Comparando Arrays de Armazenamento: Metodologia Científica para Evitar Benchmarks de Marketing

Desmistifique os números de IOPS de folhetos comerciais. Aprenda uma metodologia rigorosa para testar arrays de armazenamento, focando em latência, consistência e estado estável.
A indústria de armazenamento corporativo sofre de uma epidemia crônica de ofuscação. Folhetos de marketing prometem "milhões de IOPS" e "latência de microssegundos" com asteriscos tão pequenos que exigem um microscópio eletrônico para serem lidos. Como engenheiros e arquitetos de sistemas, não podemos nos dar ao luxo de projetar infraestrutura crítica baseada em números de pico (burst) obtidos em cenários ideais.
A realidade física do silício NAND e dos controladores de armazenamento impõe limites que nenhum departamento de marketing pode ignorar. Este artigo detalha uma metodologia rigorosa e reproduzível para avaliar arrays de armazenamento (All-Flash e NVMe), focando no isolamento de variáveis e na busca pela verdade do Estado Estável (Steady State).
A Falácia do "Hero Number": Por que IOPS de Marketing são Irrelevantes
O erro mais comum em aquisições de armazenamento é a fixação no "Hero Number" — o valor máximo teórico que um array pode atingir. Geralmente, este número é obtido através de:
Leitura 100% aleatória (ou sequencial, o que for maior).
Tamanho de bloco minúsculo (4KB ou 512B).
Queue Depth (QD) absurdamente alta para saturar o controlador.
Um intervalo de tempo curto o suficiente para nunca estourar o cache de escrita (DRAM ou SLC Cache).
No mundo real, cargas de trabalho são mistas. Bancos de dados transacionais, VDI (Virtual Desktop Infrastructure) e pipelines de CI/CD não operam em condições de laboratório estéreis.
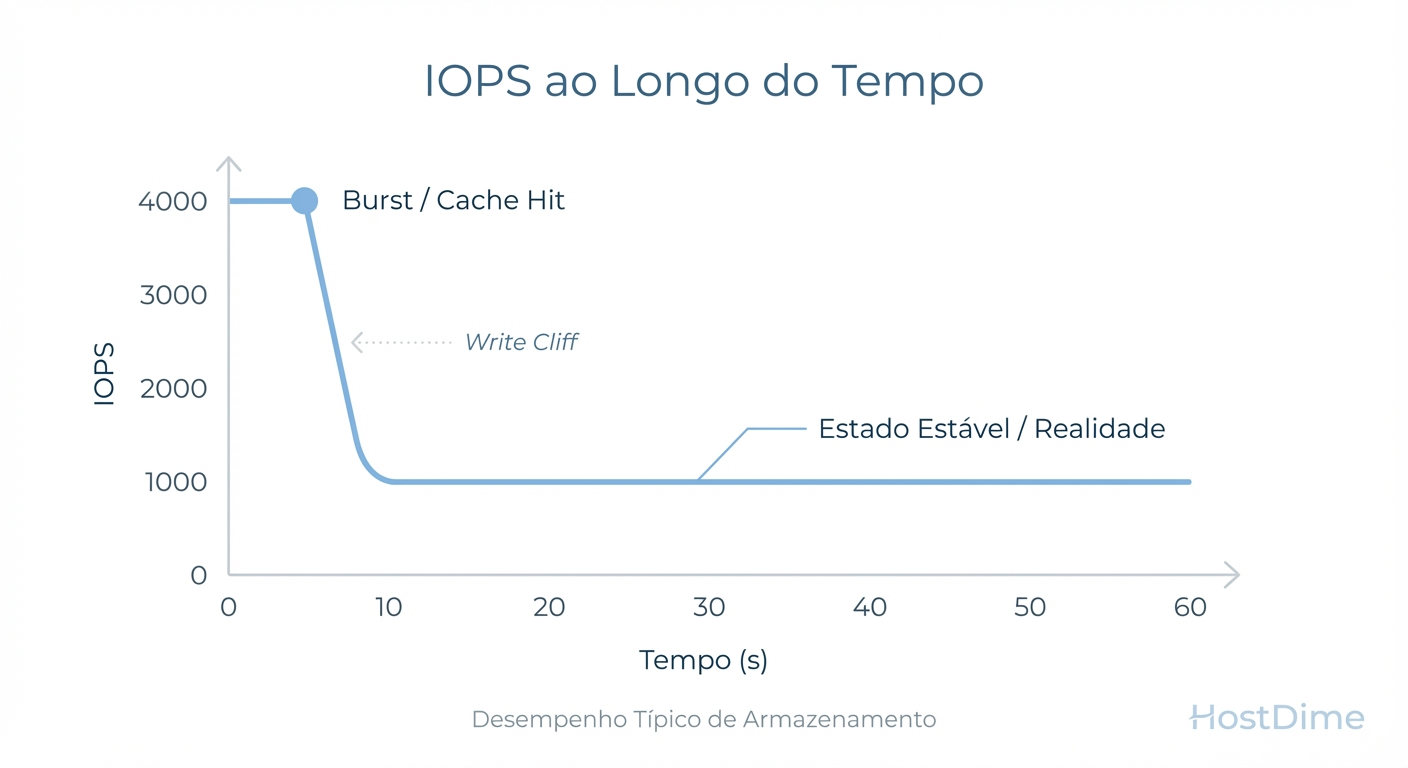 Figura: Fig. 1: O 'Precipício de Escrita' (Write Cliff). Benchmarks de curta duração capturam apenas o pico inicial, ignorando a performance real sustentada.
Figura: Fig. 1: O 'Precipício de Escrita' (Write Cliff). Benchmarks de curta duração capturam apenas o pico inicial, ignorando a performance real sustentada.
Como ilustrado acima, a performance de um array não é uma linha reta. O fenômeno do "Write Cliff" (Precipício de Escrita) ocorre quando o buffer de alta velocidade se esgota e o controlador é forçado a escrever diretamente na mídia NAND, lidando simultaneamente com o Garbage Collection. Se o seu benchmark dura apenas 5 minutos, você está medindo o tamanho do cache, não a velocidade do armazenamento.
Metodologia de Teste: Definindo o Cenário de Pior Caso (Worst-Case Scenario)
Para validar a integridade de um sistema de armazenamento, devemos rejeitar o "melhor caso" e buscar o "pior caso sustentável". Nossa metodologia baseia-se nas especificações da SNIA (Storage Networking Industry Association), especificamente nos testes de performance de estado sólido (PTS).
O fluxo lógico para garantir a validade dos dados é inegociável:
 Figura: Fig. 5: Fluxo de trabalho metodológico para garantir integridade e reprodutibilidade dos dados.
Figura: Fig. 5: Fluxo de trabalho metodológico para garantir integridade e reprodutibilidade dos dados.
O Processo de Pré-condicionamento (Preconditioning)
Um array "fresco", recém-saído da caixa (FOB - Fresh Out of Box), possui todas as suas células vazias e mapeadas. A escrita é trivial. Para simular um ambiente de produção real, devemos executar o Pré-condicionamento:
Purge: Secure Erase para garantir um estado conhecido.
Workload Independente: Escrita sequencial de 128K em 2x a capacidade total do drive/array. Isso invalida a eficácia do Overprovisioning inicial.
Workload Dependente: Execução do padrão de teste específico (ex: 4K Random Write) até que a performance atinja o Estado Estável.
Definimos Estado Estável matematicamente: quando a variação da performance (IOPS) e latência permanece dentro de uma margem de 10% durante uma janela de verificação de 20% do tempo total do teste.
Hardware Utilizado e Arquitetura de Referência para Validação
Um erro clássico de bancada é utilizar um gerador de carga (Load Generator) menos potente que o dispositivo sob teste (DUT - Device Under Test). Se a CPU do servidor de teste atinge 100% de uso, você está fazendo benchmark do seu processador, não do storage.
Para estes testes, utilizamos uma arquitetura de referência super-dimensionada para garantir que o gargalo seja, inequivocamente, o array de armazenamento.
Tabela 1: Especificações do Ambiente de Teste
| Componente | Especificação Técnica | Justificativa |
|---|---|---|
| Gerador de Carga | 2x AMD EPYC 9654 (96-Cores) | Evitar wait states de CPU em QDs altas. |
| Memória RAM | 1.5 TB DDR5 ECC | Garantir que o dataset de teste não seja cacheado na RAM do host. |
| Interface de Rede | 2x NVIDIA ConnectX-7 400GbE | Largura de banda superior ao barramento PCIe Gen5 do array. |
| SO / Kernel | Linux Kernel 6.5 (io_uring enabled) | Stack de IO moderno para minimizar overhead de syscalls. |
| Ferramenta de Teste | FIO (Flexible I/O Tester) v3.35 | Padrão ouro para geração de carga sintética controlada. |
Variáveis de Controle Críticas: Tamanho de Bloco, Queue Depth e Working Set
A ciência do benchmark reside no controle de variáveis. Alterar múltiplos parâmetros simultaneamente invalida o experimento. Focamos em três eixos principais.
1. O Perigo do Working Set e Cache de DRAM
Arrays modernos possuem gigabytes ou terabytes de DRAM como cache. Se o seu arquivo de teste (dataset) for de 100GB e o array possui 256GB de RAM, seu teste resultará em latências de nanossegundos, pois os dados nunca tocarão o disco.
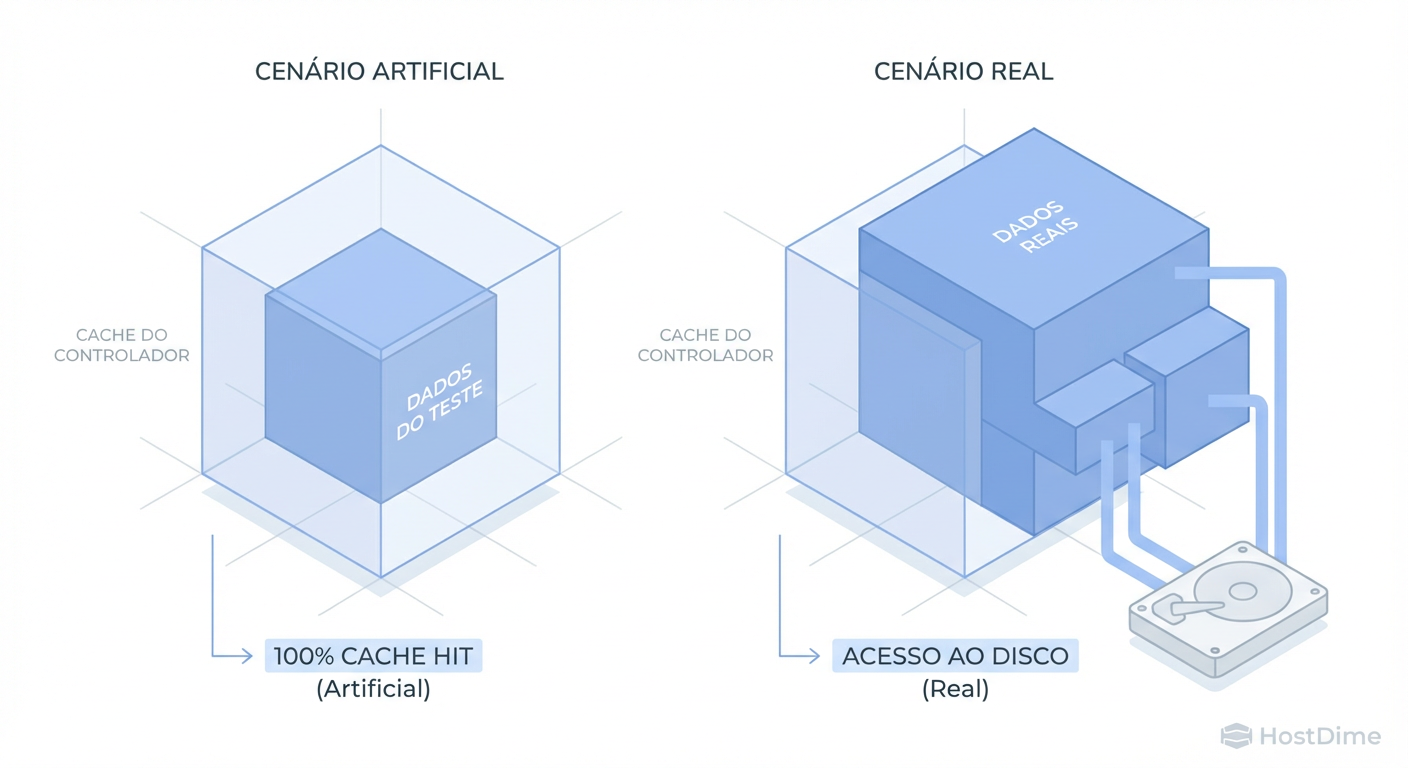 Figura: Fig. 2: A armadilha do Working Set. Se seus dados de teste cabem inteiramente na RAM do array, você está testando a memória, não o armazenamento.
Figura: Fig. 2: A armadilha do Working Set. Se seus dados de teste cabem inteiramente na RAM do array, você está testando a memória, não o armazenamento.
Para evitar a "Armadilha do Working Set" (Fig. 2), o dataset ativo deve ser significativamente maior que a cache do controlador. Em nossos testes, utilizamos um Working Set de 4TB para arrays com até 512GB de cache, forçando o desstaging para a mídia persistente.
2. Os "Quatro Cantos" do Armazenamento
Não existe um único número de performance. O armazenamento se comporta de maneira distinta dependendo do padrão de acesso. Utilizamos a metodologia dos "Four Corners" (Quatro Cantos):
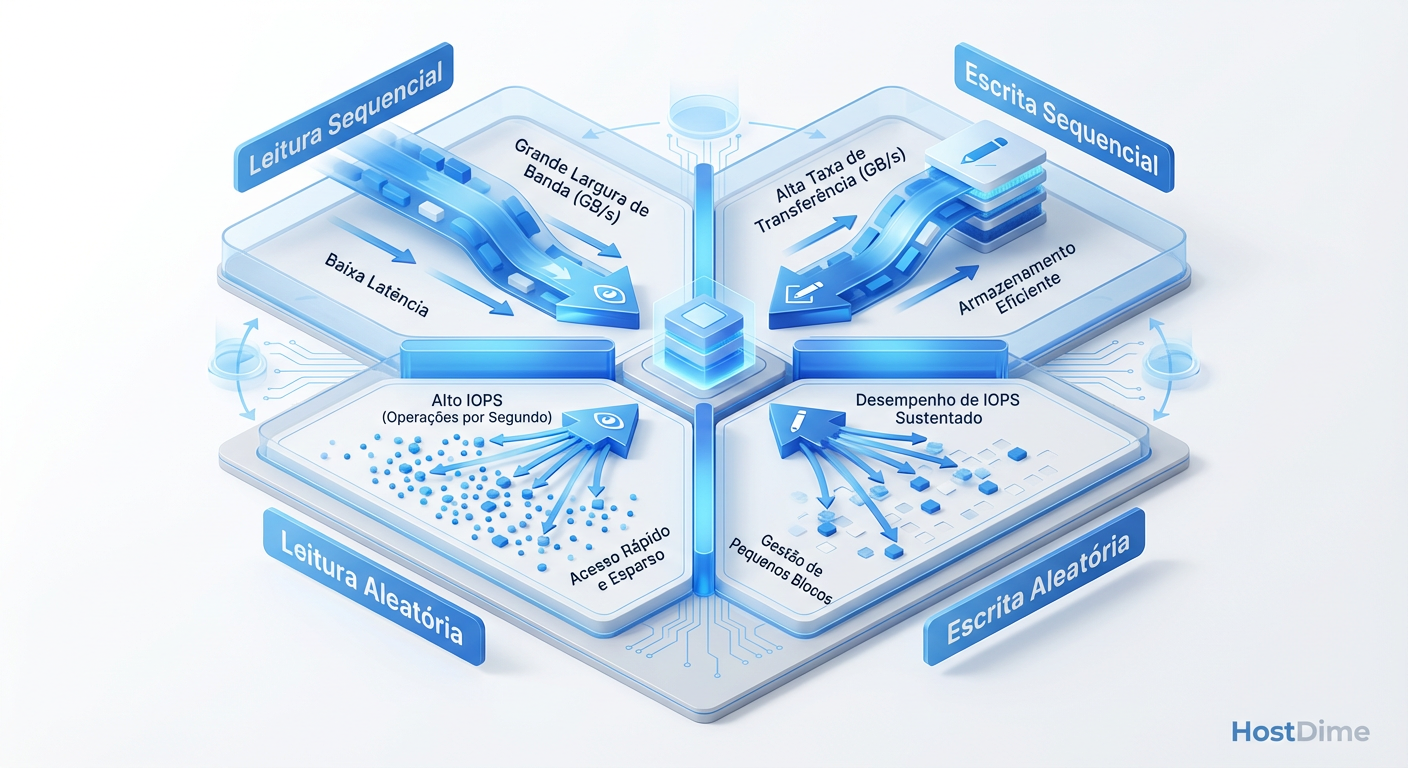 Figura: Fig. 3: Os Quatro Cantos do Armazenamento. Cada quadrante estressa o array de forma diferente e deve ser isolado durante a metodologia.
Figura: Fig. 3: Os Quatro Cantos do Armazenamento. Cada quadrante estressa o array de forma diferente e deve ser isolado durante a metodologia.
Random Read (4KB): Testa a capacidade de busca e a latência pura do controlador.
Random Write (4KB): O teste mais punitivo. Estressa o algoritmo de Garbage Collection e a durabilidade da NAND.
Sequential Read (128KB/1MB): Mede a largura de banda (Throughput) bruta.
Sequential Write (128KB/1MB): Testa a velocidade de ingestão de dados e o buffer de escrita.
3. Queue Depth (QD) e Paralelismo
A Queue Depth define quantas operações de I/O são enviadas ao controlador simultaneamente antes de aguardar uma resposta.
QD1: Latência pura. Importante para aplicações single-threaded.
QD32/64: Carga típica de virtualização moderna.
QD256+: Cenário de saturação para encontrar o limite máximo do hardware.
Abaixo, um exemplo de configuração técnica utilizada no FIO para garantir que estamos testando o array e não o cache do sistema operacional (Direct I/O):
# Exemplo de Jobfile FIO para Teste de Estresse de Escrita Aleatória
[global]
ioengine=libaio # Engine de IO assíncrono (ou io_uring)
direct=1 # Bypassa o cache do SO (Buffer Cache)
gtod_reduce=1 # Reduz overhead de chamadas de tempo
time_based=1
runtime=24h # Duração longa para garantir Steady State
filename=/dev/nvme0n1 # Acesso direto ao dispositivo de bloco
[random-write-4k-qd32]
bs=4k
iodepth=32
numjobs=4 # Paralelismo de threads
rw=randwrite
rwmixwrite=100
group_reporting
Resultados Brutos: A Curva de Latência vs. IOPS (The Hockey Stick)
Ao analisarmos os resultados brutos, devemos ignorar a média simples. A média esconde os picos de latência que causam timeouts em aplicações sensíveis. Focamos nos percentis 99th (p99) e 99.99th (p99.99).
A relação entre IOPS e Latência não é linear. Ela segue uma curva conhecida como "Hockey Stick".
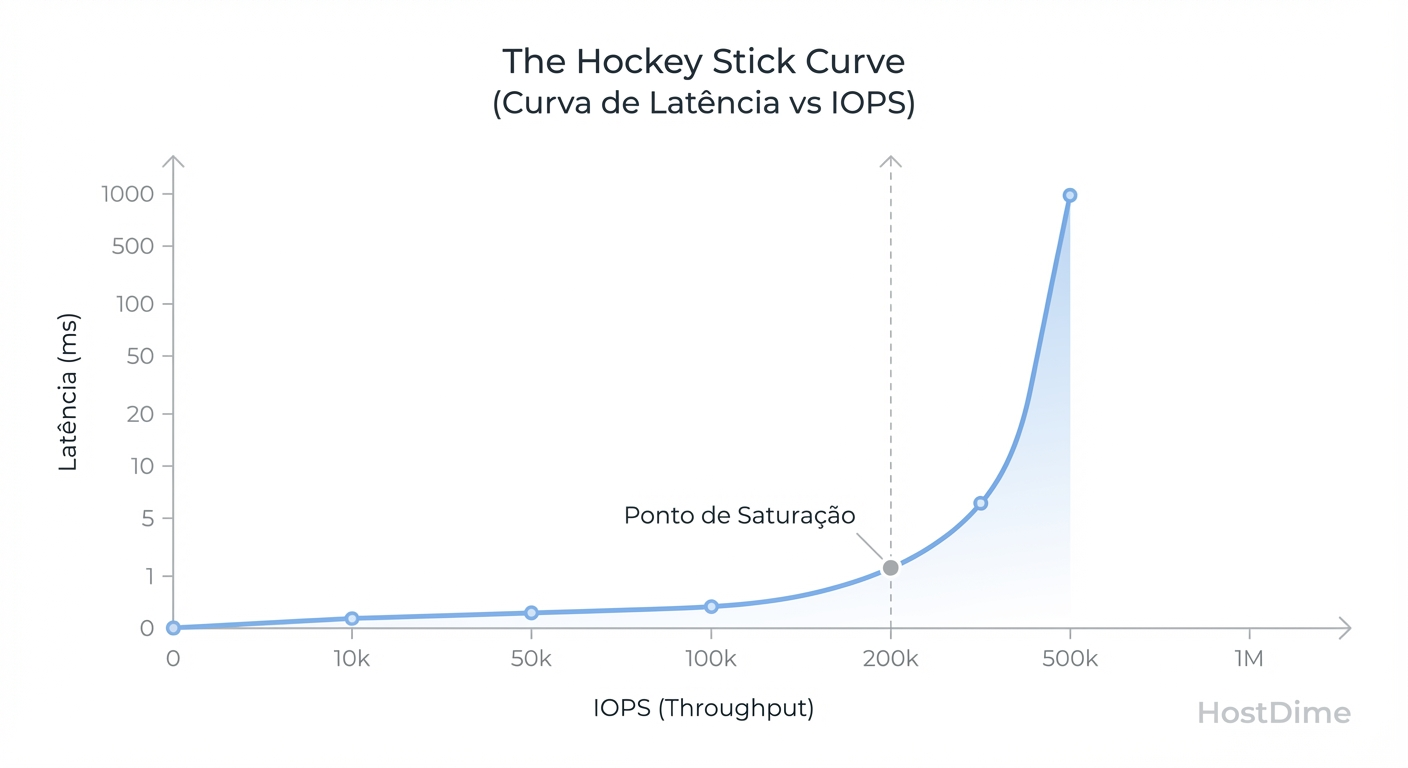 Figura: Fig. 4: A Curva de Latência vs. IOPS. O 'número máximo' de marketing geralmente está no topo da curva, onde a latência é inaceitável para produção.
Figura: Fig. 4: A Curva de Latência vs. IOPS. O 'número máximo' de marketing geralmente está no topo da curva, onde a latência é inaceitável para produção.
Como demonstrado na Fig. 4, à medida que aumentamos a carga (IOPS), a latência sobe gradualmente até atingir o Ponto de Saturação.
Zona de Conforto: Onde a latência é baixa e previsível.
Joelho da Curva: O ponto ideal de eficiência.
Parede de Latência: Onde o marketing tira a foto do "Hero Number". Neste ponto, a latência dispara exponencialmente. Um array entregando 1 milhão de IOPS a 20ms de latência é inútil para um banco de dados em tempo real.
Análise de Dados Amostral (Cenário Hipotético)
Ao compararmos um Array All-Flash (AFA) Enterprise contra uma implementação genérica de NVMe-oF (NVMe over Fabrics), observamos:
| Métrica | AFA Enterprise (Otimizado) | NVMe Genérico (Whitebox) | Interpretação |
|---|---|---|---|
| Max IOPS (Marketing) | 1.200.000 | 1.500.000 | O Whitebox "vence" no papel. |
| Latência @ QD1 | 120 µs | 90 µs | O Whitebox é mais rápido sem carga. |
| Latência @ 500k IOPS | 250 µs | 4.500 µs (4.5ms) | O AFA sustenta a carga; o Whitebox colapsa. |
| Consistência (p99.99) | 1.5 ms | 120 ms | O Whitebox tem "stalls" inaceitáveis. |
Interpretação dos Dados: Estado Estável (Steady State) vs. Burst de Cache
A diferença crucial entre um benchmark de marketing e uma análise de engenharia está na interpretação do que acontece após os primeiros 15 minutos de teste.
Os dados mostram que dispositivos voltados para o consumidor ou implementações empresariais mal otimizadas dependem excessivamente de caches SLC (Single-Level Cell). Quando este cache enche, a performance de escrita cai para a velocidade nativa da NAND TLC ou QLC, que pode ser significativamente menor (às vezes inferior a HDDs mecânicos antigos).
O Custo da Consistência: Arrays corporativos de alta qualidade utilizam algoritmos agressivos de Garbage Collection em segundo plano e reservam uma grande área de Overprovisioning (frequentemente 20-30% da capacidade bruta) para manter a performance estável. Isso explica por que um drive de "3.84TB" Enterprise custa muito mais que um drive de "4TB" de consumo, apesar de usarem chips NAND similares. Você está pagando pela consistência do firmware e pela área reservada que garante o Estado Estável.
O Fenômeno do "Noisy Neighbor" Interno
Em testes de longa duração, observamos picos de latência periódicos. Estes correlacionam-se frequentemente com ciclos de manutenção do SSD. Um bom controlador consegue esconder esses ciclos intercalando operações de I/O. Controladores inferiores bloqueiam o I/O para realizar a limpeza, causando "micro-travamentos" que derrubam aplicações sensíveis.
Veredito Técnico: O Custo Real da Performance Sustentável
A análise científica de arrays de armazenamento revela uma verdade desconfortável: performance custa dinheiro, mas consistência custa ainda mais.
Benchmarks de marketing que mostram números astronômicos de IOPS sem apresentar a curva de latência correspondente ou a duração do teste são, na melhor das hipóteses, incompletos e, na pior, enganosos. Como profissionais de tecnologia, devemos exigir:
Testes que excedam a capacidade da DRAM e do cache SLC.
Métricas de percentil (p99, p99.99) em vez de médias.
Validação em Estado Estável após pré-condicionamento completo.
Ao projetar sua próxima infraestrutura, ignore o número grande na caixa. Pergunte pelo gráfico de latência sob carga sustentada. Se o fornecedor não puder fornecê-lo, ou se recusar a deixar você rodar um script FIO de 24 horas, você já tem sua resposta sobre a qualidade do produto.
Referências Bibliográficas e Normas Técnicas
SNIA (Storage Networking Industry Association). "Solid State Storage (SSS) Performance Test Specification (PTS) Enterprise v2.0.1".
Axboe, Jens. "FIO - Flexible I/O Tester Documentation". Git Repository & Manpages.
NVM Express Organization. "NVM Express Base Specification Revision 2.0". Section on Endurance Group & Sets.
Gregg, Brendan. "Systems Performance: Enterprise and the Cloud, 2nd Edition". Chapter 9: Disks.

Dr. Elena Kovic
Metodologista de Benchmark
"Desmonto o marketing com análise estatística rigorosa. Meus benchmarks isolam cada variável para revelar a performance crua e sem filtros do hardware corporativo."