CXL 3.1 e a ascensão do memory fabric no data center moderno

Análise estratégica sobre como o protocolo CXL 3.1 transforma a memória RAM em um recurso de rede, eliminando o desperdício de 'stranded memory' e redefinindo a arquitetura de servidores corporativos.
A ineficiência da memória DRAM tornou-se o "elefante na sala" dos data centers modernos. Enquanto a capacidade de processamento (CPU/GPU) e o armazenamento persistente (NVMe) escalaram de forma agressiva na última década, a memória permaneceu presa a um modelo arquitetônico rígido, caro e localmente vinculado ao processador. O lançamento das especificações do CXL 3.1 (Compute Express Link) marca o ponto de inflexão dessa arquitetura, prometendo transformar a memória de um recurso estático em um fabric dinâmico e compartilhável.
Para analistas de infraestrutura e arquitetos de storage, o CXL não é apenas um novo barramento; é a redefinição da hierarquia de dados. Estamos observando a transição de servidores monolíticos para racks desagregados, onde a memória é provisionada sob demanda, similar ao que já fazemos com o armazenamento em redes SAN (Storage Area Network).
Resumo em 30 segundos
- O Problema: A "Stranded Memory" (memória presa e ociosa em servidores individuais) desperdiça bilhões de dólares em CAPEX anualmente nos hyperscalers.
- A Solução: O CXL 3.1 permite criar pools de memória compartilhada fora do servidor, acessíveis via switches, reduzindo a necessidade de superprovisionamento de DRAM local.
- O Impacto: Criação de uma nova camada de "Far Memory" (Tier 2), situada entre a DRAM rápida (Tier 1) e o SSD NVMe (Tier 3), otimizando custos e capacidade.
O fim da era da memória estática e o custo do desperdício
Historicamente, a compra de um servidor exigia uma aposta de longo prazo: quanto de RAM será necessário para a carga de trabalho máxima prevista nos próximos cinco anos? Se você errasse para menos, a performance degradava (swap em disco). Se errasse para mais, o capital ficava imobilizado em silício ocioso.
Estudos de mercado indicam que a utilização média de DRAM em data centers de nuvem pública oscila entre 40% e 50%. O restante é o que chamamos de Stranded Memory. Ela está lá, foi paga, consome energia para refresh, mas é inacessível para outros nós do cluster que podem estar sofrendo com falta de recursos.
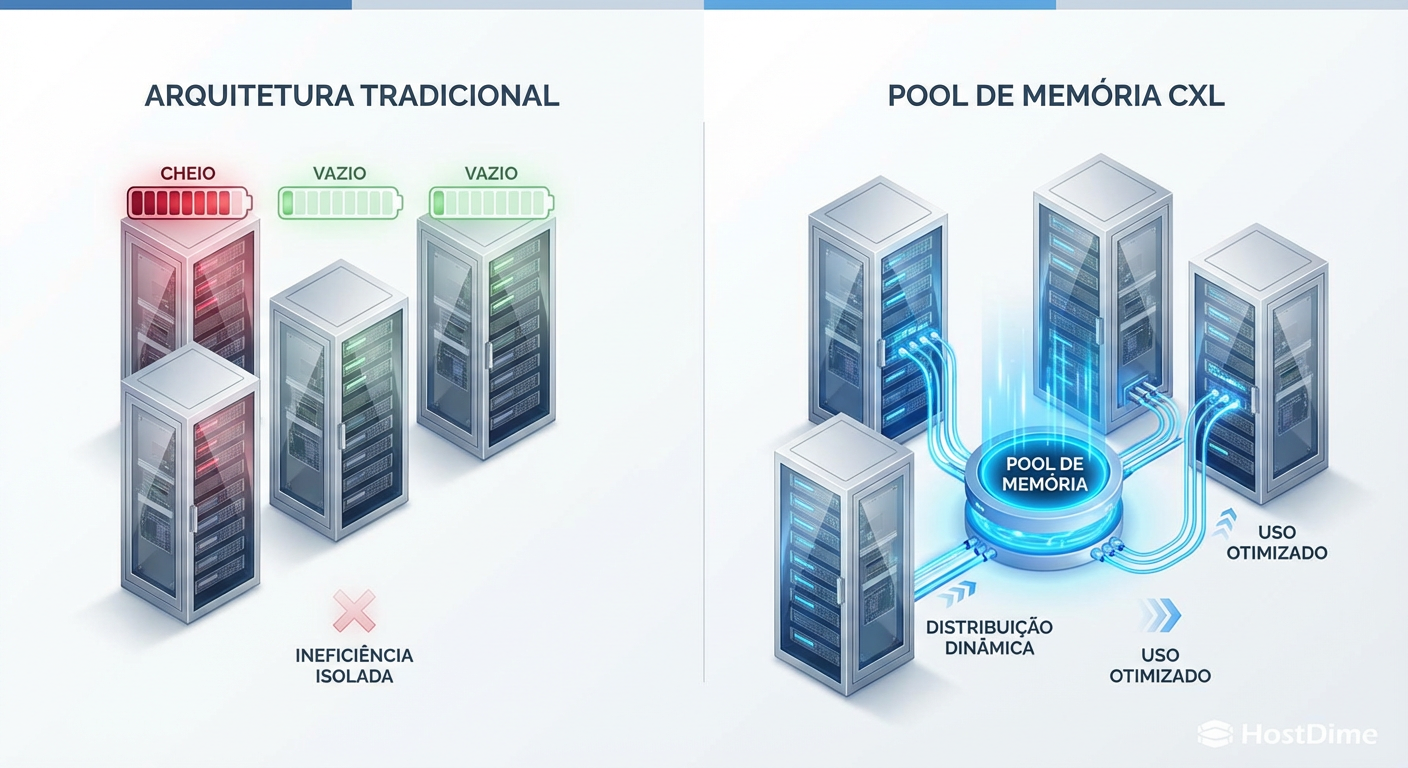 Figura: Comparativo visual entre a arquitetura tradicional com memória isolada e ineficiente versus o modelo de Memory Pooling via CXL, onde recursos são alocados dinamicamente.
Figura: Comparativo visual entre a arquitetura tradicional com memória isolada e ineficiente versus o modelo de Memory Pooling via CXL, onde recursos são alocados dinamicamente.
O CXL ataca diretamente essa ineficiência financeira. Ao desacoplar a memória da CPU, permitindo que módulos de expansão (CMM - CXL Memory Modules) sejam conectados via slots PCIe ou através de um backplane cabeado, as empresas podem reduzir a densidade de DRAM na placa-mãe (a mais cara) e confiar em pools de expansão para picos de carga.
A evolução do gargalo para a malha de memória
O protocolo CXL utiliza a camada física do PCIe (atualmente PCIe 6.0 para CXL 3.1) para transportar comandos de memória com coerência de cache. No entanto, é crucial distinguir as gerações para entender o momento atual do mercado.
O CXL 1.1 e 2.0 focavam principalmente na expansão de capacidade ponto-a-ponto. Era uma relação de um-para-um: uma CPU acessando um módulo de expansão. O CXL 3.1 altera drasticamente esse cenário ao introduzir capacidades robustas de fabric.
💡 Dica Pro: Não confunda expansão com pooling. Expansão (CXL 2.0) é apenas "mais RAM no mesmo servidor". Pooling (CXL 3.0/3.1) é "RAM compartilhada entre múltiplos servidores via switch".
Com o CXL 3.1, introduz-se o suporte a comunicação Peer-to-Peer (P2P). Isso significa que periféricos podem conversar entre si sem passar pela CPU host. Imagine uma placa de rede (NIC) gravando dados diretamente na memória de um acelerador de IA, ou um SSD NVMe transferindo dados para um pool de memória CXL. Isso reduz a latência de cauda e libera ciclos preciosos da CPU principal.
Quem ganha com a desagregação do hardware
A movimentação dos grandes players confirma que essa não é uma tecnologia de nicho. A Samsung e a SK Hynix já disputam a liderança no mercado de módulos CMM-D (CXL Memory Module - DRAM), enquanto a Micron aposta em soluções híbridas.
No entanto, o verdadeiro campo de batalha estratégico está nos controladores e switches. Empresas como Astera Labs e Marvell estão se posicionando como os "novos Broadcom" desse ecossistema, fornecendo o silício que permite a conectividade da malha.
Para o mercado de storage enterprise, isso sinaliza uma fusão de conceitos. Os fabricantes de arrays de armazenamento (como Dell, NetApp e Pure Storage) estão observando atentamente. No futuro próximo, um "Storage Array" poderá não conter apenas SSDs, mas também terabytes de memória CXL para oferecer uma camada de cache global ultra-rápida para bancos de dados in-memory como SAP HANA ou Redis.
 Figura: Detalhe interno de um rack moderno mostrando um Switch CXL central conectando lâminas de computação a gavetas de memória dedicadas, ilustrando a desagregação física do hardware.
Figura: Detalhe interno de um rack moderno mostrando um Switch CXL central conectando lâminas de computação a gavetas de memória dedicadas, ilustrando a desagregação física do hardware.
O trade-off inevitável: latência vs capacidade
É vital alinhar as expectativas: a memória CXL não é mágica. Ela introduz latência adicional devido à distância física e aos saltos nos switches e controladores. Enquanto a memória DDR5 local opera na casa dos nanosegundos (ns) baixos, o CXL adiciona uma penalidade que pode variar de 170ns a 250ns, dependendo da topologia.
Isso cria uma nova hierarquia de armazenamento no data center, onde o CXL atua como uma camada intermediária vital.
Tabela comparativa: a nova hierarquia de dados
| Característica | DRAM Local (DDR5) | CXL Memory (Tier 2) | NVMe SSD (Tier 3) |
|---|---|---|---|
| Latência Típica | < 100 ns | 170 - 300 ns | 80.000 - 100.000 ns (80-100 µs) |
| Custo por GB | Muito Alto | Alto (mas menor que DDR5 local) | Baixo |
| Capacidade | Limitada pelos slots da CPU | Alta (Expansível via Fabric) | Muito Alta |
| Persistência | Volátil | Volátil (geralmente) | Persistente |
| Caso de Uso | Kernel, Hot Data, Cache L1/L2 | In-Memory DB, AI Training Sets | Armazenamento de Dados, Cold Data |
⚠️ Perigo: Aplicações sensíveis à latência extrema (como High Frequency Trading) devem continuar priorizando a DRAM local. O CXL brilha em aplicações de throughput (largura de banda) e grandes volumes de dados, como treinamento de LLMs (Large Language Models), onde a capacidade da VRAM ou DRAM local é o gargalo principal.
A convergência entre memória e armazenamento
O CXL 3.1 também abre portas para o conceito de "Memory Semantic SSDs". No passado, tentamos isso com tecnologias como o Intel Optane, que, apesar de tecnicamente brilhante, falhou comercialmente devido ao custo e ecossistema fechado.
Com o padrão aberto do CXL, podemos ver o ressurgimento dessa classe de dispositivos. Imagine um SSD NVMe que fala a linguagem da memória (load/store) em vez da linguagem de bloco (read/write). Isso eliminaria a sobrecarga das pilhas de software de sistema de arquivos e drivers NVMe tradicionais para certas operações.
A indústria caminha para um modelo onde o sistema operacional enxerga um espaço de endereçamento plano e gigantesco. O gerenciamento de onde o dado reside (se na DRAM rápida, no CXL ou no SSD) será feito por hardware ou por hypervisors inteligentes, de forma transparente para a aplicação.
Perspectiva estratégica
A adoção do CXL 3.1 não será um evento de "troca total" (rip-and-replace), mas uma evolução gradual que acompanhará os ciclos de renovação de servidores baseados em processadores Intel Xeon 6 (Granite Rapids) e AMD EPYC (Turin e sucessores).
Para gestores de infraestrutura, a recomendação é iniciar o planejamento de arquitetura considerando a densidade de memória. Em renovações de parque previstas para os próximos 18 a 24 meses, priorize chassis e placas-mãe que possuam suporte a expansão CXL, mesmo que você não compre os módulos imediatamente. A flexibilidade de adicionar 512GB ou 1TB de RAM a um servidor existente via slot PCIe no meio do seu ciclo de vida é uma ferramenta poderosa de proteção de investimento e extensão da vida útil do ativo.
O Memory Fabric deixou de ser ficção científica para se tornar o próximo requisito padrão de arquitetura de data center de alta performance.
Perguntas Frequentes (FAQ)
O que diferencia o CXL 3.1 das versões anteriores?
Enquanto o CXL 1.1 e 2.0 focavam na expansão ponto-a-ponto (uma CPU para um dispositivo), o CXL 3.1 introduz capacidades reais de 'fabric'. Isso permite a comunicação peer-to-peer entre dispositivos e o compartilhamento global de memória (GIM) através de switches, sem a necessidade de passar pela CPU host, reduzindo latência e liberando processamento.Como o CXL 3.1 impacta o custo total de propriedade (TCO)?
A tecnologia combate diretamente a 'stranded memory' (memória presa e ociosa em servidores individuais). Ao permitir a criação de pools de memória compartilhada, os data centers podem provisionar menos RAM física total para atender à mesma carga de trabalho, reduzindo custos de CAPEX em até 30% e melhorando a eficiência energética.O CXL vai substituir a memória DRAM DDR5 tradicional?
Não. O CXL atua como uma camada de 'Tier 2' ou 'Far Memory'. A DRAM local (DDR5/DDR6) continuará existindo para dados ultra-quentes que exigem latência mínima (abaixo de 100ns), enquanto o CXL gerencia grandes volumes de dados com latência ligeiramente maior, preenchendo o abismo entre a RAM e o SSD.
Arthur Siqueira
Analista de Mercado de Storage
"Analiso o cenário macroeconômico do armazenamento corporativo. Meu foco está nos movimentos de consolidação, flutuações de market share e na saúde financeira que dita o futuro dos grandes players."