Deduplicação no Proxmox Backup Server: a matemática do Buzhash e chunks dinâmicos

Entenda como o Proxmox Backup Server utiliza o algoritmo Buzhash e chunks dinâmicos no formato pxar para economizar terabytes no seu homelab ou datacenter.
Se você gerencia sua própria infraestrutura, sabe que o custo do armazenamento é o verdadeiro vilão do orçamento. Comprar servidores usados é fácil, mas encher gavetas com discos rígidos de alta capacidade drena qualquer carteira. Quando começamos a fazer backups de máquinas virtuais e containers, o espaço desaparece em questão de dias. É aqui que a deduplicação deixa de ser um luxo corporativo e se torna uma necessidade absoluta para a sobrevivência do seu homelab ou datacenter local.
O Proxmox Backup Server (PBS) mudou as regras do jogo para quem faz self-hosting. Ele não apenas guarda seus dados, mas os fatia, analisa e armazena de uma forma incrivelmente eficiente. O segredo por trás dessa economia massiva de discos não é mágica. É pura matemática aplicada ao armazenamento de blocos.
Resumo em 30 segundos
- O Proxmox Backup Server utiliza deduplicação no nível do bloco para economizar espaço massivo em discos.
- Algoritmos de chunks dinâmicos baseados em Buzhash resolvem o problema de deslocamento de bytes que quebra a deduplicação tradicional.
- Para que a matemática funcione sem gargalos, o uso de SSDs para armazenar os índices do datastore é praticamente obrigatório.
O pesadelo do armazenamento quando cada backup completo devora seus discos
A regra de ouro do backup dita que você precisa de múltiplas cópias dos seus dados. Se você tem um cluster Proxmox VE rodando 2 terabytes de máquinas virtuais, um backup completo diário exigiria 14 terabytes de armazenamento bruto em apenas uma semana. Nenhuma carteira de operador independente aguenta escalar discos rígidos mecânicos (HDDs) ou arrays de estado sólido (SSDs) nessa velocidade.
Muitos administradores tentam contornar isso fazendo apenas backups incrementais tradicionais. O problema é que a cadeia de incrementais se torna frágil. Se um arquivo no meio da corrente corromper, todos os backups subsequentes podem ser perdidos. Precisamos da segurança de um backup completo sintético, mas com o custo de armazenamento de um incremental minúsculo.
 Figura: Servidor com discos lotados exigindo expansão constante de hardware
Figura: Servidor com discos lotados exigindo expansão constante de hardware
A deduplicação resolve isso garantindo que um bloco de dados específico seja gravado no disco físico apenas uma vez, não importa quantas máquinas virtuais ou backups diários o contenham. Se você tem dez VMs rodando o mesmo sistema operacional base, os arquivos do núcleo do sistema são gravados apenas uma vez no seu storage.
Por que o rsync e os snapshots de file system não resolvem o problema do espaço
Ferramentas clássicas como o rsync são fantásticas para sincronizar arquivos soltos. No entanto, quando lidamos com imagens de disco de máquinas virtuais (arquivos raw ou qcow2), o rsync enxerga um único arquivo gigante. Se um pequeno log for alterado dentro da VM, o rsync pode ter dificuldades para sincronizar apenas a diferença de forma eficiente sem ler o arquivo inteiro repetidas vezes.
Snapshots no nível do sistema de arquivos, como os nativos do ZFS ou Btrfs, são excelentes para reversões rápidas. O problema é que eles residem no mesmo pool de armazenamento dos dados de produção. Se o seu array de discos principal falhar, os snapshots morrem junto com ele. Um backup real precisa estar em um hardware separado, preferencialmente em um servidor dedicado.
⚠️ Perigo: Nunca confie apenas em snapshots locais como sua única estratégia de backup. Um erro catastrófico no hypervisor ou uma falha dupla de discos no seu pool ZFS levará seus dados originais e suas cópias de segurança para o túmulo simultaneamente.
A armadilha dos blocos de tamanho fixo na deduplicação tradicional
A primeira geração de sistemas de deduplicação tentou resolver o problema cortando os arquivos em pedaços de tamanho exato. Imagine fatiar um arquivo de 100 megabytes em blocos fixos de 1 megabyte. O sistema calcula o hash (uma assinatura digital) de cada bloco e o salva. Se o mesmo bloco aparecer novamente, o sistema apenas cria um ponteiro para o bloco original.
Isso funciona perfeitamente até que ocorra o temido "deslocamento de bytes". Imagine que você insira uma única linha de texto no início de um arquivo de log dentro da sua VM. Essa pequena adição empurra todos os dados subsequentes alguns bytes para a frente.
Como os blocos têm tamanho fixo, os limites de corte agora caem em lugares diferentes. O sistema recalcula os hashes e percebe que todos os blocos mudaram. O resultado é desastroso. O software de backup acha que o arquivo inteiro é novo e grava tudo de novo no disco, destruindo a eficiência da deduplicação.
Comparativo de estratégias de fatiamento de dados
| Característica | Chunks Fixos (Deduplicação Básica) | Chunks Dinâmicos (Proxmox Backup Server) |
|---|---|---|
| Performance de CPU | Alta (Cálculo simples de offset) | Média (Exige cálculo contínuo de hash) |
| Eficiência de Espaço | Baixa em arquivos modificados | Altíssima (Resiste a deslocamento de bytes) |
| Complexidade | Baixa | Alta (Uso de algoritmos de janela deslizante) |
| Custo de Storage | Alto (Desperdício por falsos positivos) | Baixo (Otimização máxima do disco) |
A matemática do Buzhash e a magia dos chunks dinâmicos no formato pxar
Para contornar a armadilha do tamanho fixo, o Proxmox Backup Server utiliza chunks dinâmicos. O tamanho de cada pedaço de dado não é definido por uma régua rígida, mas sim pelo próprio conteúdo do arquivo. É aqui que entra o algoritmo Buzhash.
O Buzhash é uma função de hash cíclico (rolling hash). Imagine uma pequena janela deslizante que percorre os dados do seu backup, byte por byte. A cada passo, o algoritmo calcula um hash rápido apenas dos dados que estão dentro dessa janela.
 Figura: Representação visual da janela deslizante do Buzhash criando chunks dinâmicos
Figura: Representação visual da janela deslizante do Buzhash criando chunks dinâmicos
O sistema define uma regra matemática arbitrária. Por exemplo: "Sempre que os últimos 24 bits do hash calculado forem iguais a zero, faça um corte aqui". Como o corte é baseado no conteúdo que está passando pela janela, os limites do chunk ficam "ancorados" aos dados.
Se você inserir um byte no início do arquivo, a janela deslizante vai ler esse novo byte, mas assim que chegar aos dados antigos, a matemática voltará a bater. O corte será feito exatamente no mesmo lugar em relação ao conteúdo original. Apenas o primeiro chunk será considerado novo e gravado no disco. Todo o resto do arquivo será reconhecido e deduplicado perfeitamente.
Para empacotar tudo isso, o PBS utiliza o formato pxar (Proxmox File Archive Format). Ele foi desenhado do zero para armazenar metadados de arquivos e diretórios de uma forma que seja amigável para essa deduplicação baseada em chunks, garantindo que a restauração granular de arquivos seja rápida e não exija a reconstrução de blocos gigantescos na memória.
Como validar a eficiência da deduplicação lendo os relatórios do datastore no Proxmox
Configurar o servidor é apenas o primeiro passo. Como operadores de infraestrutura, precisamos monitorar se a matemática está realmente salvando nossos discos. A interface web do Proxmox Backup Server fornece métricas cruciais no painel do seu Datastore.
A métrica mais importante é o Fator de Deduplicação (Deduplication Factor). Se o painel mostra um fator de 15.0x, isso significa que para cada 15 gigabytes de dados lógicos que suas VMs acham que estão armazenando, o PBS está consumindo apenas 1 gigabyte de espaço físico real no seu array de discos.
💡 Dica Pro: Não se assuste se o seu primeiro backup completo mostrar um fator de deduplicação de 1.0x. A mágica acontece a partir do segundo backup. Deixe a rotina rodar por uma semana e observe o gráfico de uso de disco se estabilizar em uma linha quase horizontal, mesmo com backups completos diários.
Você também notará o processo de Garbage Collection (Coleta de Lixo). Como vários backups apontam para os mesmos chunks, o PBS não pode simplesmente apagar um arquivo quando um backup expira. A coleta de lixo varre os índices para descobrir quais chunks ficaram órfãos (nenhum backup aponta mais para eles) e só então libera o espaço físico no disco.
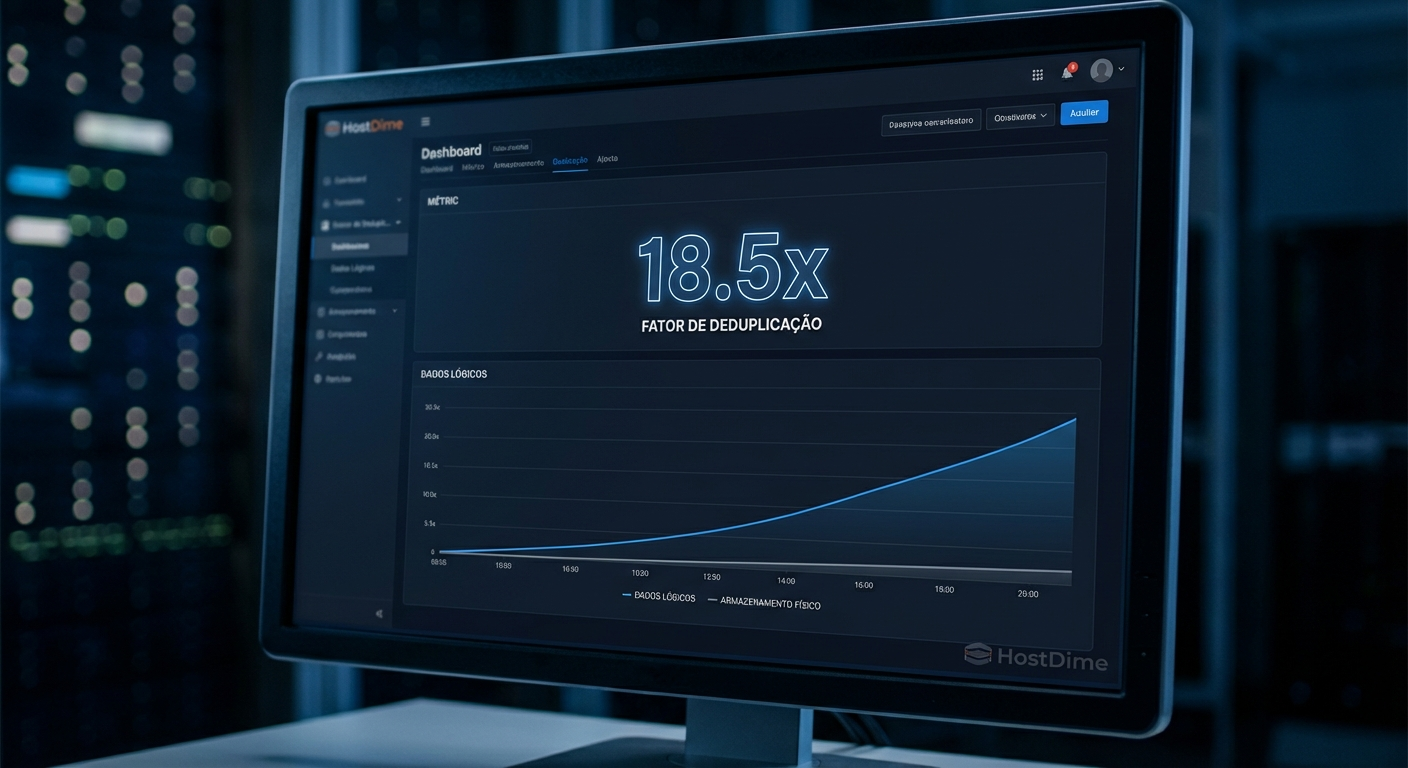 Figura: Gráfico mostrando o crescimento lógico versus o armazenamento físico real
Figura: Gráfico mostrando o crescimento lógico versus o armazenamento físico real
O impacto no hardware: por que você precisa de SSDs para os índices
Toda essa matemática de janela deslizante e ponteiros de chunks tem um preço: operações de entrada e saída por segundo (IOPS). O diretório .chunks no seu datastore do PBS vai abrigar milhões de pequenos arquivos.
Se você tentar rodar o datastore inteiro em um array RAID de discos rígidos mecânicos (HDDs) de 7200 RPM, você vai sofrer. A agulha do disco mecânico não consegue pular rápido o suficiente para ler e gravar milhares de hashes minúsculos durante a fase de verificação ou coleta de lixo. O processo que deveria levar minutos pode demorar dias.
A recomendação absoluta da comunidade homelab e de arquitetura enterprise é o uso de armazenamento em estado sólido. Se o orçamento for apertado e você precisar usar HDDs para o armazenamento em massa dos chunks, você deve, no mínimo, utilizar SSDs NVMe ou SATA de classe enterprise para o sistema operacional do PBS e para partições de metadados especiais (se estiver usando ZFS por baixo do PBS).
Discos de estado sólido entregam dezenas de milhares de IOPS, permitindo que o banco de dados de índices do Proxmox Backup Server encontre as referências dos chunks quase instantaneamente.
O veredito sobre a topologia de armazenamento
A deduplicação do Proxmox Backup Server é uma das implementações mais elegantes disponíveis no mundo open source. Ela democratizou a proteção de dados de nível corporativo para qualquer pessoa com um servidor modesto. No entanto, é vital entender onde a inteligência deve residir.
Muitos administradores cometem o erro de habilitar a deduplicação nativa do sistema de arquivos ZFS no servidor de backup, achando que vão economizar ainda mais espaço. Isso é um erro fatal. A deduplicação do ZFS é inline, consome quantidades absurdas de memória RAM (cerca de 1GB a 5GB de RAM por terabyte de disco) e vai brigar por recursos com o PBS.
Deixe o sistema de arquivos (seja ZFS, Ext4 ou XFS) focado apenas em garantir a integridade dos dados no disco. Deixe a matemática complexa do Buzhash e o gerenciamento dos chunks dinâmicos exclusivamente a cargo do Proxmox Backup Server. Ao respeitar essa divisão de tarefas e fornecer o hardware adequado para os índices, seus discos vão durar anos a mais e seu orçamento de TI agradecerá.
Referências & Leitura Complementar
Proxmox Backup Server Documentation: "Terminologia e Arquitetura - Chunks e Deduplicação". Disponível na documentação oficial da Proxmox.
RFC 3174 / Hash Algorithms: Conceitos fundamentais sobre funções de hash seguro aplicadas a blocos de dados.
Buzhash Algorithm: Uzgalis, R. (1992). "Hashing Concepts and the Buzhash Algorithm". Referência técnica sobre o funcionamento de rolling hashes para limites dinâmicos.
O que é o formato pxar no Proxmox Backup Server?
O pxar (Proxmox File Archive Format) é um formato de arquivamento otimizado para deduplicação, projetado para armazenar metadados e dados de arquivos de forma eficiente, permitindo acesso rápido e restauração granular sem precisar extrair o arquivo inteiro.Por que chunks dinâmicos são melhores que chunks fixos?
Chunks dinâmicos se ajustam ao conteúdo do arquivo. Se um byte for inserido no início de um arquivo, o algoritmo Buzhash recalcula os limites do chunk, preservando a deduplicação do restante do arquivo. Em blocos de tamanho fixo, essa mesma alteração mudaria todos os blocos subsequentes, destruindo a economia de espaço.A deduplicação do PBS consome muita memória RAM?
Diferente da deduplicação inline do ZFS, que exige muita RAM para manter a tabela de blocos na memória, o PBS gerencia a deduplicação no nível do software de backup com índices otimizados em disco (preferencialmente SSDs). Isso o torna muito mais amigável e viável para servidores self-hosted com recursos limitados.
Marcos Lopes
Operador Open Source (Self-Hosted)
"Troco licenças proprietárias por soluções open source robustas, ciente de que a economia financeira custa suor na manutenção. Defensor da soberania de dados e da força da comunidade."