CXL e o Fim da Memória Local: Redesenhando a Infraestrutura de IA em 2026

A desagregação de memória via CXL 3.1 não é apenas uma tendência, é uma necessidade física. Analisamos o impacto no TCO, a latência real de 200ns e como arquitetar pools de memória para clusters de IA.
A arquitetura de servidores x86, como a conhecemos nas últimas três décadas, atingiu um muro de concreto em 2026. Não estamos falando apenas da Lei de Moore ou da densidade de transistores, mas de um problema muito mais pragmático e financeiramente doloroso: o acoplamento rígido entre computação e memória.
Em projetos de infraestrutura para Inteligência Artificial e bancos de dados em memória (in-memory databases), observamos um padrão alarmante. Para obter a capacidade de memória necessária para rodar um modelo de linguagem grande (LLM) ou um cluster de vetores, somos forçados a superprovisionar núcleos de CPU que nunca serão utilizados. Você compra o processador mais caro não pelos seus ciclos de clock, mas porque ele é o único que suporta 4TB de RAM.
Essa ineficiência estrutural é o que o Compute Express Link (CXL) veio resolver. Se você ainda trata memória como um componente estático soldado à placa-mãe, sua arquitetura já está obsoleta.
Resumo em 30 segundos
- O Problema: A "memória ilhada" (stranded memory) desperdiça até 50% da DRAM em datacenters, pois a memória está presa a CPUs específicas e não pode ser compartilhada.
- A Solução: O CXL permite criar pools de memória desagregada via barramento PCIe, acessíveis por múltiplos servidores com latência próxima à da DRAM local.
- O Resultado: Redução drástica no TCO ao permitir que a capacidade de memória escale independentemente da computação, viabilizando modelos de IA massivos sem comprar CPUs desnecessárias.
O custo invisível da memória ilhada em clusters de inferência
Em arquitetura de sistemas distribuídos, a eficiência de utilização de recursos é o "Santo Graal" do Custo Total de Propriedade (TCO). No entanto, a realidade dos datacenters em 2026 mostra um cenário diferente. A fragmentação de recursos, ou stranded memory, é o imposto oculto que drena orçamentos de TI.
Imagine um cluster Kubernetes rodando cargas de trabalho mistas. O Servidor A está utilizando 90% da sua CPU, mas apenas 30% da sua memória. O Servidor B, rodando um banco de dados vetorial para RAG (Retrieval-Augmented Generation), está com a memória 100% tomada, causando thrashing, mas sua CPU está em 10%.
No modelo tradicional, a memória livre do Servidor A é inútil para o Servidor B. Ela está "ilhada". Você pagou por ela, ela está consumindo energia (DRAM consome watts significativos apenas para manter o estado dos dados), mas não gera valor.
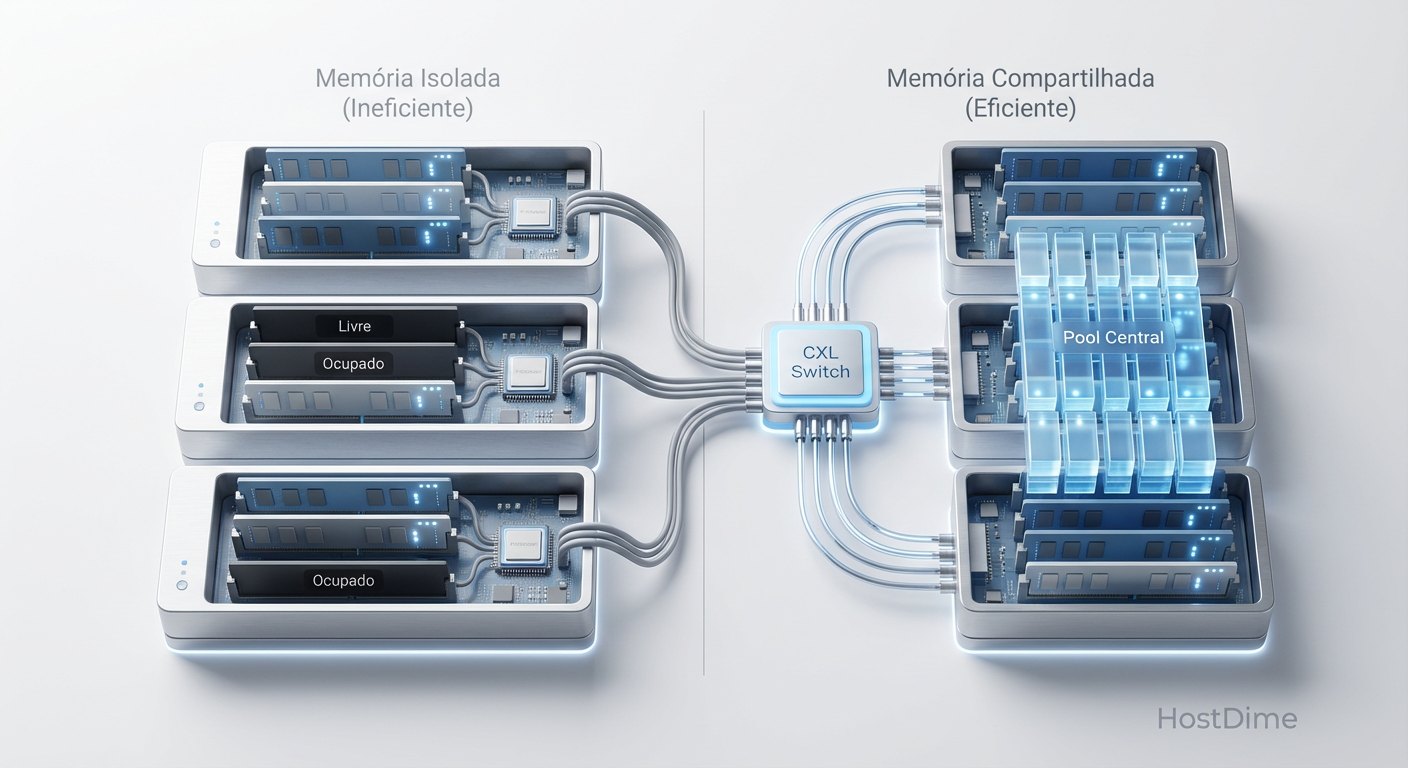 Fig. 1: O problema da fragmentação de recursos (Stranded Memory) vs. a eficiência do Pooling via CXL.
Fig. 1: O problema da fragmentação de recursos (Stranded Memory) vs. a eficiência do Pooling via CXL.
Com a introdução de pools de memória via CXL 2.0 e 3.0, quebramos essa barreira física. A memória deixa de ser um recurso local para se tornar um recurso de cluster. Se o Servidor B precisa de mais 512GB para um pico de carga, ele pode alocar dinamicamente do pool compartilhado, sem a necessidade de intervenção física ou reinicialização. Isso eleva a utilização média de memória de 40-50% para patamares acima de 85%.
A física do gargalo de von Neumann e a saturação dos canais DDR5
Para entender por que precisamos de uma nova interconexão, precisamos olhar para a física da placa-mãe. A arquitetura de von Neumann, onde dados e instruções trafegam pelo mesmo barramento, está sufocada.
Os processadores modernos, como os EPYC da AMD ou os Xeons da Intel, escalaram o número de núcleos de forma agressiva. No entanto, o número de canais de memória (o caminho físico entre a CPU e o pente de RAM) não cresceu na mesma proporção. Adicionar mais canais DDR5 exige mais pinos no soquete da CPU e mais trilhas na placa-mãe (PCB), aumentando a complexidade e o custo de fabricação a níveis proibitivos.
💡 Dica Pro: Ao desenhar especificações de servidores para 2026, não olhe apenas para a largura de banda teórica (GB/s). Calcule a largura de banda por núcleo. Você notará que, apesar do DDR5 ser rápido, a largura de banda disponível para cada core individual está diminuindo em CPUs de alta densidade.
O CXL utiliza a interface física do PCIe (atualmente PCIe 6.0 em implementações de ponta) para expandir a largura de banda e a capacidade de memória. Diferente do PCIe tradicional, que trata dispositivos como periféricos de I/O (entrada/saída), o protocolo CXL.mem permite que a CPU acesse essa memória externa com semântica de load/store.
Isso significa que, para o processador e para o sistema operacional, a memória conectada via CXL parece memória local. O controlador de memória não está mais limitado à área física ao redor do soquete da CPU.
Por que o tiering via software em NVMe falha na latência de cauda
Uma pergunta recorrente em reuniões de arquitetura é: "Por que não usamos apenas SSDs NVMe rápidos e fazemos tiering via software ou swap?"
A resposta reside na ordem de grandeza da latência. Mesmo os SSDs Enterprise mais rápidos de 2026, utilizando NAND de baixa latência (como XL-FLASH ou Z-NAND), operam na casa dos microssegundos (µs). A memória DRAM opera em nanossegundos (ns).
Existe um abismo de desempenho aqui.
DRAM Local: ~80-100 ns
Memória CXL: ~170-250 ns (apenas ~100ns de penalidade adicional)
SSD NVMe (Gen5/Gen6): ~10.000 - 20.000 ns (10-20 µs)
Quando uma aplicação de IA precisa acessar um peso de modelo que não está na memória, e o sistema precisa buscá-lo no NVMe, a CPU para e espera. Esses "stalls" se acumulam. Em sistemas de inferência em tempo real, isso destrói a latência de cauda (P99). O usuário percebe isso como uma pausa na geração do texto ou uma falha na transação.
 Fig. 2: A hierarquia de latência em 2026. O CXL preenche o abismo de desempenho entre a DRAM local e o armazenamento Flash.
Fig. 2: A hierarquia de latência em 2026. O CXL preenche o abismo de desempenho entre a DRAM local e o armazenamento Flash.
O tiering via software (como o swap do Linux ou soluções proprietárias de memory paging) introduz overhead de interrupções e trocas de contexto no kernel. O CXL resolve isso via hardware. A latência do CXL é determinística e baixa o suficiente para que a CPU continue operando sem as paradas catastróficas associadas ao acesso a disco, mesmo que esse disco seja um NVMe de última geração.
Implementando desagregação com controladores CXL e memória tierizada
A implementação prática dessa tecnologia em 2026 envolve novos componentes no rack. Não estamos mais apenas plugando DIMMs. Estamos lidando com módulos E1.S ou E3 (formatos EDSFF, originalmente de SSDs) que contêm DRAM e um controlador CXL inteligente.
Empresas como Astera Labs, Marvell e Samsung desenvolveram controladores que gerenciam a coerência de cache e o tráfego de dados. O dispositivo CXL funciona como um "tradutor" que fala a língua da memória (DDR) de um lado e a língua do barramento serial (PCIe/CXL) do outro.
⚠️ Perigo: A compatibilidade de BIOS e Kernel é crítica. Para utilizar CXL Type 3 (Expansão de Memória), seu kernel Linux deve ser versão 6.x ou superior com suporte a Tiered Memory ativado e configurado corretamente (numactl, CXL drivers). Sem isso, o sistema verá o dispositivo, mas não saberá como alocar páginas nele de forma eficiente.
A estratégia de implementação recomendada é o Tiering Transparente. O hardware e o sistema operacional gerenciam a colocação de dados. Dados "quentes" (acessados frequentemente) ficam na DRAM local (Tier 0). Dados "mornos" são movidos automaticamente para a memória CXL (Tier 1). Dados frios vão para o armazenamento NVMe (Tier 2).
 Fig. 3: Controladores inteligentes como o Leo da Astera Labs gerenciam a coerência de cache e o roteamento de dados no barramento PCIe 6.0.
Fig. 3: Controladores inteligentes como o Leo da Astera Labs gerenciam a coerência de cache e o roteamento de dados no barramento PCIe 6.0.
O controlador CXL atua quase como um controlador RAID sofisticado, mas para memória volátil, garantindo integridade e corrigindo erros (ECC) antes que eles cheguem à CPU.
Impacto no TCO e a métrica de custo por gigabyte efetivo
Como arquitetos, nossa responsabilidade final é com a viabilidade econômica da solução. O CXL altera fundamentalmente a matemática do armazenamento e memória.
Historicamente, o custo por GB da DRAM é estático. Com CXL, introduzimos a variável de utilização.
Considere o seguinte cenário comparativo para um cluster de treinamento de IA:
| Métrica | Arquitetura Tradicional | Arquitetura com CXL Pooling |
|---|---|---|
| Memória por Nó | 2TB (Fixo) | 512GB (Local) + Pool Compartilhado |
| Utilização Média | 40% | 85% |
| Overprovisioning | Necessário (para picos) | Eliminado (alocação dinâmica) |
| Custo de Upgrade | Trocar DIMMs (Downtime) | Adicionar Módulos ao Pool (Hot-plug) |
O "Custo por Gigabyte Efetivo" cai drasticamente porque paramos de comprar memória que fica ociosa. Além disso, o CXL permite o uso de mídias de memória alternativas. Não precisamos usar a DDR5 mais cara e rápida para o Tier 1. Podemos usar DDR4 reaproveitada ou novas tecnologias de Storage Class Memory (SCM) que são mais baratas que DRAM e mais rápidas que NAND, conectadas via CXL.
Isso permite estender a vida útil dos servidores. Em vez de substituir um servidor inteiro porque ele atingiu o limite de memória, adicionamos um chassi de expansão de memória CXL (JBOM - Just a Bunch of Memory).
O futuro é desagregado
A transição para CXL não é apenas uma atualização de hardware; é uma mudança de paradigma. Estamos saindo de uma era "centrada no servidor", onde cada caixa deve ser autossuficiente, para uma era "centrada no dado", onde recursos são compostos dinamicamente conforme a necessidade da carga de trabalho.
Para 2026 e além, a recomendação é clara: evite investir pesadamente em arquiteturas monolíticas com quantidades massivas de RAM local, a menos que sua carga de trabalho exija latência absoluta de Tier 0 em 100% dos dados (o que é raro). A flexibilidade do CXL oferece um seguro contra a imprevisibilidade dos requisitos dos modelos de IA futuros.
Se sua infraestrutura de armazenamento e memória não for elástica, ela será o gargalo financeiro que inviabilizará seus projetos de inovação.
Perguntas Frequentes
1. O CXL substitui a memória RAM tradicional (DIMMs)? Não. A memória local (conectada diretamente à CPU) sempre oferecerá a menor latência possível. O CXL atua como um complemento, uma camada de capacidade expandida que preenche a lacuna entre a RAM local e o armazenamento SSD.
2. Posso usar CXL em servidores antigos? Não. O suporte a CXL exige processadores compatíveis (como Intel Sapphire Rapids/Granite Rapids ou AMD Genoa/Turin e sucessores) e placas-mãe com slots PCIe 5.0 ou 6.0 cabeados para sinalização CXL.
3. Qual a diferença entre CXL 2.0 e 3.0? O CXL 2.0 introduziu o conceito de Switching e Pooling (compartilhamento de memória entre hosts). O CXL 3.0, baseado em PCIe 6.0, dobra a largura de banda e melhora a coerência de cache para compartilhamento de memória peer-to-peer, permitindo que GPUs acessem a memória umas das outras sem passar pela CPU host.
4. O CXL afeta o desempenho de bancos de dados como Redis ou SAP HANA? Depende. Para bancos de dados in-memory, o CXL permite bancos muito maiores do que caberiam em um único servidor. Embora a latência seja ligeiramente maior, o ganho de capacidade e a eliminação de I/O de disco geralmente resultam em um desempenho sistêmico superior e custo menor.
Referências & Leitura Complementar
Compute Express Link™ (CXL™) 3.1 Specification. CXL Consortium, 2023. Disponível para membros do consórcio. Define os padrões de sinalização e coerência para a geração atual.
JEDEC DDR5 SDRAM Standard (JESD79-5C). JEDEC Solid State Technology Association. Fundamental para entender as limitações físicas que o CXL busca mitigar.
Astera Labs Leo Memory Connectivity Platform Datasheet. Documentação técnica real sobre controladores CXL e gerenciamento de latência em hardware.
Meta's Tectonic File System & Tiered Memory Architecture. Papers de engenharia da Meta detalhando o uso de memória tierizada em escala para treinamento de IA.

Otávio Henriques
Arquiteto de Soluções Enterprise
"Com duas décadas desenhando infraestruturas críticas, olho além do hype. Foco em TCO, resiliência e trade-offs, pois na arquitetura corporativa a resposta correta quase sempre é 'depende'."