Corrupção Silenciosa de Dados: O Inimigo Invisível e a Defesa do ZFS e Btrfs

Aprenda como a corrupção silenciosa (bit rot) destrói dados sem avisos e como a arquitetura de Checksums e Merkle Trees do ZFS e Btrfs previne o desastre.
Imagine que você acabou de salvar a planilha financeira da sua empresa ou a única cópia digital das fotos do nascimento do seu filho. O sistema operacional confirmou a gravação. O disco rígido não reportou erros. Você dorme tranquilo. Cinco anos depois, ao tentar abrir o arquivo, você encontra um erro de leitura ou, pior, uma imagem corrompida onde metade dos pixels são ruído digital.
Bem-vindo ao mundo da Corrupção Silenciosa de Dados (Silent Data Corruption - SDC), também conhecida como bit rot.
Como arquitetos de sistemas e administradores de armazenamento, fomos treinados para temer falhas catastróficas: o disco que para de girar, a controladora que solta fumaça. No entanto, o inimigo mais perigoso não é aquele que grita, é aquele que sussurra. Em sistemas de arquivos legados (como ext4, XFS ou NTFS), a integridade dos dados é uma presunção, não uma garantia.
Neste artigo, vamos descer ao nível do bloco lógico para entender como a física dos meios de armazenamento joga contra nós e como as arquiteturas modernas de Copy-on-Write (CoW), especificamente ZFS e Btrfs, utilizam matemática avançada para garantir que o que você lê é exatamente o que você escreveu.
A Natureza da Corrupção Silenciosa: Quando o Hardware Mente
A premissa básica da computação confiável é que o hardware é determinístico. Se eu instruo o disco a escrever 0 no setor 5400, ele deve escrever 0. Se eu leio o setor 5400, ele deve retornar 0. Na prática, a realidade física é muito mais caótica.
A corrupção silenciosa ocorre quando os dados no disco são alterados sem que o sistema operacional seja notificado. Isso acontece por diversos vetores:
Bit Flips Magnéticos: A entropia natural faz com que a orientação magnética de um bit no prato do HDD mude espontaneamente ao longo do tempo.
Firmware Bugado: Discos rígidos e SSDs são computadores completos com seus próprios processadores e códigos complexos. Um bug no firmware pode confirmar uma gravação no cache volátil do disco, mas falhar ao persisti-la no meio físico (Phantom Write).
Misdirected Writes: A controladora tenta escrever no Bloco A, mas devido a um erro de endereçamento ou vibração, escreve no Bloco B, corrompendo dados válidos que lá residiam.
Raios Cósmicos: Partículas de alta energia podem atingir a memória DRAM ou o buffer do disco, invertendo bits em trânsito antes mesmo de serem gravados.
Em um sistema de arquivos tradicional, não há mecanismo intrínseco para validar o conteúdo do bloco de dados em relação ao que foi solicitado. O sistema confia cegamente no hardware. Se o disco retorna lixo, o sistema de arquivos entrega lixo para a aplicação.
Arquitetura de Confiança: Árvores de Merkle e Checksums End-to-End
Para combater a mentira do hardware, ZFS e Btrfs adotam uma postura de "zero confiança". A base dessa defesa é a Integridade End-to-End (Ponta a Ponta). Isso significa que a validação dos dados não deve ocorrer apenas na controladora do disco, mas deve ser gerenciada pelo próprio sistema de arquivos.
A estrutura de dados que torna isso possível é a Árvore de Merkle (Merkle Tree).
Diferente de sistemas legados que mantêm metadados (onde está o dado) separados da verificação de integridade, no ZFS e Btrfs, o ponteiro para um bloco de dados contém não apenas o endereço físico, mas também o checksum (hash criptográfico) do conteúdo esperado daquele bloco.
O Princípio do Checksum no Ponteiro Pai
Esta é a genialidade de Jeff Bonwick e da equipe original do ZFS: O checksum não é armazenado com o bloco de dados, mas sim no bloco pai que aponta para ele.
O bloco de dados (Nível 0) é hasheado (usando algoritmos como Fletcher4 ou SHA-256).
Esse hash é armazenado no bloco de metadados indireto (Nível 1) que aponta para o dado.
O bloco de metadados (Nível 1) é então hasheado, e seu hash é armazenado no Nível 2.
Isso sobe recursivamente até o Uberblock (ZFS) ou Superblock (Btrfs).
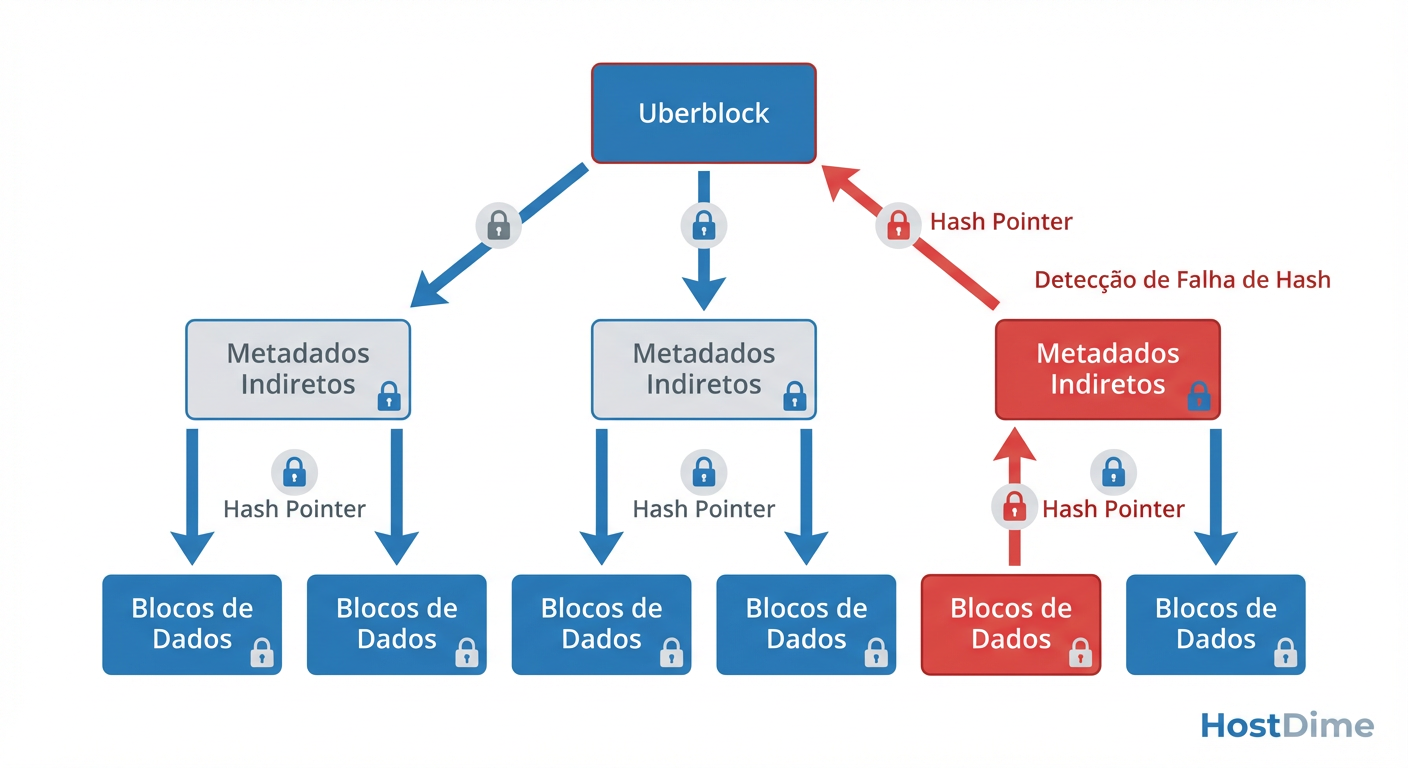 Figura: Fig. 1: A Árvore de Merkle garante que a corrupção em um bloco de dados invalide o hash do pai, tornando a corrupção matematicamente impossível de ser ignorada.
Figura: Fig. 1: A Árvore de Merkle garante que a corrupção em um bloco de dados invalide o hash do pai, tornando a corrupção matematicamente impossível de ser ignorada.
Como ilustrado na figura acima, essa estrutura cria uma cadeia de confiança inquebrável. Se um único bit for alterado no disco (corrupção silenciosa), ao ler o dado, o sistema de arquivos calculará o hash do que foi lido e o comparará com o hash armazenado no ponteiro pai. A discrepância será óbvia e imediata. É matematicamente impossível para o ZFS ou Btrfs entregar dados corrompidos para a aplicação sem perceber o erro.
Mecânica no Disco: O Processo de Self-Healing em Ação
Detectar o erro é apenas metade da batalha. A verdadeira magia dos sistemas de arquivos de próxima geração é a capacidade de Self-Healing (Autocorreção).
Para que o self-healing funcione, o sistema precisa de redundância gerenciada pelo sistema de arquivos, não pelo hardware. Isso significa utilizar configurações como ZFS Mirror, RAIDZ (1/2/3) ou Btrfs RAID1/RAID10.
O Fluxo de Leitura e Reparação
Quando uma aplicação solicita um arquivo, o seguinte processo ocorre em microssegundos:
Solicitação: O sistema de arquivos lê o ponteiro do bloco e obtém o checksum esperado (ex:
0xA1).Leitura: O sistema lê o bloco de dados do Disco 1.
Verificação: O sistema calcula o checksum do dado lido. Digamos que o resultado seja
0xB2.Detecção de Falha:
0xA1 != 0xB2. O ZFS/Btrfs sabe que o Disco 1 mentiu. O dado está podre.Recuperação: O sistema consulta a paridade ou o espelho (Disco 2) para obter a cópia redundante do mesmo bloco.
Validação da Cópia: O sistema lê do Disco 2 e verifica o checksum. Resultado:
0xA1. Sucesso.Entrega e Reparo: O dado correto é entregue à aplicação. Simultaneamente, o sistema sobrescreve o bloco corrompido no Disco 1 com a cópia correta, "curando" o arranjo.
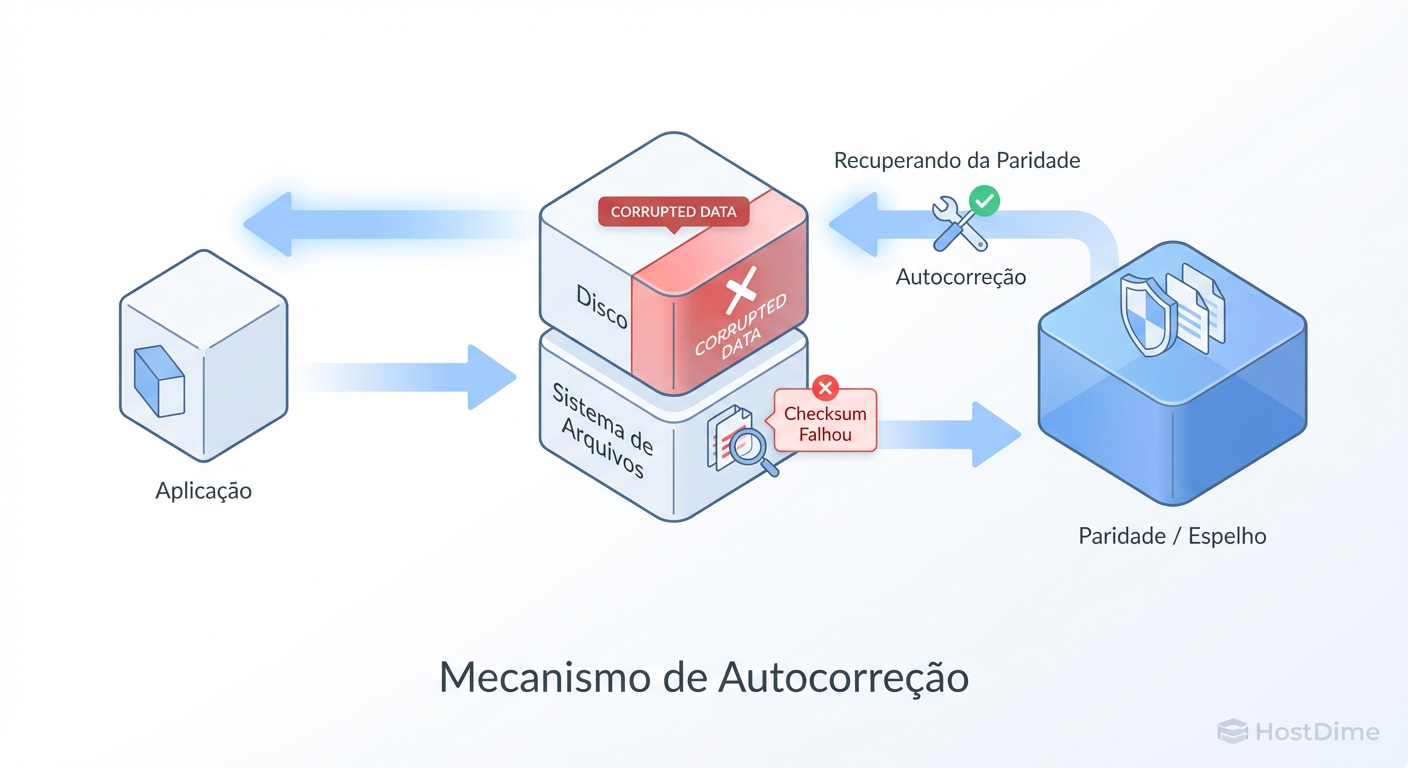 Figura: Fig. 2: O fluxo de Autocorreção (Self-Healing). O sistema de arquivos intercepta o dado podre, repara-o usando a redundância e entrega o dado limpo à aplicação, tudo em microssegundos.
Figura: Fig. 2: O fluxo de Autocorreção (Self-Healing). O sistema de arquivos intercepta o dado podre, repara-o usando a redundância e entrega o dado limpo à aplicação, tudo em microssegundos.
Tudo isso acontece de forma transparente. A aplicação nunca recebe um erro de I/O; ela apenas percebe uma latência ligeiramente maior durante a operação de reparo.
Nota Importante: Se você não tiver redundância (ex: um único disco em zpool ou btrfs single), o sistema ainda detectará a corrupção (EIO - Input/Output Error), protegendo você de usar dados falsos, mas não poderá repará-los automaticamente.
Comandos Práticos de Diagnóstico: zpool status, btrfs scrub e smartctl
Como administradores, não precisamos esperar um desastre para verificar a saúde dos nossos dados. ZFS e Btrfs oferecem ferramentas poderosas para auditoria proativa.
O Processo de Scrubbing
O Scrubbing é o ato de ler todos os dados alocados no pool e recalcular seus checksums para verificar a consistência. É como uma vacina contra o bit rot latente.
 Figura: Fig. 3: O processo de Scrubbing atua como uma vacina, lendo proativamente todos os dados para verificar a consistência dos checksums e corrigir erros latentes.
Figura: Fig. 3: O processo de Scrubbing atua como uma vacina, lendo proativamente todos os dados para verificar a consistência dos checksums e corrigir erros latentes.
Diagnóstico no ZFS
O comando principal é o zpool status. Ele nos dá a visão da integridade lógica.
# Verificar o status do pool
root@server:~# zpool status -v tank
pool: tank
state: ONLINE
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: http://zfsonlinux.org/msg/ZFS-8000-9P
scan: scrub repaired 128K in 2h15m with 0 errors on Sat Jan 3 14:00:00 2026
config:
NAME STATE READ WRITE CKSUM
tank ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
sda ONLINE 0 0 2 <-- 2 Erros de Checksum
sdb ONLINE 0 0 0
errors: No known data errors
Análise: Observe a coluna CKSUM. O valor 2 indica que o ZFS encontrou dois blocos onde o dado lido não batia com o hash. Como o status diz "repaired 128K", o self-healing funcionou.
Para iniciar uma verificação manual:
zpool scrub tank
Diagnóstico no Btrfs
No Btrfs, a lógica é similar, mas os comandos diferem.
# Iniciar o scrub
root@server:~# btrfs scrub start /mnt/data
# Verificar o status do scrub
root@server:~# btrfs scrub status /mnt/data
UUID: ...
Scrub started: Sat Jan 3 14:00:00 2026
Status: finished
Duration: 2:15:00
Total to scrub: 1.50TiB
Rate: 190MB/s
Error summary: csum=5
Corrected: 5
Uncorrectable: 0
Unverified: 0
Para ver estatísticas acumuladas de erros no nível do dispositivo:
btrfs device stats /mnt/data
O Papel do SMART (smartctl)
Embora o ZFS/Btrfs gerenciem a integridade lógica, o SMART monitora a saúde física. Use o smartctl para correlacionar erros de checksum com falhas físicas (como setores realocados).
smartctl -a /dev/sda | grep -i "Reallocated_Sector"
Se o ZFS reporta erros de CKSUM e o SMART reporta aumento em Reallocated_Sector_Ct, o disco está morrendo fisicamente. Se o ZFS reporta CKSUM mas o SMART está limpo, o problema pode ser cabo, controladora ou bit rot magnético puro.
Mitos Comuns: A Falácia do Controlador RAID e o Medo da RAM não-ECC
Na comunidade de armazenamento, certos mitos persistem e impedem a adoção de tecnologias mais seguras. Vamos desconstruir dois dos maiores.
Mito 1: "Meu controlador RAID Hardware de $1000 protege meus dados."
A Realidade: Controladores RAID de hardware são ótimos para manter o sistema online se um disco falhar, mas são péssimos para integridade de dados. O RAID de hardware opera em um nível inferior ao sistema de arquivos. Se ocorrer uma corrupção silenciosa (bit rot) em um dos discos de um RAID 5, o controlador não tem contexto para saber qual dos blocos (dados ou paridade) está correto e qual está errado, pois ele não possui o checksum do conteúdo. Pior ainda é o "Write Hole": em caso de falta de energia durante uma escrita, a paridade pode ficar dessincronizada com os dados. O ZFS/Btrfs resolvem isso com escritas atômicas transacionais (Copy-on-Write). O dado nunca é sobrescrito no lugar; ele é escrito em um novo local e o ponteiro só é atualizado após a confirmação da integridade.
Mito 2: "ZFS sem memória ECC é perigoso (Scrub of Death)."
A Realidade: Este é um dos mitos mais nocivos propagados em fóruns. A lógica do mito é: "Se a RAM estiver ruim, o ZFS vai calcular checksums errados durante o scrub e corromper os dados bons no disco para 'corrigi-los' com base na memória ruim." A Defesa: Matt Ahrens, co-fundador do ZFS, já desmentiu isso. Embora a memória ECC (Error Correcting Code) seja altamente recomendada para qualquer servidor sério (independente do sistema de arquivos), o ZFS não é mais suscetível a RAM ruim do que o NTFS ou ext4. Na verdade, o ZFS é mais seguro. Se a RAM inverter um bit, o ZFS provavelmente falhará na verificação do checksum na leitura e retornará um erro de I/O, protegendo o dado no disco. Um sistema de arquivos tradicional escreveria o bit invertido da RAM para o disco silenciosamente, corrompendo o armazenamento permanentemente.
Cenário de Desastre: Simulando e Recuperando de um Bit Flip em Metadados
Para entender a resiliência, vamos analisar um cenário teórico onde a corrupção atinge o local mais crítico possível: os metadados que descrevem a estrutura de diretórios.
O Cenário:
Um servidor de arquivos ZFS usa um pool em espelho (mirror). Devido a uma flutuação de voltagem, o Disco A escreve um bit errado em um bloco de metadados que lista os arquivos de /tank/financeiro.
A Detecção:
O usuário tenta listar os arquivos:
ls /tank/financeiro.O ZFS lê o bloco de metadados do Disco A.
O ZFS calcula o hash SHA-256 desse bloco.
O ZFS compara com o hash armazenado no diretório pai (
/tank).Mismatch: O hash não bate. O ZFS sabe que a estrutura de diretório lida do Disco A é inválida.
A Recuperação Automática: Sem retornar erro ao usuário, o ZFS imediatamente requisita o mesmo bloco de metadados ao Disco B. Ele verifica o hash do bloco vindo do Disco B. O hash confere.
O Resultado:
O comando ls retorna a lista de arquivos corretamente. Nos bastidores, o ZFS emite um alerta no zpool status indicando que houve uma reparação nos metadados.
Comparação com Legado (ext4/fsck):
Em um sistema tradicional, o fsck encontraria uma inconsistência na estrutura de diretórios. Sem checksums para saber qual versão é a "verdadeira" e sem paridade granular, a ferramenta muitas vezes opta por truncar o diretório ou mover os arquivos órfãos para /lost+found, resultando em perda parcial de dados e caos administrativo.
Veredito Técnico: A Integridade como Prioridade Absoluta
A era de confiar cegamente no armazenamento magnético ou flash acabou. À medida que as capacidades dos discos aumentam para a casa dos Terabytes e Petabytes, a probabilidade estatística de erros de leitura não recuperáveis (URE) e corrupção silenciosa aproxima-se de 100%.
Utilizar ZFS ou Btrfs não é apenas uma escolha de "features" como snapshots ou compressão; é uma escolha fundamental sobre a validade da sua existência digital.
Sistemas de arquivos Copy-on-Write com checksums end-to-end transformam a incerteza do hardware em certeza matemática. Eles nos permitem afirmar não apenas que "temos os dados", mas que "os dados que temos são verdadeiros".
Em um mundo onde os dados são o novo petróleo, permitir que eles vazem através das rachaduras da corrupção silenciosa é uma negligência inaceitável. Implemente redundância, agende seus scrubs e nunca confie em um disco que não possa provar sua honestidade matemática.
Referências Bibliográficas
Bonwick, J., & Ahrens, M. (2001). ZFS: The Last Word in File Systems. Sun Microsystems.
Rodeh, O., Bacik, J., & Mason, C. (2013). BTRFS: The Linux B-Tree Filesystem. ACM Transactions on Storage.
CERN Data Reliability Study. (2007). Estudo sobre corrupção silenciosa de dados em ambientes de Petabytes.
Lucas, M. W., & Jude, A. (2016). FreeBSD Mastery: ZFS. Tilted Windmill Press.
OpenZFS Documentation. Checksums and Data Integrity. openzfs.org.

Roberto Almeida
Auditor de Compliance (LGPD/GDPR)
"Especialista em mitigação de riscos regulatórios e governança de dados. Meu foco é blindar infraestruturas corporativas contra sanções legais, garantindo a estrita conformidade com a LGPD e GDPR."