Deduplicação e Compressão: O Cálculo Real de TCO em Storage Moderno

Economizar disco pode custar caro em latência. Uma análise sênior sobre OpenZFS Fast Dedup, algoritmos ZSTD vs LZ4 e o trade-off entre CPU e armazenamento.
Resumo em 30 segundos
- A Falácia do "Espaço Grátis": Deduplicação não é mágica; é uma troca de Capacidade de Disco por Memória RAM e Ciclos de CPU. Se o custo da RAM necessária para manter a Tabela de Deduplicação (DDT) exceder o custo do armazenamento economizado, você está perdendo dinheiro.
- O Pesadelo da Latência: Em discos mecânicos (HDD), a deduplicação transforma leituras sequenciais em leituras aleatórias ("shattered I/O"), destruindo o throughput de restauração e leitura.
- OpenZFS 2.3 & Fast Dedup: A nova implementação (lançada no ciclo 2024/2025) introduz cotas para a DDT e prefetching inteligente, mas a regra de ouro permanece: use Special VDEVs (NVMe) para metadados ou não use deduplicação.
Há uma sedução perigosa no conceito de deduplicação. A promessa de armazenar 100 TB de dados em 20 TB de disco físico parece, à primeira vista, o Santo Graal da eficiência de infraestrutura. No entanto, como arquitetos, nosso trabalho não é perseguir o cenário ideal, mas gerenciar as falhas do cenário real.
A realidade brutal é que a deduplicação (dedup) em primary storage é frequentemente um erro de cálculo financeiro e técnico. Diferente da compressão (como LZ4 ou ZSTD), que hoje é computacionalmente barata e quase sempre recomendada, a deduplicação impõe uma "taxa de imposto" contínua sobre cada operação de I/O.
Neste artigo, vamos dissecar a matemática por trás desse recurso, ignorando o marketing dos vendors e focando no que realmente importa: TCO (Custo Total de Propriedade), latência de cauda e a física dos discos.
O Custo Oculto da Latência de Reidratação
Quando você grava um arquivo em um sistema de arquivos convencional, o objetivo do allocator é manter os blocos contíguos. Isso garante que, ao ler o arquivo de volta, a cabeça do disco (em HDDs) ou as páginas da NAND (em SSDs) sejam acessadas sequencialmente.
A deduplicação quebra esse contrato.
Imagine que você tem 50 máquinas virtuais (VMs) baseadas na mesma imagem "Gold" do Windows Server. O sistema de storage identifica que os blocos do ntoskrnl.exe são idênticos em todas as 50 VMs e armazena apenas uma cópia física. Economizamos espaço? Sim. Mas criamos um problema de fragmentação lógica extrema.
Quando a VM #49 precisa ler esse arquivo, o storage busca o bloco único. Se o próximo bloco necessário for exclusivo da VM #49, o disco precisa buscar em outro lugar físico. O que era uma leitura linear torna-se um padrão de acesso totalmente aleatório.
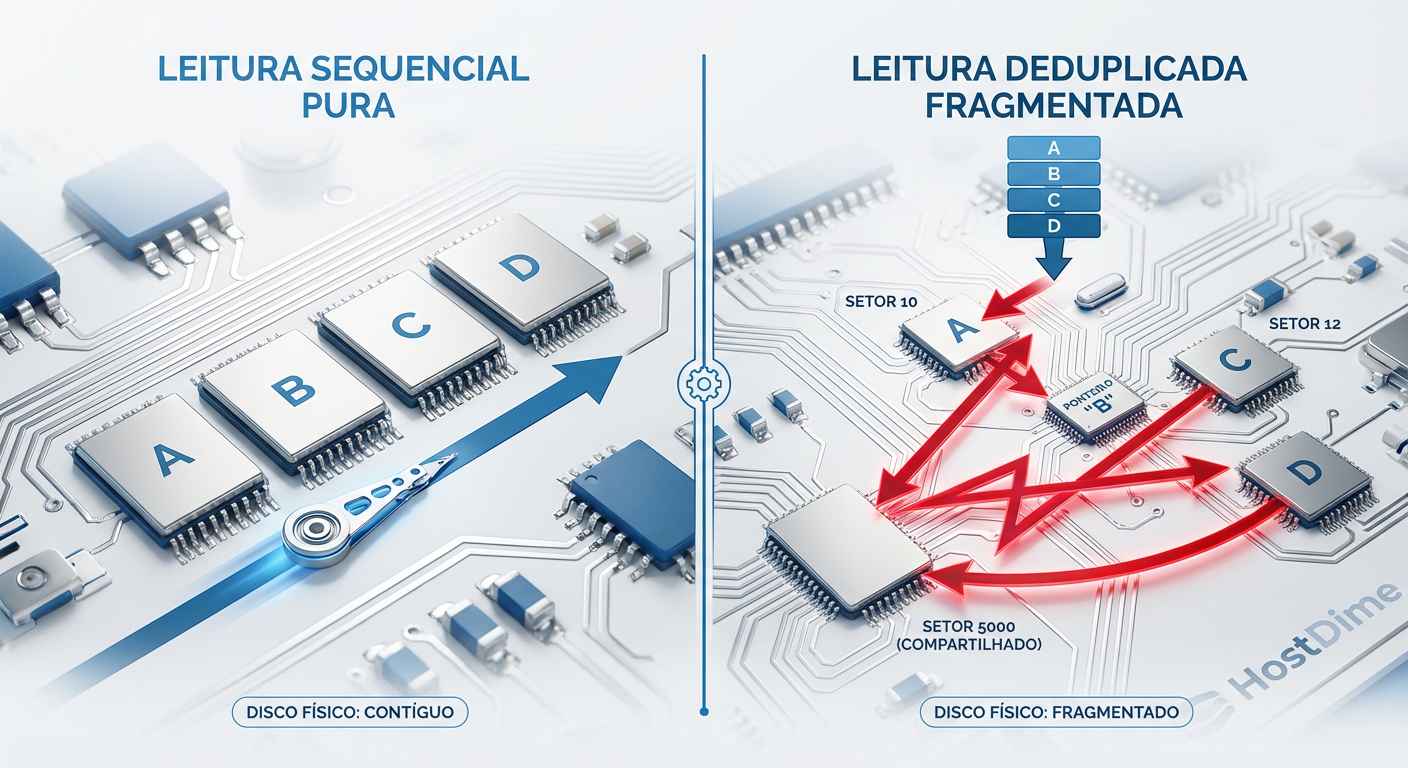 Figura: A "Taxa de Fragmentação": Como a deduplicação transforma I/O sequencial em aleatório, matando a performance de HDDs.
Figura: A "Taxa de Fragmentação": Como a deduplicação transforma I/O sequencial em aleatório, matando a performance de HDDs.
Como vemos na representação acima, em um array de HDDs, isso é catastrófico. O tempo de busca (seek time) de 8ms a 12ms se acumula. Se sua carga de trabalho exige throughput sequencial (ex: streaming de vídeo, restauração de backup, full table scans em bancos de dados), a deduplicação pode reduzir sua performance em ordens de magnitude. Em SSDs/NVMe, o impacto é menor devido à ausência de partes móveis, mas a amplificação de leitura e o custo de CPU para remontar o fluxo de dados (reidratação) ainda introduzem latência.
A Matemática da Entropia e o Estouro da Tabela Hash (DDT)
O coração da deduplicação no ZFS (e na maioria dos sistemas enterprise) é a DDT (Dedup Table). É uma tabela hash gigante que mapeia a assinatura (checksum, geralmente SHA-256) de cada bloco para sua localização física.
Aqui entra o cálculo de TCO que muitos ignoram.
Para cada bloco único no disco, você precisa de uma entrada na DDT. No ZFS, uma entrada na DDT consome aproximadamente 320 bytes de memória RAM. Vamos fazer a conta para um pool de 100 TB com blocos de 64 KB (tamanho padrão comum para VMs):
Capacidade: 100 TB = 104.857.600 MB.
Total de Blocos: 104.857.600 MB / 0.064 MB (64KB) ≈ 1.6 bilhão de blocos.
Tamanho da DDT: 1.6 bilhão * 320 bytes ≈ 512 GB de RAM.
💡 Dica Pro: A regra de ouro antiga era "1 GB de RAM para cada 1 TB de Storage". Em 2025, com tamanhos de bloco maiores (recordsize=1M), essa proporção melhora, mas o risco permanece.
Se a sua DDT não couber na memória RAM (ARC), o sistema precisa buscá-la no disco a cada gravação para verificar se o bloco já existe. Isso é conhecido como "DDT Spill". Quando isso acontece, a performance de escrita cai para perto de zero. Seu storage de alta performance se torna mais lento que um pendrive USB 2.0.
Portanto, o custo da deduplicação não é zero. É o custo de 512 GB de RAM DDR5 ECC. Você deve se perguntar: O custo dessa RAM é menor que o custo dos HDDs/SSDs que estou economizando? Frequentemente, a resposta é não.
Por Que Ativar Deduplicação Global é um Erro de Arquitetura
Um erro comum de "Júnior" é ativar zfs set dedup=on na raiz do pool. Isso força o sistema a calcular hashes e verificar a DDT para tudo: logs de transação, arquivos temporários, metadados e backups criptografados (que, por definição de alta entropia, não deduplicam).
A deduplicação deve ser cirúrgica. Ela só faz sentido financeiro e técnico em datasets onde a taxa de duplicação é garantidamente alta e a latência de leitura não é crítica.
Candidatos Válidos:
Diretórios de VDI (Virtual Desktop Infrastructure).
Repositórios de Build/CI CD (onde milhares de containers compartilham as mesmas libs).
Backups não criptografados (embora ferramentas como Borg ou Proxmox Backup Server façam isso melhor no lado do cliente).
Candidatos Inválidos (Perda de Dinheiro):
Bancos de Dados (PostgreSQL, MySQL, Oracle) - a compressão LZ4 é superior aqui.
Mídia (Vídeo/Áudio) - já são formatos comprimidos.
Backups Criptografados.
O Novo Paradigma: OpenZFS 2.3 Fast Dedup e Special VDEVs
Historicamente, a recomendação de arquitetos sêniores sobre deduplicação no ZFS era simples: "Não use". Porém, o cenário mudou com a chegada do OpenZFS 2.3 (e implementações prévias no TrueNAS SCALE) trazendo o recurso de Fast Dedup.
Esta atualização ataca os dois maiores problemas da implementação legada:
DDT Bloat (Inchaço): Antigamente, remover dados deduplicados era dolorosamente lento porque a tabela precisava ser atualizada de forma ineficiente. O Fast Dedup introduz o Log-based Dedup, permitindo atualizações em batch e remoção assíncrona.
Controle de Memória: Agora é possível definir um Dedup Quota. Se a tabela atingir um tamanho limite na RAM, o sistema para de tentar deduplicar novas gravações, degradando graciosamente para um sistema de arquivos normal, em vez de travar o servidor.
A Salvação: Special VDEVs
Mesmo com o Fast Dedup, a física não muda: a DDT precisa ser lida rapidamente. A arquitetura moderna exige o uso de Special VDEVs.
Trata-se de dedicar um par espelhado (Mirror) de dispositivos NVMe de alta resistência (DWPD alto) exclusivamente para armazenar Metadados e a DDT. Isso isola as operações de busca de hash dos discos de dados (HDDs rotacionais ou SSDs SATA mais lentos).
 Figura: Arquitetura Híbrida: Isolando a DDT em NVMes dedicados (Special VDEVs) para evitar o gargalo de IOPS nos discos de dados.
Figura: Arquitetura Híbrida: Isolando a DDT em NVMes dedicados (Special VDEVs) para evitar o gargalo de IOPS nos discos de dados.
Ao mover a DDT para NVMes, eliminamos a penalidade de seek na verificação de existência do bloco. O custo de TCO muda: agora o custo da deduplicação é o preço de dois NVMes Enterprise, não mais 512 GB de RAM.
Métricas de Validação: zdb -S e o Custo Computacional
Antes de ativar qualquer switch, você deve validar a hipótese. O ZFS fornece uma ferramenta nativa para isso: zdb.
O comando zdb -S <poolname> simula a tabela de deduplicação na memória sem ativá-la, varrendo todos os metadados atuais.
Simulated DDT histogram:
bucket allocated referenced
______ ______________________________ ______________________________
refcnt blocks LSIZE PSIZE Dratio blocks LSIZE PSIZE Dratio
------ ------ ----- ----- ------ ------ ----- ----- ------
1 2.5M 300G 150G 2.00 2.5M 300G 150G 2.00
2 100K 10G 5G 2.00 200K 20G 10G 2.00
4 10K 1G 500M 2.00 40K 4G 2G 2.00
Total 2.6M 311G 155G 2.00 2.7M 324G 162G 2.00
Como ler isso:
Olhe para a coluna Dratio (Dedup Ratio). Se o resultado final for menor que 1.5x (ou seja, economizando menos de 33% de espaço), a deduplicação não vale a pena. O custo de CPU (cálculo de SHA-256 para cada write) e o custo de RAM/NVMe superam a economia de comprar mais um disco rígido.
⚠️ Perigo: Não confie em estimativas de fabricantes de storage proprietário. Eles frequentemente calculam a taxa de deduplicação baseada em "capacidade lógica provisionada" (thin provisioning) e não em dados únicos reais, inflando os números para 10:1 ou 20:1. Use
zdb -Sou ferramentas comofdupespara uma análise honesta.
Trade-offs e Decisão Arquitetural
A decisão de usar deduplicação deve ser baseada em uma planilha de TCO, não em ideologia.
Cenário A: O Home Lab ou SMB Você tem um servidor com 64GB de RAM e 40TB de disco.
- Veredito: Não use dedup. Use compressão
zstd-3oulz4. A memória é preciosa demais para o ARC (cache de leitura) para ser desperdiçada com uma tabela hash. Discos rígidos são baratos. Compre mais um disco de 14TB.
Cenário B: O Datacenter de Virtualização (All-Flash) Você tem um cluster All-Flash NVMe rodando 2.000 VMs. O custo do TB de NVMe é alto.
- Veredito: Use dedup (com cautela). Com o OpenZFS 2.3 Fast Dedup e a velocidade nativa do NVMe, a penalidade de latência é mascarada. A economia de espaço em flash de nível enterprise (que custa caro) justifica o uso de CPU e RAM.
Cenário C: O Arquivo Morto (Backup Server) Você armazena 500TB de backups em HDDs rotacionais.
- Veredito: Depende. Se for backup inline (o storage faz o dedup), cuidado com a velocidade de ingest. Se a DDT não couber na RAM, seus backups vão falhar por timeout. Prefira deduplicação no software de backup (Veeam, Proxmox PBS) antes de enviar os dados para o storage. Deixe o storage ser "burro" e rápido.
O Futuro é Híbrido
A deduplicação não é uma bala de prata; é uma ferramenta de compressão financeira com efeitos colaterais técnicos severos. Com a introdução do OpenZFS 2.3 e a democratização dos SSDs NVMe para camadas de metadados, a barreira de entrada diminuiu, mas a física da latência permanece.
Minha recomendação para 2026 em diante: Priorize Compressão (ZSTD) > Tiering Automático > Deduplicação. Só ative a deduplicação se você tiver (1) Special VDEVs dedicados e (2) uma prova matemática via zdb -S de que a economia de espaço pagará o hardware adicional necessário para suportá-la.
Se você não pode pagar pela RAM ou pelo NVMe para segurar a DDT, você não pode pagar pela deduplicação. Compre mais discos giratórios e durma tranquilo.
Referências & Leitura Complementar
OpenZFS 2.3 Release Notes & Fast Dedup PR: Detalhes técnicos sobre a implementação do Log-based Dedup e cotas de DDT. [GitHub OpenZFS]
SNIA (Storage Networking Industry Association) Dictionary: Definições padronizadas de Data Deduplication e Rehydration.
JEDEC SSD Specifications: Para entender as implicações de Write Amplification em SSDs de consumo vs Enterprise quando submetidos a workloads de metadados intensos.
"ZFS on Linux" Mailing List Archives: Discussões históricas sobre DDT Spill e performance de Special VDEVs.

Otávio Henriques
Arquiteto de Soluções Enterprise
"Com duas décadas desenhando infraestruturas críticas, olho além do hype. Foco em TCO, resiliência e trade-offs, pois na arquitetura corporativa a resposta correta quase sempre é 'depende'."