figura: Topologia recomendada: Separação física entre tráfego público e tráfego de replicação (backend).
Checklist de Hardware Crítico
CPU: O Ceph gosta de clocks altos. Cada OSD (disco) pode consumir de 1 a 2 threads de CPU sob carga pesada.
Memória RAM: Reserve 1GB de RAM para cada 1TB de armazenamento bruto, mais 2GB base para o sistema Ceph. Isso é além do que suas VMs precisam.
Rede (O Fator Decisivo):
- Latência: O Ceph é síncrono. A gravação só é confirmada quando replicada. Redes lentas = VMs lentas.
- Largura de Banda: 1GbE é aceitável apenas para testes ou clusters muito pequenos com HDDs. Para produção com SSDs/NVMe, 10GbE é o mínimo obrigatório para a rede de backend (Cluster Network).
Discos (Enterprise vs Consumer):
- Evite SSDs de consumo (QLC/TLC sem DRAM cache) para o Ceph. A amplificação de escrita do Ceph destruirá a vida útil (TBW) desses discos rapidamente e a performance de escrita cairá drasticamente.
- Prefira SSDs "Mixed Use" ou "Read Intensive" de classe Enterprise com proteção contra perda de energia (PLP).
⚠️ Perigo: Nunca use controladoras RAID (PERC, SmartArray) em modo RAID 0, 1, 5, etc. O Ceph precisa de acesso direto ao disco (SMART, instruções de flush). Configure sua controladora para HBA / IT Mode / Passthrough.
2. Instalação dos Pacotes Ceph Reef
O Proxmox VE 8 facilita a instalação através da interface gráfica, mas entender o que acontece nos bastidores é essencial. O processo deve ser repetido em todos os nós do cluster.
Acesse a interface web do Proxmox.
Selecione o nó no menu lateral esquerdo.
Navegue até Ceph na coluna central.
Você verá um aviso de que o Ceph não está instalado. Clique em Install Ceph.
O assistente solicitará a versão. Para Proxmox VE 8, a escolha padrão é o Ceph Reef (18.2).
Se preferir a precisão do terminal (ou para automação), execute em cada nó:
pveceph install
Após a instalação dos pacotes, o assistente de configuração inicial será aberto.
3. Configuração de Rede: Public vs Cluster
Esta é a etapa onde a maioria dos administradores falha. O assistente pedirá para definir as redes.
Public Network: Usada pelos clientes (VMs, Containers) para acessar os dados e pelos Monitores (MONs) para comunicação.
Cluster Network: Usada exclusivamente pelos OSDs para replicar dados (Heartbeat e Rebalancing).
Por que separar? Quando um OSD falha e precisa ser reconstruído (recovery), o tráfego de dados é massivo. Se isso compartilhar o mesmo cabo da rede das VMs, suas aplicações vão travar devido ao congestionamento.
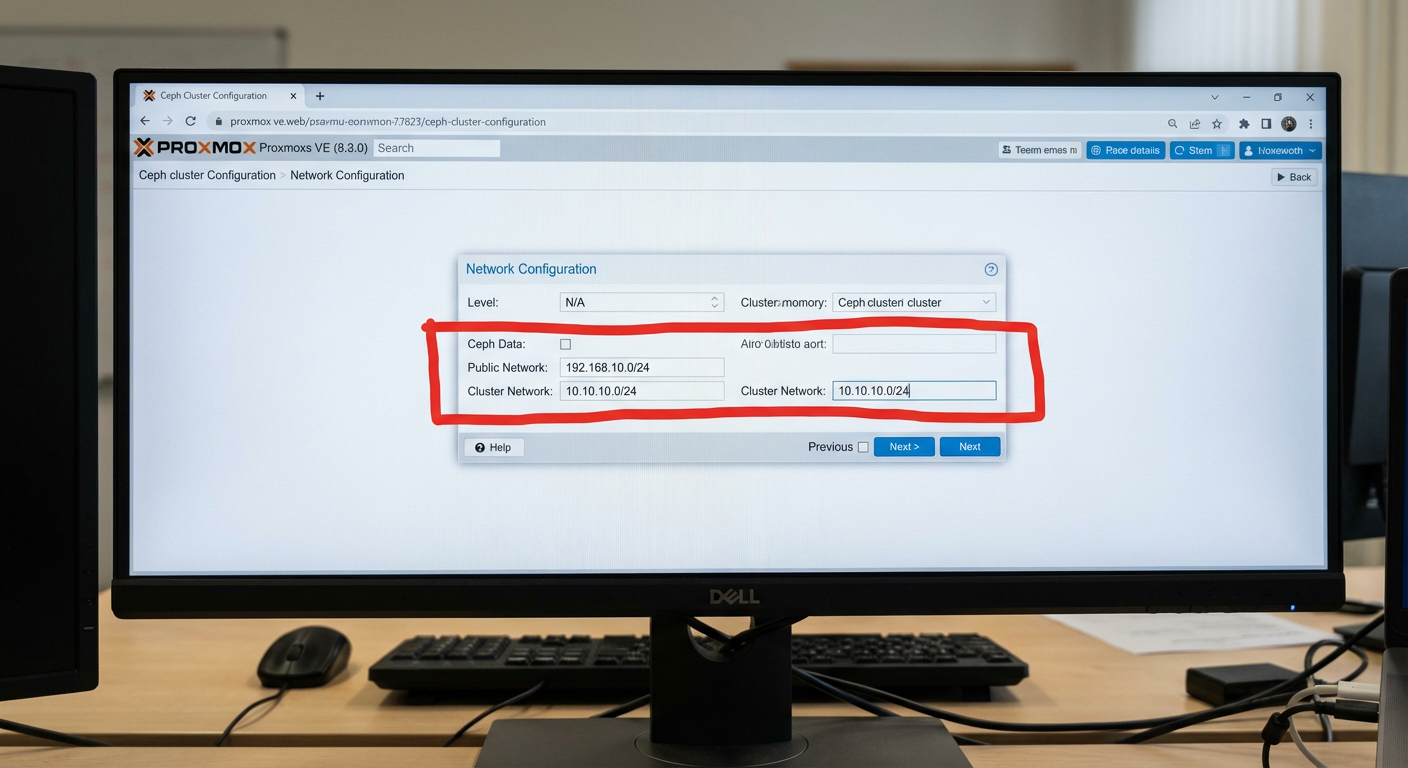 Figura: Configuração de redes distintas para evitar gargalos de performance durante a recuperação de dados.
Figura: Configuração de redes distintas para evitar gargalos de performance durante a recuperação de dados.
Exemplo de Configuração:
Public:
192.168.1.0/24(Interfacevmbr0- 1GbE)Cluster:
10.10.50.0/24(Interfaceenp1s0- 10GbE DAC direto ou Switch dedicado)
Se você possui apenas uma interface de rede física (não recomendado), configure ambas as redes para o mesmo CIDR, mas esteja ciente das limitações de performance.
4. Monitores (MON) e Managers (MGR)
O Monitor (MON) mantém o mapa do cluster. Sem quórum de monitores, o cluster para (entra em modo read-only ou bloqueia). O Manager (MGR) lida com métricas, dashboard e orquestração.
Regra do Quórum
Você precisa de um número ímpar de monitores para evitar situações de "split-brain".
1 Nó: 1 Monitor (Risco alto, apenas teste).
3 Nós: 3 Monitores (Padrão de produção).
5+ Nós: 3 a 5 Monitores.
Na interface do Proxmox, após a configuração de rede, o primeiro monitor será criado automaticamente no nó onde você está rodando o assistente.
Para criar os monitores restantes:
Vá em Ceph > Monitor.
Clique em Create.
Selecione os outros nós do cluster.
💡 Dica Pro: Mantenha sempre 3 monitores, mesmo que seu cluster tenha 10 nós. Mais monitores aumentam a latência de escrita do mapa do cluster sem trazer benefícios significativos de redundância.
5. Provisionamento de OSDs (Object Storage Daemons)
Agora vamos transformar os discos físicos em armazenamento Ceph. O Proxmox usa o ceph-volume com LVM para gerenciar os discos.
Navegue até Ceph > OSD.
Clique em Create: OSD.
Na janela que se abre:
- Disk: Selecione o disco físico (ex:
/dev/sdb). - DB/WAL Disk: Se você estiver usando HDDs mecânicos (spinners), é altamente recomendado usar um SSD/NVMe rápido para armazenar o DB (Database) e o WAL (Write Ahead Log). Isso acelera drasticamente a performance. Se estiver usando um cluster "All-Flash" (só SSDs), deixe este campo vazio (o DB/WAL ficará no mesmo disco).
- Encryption: Opcional. Adiciona overhead de CPU. Use apenas se houver requisito legal de segurança.
- Disk: Selecione o disco físico (ex:
 Figura: Estratégia de DB/WAL: Acelerar HDDs mecânicos usando uma partição de NVMe para metadados é uma prática comum para ganho de IOPS.
Figura: Estratégia de DB/WAL: Acelerar HDDs mecânicos usando uma partição de NVMe para metadados é uma prática comum para ganho de IOPS.
Repita o processo para todos os discos em todos os nós.
Verificação via Terminal: Após criar os OSDs, verifique a árvore do cluster para garantir que estão distribuídos corretamente:
ceph osd tree
A saída deve mostrar seus nós (host) e os discos (osd.0, osd.1, etc.) aninhados abaixo deles com status up e in.
6. Pools e Regras de Réplica
O armazenamento bruto está pronto. Agora precisamos criar "Pools" lógicos para as VMs consumirem.
Vá em Ceph > Pools.
Clique em Create.
Name: Geralmente algo como
rbd-vms.Size: O padrão é 3/2.
- Size (3): O dado será gravado 3 vezes (1 original + 2 cópias).
- Min. Size (2): O cluster aceita escrita desde que consiga gravar pelo menos 2 cópias. Se cair para 1, a escrita bloqueia para evitar perda de dados (split-brain).
PG Autoscale Mode: Deixe em on. O Ceph moderno calcula automaticamente o número de Placement Groups (PGs) baseado no uso.
⚠️ Perigo: Nunca defina
Size=2eMin_Size=1em produção. Se um disco falhar durante a recuperação de outro, você perderá dados permanentemente e corromperá o pool inteiro. O custo de armazenamento (33% de eficiência) é o preço da alta disponibilidade.
7. Validação de Performance e Troubleshooting
Não coloque VMs em produção sem antes estressar o storage. O Proxmox já traz as ferramentas necessárias.
Benchmark Sintético
Use o rados bench para testar a velocidade bruta do cluster (sem a camada de virtualização do KVM atrapalhando).
Teste de Escrita (10 segundos):
rados bench -p rbd-vms 10 write --no-cleanup
Observe o valor de "Average Latency". Para SSDs, deve estar abaixo de 2-5ms. Para HDDs, abaixo de 50ms.
Teste de Leitura:
rados bench -p rbd-vms 10 seq
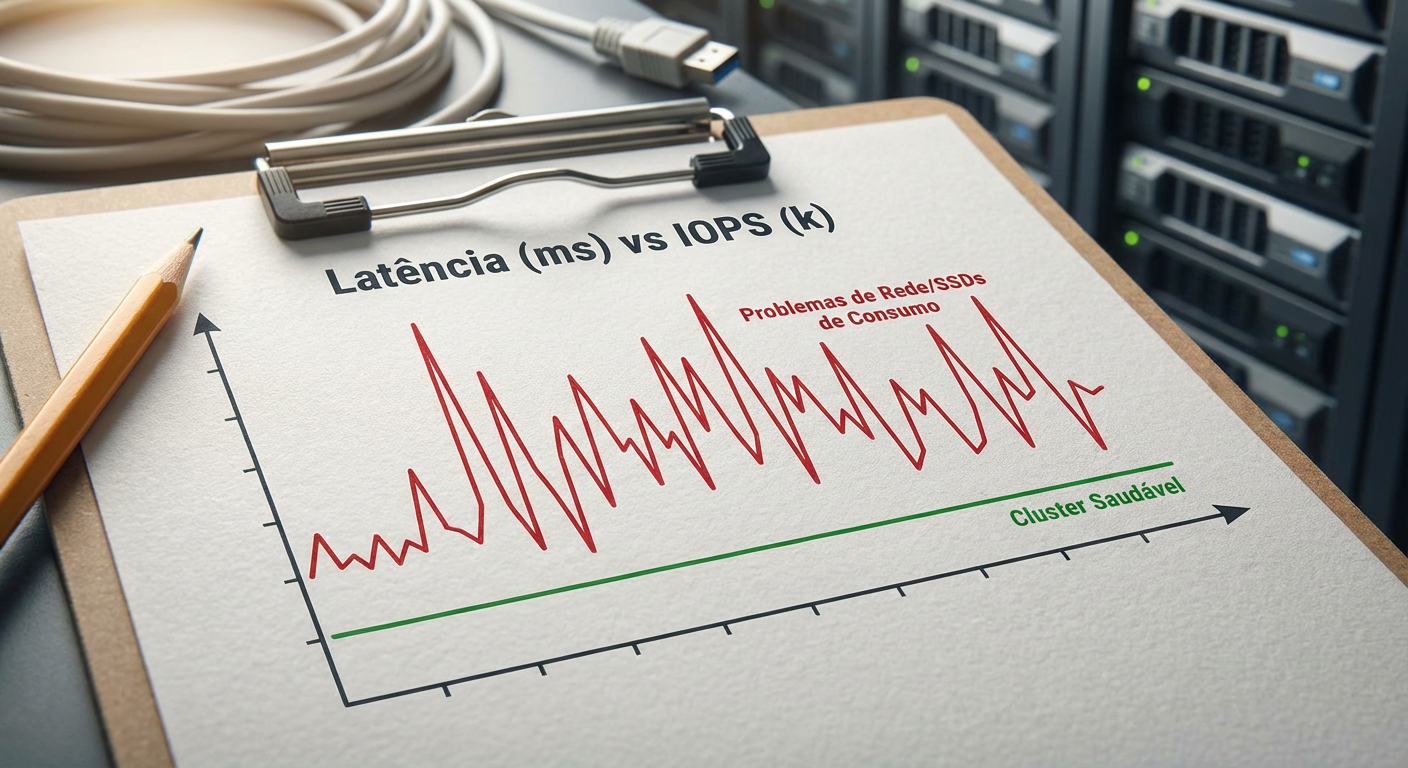 Figura: Monitoramento de latência: O indicador vital da saúde do seu storage. Picos acima de 100ms indicam gargalos severos.
Figura: Monitoramento de latência: O indicador vital da saúde do seu storage. Picos acima de 100ms indicam gargalos severos.
Problemas Comuns
PGs in "degraded" state:
- Isso é normal se um nó foi reiniciado. O Ceph está verificando se os dados estão sincronizados.
- Se persistir, verifique a rede do cluster.
Latência Alta (Slow Ops):
- Verifique se algum disco está morrendo (
dmesg | grep sdX). - Verifique se a rede de cluster está saturada.
- Confirme se não há Clock Skew (diferença de horário) entre os nós. Instale e configure o
chronyountp.
- Verifique se algum disco está morrendo (
OSD Down:
- Tente reiniciar o serviço:
systemctl restart ceph-osd@<id>. - Se falhar, verifique os logs em
/var/log/ceph/. Geralmente indica falha física do disco.
- Tente reiniciar o serviço:
Próximos Passos e Manutenção
Configurar o Ceph no Proxmox é apenas o "Dia 1". Para o "Dia 2" e além, sua atenção deve se voltar para o monitoramento contínuo. Configure alertas de e-mail no Proxmox para falhas de disco e monitore a saúde dos SSDs (Wearout level).
Lembre-se que o Ceph é um sistema vivo. Ele se cura (self-healing) e se rebalanceia. Sua função não é microgerenciar onde cada bit está gravado, mas garantir que a infraestrutura subjacente — rede limpa, energia estável e discos saudáveis — permita que ele faça seu trabalho. Se você planeja crescer, adicione nós e discos gradualmente; o Ceph cuidará de redistribuir os dados sem downtime.

Roberto Xavier
Comandante de Incidentes
"Lidero equipes em momentos críticos de infraestrutura. Priorizo a restauração rápida de serviços e promovo uma cultura de post-mortem sem culpa para construir sistemas mais resilientes."