CXL 3.1: A Revolução da Memória Desagregada ou Pesadelo de Latência?

Análise técnica cética sobre o CXL 3.1 e as novas malhas de memória. Descubra a verdade sobre latência, Global Integrated Memory (GIM) e o que o marketing não conta sobre desagregação.
CXL 3.1 promete ser o santo graal da infraestrutura de data centers: memória infinita, compartilhada e livre das amarras dos slots DIMM da placa-mãe. O marketing vende a ideia de que finalmente podemos tratar a memória RAM como tratamos o armazenamento SAN — um pool gigante e flexível.
Mas vamos colocar os pés no chão. Se você trabalha com arquitetura de servidores e storage, sabe que a física não tira folga. O CXL (Compute Express Link) 3.1, rodando sobre o barramento PCIe 6.0, é uma maravilha da engenharia, mas não é mágica. Estamos prestes a trocar o problema do desperdício de memória pelo pesadelo do gerenciamento de latência não-uniforme (NUMA) em esteroides.
Resumo em 30 segundos
- Mudança de Paradigma: O CXL 3.1 transforma a memória de um recurso local e isolado em uma malha (fabric) compartilhada, permitindo comunicação peer-to-peer entre dispositivos sem intervenção da CPU.
- O Fim do Desperdício: A principal vantagem é econômica, eliminando a "memória órfã" (stranded memory) ao permitir que múltiplos servidores acessem um pool central de RAM conforme a demanda.
- O Preço da Física: A latência adicional introduzida pelos switches e pelo protocolo PCIe 6.0 cria uma nova camada de "Far Memory", exigindo que softwares e hypervisors sejam reescritos para não engasgarem.
Do barramento local à malha de memória global
Até o CXL 2.0, a conversa girava em torno de conectar um expansor de memória a um servidor, ou talvez um pool simples onde um switch alocava RAM para o Servidor A ou B. Era útil, mas limitado. O CXL 3.1 joga o tabuleiro para o ar.
Baseado na especificação PCIe 6.0 (que dobra a taxa de transferência para 64 GT/s usando codificação PAM4), o CXL 3.1 introduz recursos de fabric reais. Não estamos mais falando apenas de uma árvore hierárquica simples. Estamos falando de topologias complexas onde dispositivos podem conversar entre si (Peer-to-Peer) sem passar pela CPU host.
Isso permite que uma placa aceleradora (como uma GPU ou FPGA) acesse diretamente a memória de outra placa ou um pool de memória compartilhado através de switches multinível. Para o ecossistema de storage, isso é gigantesco. Imagine um buffer de gravação NVMe que reside em uma memória CXL compartilhada, acessível por múltiplos controladores de storage simultaneamente. Soa perfeito no papel, até você olhar para o relógio.
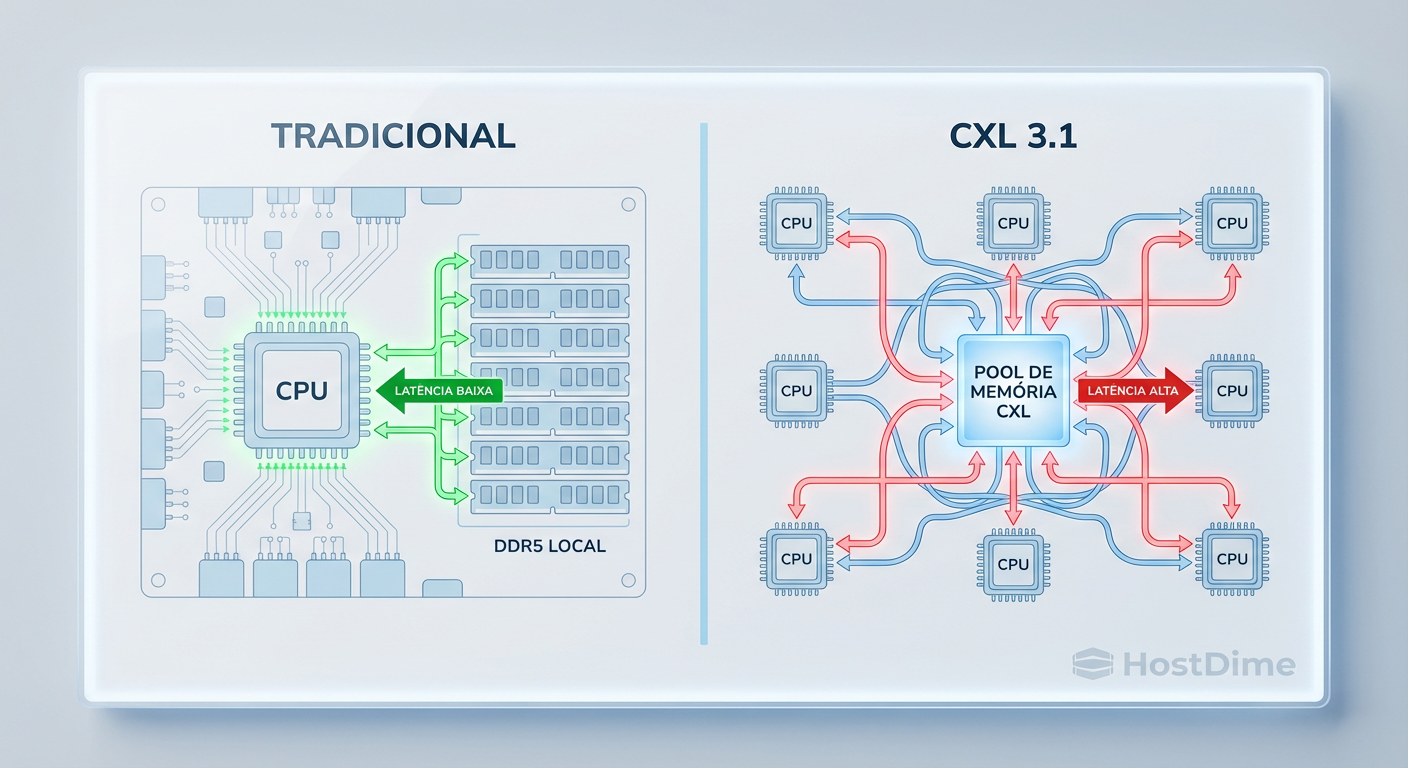 Figura: Comparativo arquitetural: Acesso direto à memória local (DDR5) versus a topologia de malha do CXL 3.1 com switches intermediários e latência adicionada.
Figura: Comparativo arquitetural: Acesso direto à memória local (DDR5) versus a topologia de malha do CXL 3.1 com switches intermediários e latência adicionada.
A promessa econômica do fim da memória órfã
Por que os hyperscalers (Google, Meta, Microsoft) estão empurrando isso goela abaixo da indústria? Dinheiro.
Em um data center tradicional, a "memória órfã" (stranded memory) é um buraco negro de orçamento. Se você tem um servidor com 1TB de RAM, mas a carga de trabalho usa apenas 200GB de RAM e 100% da CPU, os 800GB restantes estão presos ali. Você não pode "emprestá-los" para o servidor vizinho que está faminto por memória.
💡 Dica Pro: Ao avaliar TCO (Custo Total de Propriedade) de servidores com CXL, não olhe apenas para o custo do hardware. O ganho real está na densidade de consolidação. Se você conseguir reduzir a compra de DRAM em 20% através de pooling, o custo dos switches CXL e controladores se paga rapidamente.
O CXL 3.1 permite criar "appliances de memória". Um chassi cheio de módulos de memória CXL (E1.S ou E3.S) que atua como um banco de sangue universal. O hypervisor (VMware vSphere, Proxmox ou KVM) pode solicitar 50GB extras para uma VM crítica, usar e devolver. Isso transforma CAPEX desperdiçado em recurso utilizável.
O gargalo físico: PCIe 6.0 e a Latência de Cauda
Aqui é onde o marketing da "memória desagregada" colide com a realidade da engenharia. Memória RAM local (DDR5) conectada diretamente ao controlador de memória da CPU tem uma latência na casa dos 70-100 nanossegundos (ns).
Quando você move essa memória para fora do soquete, passa por trilhas da placa-mãe, entra em um controlador CXL, trafega por um cabo ou backplane, passa por um switch CXL 3.1 e finalmente chega ao chip DRAM, você adicionou uma penalidade significativa.
Estamos falando de adicionar, no mínimo, 150ns a 250ns de latência sobre o acesso local. Para um banco de dados in-memory (como Redis ou SAP HANA) ou cargas de HPC, isso é uma eternidade.
O CXL 3.1 não substitui a RAM principal; ele cria uma nova camada de hierarquia de armazenamento:
Near Memory: DDR5 local (rápida, cara, limitada).
Far Memory: CXL Pool (latência média, capacidade massiva).
Storage Rápido: NVMe SSDs (lento comparado à RAM, persistente).
Se o seu software não for "NUMA-aware" (consciente da topologia de memória) e começar a tratar a Far Memory como se fosse local, você verá o fenômeno de "latência de cauda" (tail latency) destruir a performance da sua aplicação. O processador vai passar ciclos ociosos esperando os dados chegarem do outro lado do rack.
Segurança: O pesadelo do Global Integrated Memory (GIM)
O CXL 3.1 introduz o conceito de Global Integrated Memory (GIM), que permite que múltiplos hosts vejam e acessem o mesmo endereço físico de memória coerente. Isso é fantástico para mover dados sem cópia (zero-copy), mas é um terror para a segurança.
⚠️ Perigo: Compartilhamento de memória física entre hosts diferentes abre vetores para ataques de canal lateral (side-channel attacks) e corrupção de dados. Se um host comprometido escrever lixo em uma região de memória compartilhada que outro host está lendo como "confiável", toda a integridade do cluster de storage ou computação cai por terra.
A especificação inclui criptografia IDE (Integrity and Data Encryption), mas a implementação disso em velocidade de linha (64 GT/s) sem adicionar ainda mais latência é um desafio que os fabricantes de silício ainda estão tentando resolver de forma eficiente.
Realidade do Hardware vs. Especificação de Papel
É vital separar o que a especificação diz do que você pode comprar hoje. Embora o CXL 3.1 tenha sido finalizado, o hardware real que suporta todas as suas funcionalidades (especialmente os switches complexos e o suporte a GIM) ainda é embrionário.
A maioria dos dispositivos "CXL" no mercado hoje são, na verdade, controladores CXL 1.1 ou 2.0 (Type 3 - Expansão de Memória). Eles funcionam, mas são basicamente "RAM lenta conectada via PCIe". Os recursos avançados de malha e compartilhamento dinâmico do 3.1 exigem uma nova geração de CPUs (como Intel Xeon Granite Rapids ou AMD EPYC Turin e sucessores) e, crucialmente, switches de empresas como Astera Labs, Microchip e Xconn que sejam validados e estáveis.
Comparativo: DDR5 Local vs. CXL 3.1 Pool
Para quem precisa decidir a arquitetura do próximo refresh de servidores, a distinção deve ser clara:
| Característica | DDR5 Local (Near Memory) | CXL 3.1 Pool (Far Memory) |
|---|---|---|
| Latência | Baixa (~80-100ns) | Média/Alta (~200-300ns+) |
| Largura de Banda | Limitada pelos canais da CPU | Escalável via faixas PCIe 6.0 |
| Custo por GB | Alto (DRAM Premium) | Médio (Eficiência de uso) |
| Capacidade | Limitada pelos slots DIMM | "Infinita" (limitada pelo rack) |
| Caso de Uso | Kernel, DBs Hot, Cache L1/L2 | DBs Cold, In-Memory Analytics, VMs |
O Veredito Técnico
O CXL 3.1 não é uma atualização incremental; é uma reescrita da forma como construímos servidores. No entanto, não caia no erro de achar que ele resolve problemas de performance mágica. Ele resolve problemas de capacidade e custo.
Para arquitetos de storage e infraestrutura, a recomendação é cautela. A tecnologia de "Tiering de Memória" via software (que move páginas quentes para a RAM local e frias para o CXL) será o componente mais crítico dessa pilha. Sem um software inteligente gerenciando onde os dados vivem, o CXL 3.1 será apenas uma maneira muito cara de deixar sua CPU esperando. Prepare-se para a desagregação, mas não jogue fora seus slots DIMM locais tão cedo.
Perguntas Frequentes (FAQ)
O CXL 3.1 substitui a memória RAM DDR5 tradicional?
Não. O CXL atua como uma camada de memória "Far Memory" (mais lenta e com maior capacidade), enquanto o DDR5 continua sendo a "Near Memory" para dados críticos de baixa latência. Tentar substituir totalmente a RAM local resultaria em degradação severa de performance para a maioria das aplicações.Qual a diferença principal entre CXL 2.0 e 3.1?
Enquanto o CXL 2.0 foca em pooling simples (um dispositivo de memória alocado para múltiplos hosts, mas um de cada vez ou particionado), o CXL 3.1 habilita malhas complexas (fabrics). Isso permite switches multinível e comunicação peer-to-peer direta entre dispositivos (ex: GPU para Memória) sem a necessidade de passar pela CPU host, reduzindo o overhead do processador.O CXL 3.1 já está disponível em servidores comerciais?
A especificação está pronta, mas o ecossistema de hardware real está atrasado. Controladores e switches totalmente compatíveis com as funcionalidades avançadas do CXL 3.1 só devem atingir maturidade comercial, estabilidade de drivers e volume significativo entre o final de 2025 e o decorrer de 2026. O que vemos hoje são majoritariamente implementações de CXL 1.1 e 2.0.
Marcus Duarte
Tradutor de Press Release
"Ignoro buzzwords e promessas de marketing para focar no que realmente importa: especificações técnicas, benchmarks reais e as letras miúdas que os fabricantes tentam esconder."