CXL: A revolução de hardware que salvará os datacenters de IA do colapso de memória

A memória CXL está redefinindo a infraestrutura de IA. Descubra como o desacoplamento de RAM e o pooling de memória via CXL 2.0/3.0 quebram o gargalo de capacidade e custo nos servidores modernos.
Estamos caminhando sonâmbulos para um precipício arquitetural. Enquanto as manchetes gritam sobre a escassez de GPUs e a corrida pelos teraflops, uma crise muito mais insidiosa e fundamental está se formando nos bastidores dos grandes datacenters e, inevitavelmente, chegará aos racks dos entusiastas. Não é uma crise de processamento. É uma crise de capacidade.
Os Grandes Modelos de Linguagem (LLMs) e as cargas de trabalho de inferência massiva devoraram a Lei de Moore no café da manhã. O crescimento da contagem de parâmetros em IA superou a capacidade da indústria de densificar a DRAM em ordens de magnitude. Estamos presos na "tirania do soquete": a ideia arcaica de que a memória RAM deve estar fisicamente soldada ou encaixada a centímetros da CPU que a controla.
Essa arquitetura monolítica acabou. O futuro do armazenamento e da memória é desagregado, fluido e composável. E a chave para essa nova realidade tem um nome: CXL (Compute Express Link).
Resumo em 30 segundos
- O Problema: A quantidade de memória RAM que você pode colocar em um servidor é limitada fisicamente pelos slots DIMM e pela integridade do sinal. A IA precisa de mais RAM do que cabe em uma placa-mãe.
- A Solução: O CXL usa o barramento PCIe (o mesmo da sua placa de vídeo e SSD NVMe) para conectar memória RAM externa com coerência de cache, permitindo expansão massiva.
- O Futuro: Memória deixa de ser um recurso fixo do servidor e vira um "pool" compartilhado na rede, acessível por qualquer máquina que precise, reduzindo custos e desperdício.
A barreira invisível da escala
Para entender por que o CXL é inevitável, precisamos olhar para a física da placa-mãe moderna. Durante décadas, vivemos confortáveis com a interface DDR (Double Data Rate). Ela é rápida, confiável e paralela. Mas ela tem um defeito fatal: exige proximidade.
Cada canal de memória adicional na CPU exige centenas de pinos no soquete. Estamos chegando ao limite físico do tamanho dos processadores. Além disso, quanto mais rápida a memória (DDR5, DDR6), menor a distância que o sinal elétrico pode percorrer sem degradação. O resultado? Menos slots de memória por canal.
Hoje, um servidor de treinamento de IA de ponta pode ter terabytes de HBM (High Bandwidth Memory) ultrarrápida, mas essa memória é escassa e custa mais que ouro. Quando o modelo não cabe na HBM, ele transborda para a DRAM do sistema. Quando não cabe na DRAM, ele vai para o SSD (NVMe). E é aí que a performance cai de um penhasco.
O CXL surge para preencher esse abismo entre a RAM local e o SSD.
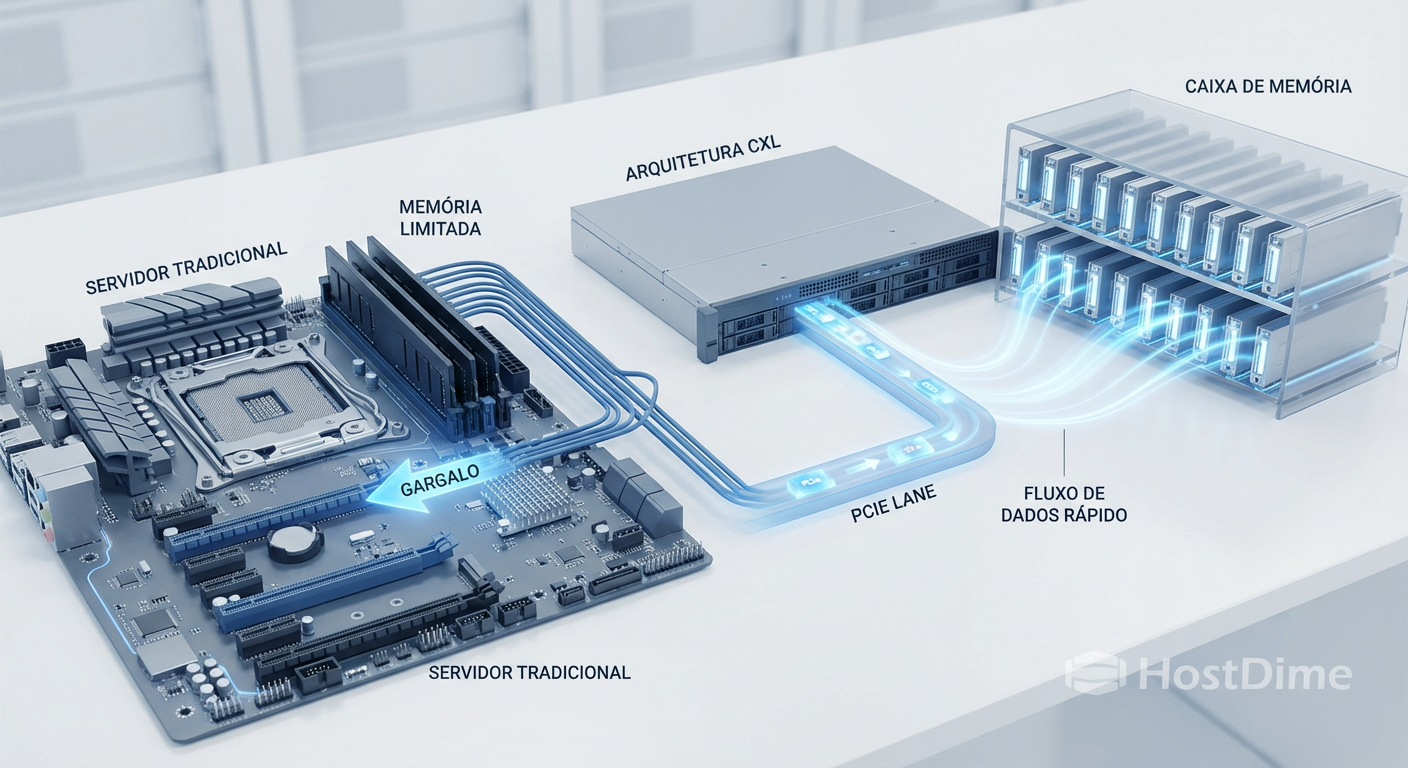 Figura: Comparação arquitetural: A limitação física dos slots DIMM tradicionais versus a expansão fluida proporcionada pelos módulos CXL via barramento PCIe.
Figura: Comparação arquitetural: A limitação física dos slots DIMM tradicionais versus a expansão fluida proporcionada pelos módulos CXL via barramento PCIe.
O desacoplamento: Memória via PCIe
O CXL é um protocolo aberto construído sobre a camada física do PCIe (Peripheral Component Interconnect Express). A partir do PCIe 5.0 e agora solidificado no PCIe 6.0, a largura de banda é suficiente para trafegar dados de memória com latência aceitável.
Mas o CXL não é apenas "RAM no slot PCIe". Se fosse só isso, seria apenas um SSD muito rápido. A mágica do CXL é a Coerência de Cache.
Quando uma CPU acessa a memória CXL, ela "sabe" que aquela memória é volátil e endereçável por byte, não por bloco (como um SSD). O protocolo CXL.mem permite que a CPU e o acelerador (GPU/FPGA) conversem e mantenham seus caches sincronizados sem o overhead de software gigantesco que teríamos ao tentar fazer isso via rede tradicional.
Isso abre portas para novos formatos de hardware. Esqueça os pentes DIMM longos e frágeis. O futuro da memória expandida se parece com um SSD Enterprise. Estamos vendo a ascensão dos formatos E1.S e E3.S (EDSFF).
💡 Dica Pro: Se você está montando um Home Lab ou servidor de armazenamento, comece a prestar atenção nos chassis que suportam drives E1.S ou E3.S. Embora hoje sejam usados para NVMe, esses mesmos slots serão os receptáculos da sua futura expansão de RAM via CXL.
Imagine inserir um módulo que parece um SSD NVMe de 2TB no seu servidor, mas o sistema operacional o reconhece instantaneamente como 2TB de memória RAM adicional. Isso já é realidade com módulos de fabricantes como Samsung e Micron lançados entre 2024 e 2025.
A economia brutal da desagregação
A verdadeira revolução não é apenas técnica, é econômica. Em datacenters de hiperescala (como AWS, Azure, Google), existe um fenômeno chamado "Stranded Memory" (Memória Encalhada).
Imagine que você tem um servidor com 1TB de RAM e 64 núcleos. Uma aplicação alocada ali usa todos os 64 núcleos, mas apenas 200GB de RAM. Os outros 800GB estão "presos". Eles não podem ser emprestados para o servidor vizinho que está desesperado por memória. Eles são desperdício puro de capital e energia (DRAM consome energia apenas para manter os dados, mesmo sem uso).
Com o CXL 2.0 e 3.0, entramos na era do Memory Pooling.
A memória sai de dentro do chassi do servidor e vai para um chassi dedicado (um "Memory Appliance"). Vários servidores se conectam a esse appliance via cabos CXL. Um orquestrador de software aloca 100GB para o Servidor A e 500GB para o Servidor B dinamicamente. Quando o Servidor A termina sua tarefa, a memória volta para o pool e pode ser realocada.
Isso reduz o TCO (Custo Total de Propriedade) de forma drástica. Estimativas da indústria sugerem que a desagregação de memória pode reduzir os custos de DRAM em datacenters em até 30% a 40% simplesmente eliminando o superprovisionamento.
Tabela Comparativa: O espectro da memória
Para situar onde o CXL se encaixa no seu ecossistema de storage e computação, veja a comparação abaixo:
| Característica | HBM (High Bandwidth Memory) | DDR5 (Local DIMM) | CXL (Memória Expandida) | SSD NVMe (Gen5) |
|---|---|---|---|---|
| Localização | Dentro do pacote da GPU/CPU | Slots na Placa-mãe | Slot PCIe / Backplane | Slot PCIe / Backplane |
| Latência Típica | < 10 ns | ~80-100 ns | ~170-250 ns | ~10.000+ ns (10µs) |
| Largura de Banda | Extrema (TB/s) | Alta (GB/s) | Alta (Limitada por PCIe lanes) | Média/Alta |
| Capacidade | Baixa (GBs) | Média (TBs) | Alta (TBs a PBs) | Muito Alta (PBs) |
| Custo por GB | Astronômico | Alto | Médio/Alto | Baixo |
| Uso Ideal | Hot Data, Pesos de IA | Computação Geral | In-Memory DB, Caching IA | Armazenamento Persistente |
Onde a física impõe limites
Não podemos ser ingênuos. O CXL não é uma bala de prata que substitui a DDR5 local para tudo. A física é implacável: distância custa tempo.
A latência de uma memória CXL (Type 3) é inerentemente maior que a da memória local. Estamos falando de um salto de ~80ns para ~200ns. Para algumas aplicações de computação de alta performance (HPC) sensíveis à latência, isso é inaceitável.
No entanto, para a grande maioria das cargas de trabalho modernas, incluindo bancos de dados em memória (como Redis ou Memcached) e inferência de IA, essa latência extra é irrelevante comparada ao ganho de capacidade. O segredo está no Tiering de Software.
Sistemas operacionais e hypervisors (como o VMware vSphere e o kernel Linux moderno) estão se tornando inteligentes o suficiente para gerenciar "Páginas Quentes" e "Páginas Frias".
Dados Quentes: Ficam na DDR5 local.
Dados Mornos: São movidos transparentemente para a memória CXL.
Dados Frios: Vão para o NVMe.
⚠️ Perigo: Implementar CXL sem uma estratégia de tiering de software adequada pode degradar a performance. Se sua CPU estiver buscando constantemente dados na "Far Memory" (CXL) para cálculos críticos, você sentirá a lentidão. A inteligência do controlador de memória e do OS é vital aqui.
 Figura: Visualização do Tiering de Memória: O fluxo dinâmico de dados quentes (CPU/DRAM), mornos (CXL) e frios (NVMe) em uma infraestrutura moderna.
Figura: Visualização do Tiering de Memória: O fluxo dinâmico de dados quentes (CPU/DRAM), mornos (CXL) e frios (NVMe) em uma infraestrutura moderna.
A transição para a infraestrutura fotônica
Se olharmos 5 a 10 anos à frente, o cobre começa a falhar. O PCIe 6.0 e 7.0 operam em frequências tão altas que o sinal elétrico mal consegue atravessar uma placa-mãe grande, quem dirá viajar por um cabo até o rack vizinho.
É aqui que o CXL encontra a Fotônica de Silício.
O futuro dos datacenters de IA não será composto por servidores individuais, mas por racks inteiros que funcionam como um único computador. O CXL será transportado por luz (fibra óptica) diretamente dos chips, usando interconexões ópticas co-empacotadas (CPO - Co-Packaged Optics).
Isso permitirá pools de memória de petabytes acessíveis com latências de nanossegundos por milhares de núcleos de processamento simultaneamente. O conceito de "meu servidor" e "seu servidor" desaparecerá. Haverá apenas "O Computador".
Para o profissional de storage e infraestrutura, isso significa que a linha entre "Armazenamento" e "Memória" vai se dissolver. Hoje gerenciamos LUNs e Volumes. Amanhã, gerenciaremos Namespaces de Memória Persistente e Volátil em um fabric unificado.
A revolução CXL não é apenas sobre ter mais RAM. É sobre reescrever as regras de como construímos computadores. A era da caixa fechada acabou. Bem-vindos à era da composição.
Perguntas Frequentes (FAQ)
O que é CXL e por que é importante para IA?
CXL (Compute Express Link) é um padrão de interconexão aberto que permite conectar memória, aceleradores e processadores com alta largura de banda e baixa latência. Para IA, ele é crucial pois permite expandir a capacidade de RAM muito além dos limites físicos dos slots DIMM da placa-mãe, resolvendo gargalos de memória em grandes modelos de linguagem (LLMs).Qual a diferença de performance entre memória CXL e DDR5 local?
A memória CXL (Type 3) adiciona uma latência extra em comparação à DDR5 conectada diretamente ao soquete da CPU, geralmente na faixa de 170-250ns (latência de 'far memory') contra ~80-100ns da memória local. No entanto, com técnicas de tiering de software, o impacto na performance real da aplicação é minimizado.O que é Memory Pooling no contexto de CXL 2.0?
Memory Pooling permite que um conjunto de módulos de memória CXL seja compartilhado dinamicamente entre vários servidores. Em vez de cada servidor ter RAM ociosa ('stranded memory'), um pool central aloca memória para quem precisa no momento, aumentando drasticamente a eficiência de utilização e reduzindo custos (TCO).
Julian Vance
Futurista de Tecnologia
"Exploro as fronteiras da infraestrutura, do armazenamento em DNA à computação quântica. Ajudo líderes a decodificar o horizonte tecnológico e construir o datacenter de 2035 hoje."