Cyber-resiliência Radical: Por que Snapshots e MFA são Apenas o Começo

Snapshots e MFA não garantem sobrevivência. Descubra como a Engenharia do Caos, imutabilidade e testes destrutivos constroem uma verdadeira cyber-resiliência.
Aqui está o artigo, escrito sob a perspectiva da Engenharia do Caos, focado em destruir premissas frágeis para construir sistemas antifrágeis.
Por: Engenheiro do Caos
Vamos ser brutalmente honestos: a sua "estratégia de segurança" provavelmente é uma ilusão de ótica. Você implementou a Autenticação Multifator (MFA), configurou snapshots diários e agora dorme tranquilo, acreditando que construiu uma fortaleza. A realidade? Você apenas trancou a porta da frente de uma casa feita de palha.
No mundo da Engenharia do Caos, operamos sob uma premissa desconfortável, mas libertadora: a falha não é uma questão de "se", mas de "quando". Sistemas distribuídos são complexos demais para serem perfeitamente seguros. A complexidade é o refúgio das vulnerabilidades. Se o seu plano de defesa depende inteiramente de impedir a entrada do atacante, você já perdeu.
A verdadeira resiliência cibernética — a radical — não se trata de prevenir o ataque, mas de sobreviver a ele. É sobre garantir que, quando o mundo arder (e ele vai), o seu negócio continue de pé. Vamos desmontar o mito da segurança tradicional e reconstruí-lo com base na sobrevivência.
O Mito da Fortaleza de Papel: Quando o Básico Falha
O mercado vende a ideia de que "higiene básica" é sinônimo de proteção robusta. Não é. É apenas o mínimo para não ser negligente. Em 2024 e 2025, vimos a ascensão meteórica de ataques que tornam o MFA tradicional obsoleto e os snapshots inúteis.
A Ilusão do MFA
O MFA é vital, mas não é infalível. Grupos como o Lapsus$ popularizaram o MFA Fatigue (bombardeio de notificações até o usuário ceder) e ataques de Adversary-in-the-Middle (AiTM), que capturam o token de sessão, não apenas a senha. Se a sua segurança para na autenticação, um token roubado transforma seu atacante em um administrador legítimo em segundos.
O Engodo do Snapshot
"Se formos atacados por Ransomware, restauramos o backup." Essa frase é dita em salas de reunião por quem não entende a anatomia de um ataque moderno. Ransomwares contemporâneos não criptografam apenas os dados "quentes"; eles caçam seus backups. Se o seu sistema de snapshot vive no mesmo control plane (plano de controle) que seus dados de produção — ou seja, acessível pelas mesmas credenciais de admin — ele será deletado ou criptografado antes mesmo que você receba o alerta de resgate.
Um snapshot acessível é apenas um dado que ainda não foi sequestrado.
Arquitetura de Sobrevivência: Imutabilidade Real e Air-Gapping Lógico
Para sobreviver, precisamos remover a capacidade humana (e a de credenciais comprometidas) de alterar a história. Precisamos de Imutabilidade.
A imutabilidade real significa que, uma vez escrito, o dado não pode ser alterado ou deletado por um período definido, nem mesmo pelo usuário "root" da conta.
WORM e Object Lock
A implementação técnica disso reside no conceito WORM (Write Once, Read Many). Em provedores de nuvem como AWS ou Azure, isso se traduz em funcionalidades como o S3 Object Lock em modo Compliance. Neste modo, nem a AWS, nem você, nem o hacker que roubou suas chaves de API podem deletar o backup antes do período de retenção expirar. É uma trava matemática e contratual.
Air-Gapping Lógico
O antigo "Air-Gap" físico (fitas em um caminhão) é lento demais para o RTO (Recovery Time Objective) moderno. A resposta é o Air-Gap Lógico:
Isolamento de Contas: Seus backups vivem em uma conta ou assinatura de nuvem totalmente separada, em uma Organização diferente.
Pull, não Push: A conta de backup "puxa" os dados da produção. A produção não tem permissão de escrita no cofre. Se a produção for comprometida, o atacante encontra uma porta de saída fechada.
Isso cria uma barreira de sobrevivência. Mesmo que a produção seja terraplanada, o histórico permanece intocado.
Reduzindo o 'Blast Radius': Segmentação e Microperímetros
Na Engenharia do Caos, falamos obsessivamente sobre Blast Radius (Raio de Explosão). Se um componente falha, quantos outros ele leva junto? Na segurança, a pergunta é: se um container for comprometido, o atacante ganha acesso a todo o cluster Kubernetes?
A maioria das redes corporativas ainda opera como um ovo: duro por fora (firewall de borda), mas mole por dentro. Uma vez ultrapassada a casca, o movimento lateral é trivial.
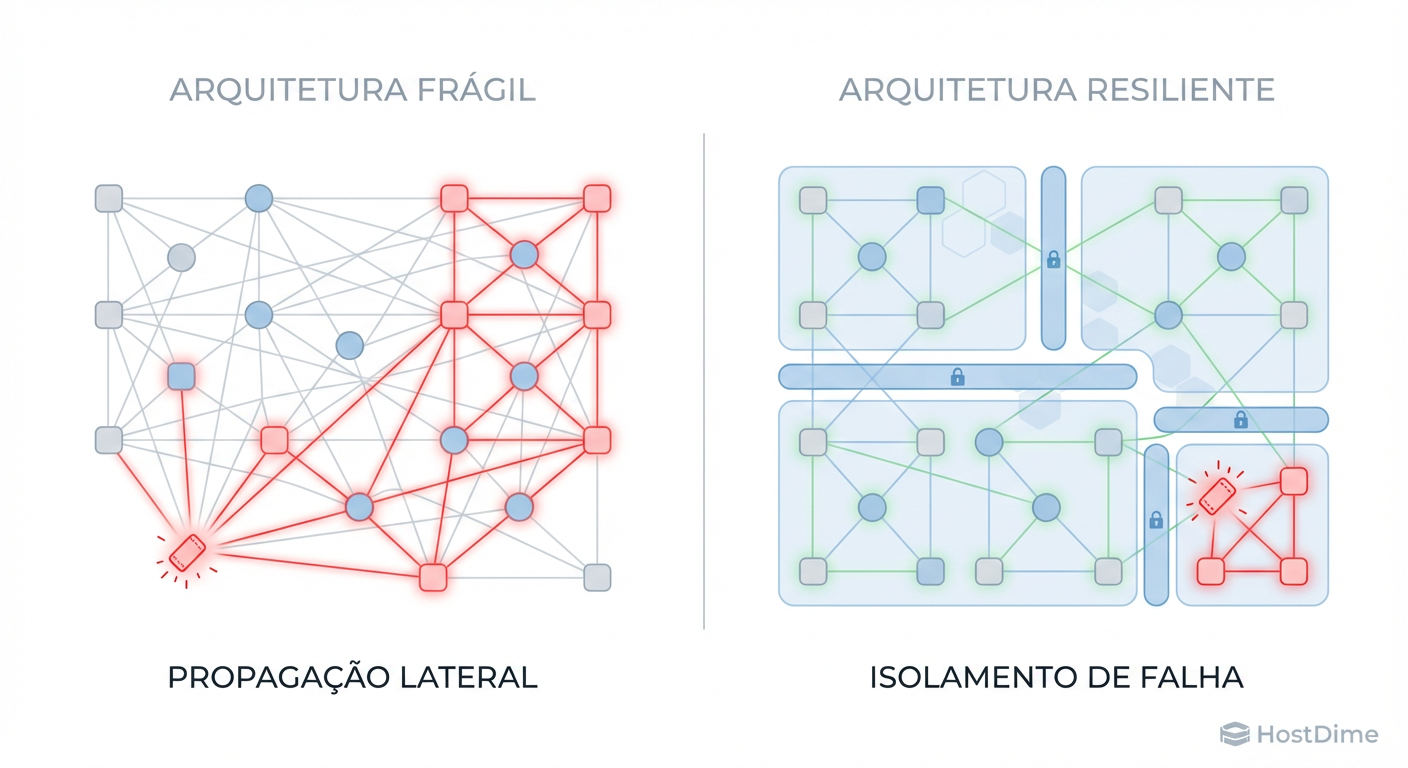 Figura: Fig. 1: A diferença entre resistir e falhar catastroficamente. A segmentação limita o 'Blast Radius' de um ataque.
Figura: Fig. 1: A diferença entre resistir e falhar catastroficamente. A segmentação limita o 'Blast Radius' de um ataque.
Estratégia de Contenção
A segmentação moderna rejeita a confiança implícita. Não importa se o tráfego vem do servidor de RH ou do banco de dados; ele deve ser verificado.
Micro-segmentação: Utilizando tecnologias como eBPF (ex: Cilium), podemos definir políticas de rede na camada 7 (aplicação). O serviço A só fala com o serviço B na rota
/api/v1/data. Qualquer outra tentativa é bloqueada e logada.Identidade como Perímetro: O endereço IP é irrelevante. O que importa é a identidade criptográfica da carga de trabalho (SPIFFE/SPIRE).
Ao reduzir o Blast Radius, transformamos um evento de extinção em um incidente gerenciável. O atacante compromete um pod, mas se vê preso em uma jaula digital, incapaz de saltar para o banco de dados principal.
Injetando Falhas: Validando a Segurança com Engenharia do Caos (Security Chaos Engineering)
Aqui é onde nos separamos dos amadores. A maioria das empresas assume que seus controles de segurança funcionam. O Engenheiro do Caos prova que eles funcionam (ou não) quebrando-os propositalmente.
Security Chaos Engineering (SCE) não é sobre criar vulnerabilidades, mas sobre injetar falhas para verificar se os mecanismos de defesa reagem como esperado.
O Ciclo de Experimentação
Não basta instalar um WAF (Web Application Firewall) e esperar o melhor. Você precisa atacá-lo.
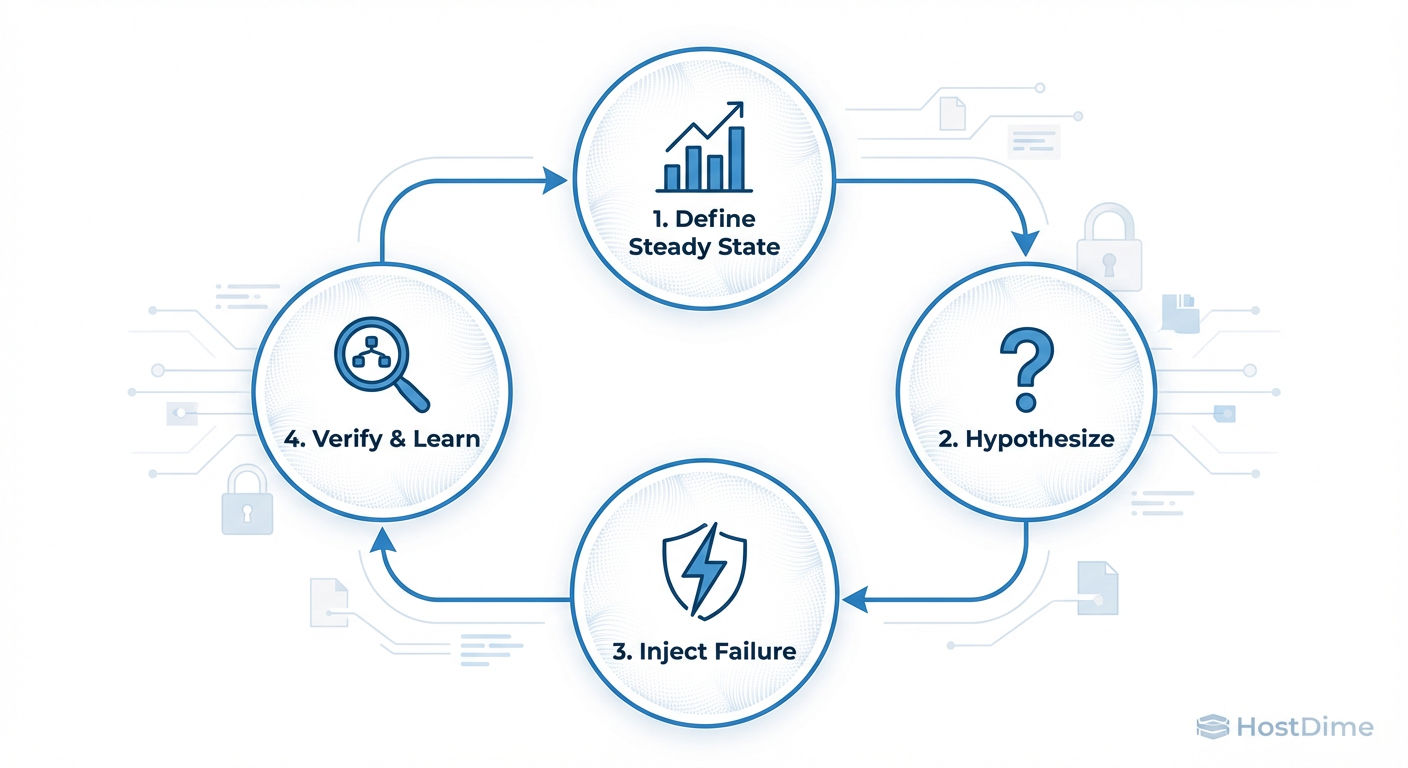 Figura: Fig. 2: O ciclo da Engenharia do Caos aplicada à Segurança. Não assuma que funciona; quebre para provar.
Figura: Fig. 2: O ciclo da Engenharia do Caos aplicada à Segurança. Não assuma que funciona; quebre para provar.
Exemplos Práticos de Experimentos de SCE:
| Hipótese | Injeção de Falha (Ação) | Expectativa (Steady State) | Realidade Comum (Falha) |
|---|---|---|---|
| "O WAF bloqueia SQL Injection" | Disparar tráfego malicioso controlado via ferramenta de teste. | WAF bloqueia, IP é banido, alerta é gerado no SIEM. | WAF bloqueia, mas nenhum alerta é gerado (Silêncio é perigoso). |
| "Permissões IAM são restritas" | Tentar acessar um bucket S3 sensível com uma role de um microserviço comprometido. | Acesso Negado (403 Forbidden). | Acesso Permitido (Role com S3:* esquecida). |
| "Failover de Firewall funciona" | Derrubar o Firewall primário durante pico de tráfego. | Tráfego migra para o secundário sem perda de pacotes. | Conexões caem, sistema entra em colapso ("Split-brain"). |
Ferramentas como Chaos Mesh ou Gremlin permitem orquestrar esses ataques de forma controlada. Se você não injetar a falha, o atacante o fará. E ele não fará isso em horário comercial com a equipe de prontidão observando.
Game Days: Simulando o Apocalipse numa Terça-feira
Tecnologia é fácil; pessoas são difíceis. A ferramenta mais resiliente do mundo falha se o operador humano entrar em pânico. É aqui que entram os Game Days.
Um Game Day não é um teste de penetração (Pentest). É um exercício de resposta a incidentes em tempo real, focado na dinâmica da equipe e nos processos.
O Fator Humano
Durante um Game Day, simulamos um cenário catastrófico — por exemplo, "Ransomware detectado em 30% dos servidores de produção". O objetivo é responder a perguntas críticas que manuais em PDF não respondem:
Acesso: As pessoas certas têm acesso às ferramentas de emergência ou as credenciais estão no 1Password de alguém que está de férias?
Comunicação: Onde a equipe se reúne se o Slack/Teams corporativo estiver comprometido? (Vocês têm um canal out-of-band no Signal?)
Decisão: Quem tem autoridade para "puxar o plugue" e desligar a operação para conter o sangramento? Essa decisão demora 5 minutos ou 2 horas de burocracia?
A resiliência é construída na memória muscular da equipe. Se a primeira vez que sua equipe lida com um ataque real for durante o ataque real, o caos vencerá.
Veredito Técnico: A Resiliência é um Hábito, não um Checkbox
A busca pela "segurança total" é uma falácia cara. O modelo mental deve mudar de "como evito ser atingido?" para "o quanto eu aguento apanhar e continuar de pé?".
Snapshots e MFA são a fundação, não o teto. A verdadeira resiliência cibernética exige uma arquitetura que pressupõe a violação (Assume Breach), que isola o dano através de segmentação impiedosa e que protege o histórico com imutabilidade matemática.
Mas, acima de tudo, exige a coragem de testar suas próprias defesas. Introduzir turbulência intencional — seja derrubando firewalls ou simulando sequestro de dados — é a única maneira de garantir que, quando a tempestade real chegar, sua organização não seja apenas mais uma estatística nos relatórios de vazamento de dados.
Abrace o caos. Domine a falha. Sobreviva.
Referências & Leitura Complementar
Para aqueles que desejam aprofundar a técnica por trás da filosofia, recomendo as seguintes leituras canônicas e especificações:
NIST SP 800-160 Vol. 2 Rev. 1: Developing Cyber-Resilient Systems: A Systems Security Engineering Approach. (O padrão ouro para engenharia de sistemas resilientes).
Principles of Chaos Engineering: principlesofchaos.org. (O manifesto original que define a disciplina).
AWS Whitepaper: Ransomware Risk Management on AWS Using the NIST Cyber Security Framework (CSF).
RFC 9113 (HTTP/2) e RFC 8446 (TLS 1.3): Entender os protocolos é essencial para saber como quebrá-los e protegê-los.
Kelly Shortridge & Aaron Rinehart: Security Chaos Engineering: Sustaining Resilience in Software and Systems (O'Reilly Media). A leitura obrigatória para conectar os pontos entre caos e segurança.

Magnus Vance
Engenheiro do Caos
"Quebro sistemas propositalmente porque a falha é inevitável. Transformo desastres simulados em vacinas para sua infraestrutura. Se não sobrevive ao meu caos, não merece estar em produção."