Datastores, Multipath e Snapshots: A Tríade da Lentidão Invisível

Descubra por que sua VM está lenta mesmo com discos rápidos. Uma análise técnica sobre snapshots órfãos, locking ATS e o parâmetro IOPS=1 no multipathing.
Você já esteve naquela sala de guerra onde o administrador de virtualização jura que a VM está lenta, mas o administrador de storage mostra o painel do array All-Flash com latência sub-milissegundo e diz: "O problema não é aqui"? Se você trabalha com infraestrutura há tempo suficiente, essa é uma terça-feira comum.
O problema é que ambos podem estar certos. Existe uma camada de abstração crítica entre o sistema operacional convidado (Guest OS) e o bloco físico no disco: o hipervisor. É nessa camada, invisível para o monitoramento tradicional do storage array e muitas vezes obscura para o admin de SO, que a performance morre silenciosamente. Não estamos falando de discos lentos, mas de como o hipervisor gerencia o acesso a esses discos através de Datastores, caminhos (paths) e mecanismos de bloqueio.
Quando a latência dispara mas o disco está saudável, geralmente estamos lidando com uma ineficiência na pilha de I/O do kernel, não na mídia física. Vamos dissecar a mecânica por trás de snapshots esquecidos, políticas de multipath mal configuradas e o pesadelo dos bloqueios SCSI.
Resumo em 30 segundos
- Snapshots não são backups: Cada snapshot ativo cria um arquivo delta que força o hipervisor a realizar leituras recursivas, multiplicando o I/O e aumentando a latência drasticamente conforme a cadeia cresce.
- O padrão mente: A configuração padrão de Multipath (Round Robin) em muitos hipervisores troca de caminho a cada 1000 I/Os, o que é ineficiente para All-Flash. O ajuste para
IOPS=1é mandatório para balanceamento real.- Bloqueios ocultos: Falhas no mecanismo VAAI/ATS podem fazer o host reverter para Reservas SCSI legadas, bloqueando uma LUN inteira para escrever um único metadado, causando o efeito "vizinho barulhento".
A mecânica destrutiva dos snapshots e delta disks
O conceito de snapshot é frequentemente mal compreendido como uma cópia estática. No mundo VMware e KVM (qcow2), um snapshot é, na verdade, um ponto de divergência. Quando você cria um snapshot, o disco base torna-se somente leitura. Todas as novas gravações são redirecionadas para um novo arquivo, frequentemente chamado de "delta disk" ou "child disk".
O problema de performance surge na leitura. Para o sistema operacional convidado ler um bloco de dados, o hipervisor precisa determinar qual arquivo na cadeia de snapshots detém a versão mais recente daquele bloco.
O custo da recursividade (RTO - Read Traversal Overhead)
Imagine uma VM com um disco base e três snapshots em cadeia (Base -> Snap1 -> Snap2 -> Snap3). O estado atual é gravado no Snap3. Se a VM solicita a leitura do Bloco A:
O hipervisor verifica o Snap3. O Bloco A foi modificado aqui? Não.
Verifica o Snap2. Modificado aqui? Não.
Verifica o Snap1. Modificado aqui? Sim.
Lê o dado do Snap1.
 Figura: A penalidade de leitura em cadeias de snapshots: cada nível adiciona overhead de metadados e busca.
Figura: A penalidade de leitura em cadeias de snapshots: cada nível adiciona overhead de metadados e busca.
Como vemos na imagem acima, cada "salto" nessa verificação adiciona latência de CPU e overhead de metadados. Em discos mecânicos (HDD), isso também causava seek time adicional, pois os arquivos delta poderiam estar fragmentados em locais diferentes do Datastore. Em All-Flash, o seek time é mitigado, mas o overhead de processamento de metadados e a amplificação de I/O permanecem.
⚠️ Perigo: Se você tem snapshots com mais de 72 horas em um ambiente de produção de alto I/O, você não tem um recurso de proteção de dados; você tem uma bomba-relógio de performance. O processo de consolidação (Delete All) de um snapshot grande gera uma quantidade massiva de I/O, podendo "atordoar" (stun) a VM por segundos ou minutos, derrubando aplicações sensíveis.
SEsparse vs. VMFSsparse
Em versões modernas de hipervisores, formatos como SEsparse (Space Efficient) tentam mitigar isso com tamanhos de bloco maiores e melhor manipulação de metadados, mas a física não muda: redirecionamento de I/O custa caro. Um Datastore saudável não deve ter VMs rodando sobre snapshots permanentemente.
Conflitos de reserva SCSI e a falha do ATS
Se os snapshots são o assassino silencioso da performance individual da VM, os mecanismos de bloqueio (locking) são os assassinos do Datastore inteiro.
Para garantir a integridade dos dados em um sistema de arquivos clusterizado (como VMFS ou GFS2), onde múltiplos hosts acessam o mesmo volume físico simultaneamente, é necessário um mecanismo de arbitragem. Antigamente, usávamos as Reservas SCSI (SCSI Reservations).
O problema da Reserva SCSI Legada
No modelo antigo, se um host precisasse atualizar metadados do volume (ex: criar um arquivo, expandir um disco, atualizar a hora de acesso), ele enviava um comando RESERVE SCSI. Isso bloqueava toda a LUN para todos os outros hosts até que o comando RELEASE fosse enviado.
Isso é o equivalente a fechar uma rodovia inteira só para pintar uma faixa de pedestres. A latência de todas as outras VMs naquele Datastore disparava.
A promessa do ATS (Atomic Test & Set)
Com a introdução do VAAI (vStorage APIs for Array Integration), passamos a usar o ATS. O ATS permite o bloqueio granular apenas do setor do disco onde o metadado reside, não da LUN inteira. É cirúrgico e eficiente.
No entanto, o ATS pode falhar. Existem cenários — frequentemente ligados a firmwares de storage desatualizados ou saturação de fila — onde o comando ATS retorna um "Miscompare" ou timeout. Quando isso acontece repetidamente, o kernel do hipervisor pode decidir, por segurança, desativar o ATS e reverter para as Reservas SCSI legadas.
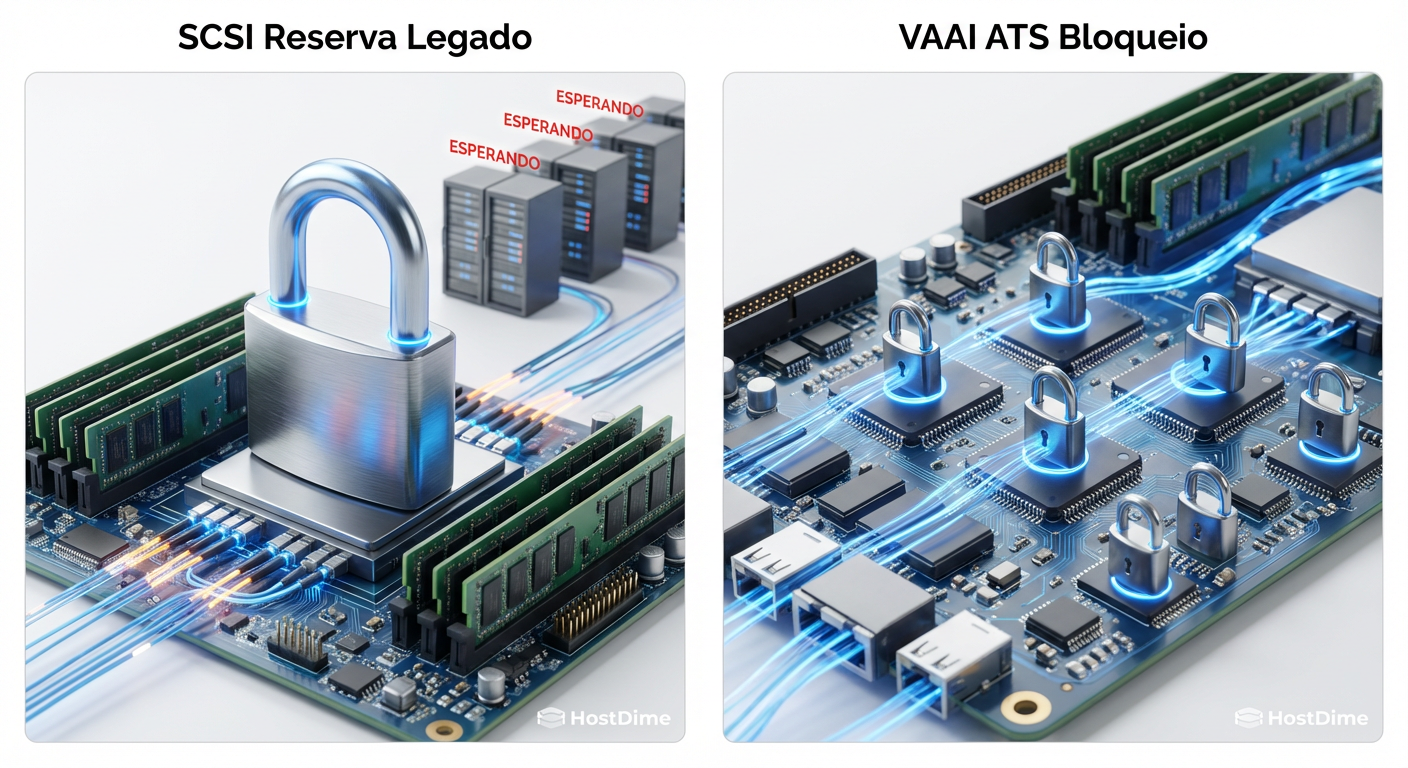 Figura: A diferença crítica entre travar o Datastore inteiro (SCSI Reservation) e o bloqueio granular por setor (ATS).
Figura: A diferença crítica entre travar o Datastore inteiro (SCSI Reservation) e o bloqueio granular por setor (ATS).
Quando essa reversão ocorre, você verá no log do kernel mensagens como ATS miscompare detected. O resultado prático? "Micro-travamentos" aleatórios em todas as VMs do Datastore, mesmo aquelas que não estão gerando carga.
💡 Dica Pro: Verifique se o seu storage suporta ATS Heartbeating. Em alguns arrays All-Flash modernos, a implementação agressiva de ATS Heartbeat pode causar falsos positivos de bloqueio. Em casos específicos (consulte o vendor), desativar o
VMFS3.UseATSForHBOnVMFS5pode estabilizar o ambiente.
O gargalo silencioso nas políticas de seleção de caminho
Você comprou um storage NVMe ou All-Flash capaz de 500.000 IOPS. Você conectou via Fibre Channel de 32Gb ou iSCSI de 25Gb. Você configurou Multipath. Mas a performance está estagnada em um patamar medíocre. O culpado provável é a política de seleção de caminho (PSP - Path Selection Policy).
Round Robin e o limite de 1000 IOPS
A maioria dos hipervisores modernos usa "Round Robin" como padrão para arrays Ativo/Ativo. A teoria é que o host deve alternar o envio de I/O entre todos os caminhos disponíveis para balancear a carga.
O problema reside na configuração padrão: IOPS=1000.
Isso significa que o host enviará 1000 comandos de I/O pelo Caminho A antes de mudar para o Caminho B.
Em um disco rotacional antigo que fazia 150 IOPS, isso significava ficar no mesmo caminho por vários segundos. Em um array All-Flash que cospe 1000 IOPS em milissegundos, essa troca é lenta demais para aproveitar o paralelismo dos múltiplos links e controladoras. Você não está balanceando carga; você está apenas alternando congestionamentos.
Otimizando a fila com IOPS=1
Para infraestruturas modernas, a recomendação quase universal é alterar o parâmetro de limite para IOPS=1. Isso força o host a trocar de caminho a cada comando de I/O (ou o mais próximo possível disso, dependendo da implementação do driver NMP).
Isso resulta em:
Melhor utilização da largura de banda total (agregando os links).
Detecção mais rápida de caminhos degradados (se um I/O falha, o próximo já tenta outro caminho).
Redução da latência média, pois as filas das HBAs são drenadas de forma mais equitativa.
O comando para verificar e ajustar isso no ESXi, por exemplo, envolve o namespace esxcli storage nmp. Não confie no padrão "automático" do instalador.
Métricas definitivas no esxtop e logs do kernel
Como provar que a lentidão é "culpa" da infraestrutura e não da aplicação? Você precisa ir além dos gráficos bonitos do vCenter ou do painel web. Você precisa do esxtop (ou ferramentas equivalentes de CLI em KVM).
Ao analisar a tela de visualização de disco (tecla u ou d), foque na tríade de latência:
1. GAVG (Guest Average Latency)
É a latência total percebida pela VM.
GAVG = KAVG + DAVG
Se este valor está alto (acima de 10-20ms para transacional, ou 2-5ms para Flash), a VM está sofrendo. Mas quem é o culpado?
2. KAVG (Kernel Average Latency)
Esta é a métrica que inocenta o storage. O KAVG mede o tempo que o comando de I/O passou "preso" dentro do kernel do hipervisor antes de ser enviado ao hardware.
- Causas de KAVG alto:
- Queuing: O storage limitou o número de comandos (Queue Depth) e o kernel está enfileirando os excedentes.
- CPU Ready: O host está tão sobrecarregado de CPU que não consegue processar a pilha de storage.
- Drivers: Driver de HBA antigo ou bugado. Se o KAVG é alto e o DAVG é baixo, não adianta comprar discos mais rápidos. O gargalo é o host.
3. DAVG (Device Average Latency)
Este é o tempo desde que o comando saiu da HBA até receber o acknowledgement do storage array.
- Causas de DAVG alto:
- Storage array saturado.
- Congestionamento na SAN (Fibre Channel/Ethernet).
- Problemas de Multipath (thrashing).
 Figura: A "verdade nua e crua" do esxtop: KAVG alto indica gargalo no host, enquanto DAVG aponta para o storage físico.
Figura: A "verdade nua e crua" do esxtop: KAVG alto indica gargalo no host, enquanto DAVG aponta para o storage físico.
Interpretando os Logs
Além das métricas em tempo real, os logs (vmkernel.log ou dmesg) contam a história dos eventos transitórios. Procure por:
SCSI sense codes: Códigos comoH:0x0 D:0x2 P:0x0indicam "Check Condition". O storage está pedindo para o host esperar.NMP: nmp_throttle_log: Indica que o multipathing detectou um caminho morto ou instável.Abort Command: O host cansou de esperar e mandou cancelar o I/O. Isso é catastrófico para bancos de dados.
Otimização prática: O que fazer amanhã
Não aceite a lentidão como "normal" só porque o painel do storage está verde. A camada de virtualização adiciona complexidade que exige ajuste fino constante.
Se você gerencia um ambiente virtualizado com storage compartilhado, sua lista de verificação imediata deve ser:
Auditoria de Snapshots: Identifique e consolide qualquer snapshot com mais de 3 dias. Use ferramentas de automação para impedir que snapshots de backup fiquem órfãos.
Ajuste de Multipath: Rode um script para validar se suas LUNs Flash estão com a política Round Robin e
IOPS=1. O ganho de performance é gratuito e imediato.Validação VAAI: Confirme se o status de aceleração de hardware está "Supported" em todos os Datastores e verifique os logs por falhas de ATS.
A performance de I/O não é apenas sobre quantos IOPS sua caixa aguenta, mas sobre a eficiência com que esses IOPS chegam à aplicação. Um storage array Ferrari com pneus furados (drivers ruins) e freio de mão puxado (snapshots) vai perder a corrida para um Fusca bem ajustado.
Referências & Leitura Complementar
VMware KB 2053145: Multipathing policies in ESXi 5.x and 6.x. Detalha as configurações de PSP e a recomendação de IOPS=1.
SNIA (Storage Networking Industry Association): Storage Virtualization and VAAI Definitions. Para entender a fundo os primitivos SCSI.
VMware Tech Paper: Performance Best Practices for vSphere 7.0/8.0. O guia definitivo de tunning de kernel e storage.
RFC 3720: Internet Small Computer Systems Interface (iSCSI). Fundamental para entender como comandos SCSI são encapsulados e onde a latência de rede interfere.

Ricardo Garcia
Especialista em Virtualização (VMware/KVM)
"Vivo na camada entre o hypervisor e o disco. Ajudo administradores a entenderem como a performance do storage define a estabilidade de datastores, snapshots e migrações críticas."